
Verstehen Sie den dritten Teil des DeepSeek-Open-Source-Projekts in einem Artikel. 300 Codezeilen enthüllen den Schlüssel hinter der Inferenzeffizienz von V3/R1

Am dritten Tag der Open Source Week brachte DeepSeek nicht nur Technologie, sondern verbreitete auch die gute Nachricht, dass R2 auf dem Weg ist. Als Benutzer ist es keine Möglichkeit, die Geburt eines Superstars mitzuerleben, wenn man die von DeepSeek verworfenen Technologiebibliotheken sieht und die Modelle sieht, die diese Technologien anwenden.
Die heutige Einführung ist DeepGEMM, eine Bibliothek, die für eine saubere und effiziente FP8-General-Matrix-Multiplikation (GEMM) mit feinkörnigen Skalierungsfunktionen entwickelt wurde, wie in DeepSeek-V3 beschrieben. Es unterstützt normale und gemischte Experten (MoE) gruppierte GEMMs. Die Bibliothek ist in CUDA geschrieben und erfordert keine Kompilierung während der Installation. Stattdessen verwendet sie leichte Just-in-Time-Module (JIT), um alle Kernel zur Laufzeit zu kompilieren.
Ich möchte nicht sagen, dass DeepSeek nicht leistungsstark ist, aber die Open-Source-Entwicklung der letzten drei Tage hat gezeigt, dass sie, selbst wenn sie von Magic Square unterstützt werden, nicht so ressourcenreich sind wie die großen Unternehmen und hart arbeiten müssen, um die Rechenressourcen zu begrenzen.
Auch dieses Mal verlässt GeepGEMM dieses Thema immer noch nicht. Im Vergleich zu früheren Technologien sind die Vorteile von DeepGEMM:
- Höhere Effizienz: Reduzierter Rechen- und Speicheraufwand durch FP8 und zweistufige Akkumulation
- Flexible Bereitstellung: Die JIT-Kompilierung ist äußerst anpassungsfähig und reduziert den Aufwand vor der Kompilierung
- Gezielte Optimierung: Unterstützung von MoE und umfassende Anpassung an den Hopper-Tensorkern
- Einfacheres Design: weniger Kerncode, vermeidet komplexe Abhängigkeiten und ist leicht zu erlernen und zu optimieren
Diese Eigenschaften zeichnen es im modernen KI-Computing aus, insbesondere in Szenarien, die effiziente Inferenz und geringen Stromverbrauch erfordern .
Gebaut für modernes KI-Computing
Höhere Effizienz und flexiblere Bereitstellung sind die Highlights von DeepGEMM. Die Kernlogik umfasst nur etwa 300 Codezeilen, übertrifft jedoch den auf Expertenebene optimierten Kernel in den meisten Matrixgrößen. Bis zu 1350+ FP8 TFLOPS auf Hopper-GPUs.
FP8 ist eine Methode zum Komprimieren von Zahlen. Dies entspricht der Reduzierung von Zahlen, die ursprünglich 32-Bit- oder 16-Bit-Speicher erfordern, in 8-Bit-Speicher. So wie Sie Notizen mit kleineren Haftnotizen machen, können Sie zwar weniger Inhalt auf jedes Blatt Papier schreiben, es ist aber schneller zu tragen und zu übertragen .
Der Vorteil dieser komprimierten Berechnung besteht darin, dass sie weniger Speicher beansprucht – eine Aufgabe gleicher Größe erfordert weniger „Haftnotizen“ und das Verschieben kleiner Papierstücke geht schneller als das Verschieben großer Dateien, sodass auch die Berechnungsgeschwindigkeit schneller ist. Die Herausforderung besteht jedoch darin, dass es leicht ist, Fehler zu machen.
Um das FP8-Genauigkeitsproblem zu lösen, verwendet DeepGEMM eine clevere „Zwei-Schritte-Methode“: Mit FP8 werden groß angelegte Multiplikationen durchgeführt, ähnlich wie mit einem Taschenrechner, um schnell eine Reihe von Ergebnissen zu berechnen. In diesem Schritt sind Fehler unvermeidlich.
Aber egal, es gibt noch einen zweiten Schritt: die hochpräzise Aggregation. Von Zeit zu Zeit werden diese Ergebnisse in eine genauere 32-stellige Summe umgewandelt und die Summe sorgfältig mit Notizpapier überprüft, um eine Anhäufung von Fehlern zu vermeiden.
Zuerst ausführen und dann zwei Stufen der kumulativen Fehlerprüfung durchlaufen. Durch dieses Design ermöglicht DeepGEMM, dass KI-Modelle reibungsloser auf Mobiltelefonen, Computern und anderen Geräten laufen und gleichzeitig den Stromverbrauch senken, sodass es sich für komplexere Anwendungsszenarien in der Zukunft eignet .

Einschließlich der Anwendung der JIT-Kompilierung handelt es sich um eine ähnliche Idee. JIT-Kompilierung, der vollständige Name ist „Just-In-Time“-Kompilierung. Auf Chinesisch kann es als Just-in-Time-Kompilierung bezeichnet werden, und das entsprechende Konzept ist statische Kompilierung.
Ein allgemeines Programm muss geschrieben und kompiliert werden, bevor Sie es verwenden, und in eine Sprache umgewandelt werden, die der Computer verstehen kann. Bei der JIT-Kompilierung wird jedoch nur der Code in Anweisungen umgewandelt, die der Computer ausführen kann, wenn das Programm ausgeführt wird.
Es kann den Code vor Ort an die Bedingungen Ihres Computers anpassen (z. B. NVIDIA Hopper-Grafikkarte) und die am besten geeigneten Anweisungen anpassen. Es ist nicht so starr wie die Vorkompilierung, sodass das Programm reibungsloser ausgeführt werden kann. Stellen Sie ohne Zeit- und Platzverschwendung nur die Teile zusammen, die Sie gerade benötigen, und sorgen Sie dafür, dass alles genau richtig ist.
Hopper Tensor Core und JIT-Kompilierung sind die besten Partner. Die JIT-Kompilierung kann zur Laufzeit vor Ort basierend auf Ihrer Hopper-Grafikkarte optimalen Code generieren und so die Recheneffizienz des Tensorkerns maximieren.
DeepGEMM unterstützt gewöhnliche GEMMs und gemischte Experten-GEMMs (MoE), die unterschiedliche Rechenanforderungen haben. Die JIT-Kompilierung kann den Code vorübergehend an die Merkmale der Aufgabe anpassen und die FP8-Berechnungs- oder Transformations-Engine-Funktion des Tensorkerns direkt mobilisieren, um Verschwendung zu reduzieren und die Geschwindigkeit zu erhöhen.
Wie lässt sich solch eine technische Route beschreiben: schlank, leicht und scharf .
Für die Mehrheit der Entwickler kann man sagen, dass DeepGEMM eine weitere gute Nachricht ist. Im Folgenden finden Sie Informationen zur Bereitstellung. Vielleicht möchten Sie damit experimentieren.
DeepGEMM-Bereitstellungshandbuch
DeepGEMM ist eine für die allgemeine Matrixmultiplikation (GEMM) des FP8 optimierte Bibliothek mit einem verfeinerten Skalierungsmechanismus und wird in DeepSeek-V3 vorgeschlagen. Es unterstützt Standard-GEMM und Mixed Expert (MoE) gruppiertes GEMM. Die Bibliothek ist in CUDA geschrieben und muss während der Installation nicht vorkompiliert werden. Stattdessen werden alle Kernfunktionen zur Laufzeit durch ein leichtes Just-in-Time-Kompilierungsmodul (JIT) kompiliert.
Derzeit unterstützt DeepGEMM nur NVIDIA Hopper-Tensorkerne. Um das Problem der unzureichenden Berechnungsgenauigkeit des FP8-Tensorkerns anzugehen, wird zur Optimierung die zweistufige Akkumulationstechnologie (Boosting) des CUDA-Kerns verwendet. Obwohl es einige Konzepte von CUTLASS und CuTe übernimmt, verlässt sich DeepGEMM nicht zu sehr auf deren Vorlagen oder mathematische Operationen, sondern strebt stattdessen nach Einfachheit und enthält nur eine Kernberechnungskernfunktion mit etwa 300 Codezeilen. Dies macht DeepGEMM zu einer klaren und leicht verständlichen Referenzressource zum Erlernen von Hopper-FP8-Matrixmultiplikations- und Optimierungstechniken.
Trotz seines einfachen Designs ist die Leistung von DeepGEMM bei einer Vielzahl von Matrixformen mit professionell optimierten Bibliotheken vergleichbar und in einigen Fällen sogar besser.
Leistung
Wir haben mit NVCC 12.8 auf H800 getestet und alle Matrixformen abgedeckt, die während der DeepSeek-V3/R1-Inferenz verwendet werden können (einschließlich Vorfüllung und Dekodierung, aber ohne Tensorparallelität). Alle Beschleunigungsmetriken werden auf der Grundlage unserer intern sorgfältig optimierten CUTLASS 3.6-Implementierung berechnet.
Die Leistung von DeepGEMM unter bestimmten Matrixformen ist nicht ideal. Wenn Sie an einer Optimierung interessiert sind, können Sie gerne optimierungsbezogene PRs einreichen.
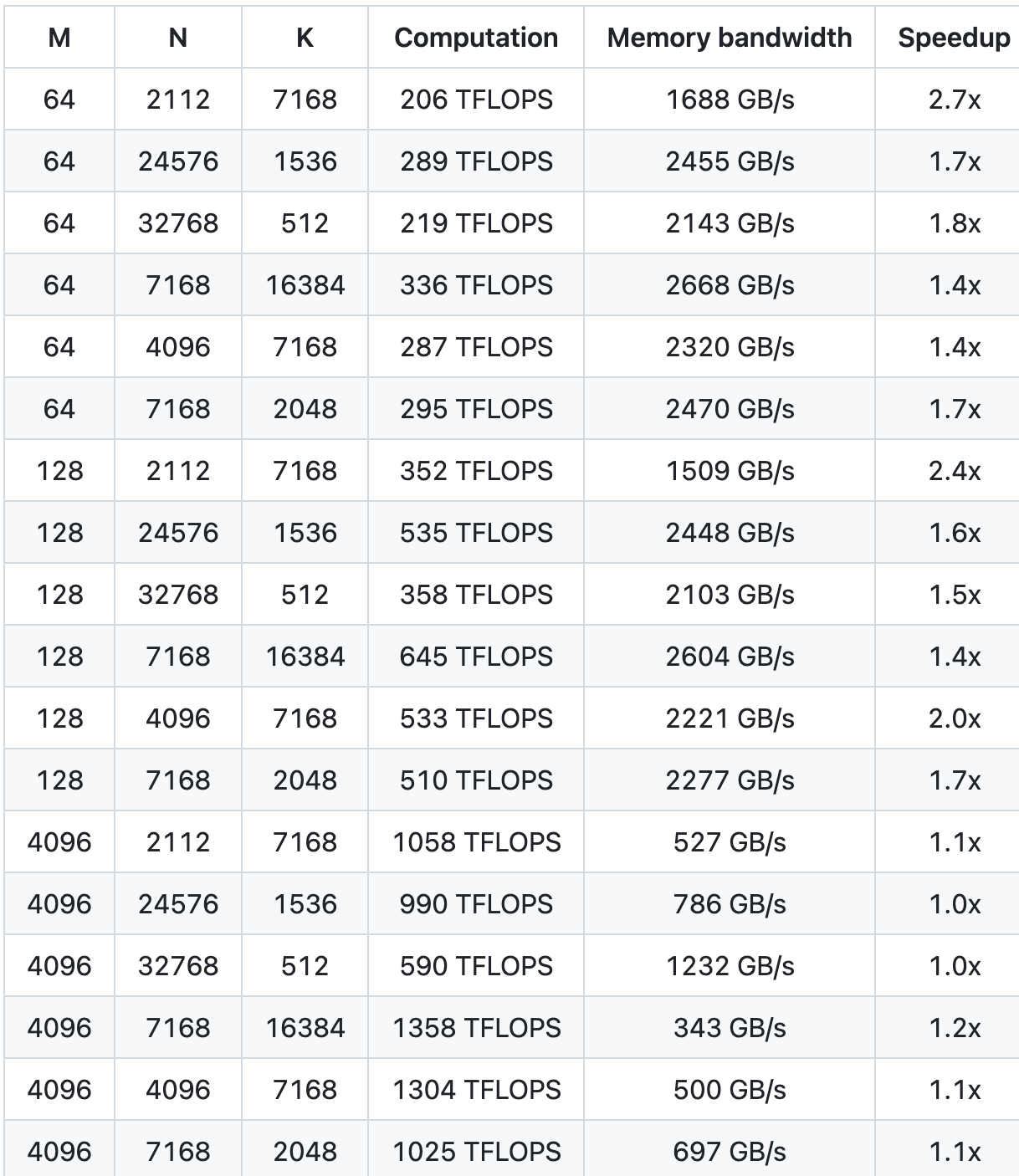
Standard-GEMM für dichte Modelle
Gruppiertes GEMM für MoE-Modell (kontinuierliches Layout)
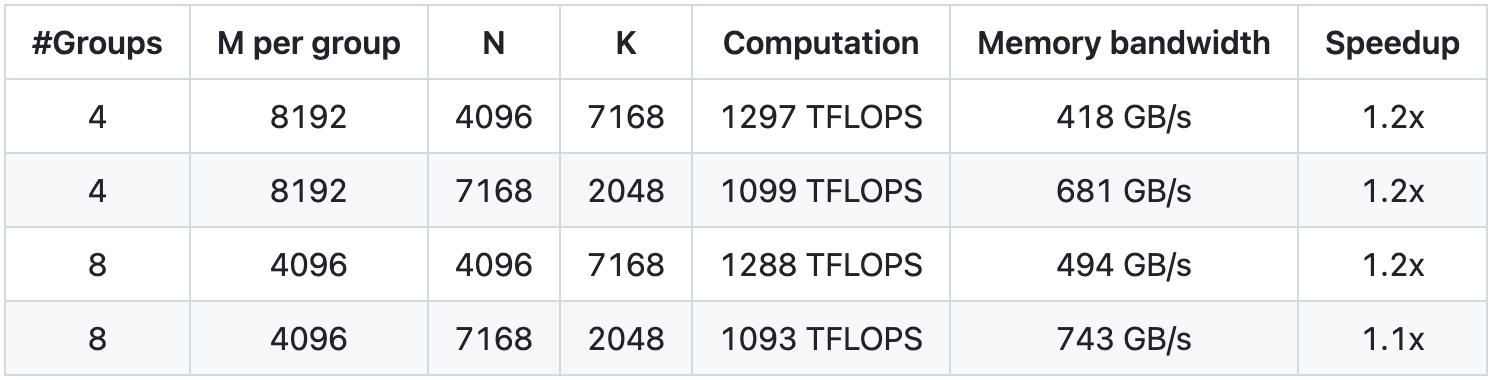
Gruppiertes GEMM (Maskenlayout) für MoE-Modell
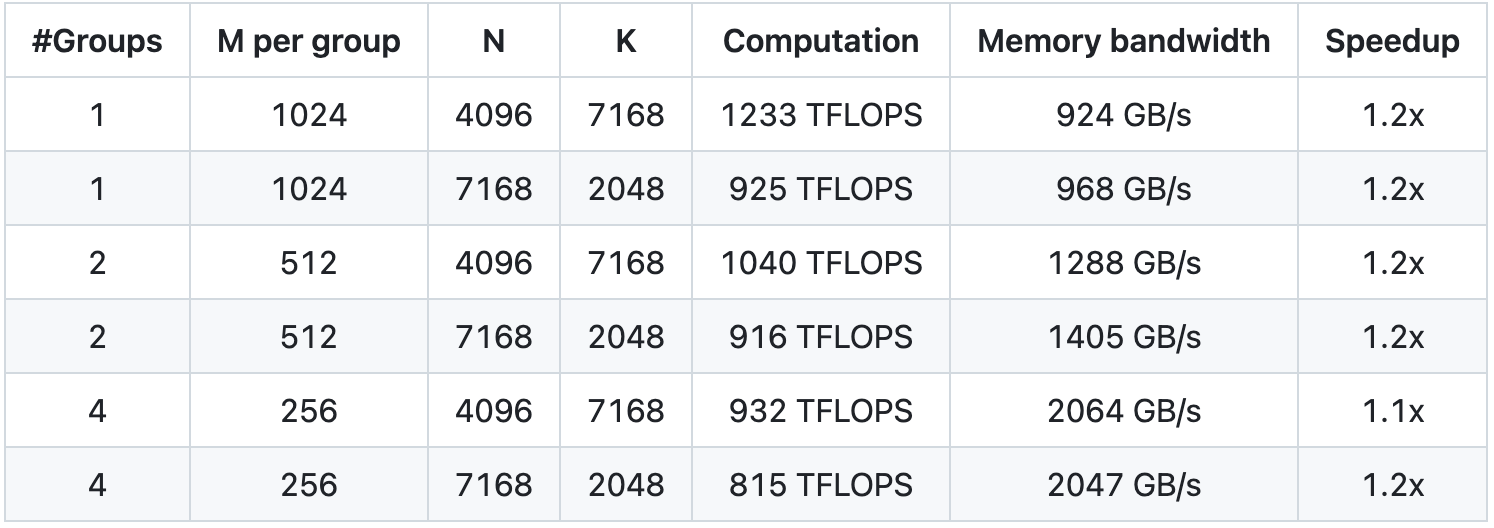
Schnellstart
Umweltanforderungen
- Hopper-Architektur-GPU, muss sm_90a unterstützen
- Python 3.8 und höher
- CUDA Version 12.3 und höher (Version 12.8 und höher wird für beste Leistung dringend empfohlen)
- PyTorch 2.1 und höher
- CUTLASS 3.6 und höher (kann über das Git-Submodul geklont werden)
entwickeln
# Submodul muss geklont werden
git clone –rekursiv [email protected]:deepseek-ai/DeepGEMM.git# Erstellen Sie symbolische Links für Include-Verzeichnisse Dritter (CUTLASS und CuTe).
Python setup.py entwickeln# Testen Sie die JIT-Kompilierung
Python-Tests/test_jit.py# Testen Sie alle GEMM-Geräte (normal, zusammenhängend gruppiert und maskiert gruppiert).
Python-Tests/test_core.py
Installieren
Python setup.py installieren
Importieren Sie dann deep_gemm in Ihr Python-Projekt und haben Sie Spaß daran!
Im Anhang finden Sie die Open-Source-Adresse von GitHub:
https://github.com/deepseek-ai/DeepGEMM
Autor: Liu Ya, Mo Chongyu
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo