
Google veröffentlicht „AI Family Bucket“, um GPT-4o entgegenzuwirken! Ein seltenes großes Suchmaschinen-Update, 121 „KI“-Sätze zur Bekämpfung von Angstzuständen

Nachdem OpenAI gestern Abend ChatGPT-4o veröffentlicht hatte, lag der Druck auf Google I/O, als ob Google den Titel „Wang Feng in AI“ auf keinen Fall loswerden könnte.
Google hingegen erwähnte AI 121 Mal und stellte in einer fast zweistündigen Pressekonferenz mehr als zehn neue Produkte und Upgrades vor. Man kann sagen, dass es „groß im Umfang und umfassend im Management“ ist, mit umfassender Berichterstattung Feuerkraft, aber es gibt nicht viele Überraschungen.

Lassen Sie uns zunächst die Höhepunkte dieser Konferenz zusammenfassen. Bitte lesen Sie weiter unten für weitere Funktionsanalysen.
Kernpunkte der Pressekonferenz:
- Google Search AI: Veröffentlichung von AI Overviews, einer erweiterten Version der AI-Suchzusammenfassungsfunktion und mehrstufigen Argumentationsfunktionen.
- Große Gemini-Modelle: Gemini 1.5 Flash (1 Million Kontexte); Gemini Pro (2 Millionen Kontexte).
- Großes Gemma-Modell: Veröffentlichung der multimodalen großen Open-Source-Modelle Pali Gemma und Gemma2.
- KI in Google Workspace: Nutzen Sie die Funktionen und das Sidepanel-Formular von Gemini, um die Produktserien von Google aneinanderzureihen.
- Gemini App: Die mobile Version der Gemini App wird bald Videogespräche mit KI unterstützen und wird in den letzten Wochen veröffentlicht.
- Projekt Astra: Das neueste multimodale KI-Projekt, einschließlich generativer KI für Bilder, Musik und Videos wie Imagen3, Music AI Sandbox und Veo.
Beginnen Sie mit der Suche und verwenden Sie Search King, um zu explodieren
Die Google-Suche ist einer der größten Investitions- und Innovationsbereiche von Google und ihr Gründungsprodukt.

Vor 25 Jahren startete Google die Suche, und heute Abend verschiebt Google erneut die Grenzen der Suche.
Einfach ausgedrückt: Mit der Google-Suche von AIGC können Sie mehr tun:
Was auch immer Sie denken, was auch immer Sie erledigen müssen, fragen Sie einfach danach und die Google-Suche wird es finden.
Alle Weiterentwicklungen der Google-Suche basieren auf dem dafür maßgeschneiderten Gemini-Modell.
Google stellte auf der Pressekonferenz vor, dass die „andere“ Google-Suche drei einzigartige Vorteile hat:
- Die Echtzeitinformationen von Google umfassen mehr als eine Billion Fakten über Menschen, Orte und Dinge
- Ein erstklassiges Produkt und einer der besten Online-Dienste
- Die Kraft der Zwillinge
Durch die Kombination dieser drei Dinge werden die neuen Suchfunktionen von Google freigeschaltet.
Die erste neue Funktion ist AI Review. Benutzer können von großen KI-Modellen generierte Zusammenfassungen oben in den Suchergebnissen erhalten, wodurch der gesamte Suchprozess vereinfacht und das Auffinden komplexer Sachverhalte vereinfacht wird.

Google sagt, dass bis Ende dieses Jahres mehr als eine Milliarde Menschen die AI-Review-Funktion in der Google-Suche nutzen werden, und Google behauptet, dass dies eines der größten Updates seiner Suchmaschine seit 25 Jahren sein wird.
Das mehrstufige Denken ist eine weitere wichtige Funktion der Google-Suche.

Durch das neue mehrstufige Denken wird es für uns sehr einfach, für die Zukunft einige Lebens-, Arbeits- und Reisepläne zu schmieden.
Über die Suchleiste können Sie beispielsweise „das beste Yoga-Studio in der Nähe“ finden und erhalten dann alle wichtigen Informationen wie Bewertungsergebnisse, Kursempfehlungen, Entfernungen etc. zu nahegelegenen Yoga-Studios in Blöcken eingeteilt und übersichtlich dargestellt die Suchergebnisse.
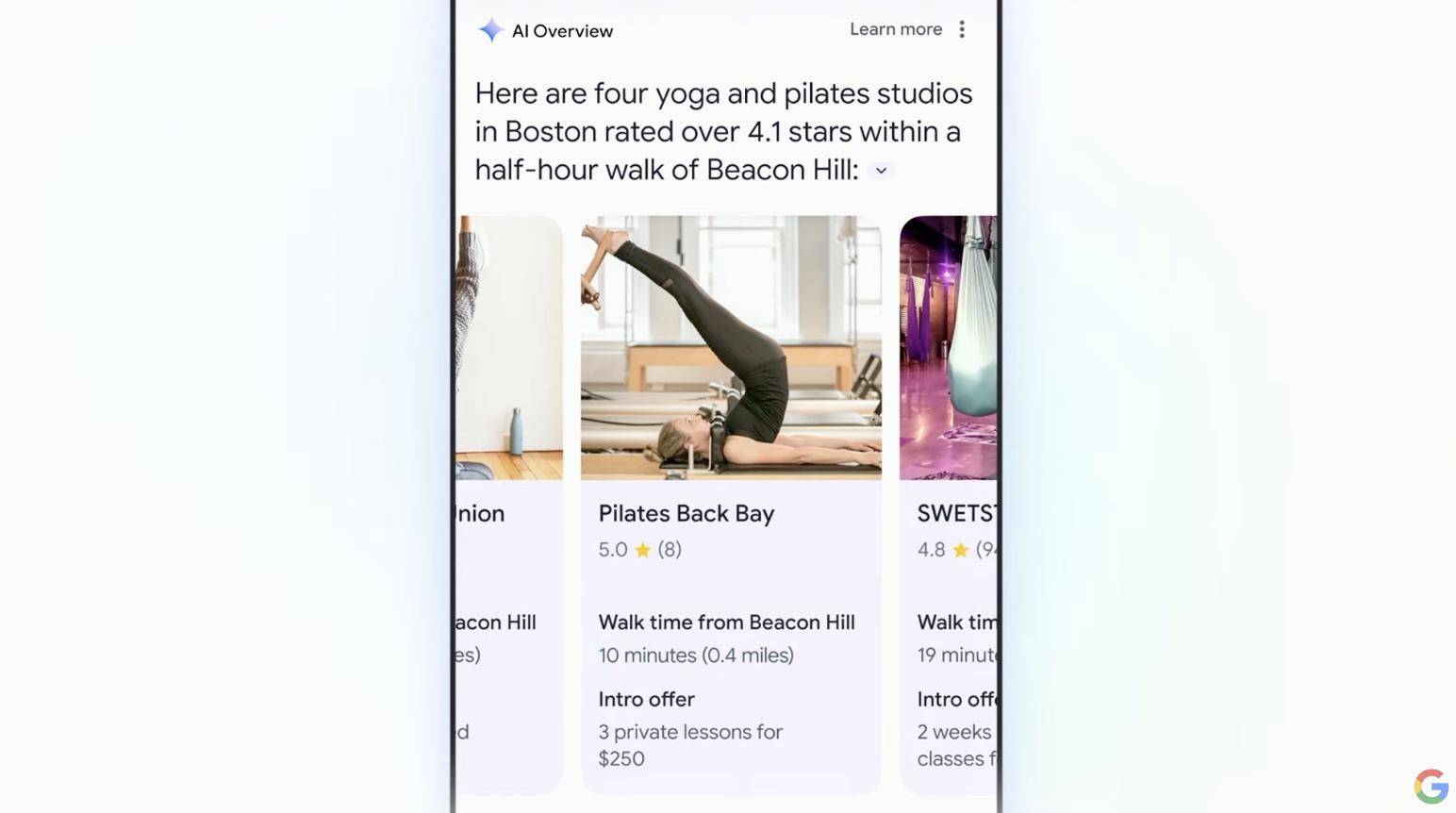
Mithilfe der riesigen Datenbank von Google kann die KI während des Suchvorgangs auf die neuesten und umfassendsten Informationen von hoher Qualität zurückgreifen, sodass die Genauigkeit und Glaubwürdigkeit der Suchergebnisse besser gewährleistet ist.
Derzeit umfasst Google mehr als 250 Millionen Standorte auf der ganzen Welt, die in Echtzeit aktualisiert werden und wichtige Informationen wie Bewertungen, Rezensionen und Geschäftszeiten enthalten.
Planning in Search ist ein weiteres Update, das den Aufwand für Sie verringert.

Nehmen wir an, Sie restrukturieren Ihre Mahlzeiten und planen von Grund auf und möchten zum Frühstück, Mittag- und Abendessen keine Makkaroni und Käse essen.
Geben Sie einfach Ihre Anforderungen in das Suchfeld ein und die Google-Suche liefert Ihnen ein neues wöchentliches Rezept, das Ihren Anforderungen entspricht und sinnvoll arrangiert ist.
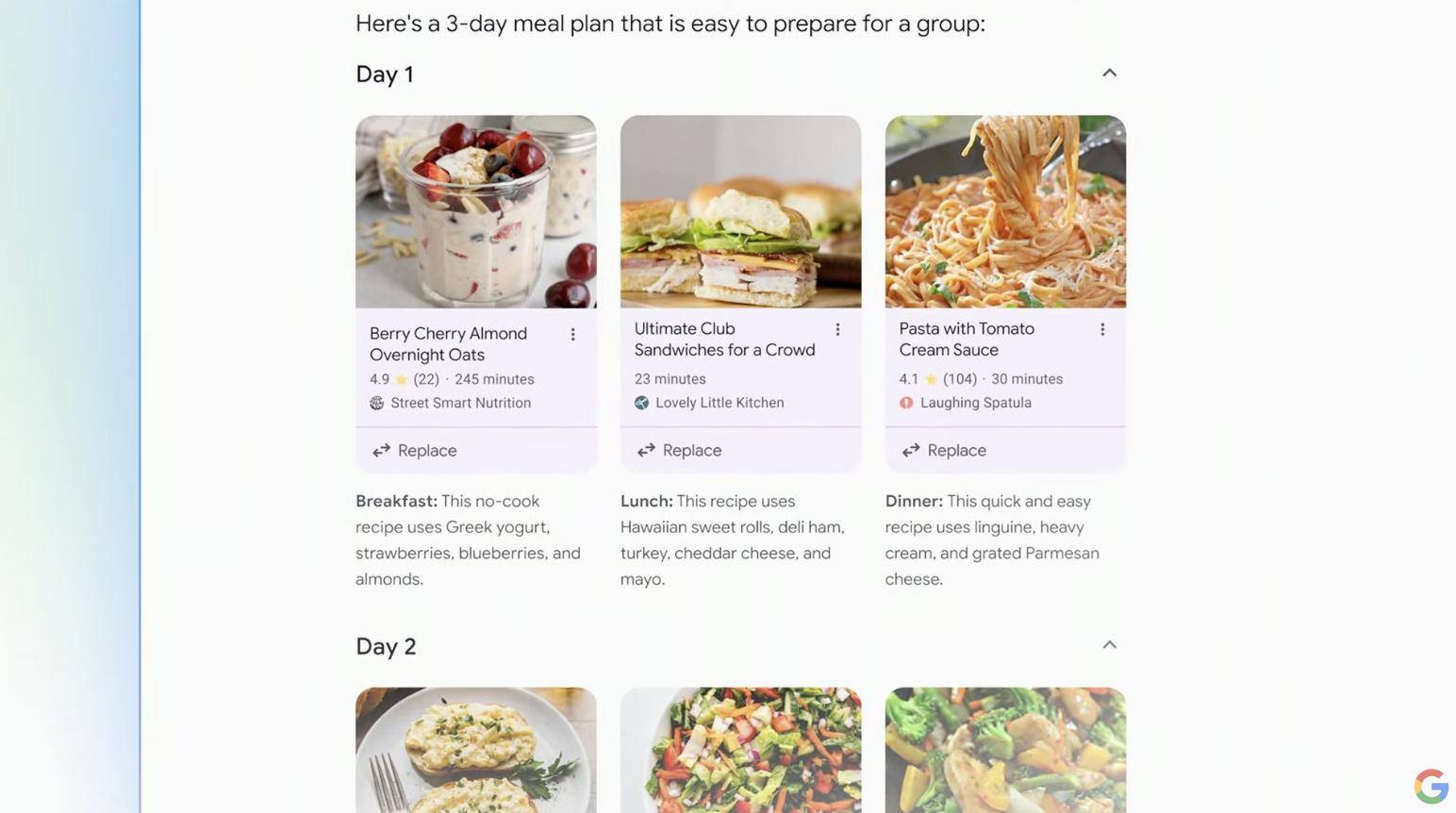
Darüber hinaus können Sie die Bedingungen und Details jederzeit ändern und die Suchergebnisse werden in Echtzeit basierend auf den neuesten Eingabeaufforderungen aktualisiert.
Wenn wir die oben genannten Funktionen in Produkten anderer Unternehmen gesehen oder sogar genutzt haben, wird Ask with Video Sie sicherlich für einige Überraschungen sorgen.
Es gibt viele Gegenstände im Leben, alle mit eigenen, exklusiven Namen. Wenn bei einigen Geräten kleinere Probleme auftreten, gibt es auch entsprechende Reparaturmethoden. Aber in vielen Fällen können das nur Fachleute sagen, und nur sie können „das richtige Medikament verschreiben“.
Durch die Funktion „Fragen mit Video“ der Google-Suche kann nun jeder als Experte bezeichnet werden, was einer Enzyklopädie auf Ihrem Mobiltelefon entspricht.

Die Teile der Aufnahme funktionieren nicht mehr und ich weiß nicht, wo ich anfangen soll. Der Verschluss der Kamera fällt plötzlich aus… Früher musste man sich möglicherweise viel Mühe geben, sie an den Hersteller zurückzusenden für den Kundendienst, aber jetzt können Sie die Linse eines Google-Geräts verwenden, um ein Foto des Problems zu machen, und die Google-Suche kann Ihnen dabei helfen, das Problem vorab zu diagnostizieren und einige kleinere Fehler zu beheben vor Ort bereitgestellt werden.
Bei der Echtzeitdemonstration auf der Pressekonferenz listete die KI auch die gesamten Reparaturschritte einzeln auf. Den Anweisungen auf dem Bildschirm folgend, konnte der Demonstrator die kleineren Probleme schnell beheben.

Diese Funktion verwendet KI, um das Video Bild für Bild zu zerlegen, die Schlüsselinformationen jedes Bildes in das lange Kontaktfenster von Gemini zu importieren, um sie einzeln zu analysieren, und verwandte Artikel, Foren, Videos usw. im Internet zu durchsuchen, um so Erkenntnisse zu gewinnen Umsetzung der intelligenten Vorschläge von Ask with Video.
Im Vergleich zur herkömmlichen Texteingabe besteht der größte Vorteil von Videos darin, dass der Interaktionsprozess zwischen uns und der KI intuitiver wird. Durch die Verwendung vager Wörter wie „hier“ und „dies“ kann das große Modell auch wissen, worauf wir uns beziehen.

Google sagte, dass diese neuesten KI-Funktionen in den nächsten Wochen in der Laborfunktion eingeführt werden, was auch bedeutet, dass eine leistungsfähigere Google-Suche nicht mehr weit von der Landung entfernt ist.
In späteren Versionen wird es sogar in der Lage sein, Antworten auf der Grundlage der automatischen Untertitel der Videos auf der Seite zu finden. Ich frage mich, ob es den Bloggern, die „XX Filme in 1 Minute gesehen haben“, die Arbeit wegnimmt.
Bilder, Lieder und Filme, die auf OpenAI abzielen
Wenn GPT-4o in den letzten zwei Tagen aufgrund der KI erneut ein Schock für die Welt war, dann ist das heute Abend von Google offiziell angekündigte Projekt Astra eine Fortsetzung des Schocks.
Project Astra ist ein Prototyp von GoogleMind – einem allgemeinen Assistenten für künstliche Intelligenz.

Ähnlich wie bei GPT-4o können Benutzer darüber Echtzeitgespräche mit KI und Video-Chat führen.
Die Demonstration auf der Pressekonferenz kann diese neue Funktion sehr gut demonstrieren. Im Demonstrationsvideo richteten die Mitarbeiter die Linse des Mobiltelefons auf die Objekte um sie herum und stellten dem Projekt Astra einige Fragen, die nahezu ohne Verzögerung präzise beantwortet wurden .
Project Astra kann beispielsweise erkennen, dass es sich bei der oberen Hälfte des Lautsprechers um einen Hochtöner handelt, und seine spezifische Funktion anhand des auf dem Computerbildschirm angezeigten Codes leicht identifizieren.
Google sagt:
Unser neues Projekt konzentriert sich auf die Entwicklung eines futuristischen KI-Assistenten, der tatsächlich im Alltag helfen kann.
Basierend auf einer stärkeren KI-Leistung kündigte Google auf der I/O außerdem drei weitere praktische Funktionen an. Sie liegen in den Bereichen „Bilder“, „Musik“ und „Videos“ und spiegeln den „Zukunftssinn“ fortschrittlicher Technologie wider.
Imagen 3 ist das neueste von Google veröffentlichte Bildgenerierungsmodell.

Es kann unsere Aufforderungswörter besser verstehen und sie verwenden, um realistischere Bilder zu erstellen.
Das generierte Bild von „Wolf“, das auf der Pressekonferenz gezeigt wurde, besteht darin, dass Imagen 3 8 detaillierte Informationen in einer Erzählung genau extrahiert hat und sie alle im Bild widergespiegelt sind.

Es ist nicht schwer festzustellen, dass die erzeugten Bilder nicht nur detailgetreu, sondern auch sehr realistisch sind.
Imagen 3 kann auch einige abstraktere Bildkreationen verarbeiten, beispielsweise kreative Bilder, die auf der Grundlage der Eingabeaufforderungen „Regenbogenfarbe“, „Federlicht“ und „schwarzer Hintergrund“ generiert werden.

Als wüsste es genau, was Sie wollen.
Der Sprecher gab auf der Pressekonferenz sogar scherzhaft an, dass „man damit die Bärte in den Gesichtern anderer Leute zählen kann.“
Auch bei der Musikgenerierung hat Google neue Durchbrüche erzielt.
Music AI Sandbox ist das neueste Modell der Musikgeneration, das Google dieses Mal auch Marc Rebillet eingeladen hat, es auf der I/O-Site zu teilen.

Basierend auf einer vom Künstler erstellten kurzen Musikdemo kann die Music AI Sandbox auf dieser Basis erweitert und erweitert werden. Außerdem kann sie basierend auf Eingaben des Benutzers, wie Musikstil und -typ usw., ein zweites Musikstück erstellen .
Google sagte, dass sie und YouTube die Music AI Sandbox entwickelt haben:
Dabei handelt es sich um eine Reihe professioneller KI-Musiktools, die neue Instrumententeile von Grund auf erstellen, Stile zwischen Titeln konvertieren usw. können, um uns beim Entwerfen und Testen zu helfen.
Ein weiteres praktisches Modell namens Veo konzentriert sich auf die Generierung von Videos.

Benutzer müssen lediglich relevante Text-, Bild- oder Videoaufforderungen eingeben, und Veo kann hochwertige 1080p-Videos mit einer Länge von bis zu 60 Sekunden erstellen.
Es erfasst die Details in Anleitungen in verschiedenen visuellen und filmischen Stilen.

Wir können beispielsweise Dinge, Landschafts- oder Zeitraffer-Luftbilder in die Eingabeaufforderungen eingeben und andere Eingabeaufforderungen zur weiteren Bearbeitung des Videos verwenden.
Die KI zur Videogenerierung ist seit langem „nur theoretisch etabliert“. Tatsächlich gibt es viele Hindernisse für die „Benutzerfreundlichkeit“: Die Videogenerierungszeit beträgt nur wenige Sekunden, und zwar im Allgemeinen kann nur wiederholt in einer oder zwei Bewegungen springen.

Aus diesem Grund sorgte Sora bei seiner Veröffentlichung für große Diskussionen. Von Fotorealismus über Surrealismus bis hin zu Animationen kann es sich mit den meisten Film- und Fernsehstilen befassen.
Neben Project Astra stellt uns Google auch ein anpassbares Gemini zur Verfügung – Gems.
Google sagte, dass es Aufgaben unter Beibehaltung bestimmter Eigenschaften erledigen und ein persönlicher Assistent für Tausende von Menschen werden kann. Benutzer können ihre Position anpassen, um ein Yoga-Freund, ein virtueller beliebter Charakter, ein Fitnesspartner, ein Trainer für kreatives Schreiben oder sogar ein Mikroblogger zu werden. Punkte, Tutoren etc. sind alles ein Problem.

Zwillinge sind verrückt nach langen Texten und die Gemini-Familie hat ein neues Mitglied bekommen
Das Gemini-Projekt hat seit seiner Bekanntgabe große Aufmerksamkeit erregt. Anfangs gab es einige Kontroversen, aber später verließ es sich auf seine eigene Stärke, um seinen Ruf wiederherzustellen, und jetzt wird es immer reifer.
Laut Pichai nutzen derzeit mehr als 1,5 Millionen Entwickler das Gemini-Modell und die Zahl der Nutzer hat 2 Milliarden erreicht. Jetzt spricht Pichai erneut von der „Gemini-Ära“ mit dem Ziel, es in alle Produkte zu integrieren und neue zu bringen Produkte für Benutzer schaffen auch neue Möglichkeiten für Entwickler, Entwickler und Start-ups.

Das neueste Gemini 1.5 Pro unterstützt derzeit 1 Million Token-Textvolumina, und später in diesem Jahr soll diese Zahl 2 Millionen erreichen und 2 Stunden Video, 22 Stunden Audio, mehr als 60.000 Codezeilen oder mehr verarbeiten können mehr als 1,4 Millionen Wörter gleichzeitig.
Darüber hinaus wurde auf der Konferenz auch Gemini Advanced auf Basis von Gemini 1.5 Pro angekündigt, das in der Lage sein soll, „mehrere große Dokumente mit insgesamt bis zu 1500 Seiten oder die Aggregation von 100 E-Mails“ zu verarbeiten und außerdem 35 Sprachen unterstützt und mehr als 150 Länder/Regionen.
Man muss sagen, dass Gemini in Bezug auf das Textvolumen tatsächlich sehr groß ist, „ein großer Schritt in Richtung des Ziels, jede Eingabe in jede Ausgabe umzuwandeln.“

Sicherheit steht immer an erster Stelle
Seit den Anfängen der KI gibt es eine anhaltende Debatte darüber, wie KI-generierte Inhalte identifiziert werden können. Die Gegenmaßnahme von Google besteht darin, über SynthID unsichtbare Wasserzeichen zu KI-generierten Bildern und Audiodaten hinzuzufügen, um diese leichter unterscheiden zu können.
In Zukunft wird Google diesen Anwendungsbereich auf Text und Video erweitern und in den nächsten Monaten durch die Aktualisierung des Open-Source-Textwasserzeichens SynthID des generativen KI-Toolkits dazu beitragen, dass KI einfacher und verantwortungsvoller erstellt wird.

Nach der Integration von Gemini gibt Android eine Warnung aus, wenn während des Anrufs verdächtige Aktivitäten festgestellt werden, z. B. die Aufforderung zur Angabe Ihrer Sozialversicherungsnummer und Bankinformationen. Dies ist, als würde das „Anti-Betrugs-Center“ direkt auf dem Telefon installiert .
Auch die Barrierefreiheitsfunktion TalkBack wird durch Gemini Nano verbessert. Bildbeschreibungen werden klarer und umfangreicher und helfen Benutzern mit Sehbehinderung, ihre Telefone durch Sprachfeedback besser zu bedienen, was die konsequente humanistische Sorgfalt von Google widerspiegelt.

Was die Leistung von Google heute Abend betrifft, ist die Bewertung von NVIDIA Research Manager Jim Fan sehr relevant.
Das neu veröffentlichte Modell von Google scheint eine multimodale Eingabe, aber keine multimodale Ausgabe zu sein. Imagen3 und Music AI Sandbox sind immer noch als unabhängige Komponenten von Gemini getrennt. Die native Zusammenführung aller modalen E/A ist die unvermeidliche Zukunft.
Es kann Aufgaben wie „Eine roboterhaftere Stimme verwenden“, „Dieses Bild bearbeiten“ und „Konsistente Comicstrips erstellen“ ausführen.
Und ohne dass Informationen an modalen Grenzen wie Emotionen und Hintergrundgeräuschen verloren gehen, eröffnet das neue Modell neue kontextbezogene Möglichkeiten, und Benutzer können das Modell anhand einiger Beispiele unterrichten und verschiedene Bedeutungen auf neuartige Weise kombinieren.

GPT-4o ist nicht perfekt, aber es hat den richtigen Formfaktor, um Andres LLM-as-OS-Metapher zu paraphrasieren:
Wir benötigen, dass das Modell so viele Dateierweiterungen wie möglich nativ unterstützt.
Google macht eines richtig: Sie unternehmen endlich ernsthafte Anstrengungen, künstliche Intelligenz in das Suchfeld zu integrieren.
Zwillinge müssen nicht unbedingt die beste sein, aber sie können die am weitesten verbreitete sein.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo