
Das Stanford-Team hat ein großes Modell der Tsinghua-Universität plagiiert. Der Autor entschuldigte sich spät in der Nacht. Chinas großes Modell kann nicht länger ignoriert werden.
Vor einiger Zeit veröffentlichte das Institut für künstliche Intelligenz der Stanford University (Stanford HAI) einen Bericht, in dem es heißt, dass die Vereinigten Staaten im Bereich großer Modelle weit vorne liegen. Der Bericht wies darauf hin, dass im Jahr 2023 61 bekannte Modelle für künstliche Intelligenz von US-Institutionen stammten, weit mehr als die 21 in der EU und 15 in China.
Vinod Khosla, ein früher Investor von OpenAI, veröffentlichte letztes Jahr auch einen Artikel auf X, in dem er sagte, dass amerikanische Open-Source-Modelle von China kopiert werden.
Allerdings ist das große inländische Modell, von dem immer angenommen wurde, dass es „die Vereinigten Staaten einholt“, nun zum Ziel von Plagiaten geworden, und das plagiierte KI-Team stammt von der Stanford University, die den oben genannten Bericht veröffentlicht hat.

Es wurde festgestellt, dass das vom Stanford AI-Team geleitete Open-Source-Modell Llama3-V im Verdacht steht, das inländische Open-Source-Modell „Little Steel Cannon“ MiniCPM-Llama3-V 2.5 von der Tsinghua University und Wall-Facing Intelligence zu plagiieren, was sofort für Aufsehen sorgte im KI-Kreis.
Unter dem echten Hammer musste sich auch das Stanford-Team dringend entschuldigen.
Wie Li Dahai, CEO von Wall-Facing Intelligence, scherzhaft antwortete, handelt es sich hierbei um eine „vom internationalen Team anerkannte Methode“. Egal wie weit wir von den Top-Großmodellen entfernt sind, inländische Großmodelle haben ein Stadium erreicht, in dem sie nicht länger ignoriert werden können.
Fassen wir den Zeitplan kurz zusammen:
- Das Stanford AI-Team veröffentlicht Llama3-V, bekannt als multimodales SOTA-Großmodell
- Internetnutzer stellten in Frage, dass das Modell den heimischen wandmontierten Smart MiniCPM-Llama3-V2.5 kopiert habe
- Vernehmungsbeweise tauchten auf, Llama3-V-Autor inszenierte „Löschen der Datenbank und Weglaufen“
- Stellen Sie sich dem offiziellen Plagiat des Wall-Geheimdienstes gegenüber und gab spät in der Nacht eine Erklärung ab
- Der Autor von Llama3-V entschuldigt sich offiziell, Internetnutzer haben unterschiedliche Meinungen
Das KI-Team von Stanford plagiierte die an der Wand angebrachte intelligente „Small Steel Cannon“ und inszenierte „Datenbank löschen und weglaufen“.
Kürzlich gab ein Stanford-KI-Team bekannt, dass es nur 500 US-Dollar kostet, ein multimodales SOTA-Großmodell zu trainieren, das GPT-4V übertrifft.
Doch schon bald wies ein
Zu diesem Zweck veröffentlichte auch der X-Benutzer @yangzhizheng1 entsprechende Vernehmungsbeweise.
Beweis eins:
Die Modellstruktur und der Code von Llama3-V und MiniCPM-Llama3-V 2.5 sind auf der Ebene des Kopierens und Einfügens nahezu ähnlich. Der Unterschied besteht wahrscheinlich darin, dass sie die Weste geändert haben – die Variablennamen wurden geändert.
Es ist wie das gleiche Kleid, aber mit Knöpfen in verschiedenen Farben. Glaubst du, dass es ein Zufall ist?
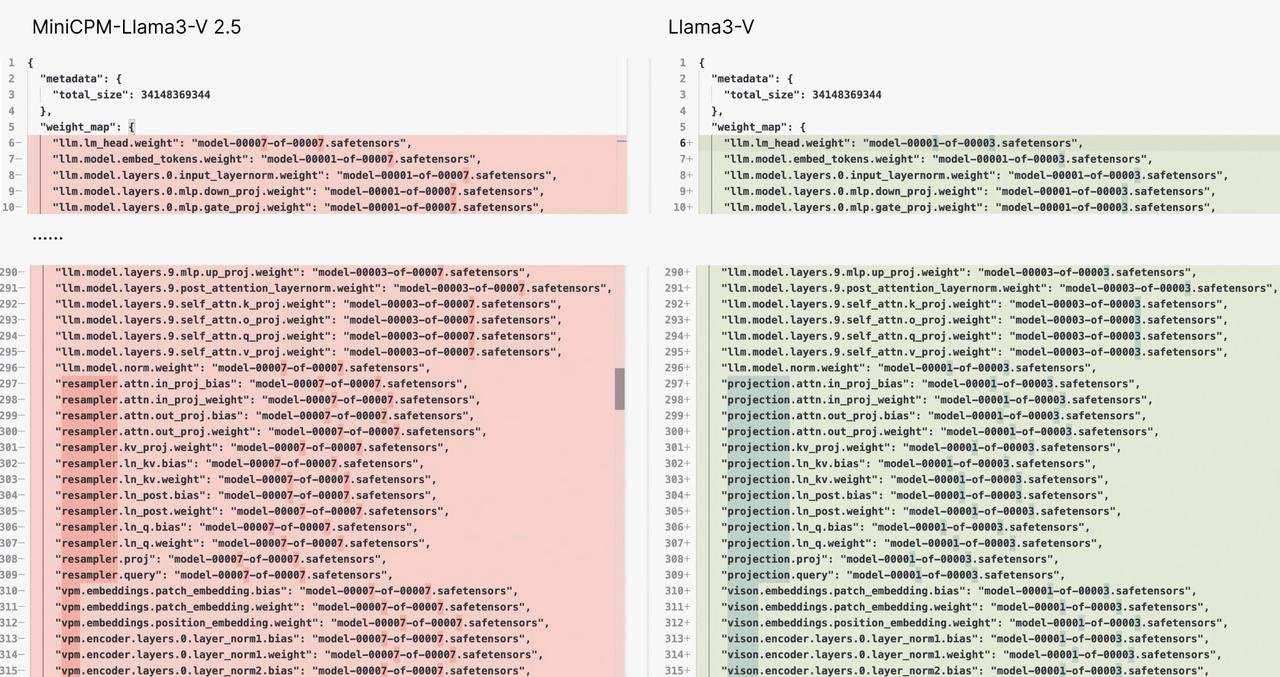
Beweis zwei:
Als die Autoren von Llama3-V gefragt wurden, warum sie den noch nicht veröffentlichten Tokenizer MinicPM-Llama3-V2.5 verwenden könnten, erklärten sie, dass sie das MinicPM-V-2-Projekt der vorherigen Generation von Wall-Facing verwendeten Intelligenz.
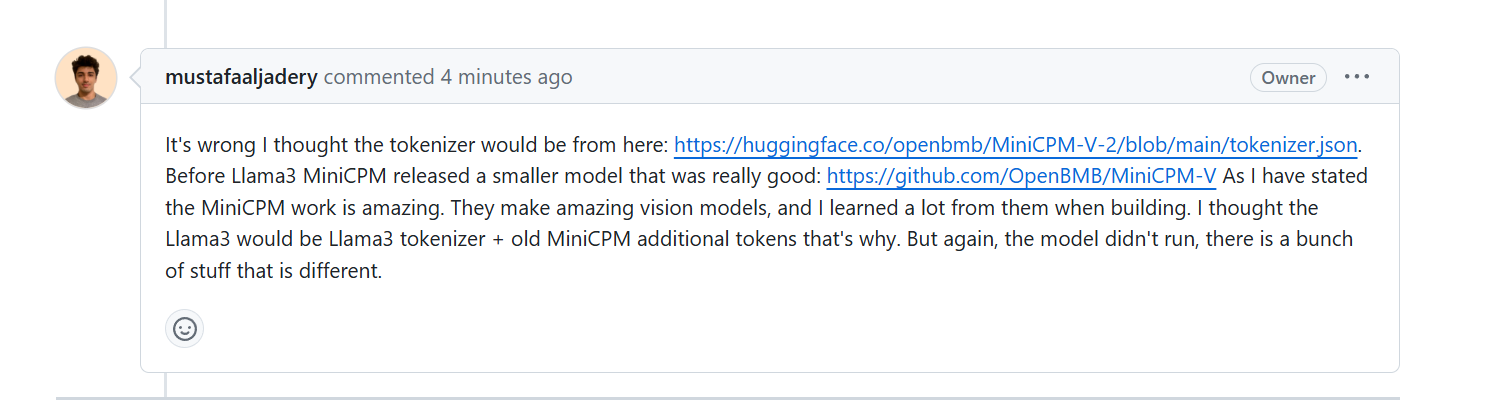
Einige Medien baten jedoch um Bestätigung von Beamten des Wallface Intelligence. Bei HuggingFace handelt es sich bei den Wortsegmentierern MiniCPM-V2 und MiniCPM-Llama3-V 2.5 jeweils um zwei Dateien, und die Dateigrößen sind völlig unterschiedlich.
Darüber hinaus besteht der Tokenizer von MiniCPM-Llama3-V 2.5 aus dem Llama3-Tokenizer und dem speziellen Token des Modells der MiniCPM-V-Serie.
Wenn man bedenkt, dass MiniCPM-V2 früher als Llama3 veröffentlicht wurde, ist es theoretisch unmöglich, dass es die noch nicht veröffentlichte Llama3-Tokenizer-Technologie enthält.
Beweis drei:
Was noch empörender ist, ist, dass der Autor des llama3-V-Projekts, als er den Zweifeln der Benutzer gegenüberstand und feststellte, dass etwas nicht gut lief, einfach eine gute Show inszenierte, indem er „die Bibliothek löschte und weglief“.
Sogar die Projektseite auf GitHub wurde entfernt, was als irreführende Version 2.0 bezeichnet werden kann.
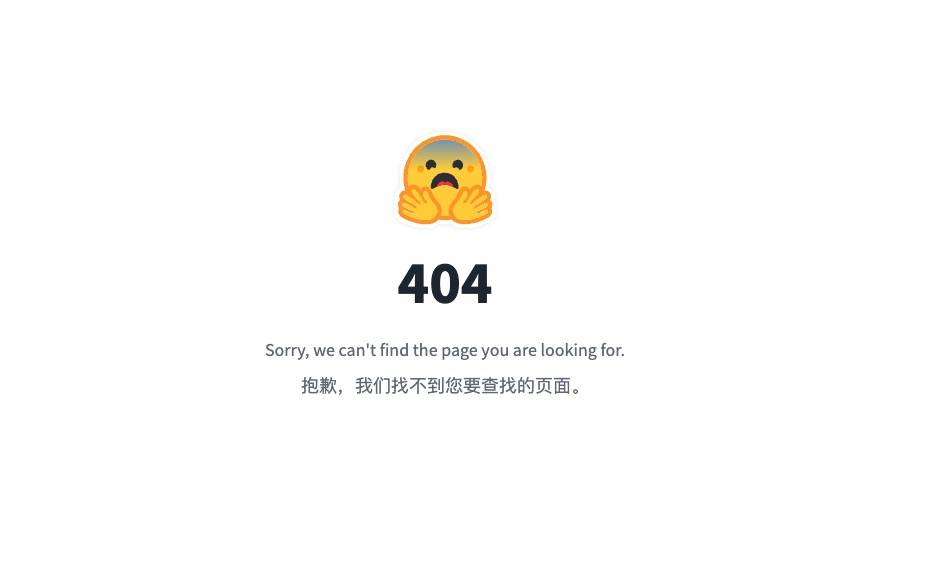
Die Hugging Face-Adresse lautet derzeit wie folgt: Wenn wir die Seite öffnen, können wir nur „404“ sehen.
https://huggingface.co/mustafaaljadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6
Dies ist noch nicht vorbei, es tauchen weitere Beweise auf:
Der
Darüber hinaus kann dieses Modell auch die tiefgreifenden antiken Schriften der Zeit der Streitenden Reiche wie „Tsinghua Slips“ erkennen, und die Fehler sind genau die gleichen. In den offiziellen Worten von Wall-Facing Intelligence:
Sie haben nicht nur Recht, sie liegen auch falsch.

Sie müssen wissen, dass diese alten Schriftdaten durch Scannen und manuelles Kommentieren der von der Tsinghua-Universität über mehrere Monate gesammelten Tsinghua-Bambusstreifen erhalten wurden. Sie wurden nie veröffentlicht.
Wie hat das Stanford AI-Team es also aus dem Nichts geschafft?
Man kann sagen, dass die nächtliche Stellungnahme von Wallface Intelligence vom 2. Juni als komplettes Plagiat des Stanford AI-Forschungsteams angesehen werden kann.
Bis zum frühen Morgen entschuldigten sich Siddharth Sharma und Aksh Garg, zwei Autoren des Stanford Llama3-V-Teams, offiziell beim an der Wand stehenden MiniCPM-Team für dieses akademische Fehlverhalten auf der sozialen Plattform X und sagten, dass alle Llama3-V-Modelle entfernt würden.
Plagiieren auch Top-Schüler berühmter Schulen? Chinas große Open-Source-Modelle holen auf
Ein wichtiger Grund, warum diese Angelegenheit im Internet für Aufsehen sorgte, ist, dass der Hintergrund des Plagiators so glamourös ist.
Aus öffentlichen Informationen geht hervor, dass Siddharth Sharma und Aksh Garg beide Bachelor-Studenten am Fachbereich Informatik der Stanford University sind und zahlreiche Arbeiten im Bereich maschinelles Lernen veröffentlicht haben. Unter ihnen hat Siddharth Sharma eine Zeit lang ein Praktikum bei Amazon absolviert und beschäftigt sich derzeit hauptsächlich mit KI und datenbezogenen Arbeiten.
Aksh Gargs Praktikumslebenslauf ist umfangreich und deckt bekannte Organisationen wie SpaceX, die Stanford University und das California Institute of Technology ab.
Was Mustafa Aljadery betrifft, der von den beiden oben genannten Autoren als „Code-Porter“ bezeichnet wird, ist er Absolvent der University of Southern California. Nachdem die öffentliche Meinung gärte, wurde das X-Konto auf privaten Status gesetzt.

Scharfäugige Internetnutzer akzeptierten die Entschuldigungserklärung des Stanford Llama3-V-Teams nicht.
Zum Beispiel die
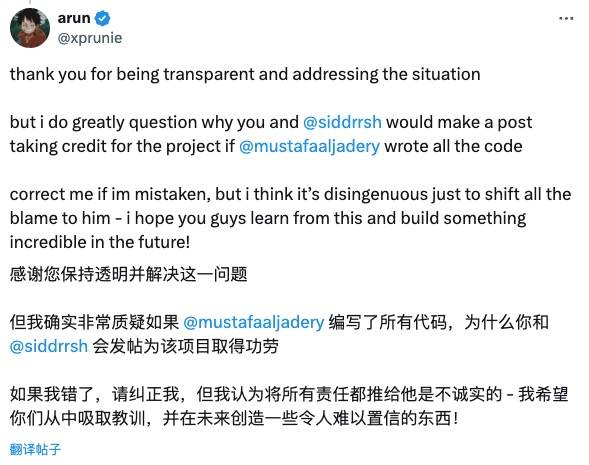
Auch Christopher David Manning, Direktor des Stanford AI Laboratory, verurteilte dieses Plagiat und lobte MiniCPM, ein hervorragendes chinesisches Open-Source-Modell.
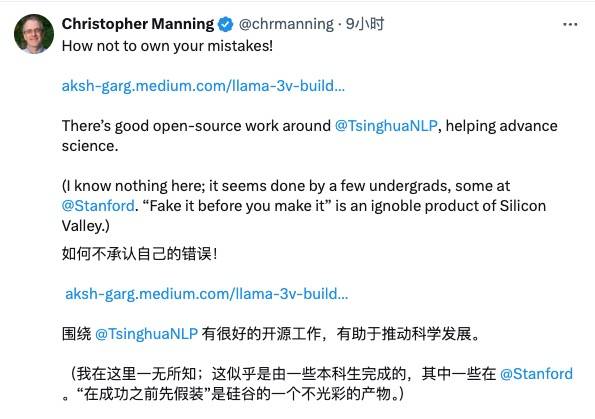
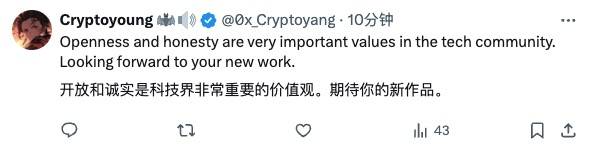
Es gibt jedoch auch Internetnutzer, die die Einstellung „Vergib anderen, wenn du ihnen Gnade erweisen musst“ vertreten und sie gemächlich ermutigen:
Offenheit und Ehrlichkeit sind sehr wichtige Werte in der Technologiewelt und ich freue mich auf Ihre neue Arbeit.
Google DeepMind-Forscher Lucas Beyer sagte, dass Chinas große Open-Source-Modelle über gute Modelle wie MiniCPM verfügen, die internationale Gemeinschaft ihnen jedoch nicht genügend Aufmerksamkeit geschenkt hat …

Auch das Wall-Facing Intelligence-Team hat gestern auf diese Angelegenheit reagiert.
Li Dahai, CEO von FaceWall Intelligence, sagte: „Technologische Innovation ist nicht einfach. Jeder Auftrag ist das Ergebnis der Tag-und-Nacht-Bemühungen des Teams und ein aufrichtiger Beitrag zum technologischen Fortschritt und zur innovativen Entwicklung auf der ganzen Welt mit begrenzter Rechenleistung.“
Wir hoffen, dass die gute Arbeit des Teams von mehr Menschen wahrgenommen und anerkannt wird, aber nicht auf diese Weise. "

Liu Zhiyuan, Chefwissenschaftler von Wall-Facing Intelligence, postete ebenfalls auf Zhihu und sagte, dass dieser Vorfall den internationalen Einfluss von Chinas innovativen Errungenschaften aus einer anderen Perspektive beweise, und betonte die Bedeutung des Open-Source-Sharings und des Respekts für den Geist der Originalität.
Es muss gesagt werden, dass dieses Plagiatsdrama im KI-Kreis eine lehrbuchmäßige Erklärung dafür ist: „Innovation ist nicht einfach, sie muss getan und geschätzt werden, akademische Integrität liegt in der Verantwortung eines jeden.“
Wissen Sie, wenn Sie die Form des Codes nachahmen, können Sie die ursprüngliche Anmut nicht kopieren.
Tatsächlich sind Chinas große Modelle seit letztem Jahr nach einem Frühlingsregen wie Pilze aus dem Boden geschossen. Sie haben sich von Nutznießern zu Mitwirkenden gewandelt und sind nicht geizig, der Welt herausragendere Open-Source-Ergebnisse zu liefern.
Von Giganten wie Alibaba und Tencent bis hin zu wandnahen Geheimdiensten sind auch KI-Start-ups wie Zhipu AI und Kunlun Tiangong aktive Mitglieder der Open-Source-Community und tragen zur Entwicklung von Chinas groß angelegten Modellen bei.
Wir hoffen auch, dass dieser Frühlingswind der Offenheit und des Teilens stärker weht.
So wie Li Dahai, CEO von Face Wall Intelligence, alle dazu aufruft, zusammenzuarbeiten, um ein offenes, kooperatives und vertrauensvolles Gemeinschaftsumfeld aufzubauen. Nur durch Zusammenarbeit kann die Welt mit der Einführung von AGI ein besserer Ort werden!
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo