
Die neuesten Produkte von OpenAI sind vollständig verfügbar! Ultraman widerlegt, dass die KI-Entwicklung ins Stocken gerät. Ilya gibt seinen Fehler zu und sucht heimlich nach dem nächsten großen Durchbruch.

In diesem Jahr gibt es in der KI-Kreis wirklich Aufregung.
Kürzlich explodierten im KI-Kreis die Nachrichten darüber, dass die Skalierungsgesetze „an die Wand stoßen“. Die Turing-Preisträger Yann Lecun, Ilya und Anthropic-Gründer Dario Amodei begannen einen Wortgefecht.
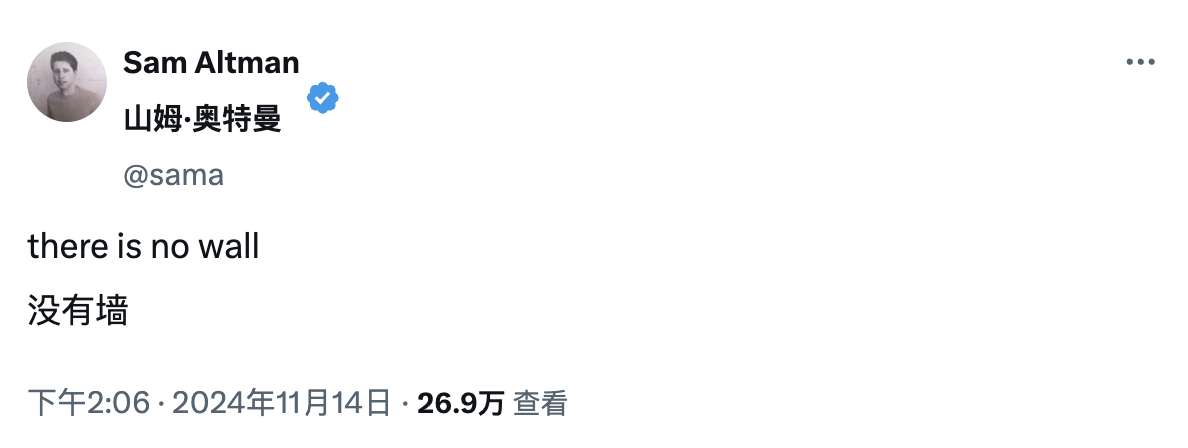
Im Mittelpunkt der Debatte steht die Frage, ob es eine Obergrenze für Leistungsverbesserungen geben wird, wenn die Modelle immer größer werden. Während sich die öffentliche Meinung verschärft, hat OpenAI-CEO Sam Altman gerade auf der X-Plattform geantwortet:
„Es gibt keine Mauer, es gibt keine Mauer“
Im Rahmen dieser Debatte enthüllte Bloomberg eine bemerkenswerte Neuigkeit.
OpenAI plant die Einführung eines KI-Agenten namens „Operator“ im Januar nächsten Jahres. Dieser Agent kann Computer verwenden, um Aufgaben im Namen von Benutzern auszuführen, beispielsweise das Schreiben von Code oder das Buchen von Reisen.
Zuvor wurde bekannt, dass auch Anthropic, Microsoft und Google in ähnliche Richtungen planen.
Für die gesamte KI-Branche war die Entwicklung der KI-Technologie nie ein eindimensionaler linearer Prozess. Wenn eine Richtung auf Widerstand zu stoßen scheint, bricht Innovation oft in anderen Dimensionen durch.
Skalierungsgesetze Stoßen Sie an eine Wand? Was als nächstes zu tun ist
Die Nachricht, dass Scaling Laws erstmals auf Engpässe gestoßen sei, stammt aus einem Bericht der ausländischen Medien The Information vom vergangenen Wochenende.
Der eloquente Bericht aus Tausenden von Wörtern enthüllte zwei wichtige Informationen.
Die gute Nachricht ist, dass OpenAI zwar 20 % des Trainingsprozesses des nächsten Generationsmodells Orion abgeschlossen hat, Altman sagte jedoch, dass Orion in Bezug auf Intelligenz und Fähigkeit, Aufgaben auszuführen und Fragen zu beantworten, bereits auf Augenhöhe mit GPT-4 sei.
Die schlechte Nachricht ist, dass Orion laut der Bewertung von OpenAI-Mitarbeitern, die es verwendet haben, im Vergleich zu den enormen Fortschritten zwischen GPT-3 und GPT-4 kleinere Verbesserungen aufweist, beispielsweise eine schlechte Leistung bei Aufgaben wie der Programmierung, und höher Betriebskosten.
In einem Satz ist Scaling Laws auf einen Engpass gestoßen.

Um zu verstehen, welche Auswirkungen es hat, wenn die Skalierungsgesetze nicht so gut sind wie erwartet, müssen wir Freunden, die damit nicht vertraut sind, kurz die Grundkonzepte der Skalierungsgesetze vorstellen.
Im Jahr 2020 schlug OpenAI erstmals Skalierungsgesetze in einem Papier vor.
Diese Theorie weist darauf hin, dass die endgültige Leistung eines großen Modells hauptsächlich vom Rechenumfang, der Menge der Modellparameter und der Menge der Trainingsdaten abhängt und grundsätzlich nichts mit der spezifischen Struktur des Modells (Anzahl der Schichten) zu tun hat /Tiefe/Breite).
Es klingt etwas umständlich, aber menschlich gesehen wird die Leistung großer Modelle entsprechend steigen, wenn die Modellgröße, das Trainingsdatenvolumen und die Rechenressourcen zunehmen.
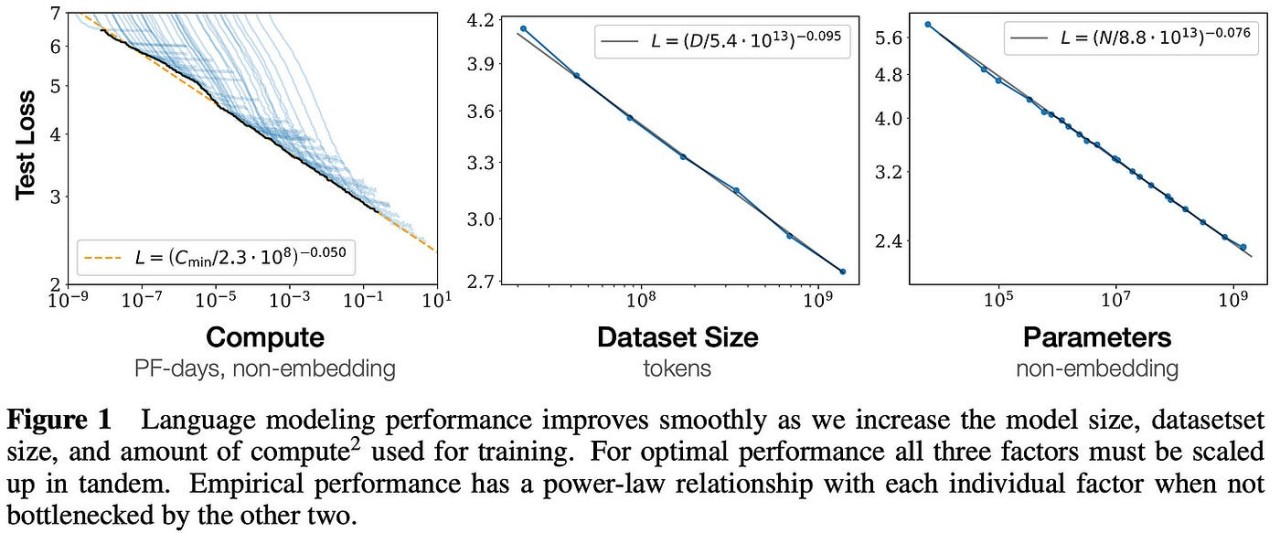
Diese Forschung von OpenAI legte den Grundstein für die spätere Entwicklung großer Modelle. Sie trug nicht nur zum Erfolg der GPT-Modellreihe bei, sondern lieferte auch wichtige Leitprinzipien für die Optimierung des Modelldesigns und des Trainings für das ChatGPT-Training.
Während wir jedoch noch über GPT-100 nachdenken, deuten die Enthüllungen von The Information darauf hin, dass eine einfache Vergrößerung der Modellgröße keine lineare Verbesserung der Leistung mehr garantieren kann und mit hohen Kosten und erheblich abnehmenden Grenznutzen einhergeht.
Und OpenAI ist nicht der Einzige, der Schwierigkeiten hat.
Bloomberg zitierte mit der Angelegenheit vertraute Personen mit der Aussage, dass Gemini 2.0 im Besitz von Google ebenfalls die erwarteten Ziele nicht erreicht habe. Gleichzeitig habe sich auch die Veröffentlichungszeit von Claude 3.5 Opus im Besitz von Anthropic wiederholt verzögert.
In der KI-Branche, die im Wettlauf mit der Zeit ist, bedeuten neue Nachrichten ohne Produkt oft die größte schlechte Nachricht.

Es muss klar sein, dass der hier erwähnte Engpass der Skalierungsgesetze nicht das Ende der Entwicklung großer Modelle bedeutet. Das tiefer liegende Problem besteht darin, dass hohe Kosten zu erheblich sinkenden Grenznutzenrenditen führen.
Dario Amodei, CEO von Anthropic, gab einmal bekannt, dass die Schulungskosten mit zunehmender Größe der Modelle explodiert sind und die Schulungskosten des derzeit entwickelten KI-Modells bis zu 1 Milliarde US-Dollar betragen.
Amodei wies auch darauf hin, dass die Kosten für die KI-Ausbildung in den nächsten drei Jahren auf astronomische Zahlen von 10 bis 100 Milliarden US-Dollar steigen werden.
Am Beispiel der GPT-Serie betragen die einzelnen Schulungskosten allein für GPT-3 etwa 1,4 Millionen US-Dollar. Diese Ausgaben resultieren hauptsächlich aus dem Verbrauch leistungsstarker Rechenressourcen, insbesondere der Verwendung von GPUs, und enormen Stromausgaben.
Allein das Training von GPT-3 verbrauchte 1287 MWh Strom.

Letztes Jahr haben Untersuchungen der University of California, Riverside gezeigt, dass ChatGPT 500 Milliliter Wasser pro 25–50 Fragen verbraucht, die es mit Benutzern kommuniziert. Schätzungen zufolge könnte der jährliche Bedarf an sauberem Süßwasser für die globale KI bis 2027 4,2–6,6 erreichen Milliarden Kubikmeter, das entspricht dem jährlichen Wasserverbrauch von 4-6 Dänemark oder der Hälfte des Vereinigten Königreichs.
Von GPT-2 über GPT-3 bis hin zu GPT-4 war die durch KI erzielte Erfahrungsverbesserung sprunghaft.
Gerade aufgrund dieser bemerkenswerten Fortschritte werden große Unternehmen massiv in den Bereich KI investieren. Wenn dieser Weg jedoch allmählich zu Ende geht, kann die bloße Erweiterung des Modellmaßstabs keine signifikante Leistungsverbesserung mehr garantieren. Hohe Kosten und sinkende Grenzvorteile sind eine Realität, der man sich stellen muss.
Anstatt blind nach Skalierung zu streben, ist es jetzt wichtiger, die Skalierung in die richtige Richtung umzusetzen.
Auf Wiedersehen, GPT; hallo, Begründung „O“
Jeder lehnt die Mauer ab, sogar die Theorie.
Als die Nachricht, dass bei Scaling Laws ein Engpass vermutet wurde, für Aufruhr in der KI-Kreis sorgte, häuften sich auch die Stimmen des Zweifels.
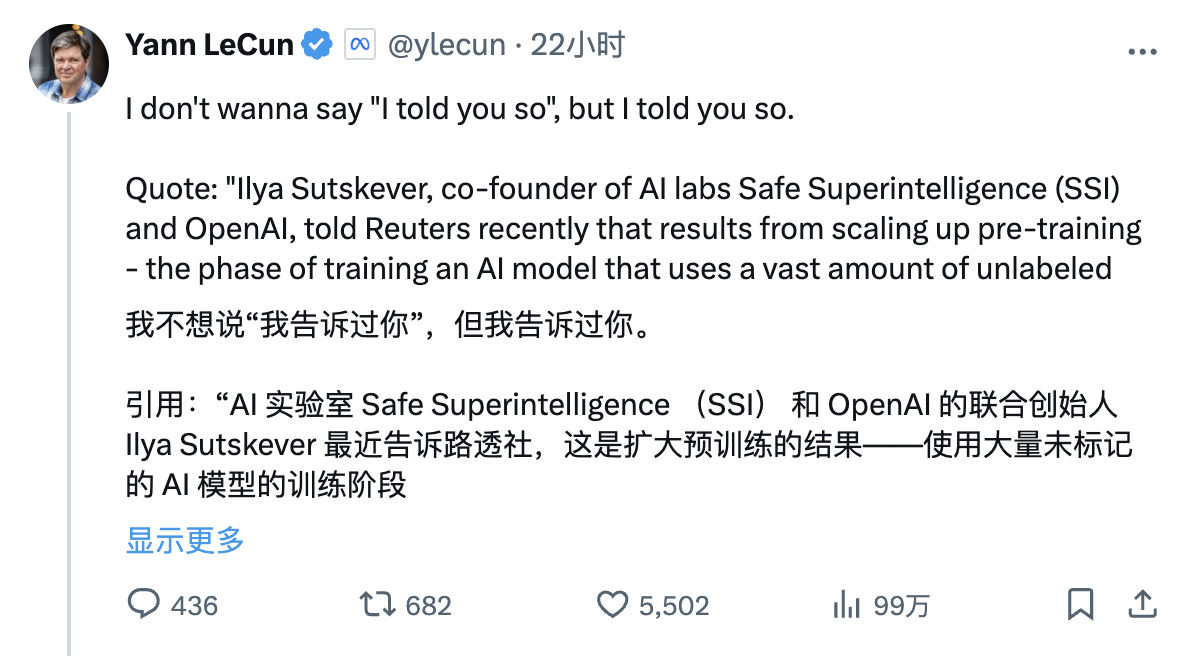
Yann Lecun, Gewinner des Turing Award und Chefwissenschaftler von Meta AI, der schon immer eine Anti-Mainstream-Haltung vertrat, veröffentlichte gestern aufgeregt das Interview von Reuters mit Ilya Sutskever auf der X-Plattform mit dem folgenden Artikel:
„Ich möchte nicht wie ein nachträglicher Einfall klingen, aber ich habe Sie daran erinnert.
Zitat: „Ilya Sutskever, Mitbegründer der KI-Labore Safe Superintelligence (SSI) und OpenAI, sagte kürzlich gegenüber Reuters, dass durch die Ausweitung der Vortrainingsphase – das heißt durch die Verwendung großer Mengen unbeschrifteter Daten, um KI-Modelle zu trainieren, Sprachmuster zu verstehen und …“ Strukturen – die Ergebnisse sind ins Stocken geraten.“
Rückblickend auf die Bewertung der aktuellen großen Modellroute durch den KI-Riesen in den vergangenen zwei Jahren kann man sagen, dass jedes Wort akribisch und jeder Satz blutig ist.
Die heutige KI ist beispielsweise dümmer als eine Katze, und ihre Intelligenz ist weit zurückgeblieben. LLM hat keine direkte Erfahrung mit der physischen Welt und manipuliert nur Texte und Bilder, ohne die Welt wirklich zu verstehen eine Sackgasse usw.
Vor zwei Monaten drehte Yann Lecun die Zeit zurück und verurteilte die aktuelle Mainstream-Linie kurzerhand zum Tode. Unter den vielen KI-Weltuntergangstheorien ist er auch fest davon überzeugt, dass Behauptungen, dass KI das Überleben der Menschheit bedrohen wird, reiner Unsinn sind:
- Große Sprachmodelle (LLMs) können keine Fragen beantworten, die nicht in ihren Trainingsdaten enthalten sind.
- Sie können schwierige Probleme nicht lösen, für die sie nicht ausgebildet sind,
- Sie können ohne erhebliche menschliche Hilfe keine neuen Fähigkeiten oder Kenntnisse erlernen.
- Sie können keine neuen Dinge erschaffen. Derzeit sind große Sprachmodelle nur ein Teil der Technologie der künstlichen Intelligenz. Eine bloße Skalierung dieser Modelle wird sie dazu nicht in der Lage machen.

Dr. Tian Yuandong, der auch bei Meta FAIR arbeitet, hat das aktuelle Dilemma schon früher vorhergesehen.
In einem Interview mit den Medien im Mai sagte der chinesische Wissenschaftler einmal pessimistisch, dass Scaling Laws zwar richtig seien, aber nicht alles seien. Seiner Ansicht nach besteht der Kern der Skalierungsgesetze darin, exponentielles Datenwachstum gegen „einige Gewinnpunkte“ einzutauschen.
„Letztendlich hat die menschliche Welt möglicherweise viele langfristige Bedürfnisse, die eine schnelle Reaktion der Menschen erfordern. Die Daten selbst in diesen Szenarien sind sehr klein und LLM kann sie nicht erfassen. Am Ende, wenn sich das Skalierungsgesetz entwickelt, kann es jeder tun.“ auf den gleichen „Daten“ stehen Auf der „isolierten Insel“ gehören die Daten auf der isolierten Insel vollständig jedem und werden in jedem Moment ständig generiert. Experten lernen, sich mit KI zu integrieren und werden sehr mächtig, und KI kann sie nicht ersetzen. "

Allerdings ist die Situation möglicherweise noch nicht so pessimistisch.
Objektiv gesehen gab Ilya in einem Interview mit Reuters zu, dass die durch die Scaling Laws erzielten Fortschritte ins Stocken geraten seien, erklärte jedoch nicht ihr Ende.
„Die 2010er Jahre waren die Ära der Skalierung, und jetzt treten wir wieder in eine neue Ära der Wunder und Entdeckungen ein. Jetzt ist die Auswahl der richtigen Dinge für die Skalierung wichtiger denn je wichtig."
Darüber hinaus sagte Ilya auch, dass SSI eine neue Methode erforscht, um den Vorschulungsprozess zu erweitern.
Auch Dario Amodei hat kürzlich in einem Podcast darüber gesprochen.
Er sagt voraus, dass es keine absolute Obergrenze für Modelle unterhalb der menschlichen Ebene gibt. Da das Modell noch nicht das menschliche Niveau erreicht hat, kann man nicht sagen, dass die Skalierungsgesetze gescheitert sind, sondern dass es tatsächlich zu einer Verlangsamung des Wachstums gekommen ist.

Seit der Antike haben sich die Berge nicht verändert und das Wasser hat sich verändert, und das Wasser hat sich nicht verändert und die Menschen haben sich verändert.
Letzten Monat sagte der OpenAI-Forscher Noam Brown auf der TED AI-Konferenz:
„Es stellt sich heraus, dass die Aufforderung an einen Roboter, während eines Pokerspiels 20 Sekunden lang nachzudenken, die gleiche Leistungsverbesserung bringt, als wenn man das Modell 100.000 Mal skaliert und es 100.000 Mal länger trainiert.“
Was Yann Lecuns gestrige Rückblicksbemerkung betrifft, antwortete er folgendermaßen:
„Im Moment befinden wir uns in einer Welt, in der, wie ich bereits sagte, der Rechenaufwand für den Einstieg in ein umfangreiches Sprachmodell vor dem Training sehr, sehr hoch ist, aber die Kosten für die Inferenz sind sehr niedrig Viele Leute waren zu Recht besorgt, dass die Kosten und die Datenmenge, die für das Training erforderlich sind, so groß werden, dass die Fortschritte in der KI abnehmen werden. Aber ich denke, eine der wirklich wichtigen Erkenntnisse von o1 ist dass diese Mauer nicht existiert und wir diesen Prozess tatsächlich weiter vorantreiben können, denn jetzt können wir das Inferenzrechnen erweitern, und es gibt riesigen Raum für eine Erweiterung des Inferenzrechnens.“
Die von Noam Brown vertretenen Forscher sind fest davon überzeugt, dass die Inferenz-/Testzeitberechnung wahrscheinlich ein weiteres Allheilmittel für die Verbesserung der Modellleistung sein wird.
Apropos, wir müssen das bekannte OpenAI o1-Modell erwähnen.
Ganz ähnlich wie beim menschlichen Denken kann das o1-Modell durch mehrstufiges Denken über Probleme nachdenken. Es legt Wert darauf, dem Modell während der Argumentationsphase mehr „Denkzeit“ zu geben. Sein Kerngeheimnis besteht darin, dass es in einem Netzwerk wie GPT-4 zusätzliches Training gibt auf dem Basismodell.
Beispielsweise können Modelle letztendlich den besten Weg nach vorne wählen, indem sie mehrere mögliche Antworten in Echtzeit generieren und auswerten, anstatt sofort eine einzelne Antwort auszuwählen. Dadurch können mehr Rechenressourcen auf komplexe Aufgaben wie mathematische Probleme und Programmierrätsel konzentriert werden oder jene komplexen Vorgänge, die menschenähnliches Denken und Entscheidungsfindung erfordern.

Google ist diesem Weg kürzlich gefolgt.
The Information berichtet, dass DeepMind in den letzten Wochen innerhalb seiner Gemini-Abteilung ein Team unter der Leitung des Chefforschungswissenschaftlers Jack Rae und des ehemaligen Character.AI-Mitbegründers Noam Shazeer gebildet hat, um ähnliche Fähigkeiten zu entwickeln.
Gleichzeitig versucht Google, um sich nicht übertrumpfen zu lassen, neue technische Wege, einschließlich der Anpassung von „Hyperparametern“, also Variablen, die bestimmen, wie das Modell Informationen verarbeitet, etwa wie schnell es Verbindungen zwischen verschiedenen Konzepten oder Mustern im Training herstellt Daten und sehen Sie, welche Variablen zu den besten Ergebnissen führen.
Nebenbei bemerkt: Ein wichtiger Grund für die Verlangsamung der GPT-Entwicklung ist der Mangel an qualitativ hochwertigem Text und anderen verfügbaren Daten.
Als Reaktion auf dieses Problem hofften Google-Forscher ursprünglich, mithilfe von KI Daten zu synthetisieren und Audio und Video in die Trainingsdaten von Gemini zu integrieren, um erhebliche Verbesserungen zu erzielen, doch diese Versuche schienen wenig Wirkung zu haben.
Mit der Angelegenheit vertraute Personen verrieten außerdem, dass auch OpenAI und andere Entwickler synthetische Daten verwenden. Allerdings stellten sie auch fest, dass die Wirkung synthetischer Daten auf die Verbesserung von KI-Modellen sehr begrenzt ist.
Hallo Jarvis
Auf Wiedersehen GPT, hallo Argumentation „o“.
In einer kürzlichen Reddit-AMA-Veranstaltung fragte ein Internetnutzer Altman, ob „GPT-5“ und eine vollständige Version des Inferenzmodells o1 veröffentlicht werden.
Damals antwortete Altman: „Wir priorisieren die Einführung von o1 und seinen Folgeversionen“ und fügte hinzu, dass begrenzte Rechenressourcen es schwierig machen, mehrere Produkte gleichzeitig auf den Markt zu bringen.
Er betonte außerdem, dass das Modell der nächsten Generation möglicherweise nicht weiterhin „GPT“ heißen dürfe.

Nun scheint Altman bestrebt zu sein, eine klare Grenze zum GPT-Namenssystem zu ziehen und stattdessen ein Inferenzmodell mit dem Namen „o“ einzuführen. Dahinter scheint eine tiefe Bedeutung zu stecken. Das Layout des Inferenzmodells könnte immer noch die Grundlage für den aktuellen Mainstream-Agenten bilden.
Kürzlich sprach Altman in einem Interview mit Y Combinator-Präsident Garry Tan auch noch einmal über die Fünf-Ebenen-AGI-Theorie:
- L1: Chat-Roboter sind KI mit Konversationsfunktionen, die reibungslose Gespräche mit Benutzern führen, Informationen bereitstellen, Fragen beantworten, bei der Erstellung helfen usw. können, wie zum Beispiel Chat-Roboter.
- L2: KI, deren Denker Probleme wie Menschen lösen können, komplexe Probleme ähnlich wie menschliche Doktoranden lösen können und leistungsstarke Argumentations- und Problemlösungsfähigkeiten demonstrieren, wie z. B. OpenAI o1.
- L3: Ein KI-System, in dem der Agent nicht nur denken, sondern auch handeln und vollautomatische Geschäfte abwickeln kann.
- L4: KI, die Innovatoren bei Erfindungen und Kreationen unterstützen kann, verfügt über die Fähigkeit zur Innovation und kann Menschen bei der Generierung neuer Ideen und Lösungen in Bereichen wie wissenschaftlicher Entdeckung, künstlerischem Schaffen oder technischem Design unterstützen.
- L5: KI, die von Organisatoren zur Erledigung organisatorischer Arbeit eingesetzt werden kann, kann die Planung, Ausführung, Rückmeldung, Iteration, Ressourcenzuweisung, Verwaltung usw. der geschäftsübergreifenden Prozesse der gesamten Organisation automatisch steuern. Sie ähnelt im Grunde dem Menschen.
Wir sehen also, dass OpenAI, wie Google und Anthropic, seinen Fokus nun von Modellen auf eine Reihe von KI-Tools namens Agents verlagert.
Kürzlich gab Bloomberg außerdem bekannt, dass OpenAI die Einführung eines neuen KI-Agenten namens „Operator“ vorbereitet, der mithilfe von Computern Aufgaben im Namen von Benutzern ausführen kann, beispielsweise das Schreiben von Code oder das Buchen von Reisen.
Bei einer Mitarbeiterversammlung am Mittwoch kündigte die Führung von OpenAI Pläne an, im Januar eine Forschungsvorschau des Tools zu veröffentlichen und es Entwicklern über die Anwendungsprogrammierschnittstelle (API) des Unternehmens zur Verfügung zu stellen.
Zuvor hat Anthropic auch einen ähnlichen Agenten auf den Markt gebracht, der Computeraufgaben des Benutzers in Echtzeit verarbeiten und in seinem Namen Vorgänge ausführen kann. Gleichzeitig hat Microsoft kürzlich eine Reihe von Agent-Tools für Mitarbeiter zum Versenden von E-Mails und zum Verwalten von Datensätzen auf den Markt gebracht.

Google bereitet außerdem die Einführung eines eigenen KI-Agenten vor.
Der Bericht enthüllte auch, dass OpenAI mehrere Forschungsprojekte im Zusammenhang mit Agenten durchführt. Der Fertigstellung am nächsten kommt ein universelles Tool, das Aufgaben in einem Webbrowser ausführen kann.
Von diesen Agenten wird erwartet, dass sie in der Lage sind, zu verstehen, zu argumentieren, zu planen und Maßnahmen zu ergreifen. Tatsächlich handelt es sich bei diesen Agenten jedoch um ein System, das aus mehreren KI-Modellen besteht, und nicht um ein einzelnes Modell.
Bill Gates sagte einmal: „Auf jedem Desktop steht ein PC“, und Steve Jobs sagte: „Jeder hat ein Smartphone in der Hand.“ Jetzt können wir mutig vorhersagen: Jeder wird seinen eigenen KI-Agenten haben.
Natürlich besteht das ultimative Ziel der Menschheit darin, dass wir hoffen, dass wir eines Tages den klassischen Filmdialog mit der KI vor uns sprechen können:
Hallo Jarvis
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo