
GPT-4V kann auf Mobiltelefonen ausgeführt werden! Face the Wall veröffentlicht die leistungsstärkste multimodale kleine Stahlpistole 2.6, die zum ersten Mal Echtzeit-Videoverständnis startet

In den letzten sechs Monaten hat sich der Trend zu großen Modellen stillschweigend geändert. Anders als der vorherige Trend des kontinuierlichen Strebens nach Größe sind kleinere und stärkere End-to-Side-Modelle zum aktuellen Trend geworden.
Vor nicht allzu langer Zeit hat der inländische Hauptmodellhersteller Face Wall Intelligence seine Präsenz erheblich ausgebaut, nachdem er vom KI-Team der Stanford University plagiiert wurde, und auch das In- und Ausland auf die außergewöhnliche Stärke des Unternehmens im Bereich KI aufmerksam gemacht.
Heute hat Wallface Intelligence ein neues MiniCPM-V 2.6-Modell mit „kleiner Stahlkanone“ auf den Markt gebracht, das die endseitigen multimodalen Fähigkeiten erneut auf ein neues Niveau hebt.
Obwohl das Modell nur über 8B-Parameter verfügt, hat es 3 SOTA-Ergebnisse beim Einzelbild-, Mehrbild- und Videoverständnis unter 20B erzielt und damit die multimodalen Fähigkeiten der endseitigen KI im umfassenden Benchmarking auf ein Niveau über GPT-4V gehoben.
Markieren Sie einfach:
- Zum ersten Mal haben die multimodalen Kernfunktionen wie Einzelbild-, Mehrbild- und Videoverständnis auf der Geräteseite GPT-4V vollständig übertroffen, und das Einzelbildverständnis hat Gemini 1.5 Pro und GPT-4o mini übertroffen.
- Einführung von Echtzeit-Videoverständnis, Multi-Image-Vereinigung, visuellem ICL-Lernen, OCR usw., um eine reale Beobachtung und das Lernen endseitiger Modelle zu ermöglichen.
- Xiaogangpao 2.6 hat die doppelte Pixeldichte der Single-Token-Codierung im Vergleich zu GPT-4o erreicht. Der visuelle Token ist 30 % niedriger als bei der Vorgängergeneration und 75 % niedriger als bei ähnlichen Modellen.
- Der quantifizierte Backend-seitige Speicher belegt nur 6 GB; die endseitige Inferenzgeschwindigkeit beträgt bis zu 18 Token/s, was 33 % schneller ist als beim Modell der vorherigen Generation. Und es unterstützt llama.cpp, ollama, vllm-Argumentation bei der Veröffentlichung;

Das Echtzeit-Videoverständnis „Long Eyes“ wird erstmals eingeführt, sodass intelligente Geräte Sie besser verstehen können
Lassen Sie uns zunächst den tatsächlichen Demonstrationseffekt des MiniCPM-V 2.6-Modells erleben.
Das Video zeigt, dass MiniCPM-V 2.6 dank der Unterstützung multimodaler Funktionen wie ein Paar „Augen“ ist und die reale Welt in Echtzeit sehen kann. Wenn der Flugmodus aktiviert ist, kann das mit diesem Modell ausgestattete Endgerät die Innenszene des wandorientierten Smart-Unternehmens genau identifizieren.
Vom Logo des smarten Unternehmens an der Wand bis hin zu Pflanzen, Schreibtischen, Wasserspendern und anderen Gegenständen sind die Artikelerkennungsfunktionen von MiniCPM-V 2.6 stressfrei und man kann sogar sagen, dass sie einfach sind.
Wenn Sie mit zahlreichen Belegen im Buchhaltungs- oder Erstattungsprozess konfrontiert sind, müssen Sie nur ein Foto machen und es in MiniCPM-V 2.6 hochladen. Dadurch kann nicht nur der spezifische Betrag jedes Belegs ermittelt, sondern auch der Gesamtbetrag berechnet werden, was den gesamten Prozess erheblich vereinfacht .
Dank seiner fortschrittlichen OCR- und CoT-Technologie (Chain of Thought) kann MiniCPM-V 2.6 nicht nur den Betrag auf dem Beleg genau erfassen, sondern auch den Problemlösungsprozess klar und prägnant darstellen:
Wenn man beispielsweise mit einem etwa einminütigen Wettervorhersagevideo konfrontiert wird, kann MiniCPM-V 2.6 mit dem „bloßen Auge“ die spezifischen Wetterbedingungen in verschiedenen Städten unter stillen Bedingungen identifizieren und beschreiben.
Auch die endseitigen multimodalen komplexen Argumentationsfunktionen von MiniCPM-V 2.6 wurden „verbessert“.
Am Beispiel der klassischen offiziellen Demonstration von GPT-4V – Einstellen des Fahrradsitzes – kann MiniCPM-V 2.6 den Benutzer durch den Dialog mit mehreren Rädern klar anleiten, den Fahrradsitz abzusenken, und anhand der Anweisungen und des Werkzeugkastens geeignete Werkzeuge empfehlen.

Oder wenn Sie über eine 2G-Internetverbindung verfügen und die von jungen Menschen weit verbreiteten Memes nicht verstehen, können Sie sich auch geduldig die Fehler hinter den Memes erklären lassen.
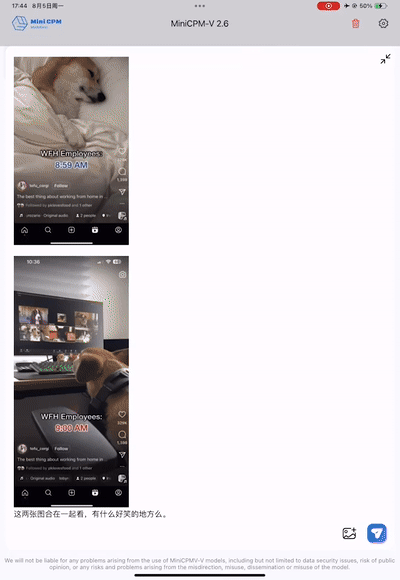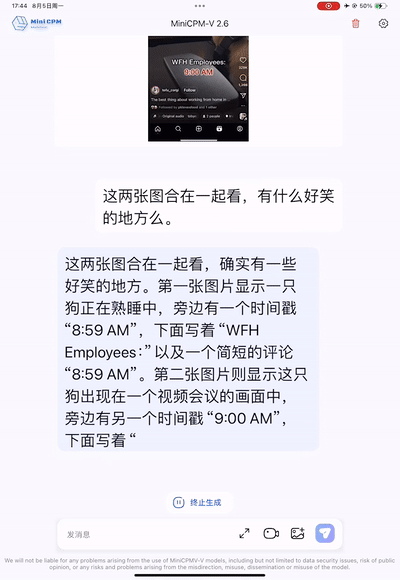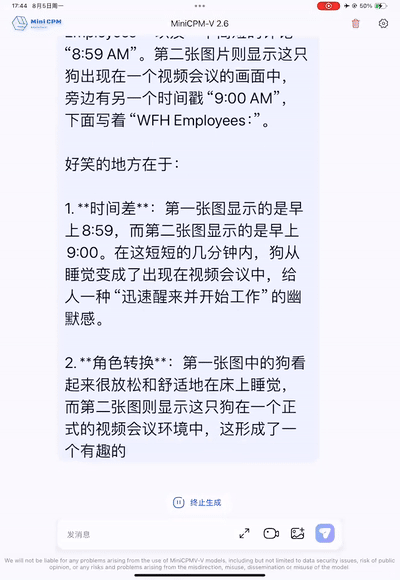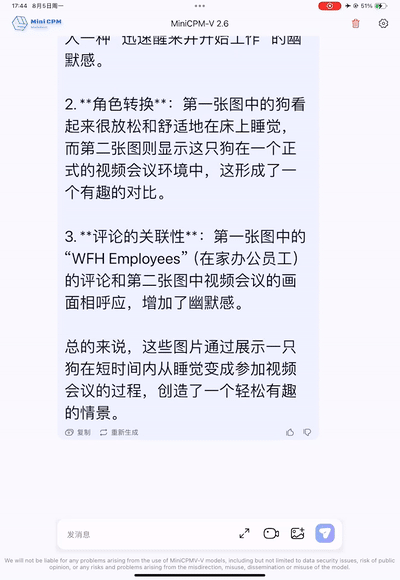
Es kann sogar humorvoller sein als Menschen und den Subtext von Memes einfangen. Als Programmierer können Sie dieses Bild betrachten, lachen und weinen.
Klein gewinnt groß: MiniCPM-V 2.6 gilt als die leistungsstärkste endseitige Multimodalität im Drei-in-Eins-Bereich
Die zentrale Wettbewerbsfähigkeit des geräteseitigen Modells besteht darin, mit kleinen Dingen einen großen Unterschied zu machen.
Laut der offiziellen Einführung von Wallface Intelligence hat MiniCPM-V 2.6 in Bezug auf die Wissenskomprimierungsrate von MiniCPM-V 2.6 die höchste multimodale Pixeldichte für große Modelle (Token Density) erreicht, die doppelt so hoch ist wie die von GPT-4o.
Token-Dichte = Anzahl der Codierungspixel / Anzahl der visuellen Token. Bezieht sich auf die Pixeldichte, die von einem einzelnen Token übertragen wird, dh auf die Dichte der Bildinformationen, die direkt die tatsächliche Betriebseffizienz des multimodalen Modells bestimmt Je höher der Wert, desto höher ist die Betriebseffizienz des Modells.
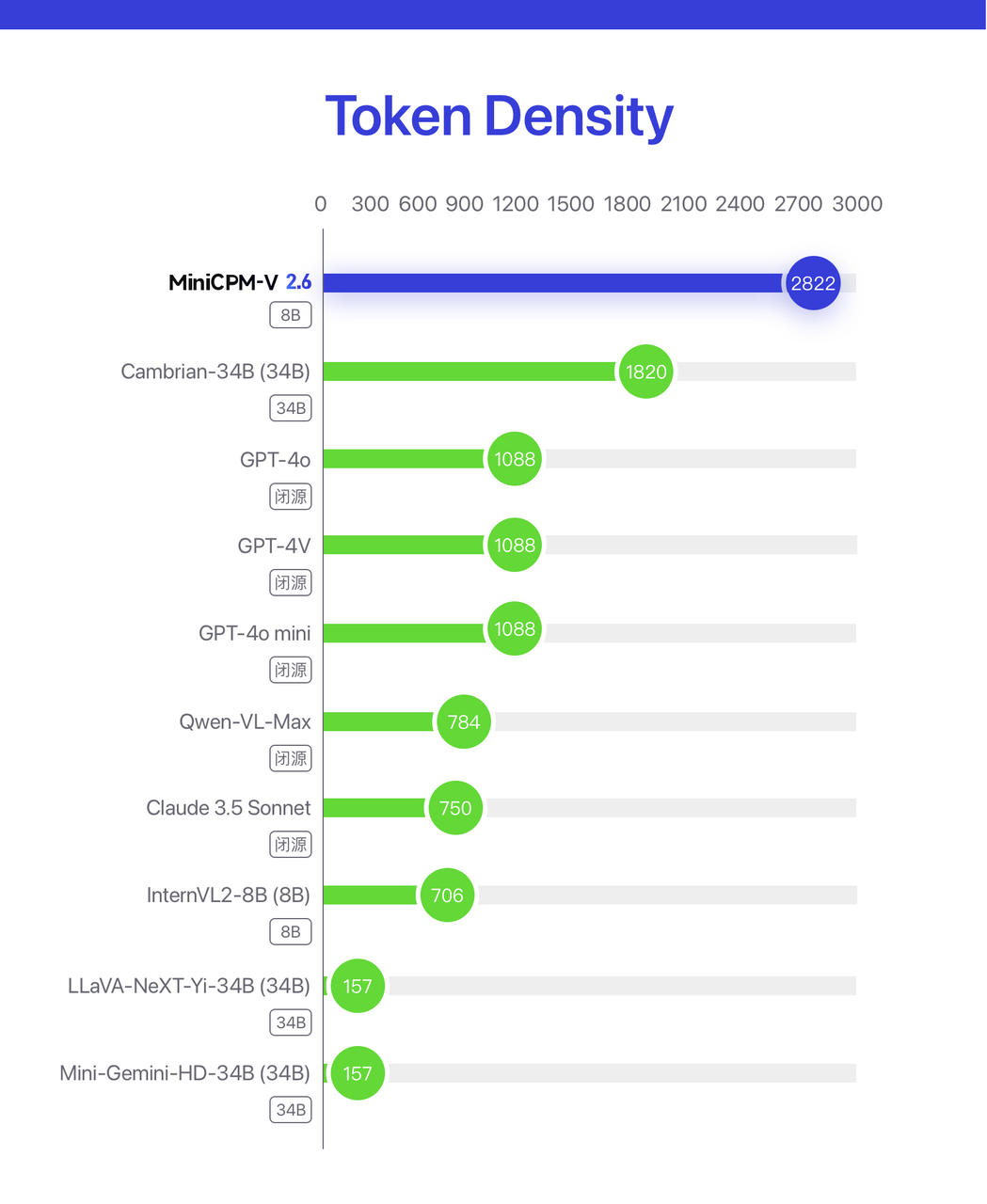
Die Token-Dichte des Closed-Source-Modells wird durch die API-Lademethode geschätzt. Die Ergebnisse zeigen, dass MiniCPM-V 2.6 die höchste Token-Dichte unter allen multimodalen Modellen aufweist und damit seine konsistenten Eigenschaften extremer Effizienz fortsetzt.
Den gemeinsamen Benchmark-Testergebnissen nach zu urteilen, übertrifft MiniCPM-V 2.6 Gemini 1.5 Pro und GPT-4o mini in Bezug auf die Fähigkeiten zum Verstehen einzelner Bilder auf der maßgeblichen umfassenden Bewertungsplattform OpenCompass.
Auf der Liste der Multi-Graph-Bewertungsplattform Mantis-Eval realisiert die Multi-Graph-Joint-Understanding-Fähigkeit von MiniCPM-V 2.6 das Open-Source-Modell SOTA und übertrifft GPT-4V. Auf der Liste der Videobewertungsplattform Video-MME erreicht die Videoverständnisfähigkeit von MiniCPM-V 2.6 die endseitige SOTA und übertrifft GPT-4V.
▲OpenCompass |. Mantis-Eval |. Video-MME-Listenergebnisse
Darüber hinaus implementiert die OCR-Leistung von MiniCPM-V 2.6 das Open-Source- und Closed-Source-Modell SOTA auf OCRBench.
Auf der Halluzinationsbewertungsliste von Object HalBench ist der Halluzinationspegel von MiniCPM-V 2.6 (je niedriger die Halluzinationsrate, desto besser) auch besser als bei vielen kommerziellen Modellen wie GPT-4o, GPT-4V, Claude 3.5 Sonnet usw.
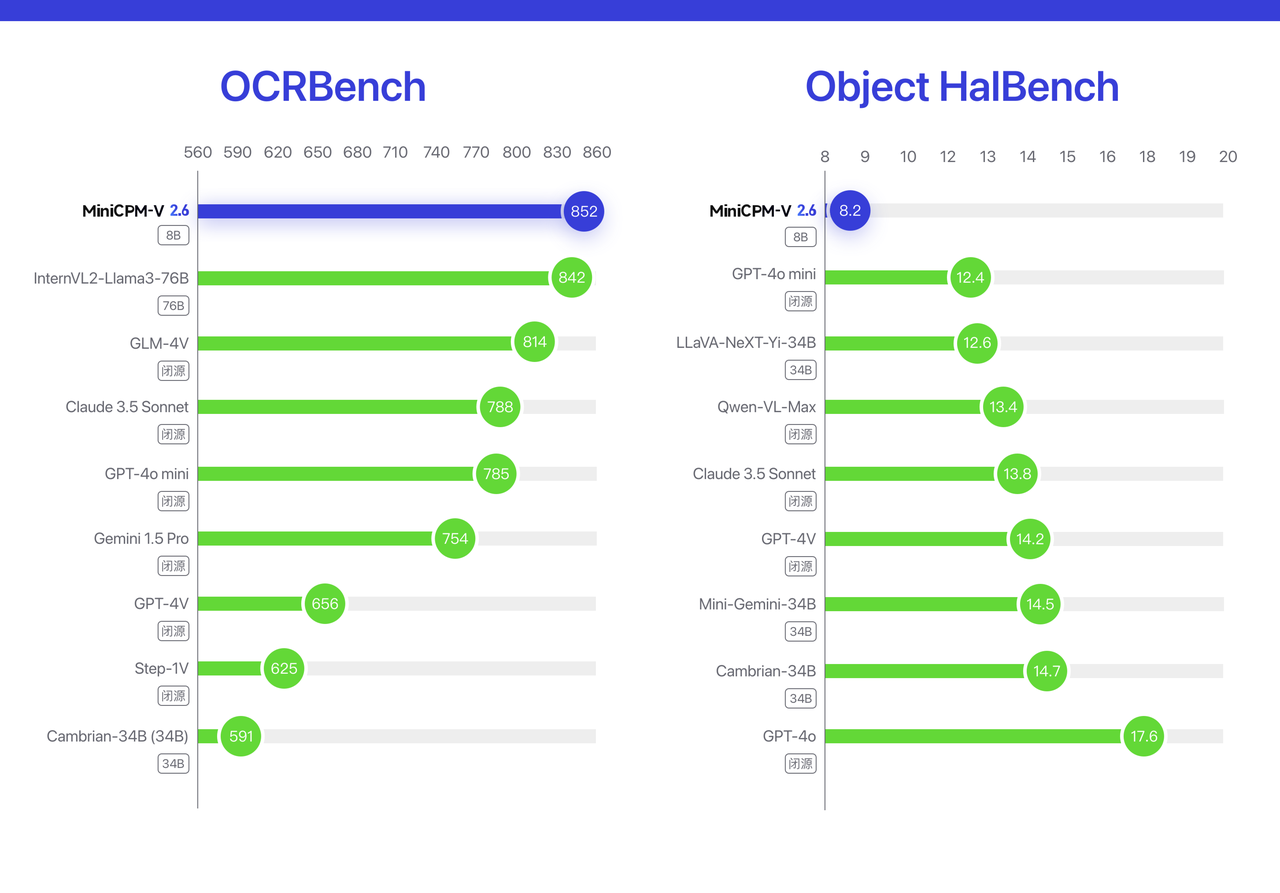
▲Obiect HalBench |. OCRBench-Listenergebnisse
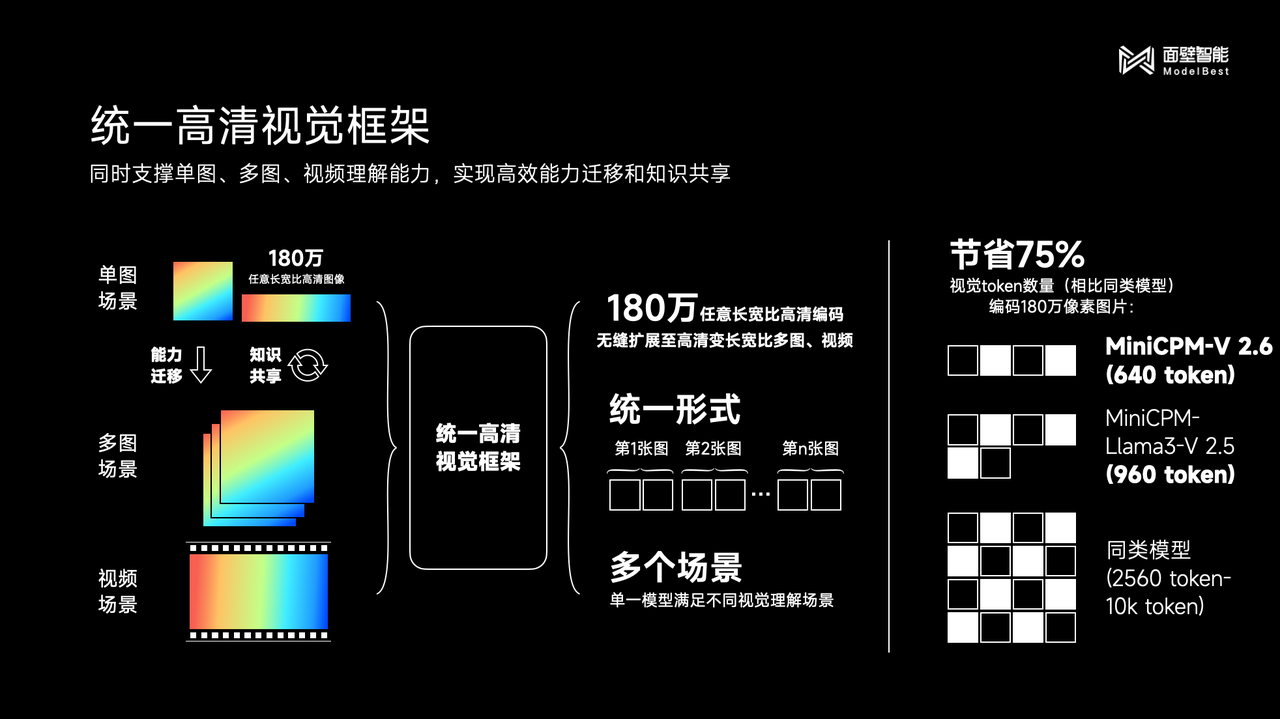
Der Grund für die hervorragende Leistung der neuen Generation der kleinen Stahlkanone MiniCPM-V 2.6 liegt hauptsächlich in der Einführung einer einheitlichen hochauflösenden visuellen Architektur.
Beamte gaben an, dass das einheitliche hochauflösende visuelle Framework nicht nur die multimodalen Vorteile traditioneller Einzelbilder übernimmt, sondern auch eine Kommunikation aus einer Hand ermöglicht.
Beispielsweise migriert die OCR-SOTA-Funktion die Fähigkeiten und den Wissensaustausch der „1,8 Millionen hochauflösenden Bildanalyse“ von MiniCPM-V für Einzelbildszenen, erweitert sie nahtlos auf Mehrbildszenen und Videoszenen und vereinheitlicht diese drei visuellen Erkenntnisse Es löst das Problem der semantischen Modellierung alternierender Texte, teilt den zugrunde liegenden visuellen Darstellungsmechanismus und erreicht eine Einsparung von mehr als 75 % bei der Anzahl visueller Token im Vergleich zu ähnlichen Modellen.
Auf der Grundlage der OCR-Informationsextraktion kann MiniCPM-V 2.6 außerdem komplexe Überlegungen ähnlich wie CoT (Chain of Thought) für Tabelleninformationen durchführen.
Am Beispiel der Olympischen Spiele 2008 konnte das Modell die Gesamtzahl der Goldmedaillen berechnen, die die drei Länder mit den meisten Goldmedaillen gewonnen haben.
[Bild]
Dieser Prozess umfasst:
- Verwenden Sie OCR-Funktionen, um die drei Länder mit den meisten Goldmedaillen im Medaillenspiegel zu identifizieren und zu extrahieren.
- Addieren Sie die Gesamtzahl der Goldmedaillen dieser drei Länder.
In Bezug auf die Glaubwürdigkeit der KI setzt MiniCPM-V 2.6 die traditionellen Vorteile der Xiaogangpao-Serie mit einer Illusionsrate von 8,2 % fort. Darüber hinaus sind die zur Wand gerichtete Ausrichtungstechnologie RLAIF-V und die Anwendung der Ausrichtungstechnologie der Ultra-Serie ebenfalls schwarze Technologien, die sich hinter MiniCPM-V 2.6 verbergen.

Offizielle Daten zeigen, dass die Zahl der Downloads der Xiaogangpao-Serie eine Million überschritten hat. Von der Einführung der endseitigen Bereitstellung, der ersten multimodalen Fähigkeit, über das stärkste endseitige multimodale Modell bis hin zur neuen Ära des umfassenden endseitigen GPT-4V-Benchmarkings dauerte es nur ein halbes Jahr .
„Smart, geschmeidig und so schnell, dass es nicht wie ein Komplettmodell aussieht!“ Dieser Satz ist die treffendste Beschreibung der kleinen Stahlpistolenserie.
Geben Sie Wall-Facing Intelligence mehr Zeit und geben Sie auch großen Modellherstellern im In- und Ausland mehr Zeit. Wir sind fest davon überzeugt, dass Wall-Facing Intelligence in Zukunft weiterhin hochwertige End-Side-KI-Modelle auf den Markt bringen und mit inländischen Modellen zusammenarbeiten wird und ausländische große Modellhersteller, um die Entwicklung endseitiger KI voranzutreiben.
In diesem Prozess werden unabhängige Entwickler und normale Benutzer die größten Nutznießer sein.
Abschließend ist die Open-Source-Adresse von MiniCPM-V 2.6 beigefügt:
GitHub  https://github.com/OpenBMB/MiniCPM-V
https://github.com/OpenBMB/MiniCPM-V
HuggingFace: https://huggingface.co/openbmb/MiniCPM-V-2_6
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo