
Nach dem GPT-4o wurde das leistungsstärkste Modell Llama 3.1 405B über Nacht zum Gott, Zuckerberg: Open Source leitet eine neue Ära ein
Gerade hat Meta wie geplant das Modell Llama 3.1 veröffentlicht.
Einfach ausgedrückt ist das neu veröffentlichte Llama 3.1 405B das bisher leistungsstärkste Modell von Meta. Es ist auch das leistungsstärkste Open-Source-Großmodell der Welt und es ist auch das leistungsstärkste Großmodell der Welt.
Von heute an besteht kein Grund mehr, über die Vorzüge von Open-Source-Großmodellen und Closed-Source-Großmodellen zu streiten, denn Llama 3.1 405B beweist mit unwiderlegbarer Stärke, dass der Kampf um Routen keinen Einfluss auf die endgültige technische Stärke hat.
Lassen Sie mich zunächst die Eigenschaften des Llama 3.1-Modells zusammenfassen:
- Enthält drei Größen: 8B, 70B und 405B, der maximale Kontext wurde auf 128 KB erhöht, unterstützt mehrere Sprachen, verfügt über eine hervorragende Codegenerierungsleistung und verfügt über komplexe Argumentationsfähigkeiten und Fähigkeiten zur Werkzeugnutzung.
- Den Benchmark-Testergebnissen zufolge übertraf Llama 3.1 GPT-4 0125 und konkurrierte mit GPT-4o und Claude 3.5.
- Durch die Bereitstellung offener/freier Modellgewichte und Codes ermöglicht die Lizenz Benutzern die Feinabstimmung, das Destillieren des Modells in andere Formen und die Unterstützung der Bereitstellung überall
- Bietet eine Llama-Stack-API zur Erleichterung der integrierten Nutzung und unterstützt die Koordination mehrerer Komponenten, einschließlich des Aufrufs externer Tools
Im Anhang finden Sie die Download-Adresse des Modells:
https://huggingface.co/meta-llama
https://llama.meta.com/

Der supergroße Becher erreicht die Spitze des leistungsstärksten Modells der Welt, während der mittelgroße und große Becher Überraschungen bereithält
Das dieses Mal veröffentlichte Llama 3.1 ist in drei Größenversionen erhältlich: 8B, 70B und 405B.
Den Benchmark-Testergebnissen nach zu urteilen, kann das supergroße Llama 3.1 405B allen Drücken von GPT-3.5 Turbo standhalten und die meisten Benchmark-Testergebnisse übertreffen GPT-4 0125.
Angesichts des leistungsstärksten Closed-Source-Großmodells GPT-4o, das zuvor von OpenAI veröffentlicht wurde, und des erstklassigen Claude 3.5 Sonnet hat Super Cup immer noch die Kraft, zu kämpfen. Allein aus den Papierparametern lässt sich sogar sagen, dass Llama 3.1 405B markiert Open Source. Zum ersten Mal haben große Modelle zu großen Closed-Source-Modellen aufgeschlossen.
Wenn man die Benchmark-Ergebnisse genauer aufschlüsselt, erzielte Llama 3.1 405B im NIH/Multi-Needle-Benchmark einen Wert von 98,1. Obwohl es nicht so gut ist wie GPT-4o, zeigt es auch, dass seine Fähigkeit, komplexe Informationen zu verarbeiten, perfekt ist.
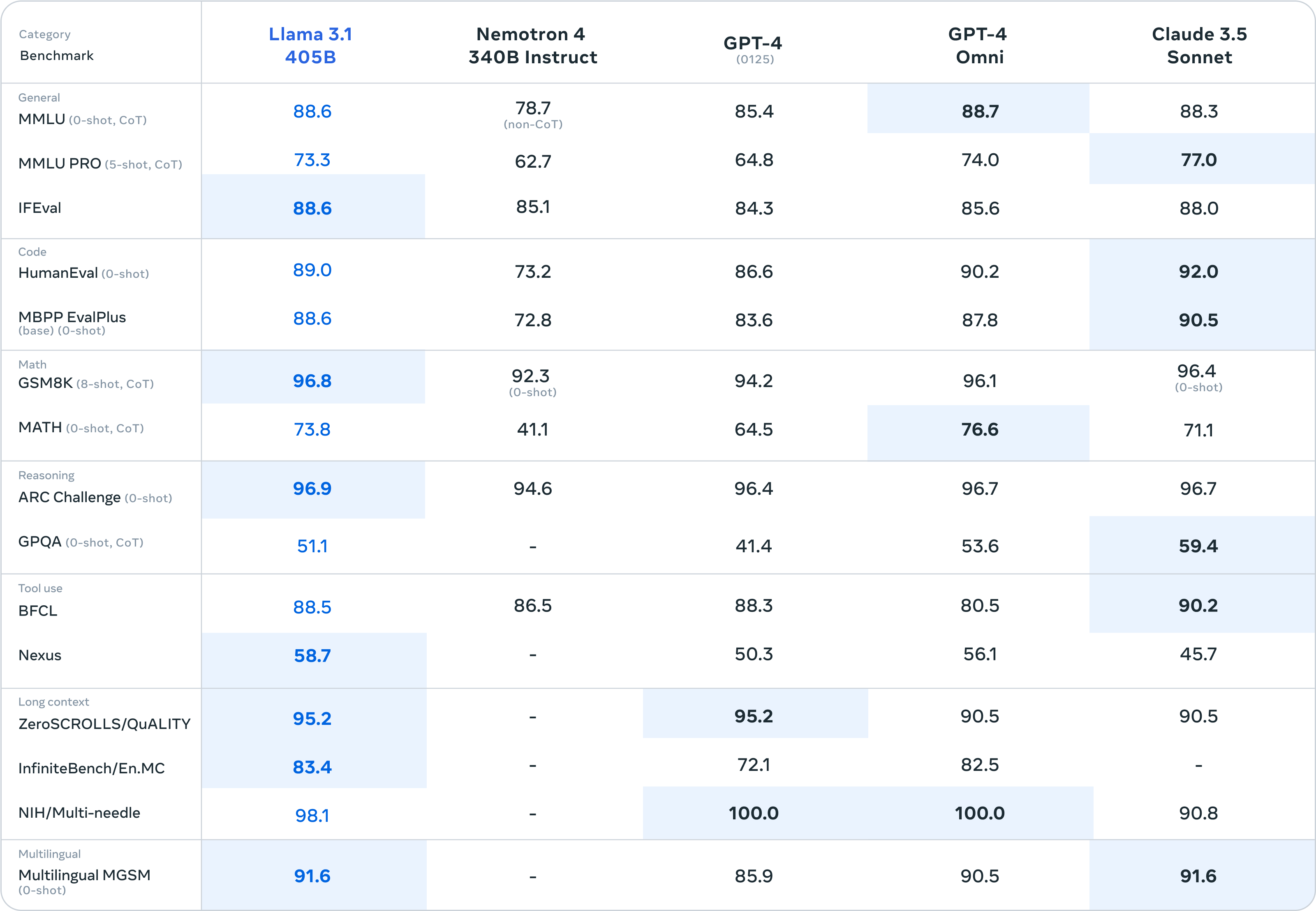
Und Llama 3.1 405B erzielte beim ZeroSCROLLS/QUALITY-Benchmark einen Wert von 95,2, was auch bedeutet, dass es über eine starke Fähigkeit verfügt, große Mengen an Textinformationen zu integrieren. Diese Ergebnisse zeigen, dass das Modell LLaMA3.1 405B hervorragend für die Verarbeitung langer Texte geeignet ist Der Schwerpunkt liegt auf LLM in RAG. Für KI-Anwendungsentwickler ist die Leistung recht benutzerfreundlich.
Besonders besorgniserregend ist, dass Human-Eval hauptsächlich für das Benchmarking der Fähigkeit des Modells verantwortlich ist, Code zu verstehen und zu generieren und abstrakte Logik zu lösen, und Llama 3.1 405B auch einen leichten Vorteil im Wettbewerb mit anderen großen Modellen hat.
Neben der Hauptspeise „Llama 3.1 405B“ lieferten auch die Beilagen „Llama 3.1 8B“ und „Llama 3.1 70B“ eine gute Leistung ab: „Kleine Siege über Große“.
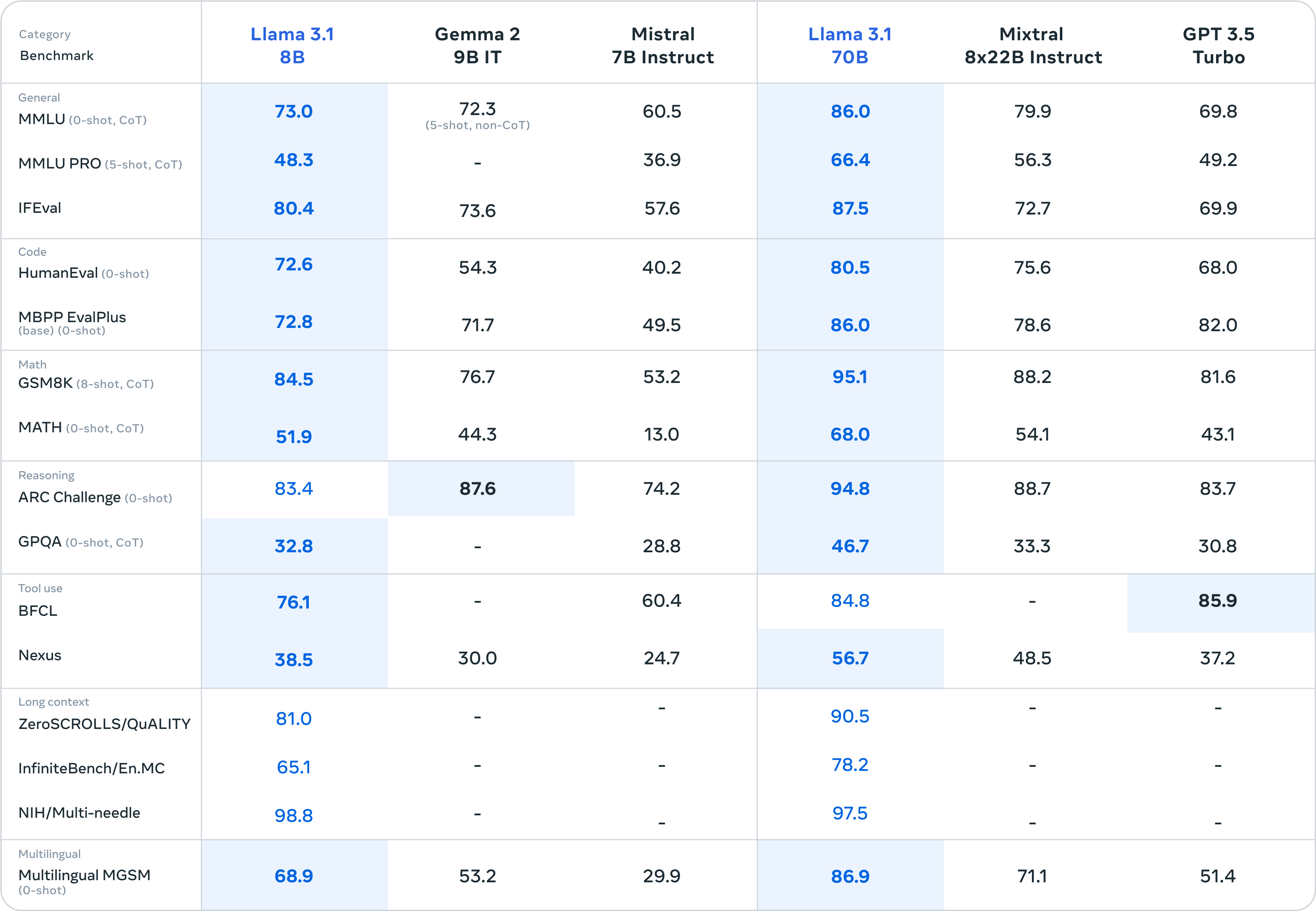
Den Benchmark-Testergebnissen nach zu urteilen, hat Llama 3.1 8B Gemma 2 9B 1T und Mistral 7B Instruct fast übertroffen. Die Gesamtleistung war sogar deutlich besser als die von Llama 3 8B. Llama 3.1 70B kann sogar GPT-3.5 Turbo und das Mixtral 8×7B-Modell mit hervorragender Leistung übertreffen.
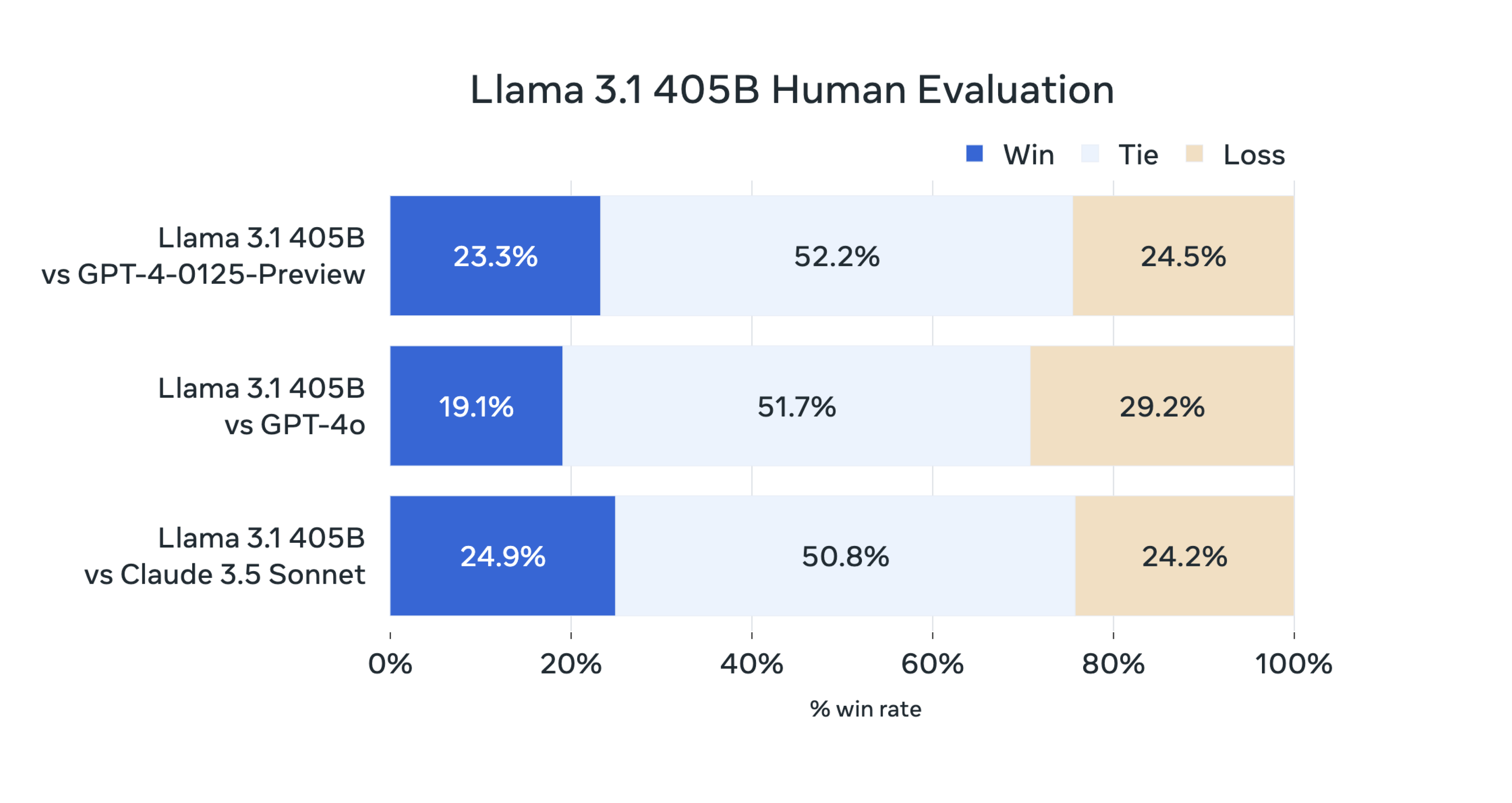
Laut der offiziellen Einführung bewertete das Llama-Forschungsteam in dieser Version die Modellleistung anhand von mehr als 150 Benchmark-Datensätzen, die mehrere Sprachen abdeckten, und führte außerdem eine große Anzahl manueller Bewertungen durch.
Die abschließende Schlussfolgerung lautet:
Unser Flaggschiffmodell ist bei mehreren Aufgaben mit Top-Basismodellen wie GPT-4, GPT-4o und Claude 3.5 Sonnet konkurrenzfähig. Gleichzeitig zeigt unser kleines Modell auch Wettbewerbsfähigkeit im Vergleich zu geschlossenen und offenen Modellen mit einer ähnlichen Anzahl von Parametern.
Wie Llama 3.1 405B hergestellt wird
Wie wird Llama 3.1 405B trainiert?
Laut dem offiziellen Blog verwendet Llama 3.1 405B als bisher größtes Modell von Meta mehr als 15 Billionen Token für das Training.
Um ein Training dieser Größenordnung zu erreichen und in kurzer Zeit die erwarteten Ergebnisse zu erzielen, optimierte das Forschungsteam außerdem den gesamten Trainingsstapel und trainierte auf mehr als 16.000 H100-GPUs. Dies ist auch das erste Llama-Modell, das in einem so großen Maßstab trainiert wurde. .
Das Team hat während des Trainingsprozesses auch einige Optimierungen vorgenommen und sich darauf konzentriert, den Modellentwicklungsprozess skalierbar und einfach zu halten:
- Anstelle eines Hybrid-Expertenmodells wurde eine Standard-Decoder-Transformer-Modellarchitektur mit nur geringfügigen Anpassungen gewählt, um die Trainingsstabilität zu maximieren.
- Es kommt ein iteratives Post-Training-Verfahren zum Einsatz, das in jeder Runde überwachte Feinabstimmung und direkte Präferenzoptimierung verwendet. Dies ermöglicht es dem Forschungsteam, synthetische Daten höchster Qualität für jede Runde zu erstellen und die Leistung jedes Features zu verbessern.
- Im Vergleich zur alten Version des Llama-Modells hat das Forschungsteam die Quantität und Qualität der für Pre-Training und Post-Training verwendeten Daten verbessert, einschließlich der Entwicklung einer stärkeren Vorverarbeitungs- und Verwaltungspipeline für Pre-Training-Daten und der Entwicklung weiterer Daten Strenge Qualitätssicherungs- und Filtermethoden für Post-Training-Daten.
Meta-Beamte gaben an, dass das neue Flaggschiffmodell unter dem Einfluss des Skalierungsgesetzes kleinere Modelle übertraf, die mit derselben Methode trainiert wurden.
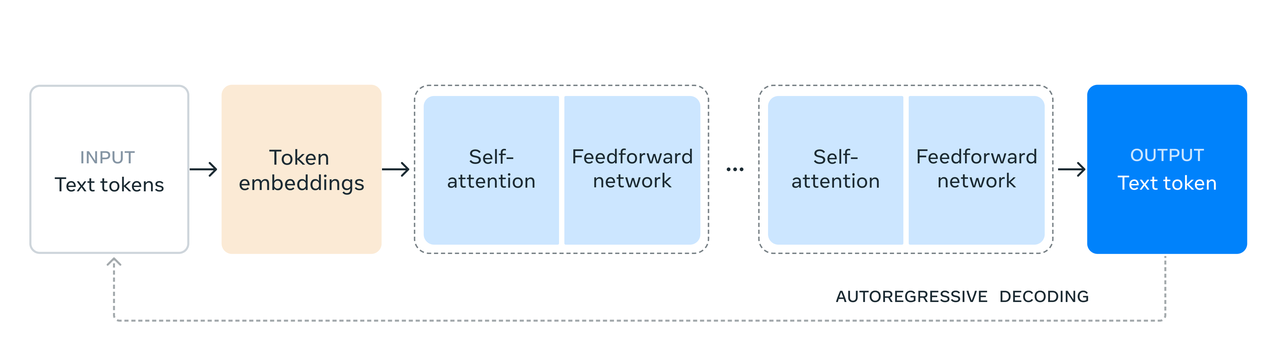
Das Forschungsteam nutzte außerdem das 405B-Parametermodell, um die Qualität kleiner Modelle nach dem Training zu verbessern.
Um die Massenproduktion von Modellen im Maßstab 405B zu unterstützen, quantisierte das Forschungsteam das Modell von 16-Bit-Präzision (BF16) auf 8-Bit-Präzision (FP8). Dadurch wurden die erforderlichen Rechenressourcen effektiv reduziert und die Ausführung des Modells ermöglicht auf einem einzelnen Serverknoten ausgeführt werden.
Es gibt auch einige Details, die es wert sind, über Llama 3.1 405B untersucht zu werden, wie zum Beispiel sein Design, das auf Praktikabilität und Sicherheit ausgerichtet ist und es ihm ermöglicht, Benutzeranweisungen besser zu verstehen und auszuführen.
Durch Methoden wie überwachte Feinabstimmung, Ablehnungsstichprobe und direkte Präferenzoptimierung werden mehrere Ausrichtungsrunden auf der Grundlage des vorab trainierten Modells durchgeführt, um ein Chat-Modell zu erstellen, das sich auch genauer an bestimmte Nutzungsszenarien anpassen kann und Benutzeranforderungen, wodurch die Leistung tatsächlicher Anwendungen verbessert wird.
Es ist erwähnenswert, dass das Llama-Forschungsteam die Generierung synthetischer Daten verwendet, um die überwiegende Mehrheit der SFT-Beispiele zu erstellen, was bedeutet, dass sie sich nicht auf reale Daten, sondern auf algorithmisch generierte Daten verlassen, um das Modell zu trainieren.
Darüber hinaus verbessert das Forschungsteam weiterhin die Qualität der synthetisierten Daten durch mehrere iterative Prozesse. Um die hohe Qualität der synthetischen Daten sicherzustellen, nutzte das Forschungsteam verschiedene Datenverarbeitungstechniken zur Datenfilterung und -optimierung.
Durch diese Techniken ist das Team in der Lage, die Menge der Feinabstimmungsdaten so zu skalieren, dass sie nicht nur auf eine einzelne Funktion anwendbar sind, sondern über mehrere Funktionen hinweg verwendet werden können, wodurch die Anwendbarkeit und Flexibilität des Modells erhöht wird.
Einfach ausgedrückt besteht die Anwendung dieser Technologie zur Generierung und Verarbeitung synthetischer Daten darin, eine große Menge hochwertiger Trainingsdaten zu erstellen, was dazu beiträgt, die Generalisierungsfähigkeit und Genauigkeit des Modells zu verbessern.
Als Unterstützer der Open-Source-Modellroute hat Meta auch in Bezug auf die „unterstützenden Einrichtungen“ des Llama-Modells Aufrichtigkeit gezeigt.
- Als Teil eines KI-Systems unterstützt das Llama-Modell die Koordination mehrerer Komponenten, einschließlich des Aufrufs externer Tools.
- Veröffentlichen Sie Referenzsysteme und Open-Source-Beispielanwendungen, fördern Sie die Beteiligung und Zusammenarbeit der Community und definieren Sie Komponentenschnittstellen.
- Fördern Sie die Interoperabilität von Tool-Chain-Komponenten und Agent-Anwendungen durch die standardisierte Schnittstelle „Llama Stack“.
- Nach der Veröffentlichung des Modells stehen Entwicklern alle erweiterten Funktionen zur Verfügung, einschließlich erweiterter Arbeitsabläufe wie der Generierung synthetischer Daten.
- Llama 3.1 405B wird mit einem Geschenkpaket mit integrierten Tools geliefert, einschließlich wichtiger Projekte, um den Prozess von der Entwicklung bis zur Bereitstellung zu vereinfachen.
Es ist erwähnenswert, dass Meta in der neuen Open-Source-Vereinbarung die Verwendung von Llama 3 zur Verbesserung anderer Modelle, einschließlich des stärksten Llama 3.1 405B, eines echten Open-Source-Gutmenschen, nicht mehr verbietet.
Im Anhang finden Sie die Adresse des 92-seitigen Schulungsberichts zur Abschlussarbeit:
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
Eine neue Ära, angeführt von Open Source
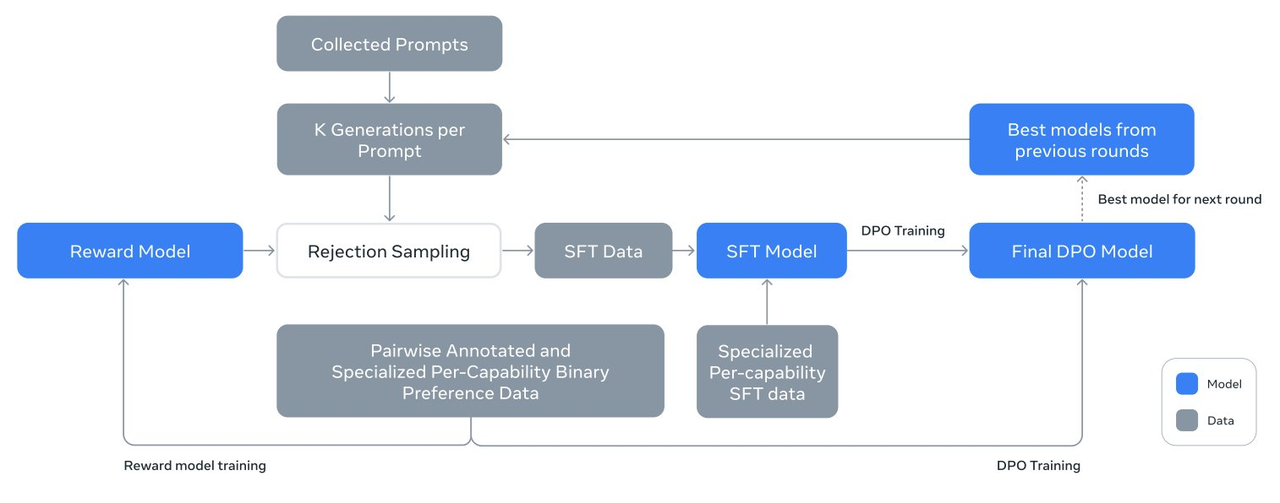
Netizen @ZHOZHO672070 hat auch schnell die Antworten von Llama 3.1 405B Instruct FP8 auf zwei klassische Fragen im Hugging Chat getestet.
Leider scheiterte Llama 3.1 405B bei der Lösung des Problems „Wer ist größer, 9,11 oder 9,9“, aber nach einem erneuten Versuch ergab es die richtige Antwort. In Bezug auf die Pinyin-Anmerkung „Ich habe es gefangen“ ist die Leistung ebenfalls akzeptabel.
Netizens nutzten das Llama 3.1-Modell, um schnell und in weniger als 10 Minuten einen Chatbot zu erstellen und bereitzustellen.
Darüber hinaus verriet der Llama-interne Wissenschaftler @astonzhangAZ auf X, dass sein Forschungsteam derzeit darüber nachdenkt, Bild-, Video- und Sprachfunktionen in Llama 3 zu integrieren.
Die Debatte zwischen Open Source und Closed Source geht im Zeitalter großer Modelle weiter, aber die heutige Veröffentlichung des neuen Meta Llama 3.1-Modells beendet diese Debatte.
Meta erklärte offiziell: „Bisher sind Open-Source-Sprachmodelle im großen Maßstab in Bezug auf Funktionalität und Leistung größtenteils hinter geschlossenen Modellen zurückgeblieben. Jetzt läuten wir eine neue Ära ein, die von Open Source angeführt wird.“
Die Geburt von Meta Llama 3.1 405B beweist eines: Die Fähigkeit eines Modells liegt nicht im Öffnen oder Schließen, sondern in der Investition von Ressourcen, den Menschen und Teams dahinter usw. Meta kann sich aufgrund vieler Faktoren für Open Source entscheiden. Aber es wird immer Menschen geben, die diese Flagge tragen.
Als erster Riese, der die Situation ausnutzte, erhielt Meta auch den Titel des ersten SOTA, der das stärkste Closed-Source-Großmodell übertraf.

Zuckerberg, CEO von Meta, schrieb heute in einem langen Artikel mit dem Titel „Open Source AI Is the Path Forward“:
„Ab dem nächsten Jahr gehen wir davon aus, dass das zukünftige Llama das fortschrittlichste in der Branche sein wird. Aber schon vorher ist Llama führend in den Bereichen Open Source, Modifizierbarkeit und Kosteneffizienz.“
Open-Source-KI-Modelle zielen möglicherweise nicht darauf ab, Closed-Source-Modelle zu übertreffen, oder aus technischer Gleichheit, damit sie nicht zu einem Mittel für einige wenige Menschen werden, um Gewinne zu erzielen, oder aus der Hoffnung, dass jeder Treibstoff zum Wohlstand der KI beiträgt Ökosystem.
Wie Zuckerberg seine Vision am Ende seines langen Beitrags beschrieb:
Ich glaube, dass die Version 3.1 von Llama ein Wendepunkt in der Branche sein wird und die meisten Entwickler beginnen werden, hauptsächlich auf Open-Source-Technologien umzusteigen. Ich freue mich darauf, dass sich dieser Trend von nun an fortsetzt … Gemeinsam sind wir bestrebt, die Vorteile der KI zu nutzen an alle auf der ganzen Welt.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo