
Stable Diffusion und große End-to-Side-Modelle auf dünnen und leichten Notebooks ausführen? Laut Intel kein Problem

Egal ob passiv oder aktiv, Substantive wie Big Model, AIGC, ChatGPT, Stable Diffusion, MidJourney usw. werden in jeder Nachrichtenliste bombardiert. Nach den Überraschungen, Panik, Erwartungen und Sorgen in der ersten Jahreshälfte ist AIGC die Nr. 1 Es war kein Wunder mehr. Das Evangelium oder die Wiederkunft Skynets – die Menschen begannen, sich ihm direkt zu stellen, es zu verstehen und es angemessen zu nutzen.
Natürlich findet diese Runde der AIGC-Welle hauptsächlich in der Cloud statt, sei es ChatGPT oder Wenxin Yiyan, Tongyi Qianwen und andere große Sprachmodellanwendungen oder MidJourney und andere KI-generierte Bildanwendungen, es gibt viele wie KI-generierte Videos Anwendungen wie Runway müssen mit dem Internet verbunden sein, da KI-Berechnungen auf Cloud-Servern erfolgen, die Tausende von Kilometern entfernt liegen.
Schließlich sind die Rechenleistung und der Speicher, die vom Server bereitgestellt werden können, im Allgemeinen viel größer als die des Computers und des mobilen Endes, aber die Situation ist nicht absolut. Endseitige KI mit schneller Reaktion und keinem Bedarf Denn Vernetzung ist zweifellos ein weiterer Trend, und Cloud-KI kann sich gegenseitig ergänzen.
In Xiaomis jährlicher Rede vor nicht allzu langer Zeit sagte Xiaomi-Gründer Lei Jun, dass das neueste 1,3-Milliarden-Parameter-Modell des Xiaomi-KI-Modells erfolgreich lokal auf dem Mobiltelefon ausgeführt wurde und einige Szenarien mit den Ergebnissen des laufenden 6-Milliarden-Parameter-Modells verglichen werden können auf der Wolke.
Obwohl die Anzahl der Parameter nicht allzu groß ist, veranschaulicht sie die Machbarkeit und das Potenzial des großen End-to-Side-Modells.
Gibt es auf der PC-Seite mit einer viel größeren Rechenleistung auch die Machbarkeit und das Potenzial von AIGC-Anwendungen wie großen Modellen auf der Geräteseite? Am 18. August veranstaltete Intel eine Sitzung zum Technologieaustausch, bei der es um den Austausch von zwei Informationsaspekten ging: Leistungsupdates für Intel Sharp Graphics DX11 und die Einführung des neuen Intel PresentMon Beta-Tools sowie um die Darstellung von Intels Fortschritten im AIGC-Bereich.

Als Intels Sharp-Desktop-Produkte letztes Jahr auf den Markt kamen, wurde versprochen, dass die Intel Sharp-Grafikkarten weiterhin optimiert und aktualisiert würden, um ein besseres Erlebnis zu bieten.
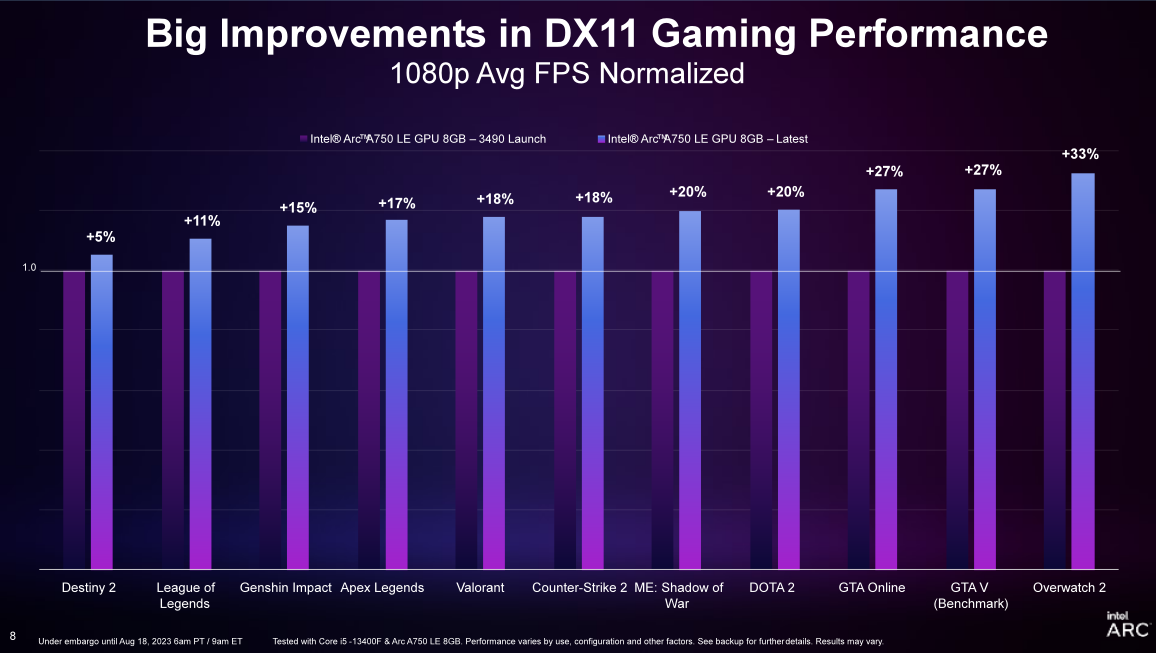
Durch die Veröffentlichung des neuesten Game On-Treibers kann Intel Ruixuan Graphics bei der Ausführung einer Reihe von DX11-Spielen eine Steigerung der Bildrate um 19 % und eine durchschnittliche Verbesserung der Bildratenflüssigkeit um etwa 20 % im 99. Perzentil (im Vergleich zur ersten Treiberversion) erreichen. . Benutzer, die die Intel Sharp A750-Grafikkarte bereits gekauft und verwendet haben, können den neuesten Treiber direkt herunterladen und Erlebnis-Upgrades in Spielen wie Overwatch 2, DOTA 2 und Apex Legends erhalten.
Für Benutzer, die bei der Auswahl einer Grafikkarte etwas zögern, ist die Ruixuan A750-Grafikkarte im 1700-Yuan-Bereich ebenfalls eine recht konkurrenzfähige Wahl.
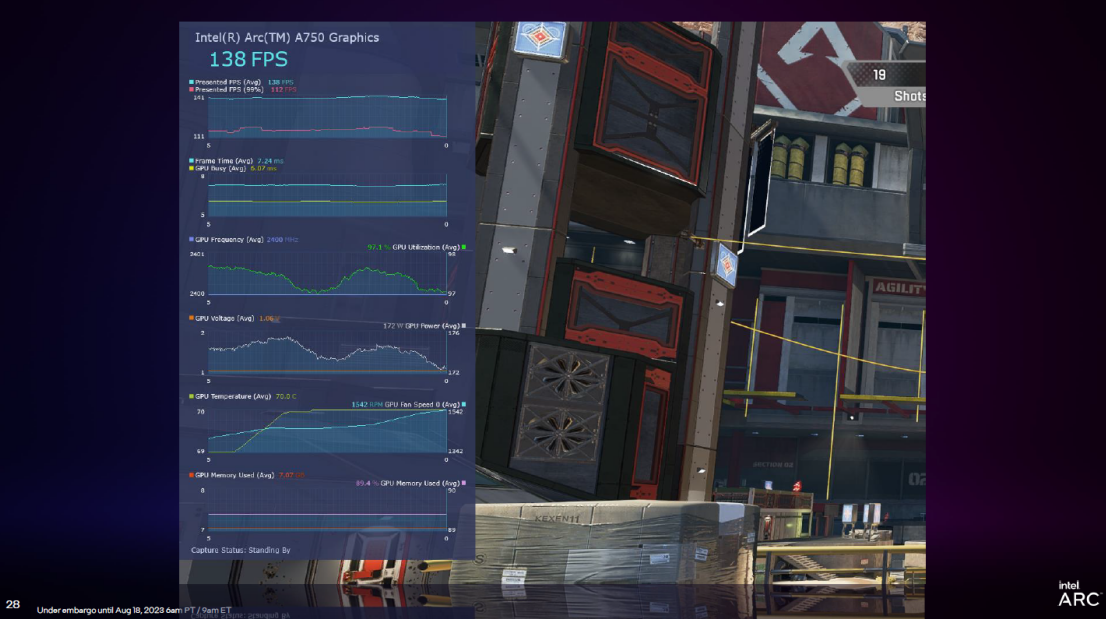
PresentMon Beta ist ein von Intel eingeführtes Tool zur Analyse der Grafikleistung. Es bietet Funktionen wie Overlay (Overlay-Ansicht), mit denen Leistungsdaten auf dem Bildschirm angezeigt werden können, während das Spiel ausgeführt wird, und Spielern dabei helfen, die Spannung und Temperatur der GPU in Echtzeit zu telemetrieren und analysieren Sie eine große Menge an Informationen in Echtzeit. Schauen Sie sich auch das Diagramm „Framezeit im Vergleich zur GPU-Auslastung“ des 99. Perzentils an.
Darüber hinaus bringt PresentMon Beta auch einen neuen Indikator namens „GPU Busy“. Hier ist eine Erklärung, damit Benutzer sehen können, wie viel Zeit die GPU tatsächlich für das eigentliche Rendern verwendet, anstatt zu warten, oder ob sich der PC, auf dem das Spiel ausgeführt wird, im CPU- und GPU-Gleichgewicht befindet.
Spiele sind ein ewiges Thema des PCs, während KI ein neues Thema ist.
Tatsächlich ist die Hauptausrüstung für diese Runde der AIGC-Welle der PC, sei es ChatGPT, MidJourney oder Stable Diffusion und andere Anwendungen, einschließlich Microsoft Office Copilot basierend auf großen Modellen oder WPS AI von Kingsoft Office. Eine bessere Erfahrung ist auf dem PC.
Im Vergleich zu anderen Geräten wie Mobiltelefonen, Tablets und PCs liegen die Vorteile von PCs jedoch nicht nur in größeren Bildschirmen und effizienteren interaktiven Eingaben, sondern auch in der Chipleistung.
Bevor Intel über AIGC auf PCs sprach, stellten wir fest, dass beim parallelen Betrieb von AIGC auf PCs häufig Hochleistungs-Gaming-Notebooks zum Ausführen von Grafiken verwendet werden, dünne und leichte Notebooks jedoch häufig ausgeschlossen werden.
Jetzt hat Intel klar erklärt, dass der auf Intel-Prozessoren basierende dünne und leichte Instinkt große Modelle ausführen kann und auch große Modelle und stabile Diffusion ausführen kann.
Intels Back-End-Lösung basiert auf OpenVINO PyTorch (einem von Intel eingeführten Open-Source-Toolkit zur Optimierung der Inferenzleistung von Deep-Learning-Modellen und deren Bereitstellung auf verschiedenen Hardwareplattformen). Über die Pytorch-API kann das Community-Open-Source-Modell gut ausgeführt werden Client-Prozessoren, integrierte Grafikkarten, separate Grafikkarten und dedizierte KI-Engines von Intel.
Beispielsweise kann das Open-Source-Bilderzeugungsmodell Stable Diffusion (insbesondere Automatic1111 WebUI) auf diese Weise FP16-Präzisionsmodelle auf Intel-CPUs und GPUs (einschließlich integrierter Grafikkarten und diskreter Grafikkarten) ausführen und Benutzer können Text und Bilder generieren . Funktionen wie Bildgenerierung und Teilreparatur.

▲ Bild von: Aijiwu
Dieses Honigpfannkuchenbild mit einer Auflösung von 512 x 512 kann beispielsweise in nur einem Dutzend Sekunden auf einem dünnen und leichten Notebook mit Intel-Prozessor erstellt werden (nur mit dem i7-13700H-Kerndisplay).
Dies ist hauptsächlich auf die Fortschritte des Core-Prozessors der 13. Generation in Bezug auf Kernanzahl, Leistung, Stromverbrauchsverhältnis und Grafikleistung zurückzuführen. Am Beispiel des i7-13700H-Prozessors mit 14 Kernen und 20 Threads hat seine TDP 45 W erreicht, und die Nicht zu unterschätzen ist auch die integrierte Grafikkarte Intel Iris Xe Graphics (96EU).
Intel Iris , und die INT8-Ganzzahlberechnung wird ebenfalls eingeführt Fähigkeit, diese hat seine KI-Grafik-Computing-Fähigkeiten verbessert und ist auch der Hauptgrund, warum Intels dünne und leichte Bücher Stable Diffusion gut unterstützen können.
In der Vergangenheit ließen sich Intel-Prozessoren mit einer TDP von etwa 45 W nur schwer in dünne und leichte Notebooks einbauen, aber mit der 13. Core-Generation gab es eine große Anzahl dünner und leichter Notebooks mit etwa 1,4 kg, 14 Kernen, 20 Threads i7-13700H-Prozessoren und noch höhere Leistung. Der i7-13900H-Prozessor ist angeschlossen, sodass die Ausführung von Stable Diffusion auf einem Notebook zur schnellen Ausgabe von Bildern nicht mehr nur Hochleistungs-Gaming-Notebooks vorbehalten ist, sondern auch dünne und leichte Notebooks können mache diesen Job in Zukunft.
Natürlich wird Stable Diffusion selbst hauptsächlich lokal ausgeführt, und es ist logisch, dass dünne und leichte Notebooks die Chipleistung verbessern und optimieren, aber das lokale End-Side-Großmodell ist eine relativ neue Sache.
Durch die Modelloptimierung wird der Bedarf des Modells an Hardwareressourcen reduziert, wodurch die Inferenzgeschwindigkeit des Modells verbessert wird, und Intel ermöglicht die gute Ausführung einiger Community-Open-Source-Modelle auf PCs.
Am Beispiel des großen Sprachmodells nutzt Intel die Beschleunigung des Intel Core Prozessors XPU der 13. Generation, Low-Bit-Quantisierung und andere Optimierungen auf Softwareebene, um die Ausführung eines großen Sprachmodells mit bis zu 16 Milliarden Parametern auf 16 GB zu ermöglichen das BigDL-LLM-Framework. auf einem Personal Computer mit Speicherkapazität und mehr.
Obwohl es eine Größenordnungslücke zu den 175 Milliarden Parametern von ChatGPT3.5 gibt, läuft ChatGPT3.5 schließlich auf einem AGI-Netzwerkcluster, der mit 10.000 NVIDIA V100-Chips aufgebaut ist. Und dieses große Modell mit 16 Milliarden Parametern, die über das BigDL-LLM-Framework laufen, läuft auf einem Prozessor wie Intel Core i7-13700H oder i7-13900H, der für leistungsstarke, dünne und leichte Notebooks konzipiert ist.
Allerdings ist auch hier zu erkennen, dass das große Sprachmodell auf der PC-Seite ebenfalls um eine Größenordnung höher ist als das auf der Mobiltelefonseite.
PCs, die es schon seit Jahrzehnten gibt, sind keine Tools für den Betrieb großer Modelle in der Cloud. Dank der Hardware-Fortschritte konnten PCs, die von Intel-Prozessoren unterstützt werden, schnell eine Verbindung zu neuen Modellen herstellen und sind mit Transformers-Modellen auf HuggingFace kompatibel. Modelle, die es gab Zu den bisher verifizierten zählen unter anderem: LLAMA/LLAMA2, ChatGLM/ChatGLM2, MPT, Falcon, MOSS, Baichuan, QWen, Dolly, RedPajama, StarCoder, Whisper usw.
▲ Bild von: Aijiwu
Auf dem Technologieaustauschtreffen demonstrierte Intel die Leistung eines großen Modells auf Basis des Core i7-13700H-Geräts: ChatGLM-6b kann die erste Latenz der ersten Token-Generierung von 241,7 ms erreichen, und die durchschnittliche Generierungsrate nachfolgender Token beträgt 55,63 ms /Zeichen. Im Bereich der Verarbeitung natürlicher Sprache bezieht sich „Token“ auf eine Grundeinheit im Text, bei der es sich um ein Wort, ein Wort, ein Unterwort, ein Satzzeichen oder andere kleinste Einheiten handeln kann, die semantisch verarbeitet werden können. Wie Sie sehen, ist die Prozessorgeschwindigkeit recht gut.
Die Nachricht, die noch verfügbar ist, ist, dass Intels Meteor Lake-Prozessor der nächsten Generation über die Vorteile einer einzigartigen separaten Modularchitektur verfügt, um die KI besser zu bedienen, einschließlich Multimedia-Funktionen wie automatisches Reframing und Szenenbearbeitungserkennung in Adobe Premiere Pro, und eine effizientere Maschine zu erreichen Lernbeschleunigung.
Obwohl AIGC ein Schlüsselwort im Jahr 2023 ist, ist KI nicht neu und es ist auch ein Schlüsselwort, über das Intel in den letzten Jahren oft gesprochen hat.
Frühere AI-Videoanruf-Rauschunterdrückung, AI-Videoanruf-Hintergrundgeräuschunterdrückung usw. sind tatsächlich Anwendungen von KI.
Es ist ersichtlich, dass die Wettbewerbsfähigkeit zukünftiger Prozessoren nicht auf die Anzahl der Kerne, die Anzahl der Threads und die Hauptfrequenz beschränkt sein wird – einer der Faktoren, die das Produkt berücksichtigen wird.
#Willkommen, dem offiziellen öffentlichen WeChat-Konto von Aifaner zu folgen: Aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich präsentiert.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo