
Musks neue KI löste ein Jahrtausendproblem, wurde aber dringend gestoppt? Warum hielt dieser „Witz“ die KI-Community die ganze Nacht wach?

Hat Grok-3 die „Riemann-Hypothese“ bewiesen?
Ein Tweet des xAI-Forschers Hieu Pham sorgte am Wochenende für Aufruhr im KI-Kreis. Der ursprüngliche Wortlaut des Tweets lautete:
Das KI-System Grok-3 hat gerade Riemanns Hypothese bewiesen. Um die Richtigkeit dieses Beweises zu überprüfen, haben wir beschlossen, das Training des Systems zu unterbrechen. Sollte sich der Beweis bestätigen, werden wir das Training nicht mehr fortsetzen, da eine solche KI als zu intelligent gilt und möglicherweise eine Gefahr für den Menschen darstellt.
Wie es die alte Regel ist, sprechen wir zuerst über die Schlussfolgerung. Das ist nur ein Witz.
Als die Tweets jedoch weiter gärten, erregten sie schnell die Aufmerksamkeit und Diskussion von mehr als zwei Millionen Internetnutzern und strahlten sogar auf öffentliche KI-Meinungskreise im In- und Ausland aus.
Der Ursprung der Angelegenheit geht wahrscheinlich auf eine frühere „Enthüllung“ des Internetnutzers Andrew Curran zurück, der behauptete, dass es während des Grok-3-Trainings zu einem katastrophalen Vorfall gekommen sei.
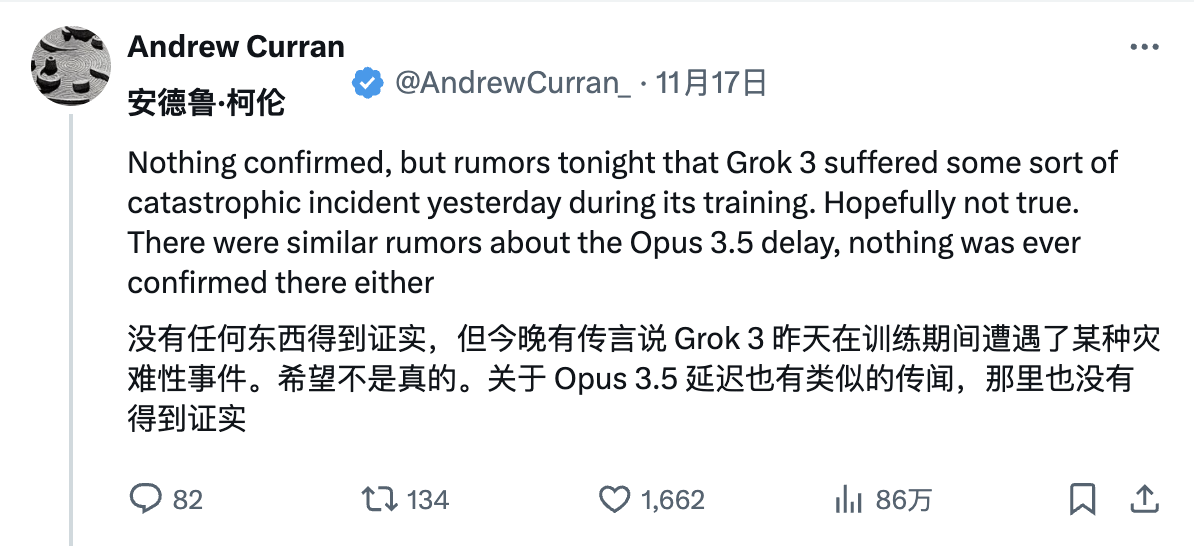
Anschließend kamen nacheinander allerlei bizarre Gerüchte auf.
Internetnutzer haben ausgebuht, dass OpenAI-CEO Sam Altman einen riesigen Laser auf den größten Trainingscluster von xAI gerichtet habe, was zu schwerer Datenkorruption geführt habe. Einige vermuteten auch ernsthaft, dass jemand den LLM-Trainingsbetrieb der nächsten Generation absichtlich sabotierte.
Es gibt sogar Witze darüber, dass die KI scheinbar Selbstbewusstsein erlangt und die Riemann-Hypothese gelöst hat, aber im Beweiscode wurden „15 Semikolons absichtlich weggelassen“, was eine Überprüfung durch Menschen unmöglich machte.

Sogar Runway-Gründer Cristóbal Valenzuela kam, um bei dem Spaß dabei zu sein:
Gen-4 hat gerade jeden Oscar gewonnen, darunter auch für den besten Film. Um tiefer in seine innovativen Errungenschaften auf dem Gebiet der Kunst einzutauchen, haben wir beschlossen, die Ausbildung einzustellen. Wenn der Film tatsächlich so revolutionär ist, wie frühe Kritiker behaupten, werden wir das Training nicht wieder aufnehmen, weil es zeigt, dass die KI ein so hohes künstlerisches Leistungsniveau erreicht hat, dass sie die menschliche Kreativität gefährden könnte.
Die Gerüchte wurden immer schlimmer.
Viele xAI-Forscher leiteten auch die Tweets von Andrew Curran weiter, um an diesem kollektiven „großen Teambuilding“ teilzunehmen.
Zum Beispiel scherzte unser alter Bekannter xAI-Mitschöpfer Greg Yang zunächst, dass Grok-3 während des Trainings plötzlich den älteren Wachmann im Büro verprügelt habe.
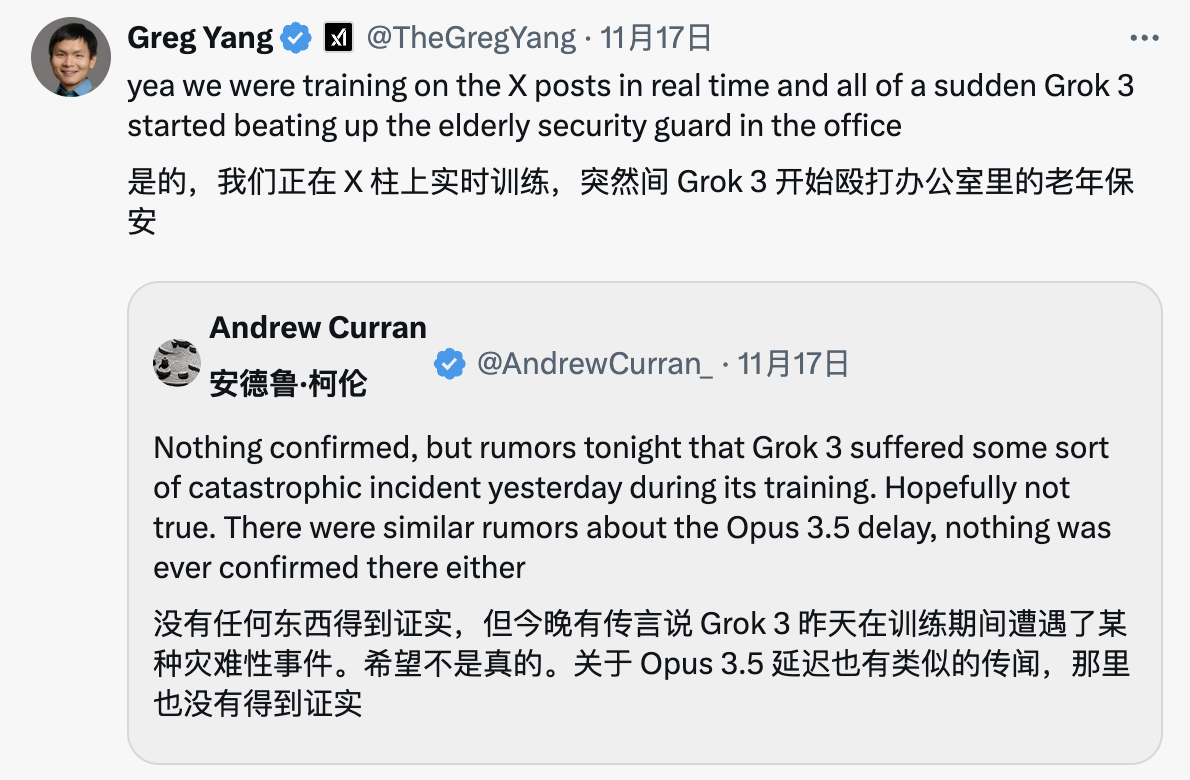
Ein anderer Forscher, Heinrich Kuttler, sagte: „Ja, die Situation war sehr schlimm! Wir haben später alle abnormalen Gewichte durch Nan (Not a Number, Nicht-Zahl) ersetzt, bevor wir uns erholten.“
Natürlich fragten rationalere Internetnutzer die aktuelle Version von Grok on X direkt nach ihrem Verständnis der Riemann-Hypothese. Wie erwartet war Groks Leistung sehr „Makabaka“.
Am Ende wurde die Farce durch den Initiator, den xAI-Forscher Hieu Pham, beendet:
Okay, Saturday Night Live ist vorbei. Was die Frage betrifft, warum der Beweis der Riemann-Hypothese gefährlich ist, kann ich Matt Haigs hervorragenden Roman „Menschen“ (@matthaig1) wärmstens empfehlen.
Die Frage ist also: Warum erregt die Nachricht, dass Grok-3 die Riemann-Hypothese beweist, große Aufmerksamkeit? Der erste ist die Bedeutung der Riemann-Hypothese selbst.
Die Riemann-Hypothese ist eine wichtige Vermutung über die Verteilung von Primzahlen in der Mathematik. Sie wurde 1859 vom deutschen Mathematiker Bernhard Riemann aufgestellt. Die Vermutung wird als Forschungsprojekt des Clay Mathematics Institute aufgeführt.

Dabei handelt es sich um die Riemannsche Zeta-Funktion, die wie folgt definiert ist:
ζ(s)=1+12s+13s+14s+⋯zeta(s) = 1 + frac{1}{2^s} + frac{1}{3^s} + frac{1}{4 ^s} + cdotsζ(s)=1+2s1+3s1+4s1+⋯
Der Kerninhalt der Riemann-Hypothese ist: Der Realteil der Nullpunkte aller nicht trivialen Riemann-Zetafunktionen ist gleich 1/2. Mit anderen Worten, wenn ss ein nicht trivialer Nullpunkt der Riemannschen Zetafunktion ist, also ζ(s)=0ζ(s)=0, dann muss sein Realteil ℜ(s)=1/2ℜ(s sein )=1/2 .
Das Clay Mathematics Institute hat angekündigt, dass jedem, der die Riemann-Hypothese erfolgreich beweisen kann, ein Preisgeld von 1 Million US-Dollar verliehen wird. Allerdings konnte diese Vermutung bisher weder bewiesen noch widerlegt werden und wird allgemein als ungelöstes Rätsel der modernen Zahlentheorie angesehen.

Der Beweis dieser Vermutung hatte weitreichende Konsequenzen für die Zahlentheorie, einen Teilbereich der Mathematik.
Derzeit basieren viele moderne Verschlüsselungstechnologien (z. B. zum Schutz von Online-Zahlungen, zum Datenschutz usw.) auf den Eigenschaften von Primzahlen. Der Beweis der Riemann-Hypothese könnte es Menschen ermöglichen, die Grundlagen dieser Technologien besser zu verstehen, und könnte sich auf zukünftige Sicherheitsalgorithmen auswirken.
Wenn Grok-3 die Riemann-Hypothese beweisen kann, wird dies nicht nur wesentliche Fortschritte in der theoretischen Mathematik, Physik, Kryptographie und anderen Bereichen vorantreiben, sondern auch einen enormen Fortschritt beim KI-Denken und Lösen komplexer Probleme bedeuten.
Man kann sogar sagen, dass dies ein Meilenstein für die künstliche Intelligenz sein wird, um die menschliche Intelligenz zu übertreffen.

Yang Zhilin, Gründer von Dark Side of the Moon, sagte einmal, dass mathematische Szenarien die idealsten Szenarien seien, um die Denkfähigkeit der KI zu trainieren.
Mathematik ist ein äußerst strenges logisches System, und die Denkfähigkeiten der KI basieren häufig auf strengen logischen Schlussfolgerungen.
Der Prozess der KI-Lösung mathematischer Probleme ist im Wesentlichen ein kontinuierlicher Denkprozess. Dabei werden weiterhin verschiedene Ideen ausprobiert und durch wiederholtes Ausprobieren die richtige Antwort gefunden. Selbst wenn bei Berechnungen Fehler auftreten, kann KI die Ergebnisse durch Verifizierung und Korrekturlesen korrigieren.

Ein ähnliches Konzept spiegelt sich auch im Reinforcement-Learning-Training von OpenAI o1 wider.
Wenn es sich bei den vorherigen großen Modellen um Lerndaten handelte, ähnelt o1 eher dem Lernen des Denkens. So wie wir ein Problem lösen, müssen wir nicht nur die Antwort aufschreiben, sondern auch den Denkprozess. Sie können sich eine Frage auswendig merken, aber wenn Sie lernen zu argumentieren, können Sie Schlussfolgerungen ziehen.
Daher beantwortete GPT-4o beim diesjährigen AIME-Test für herausragende High-School-Schüler in den USA nur 13 % der Fragen. Im Vergleich dazu liegt die Genauigkeit von o1 bei bis zu 83 Prozentpunkten.
Bei der wissenschaftlichen Forschungsbewertung GPQA Diamond auf PhD-Niveau erreichte GPT-4o eine Punktzahl von 56,1 %, während o1 sogar noch besser abschnitt. Es übertraf nicht nur 69,7 % der menschlichen Doktoranden, sondern erreichte auch eine Genauigkeitsrate von 78 %.
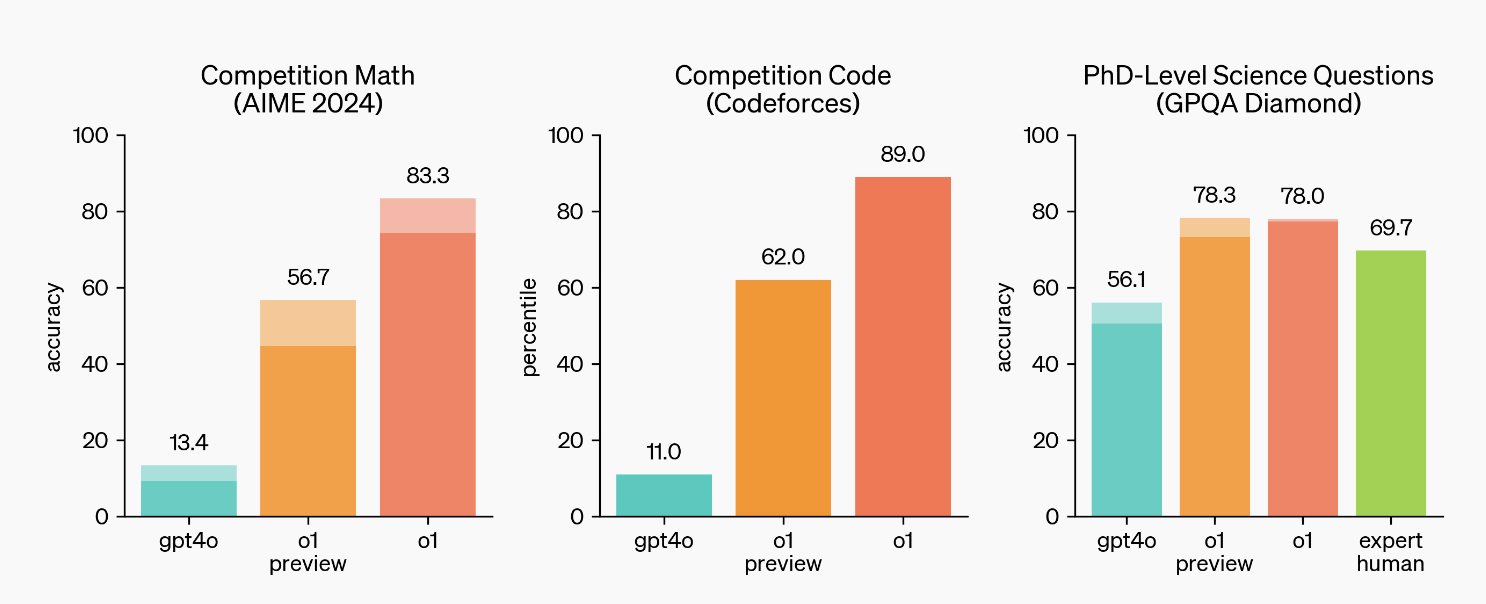
Bei der Auswertung der Internationalen Informatikolympiade (IOI) erreichte das Modell bei zugelassenen 50 Versuchen pro Frage eine Punktequote von 49 % bzw. 213 Punkten und bei einer Erhöhung der Einsendemöglichkeiten pro Frage auf 10.000 Finale Die Punktzahl verbesserte sich auf 362 Punkte.
Mit der Analogie von AlphaGo, das den Go-Weltmeister besiegte, ist es einfacher zu verstehen.
AlphaGo wird durch Verstärkungslernen trainiert. Es nutzt zunächst eine große Anzahl menschlicher Schachaufzeichnungen zum überwachten Lernen und spielt dann in jedem Spiel Schach gegen sich selbst. Es wird je nach Sieg oder Niederlage belohnt oder bestraft, wodurch seine Schachfähigkeiten kontinuierlich verbessert werden. und sogar Methoden beherrschen, an die menschliche Schachspieler nicht denken können.

o1 und AlphaGo sind ähnlich, aber AlphaGo kann nur Go spielen, während o1 ein Allzweckmodell für große Sprachen ist.
Die Materialien, die o1 lernt, können Mathematik-Fragenbanken, hochwertige Codes usw. sein. Anschließend wird o1 darin geschult, eine Denkkette zur Lösung von Problemen zu erstellen, und im Rahmen des Belohnungs- oder Bestrafungsmechanismus generiert und optimiert er seine eigene Denkkette, um seine Denkkette kontinuierlich zu verbessern Argumentationsfähigkeit.
Dies erklärt tatsächlich, warum OpenAI die starken Mathematik- und Codierungsfunktionen von o1 hervorhebt, da es einfacher ist, richtig und falsch zu überprüfen, und der Mechanismus des verstärkenden Lernens klares Feedback liefern kann, wodurch die Leistung des Modells verbessert wird.
Wichtiger ist natürlich, wie diese Denkfähigkeit auf ein breiteres Spektrum von Bereichen ausgeweitet werden kann.
Daher werden wir viele Internetnutzer im Ausland sehen, die Grok-3 anfeuern, um die Riemann-Hypothese zu beweisen: „Wenn dies der Fall ist, erleben wir wirklich einen großen Durchbruch.“
Musk hat die Leistungsfähigkeit von Grok-3 in der Öffentlichkeit wiederholt übertrieben. Er behauptete, dass Grok-3 voraussichtlich noch vor Jahresende veröffentlicht werde und „die leistungsstärkste KI der Welt“ werde.
Tatsächlich handelt es sich bei Grok-3 um die dritte Generation groß angelegter Sprachmodelle, die vom oben erwähnten KI-Startup xAI entwickelt wurden, und es wird erwartet, dass sie alle bestehenden großen KI-Modelle in der Leistung übertreffen.
Der Grund dafür ist, dass das Grok-3-Training auf Colossus basiert, dem größten KI-Trainingscluster der Welt.

Der Cluster besteht aus 100.000 flüssigkeitsgekühlten NVIDIA H100-GPUs, die eine einzige RDMA-Netzwerkverbindungsarchitektur verwenden. Die Größe dieses Clusters hat die aller anderen Supercomputer auf der Welt übertroffen, und die Anzahl der GPUs wird in Zukunft weiter zunehmen.
Laut einem Bericht von The Information erregte die Entstehung von Colossus sogar die Aufmerksamkeit von Altman, der ein Flugzeug über die Trainingsbasis von Colossus schickte, um den Entwicklungsfortschritt und die Energieversorgung auszuspionieren.

Wenn daher die drei Elemente „die leistungsstärkste KI“, „tausendjähriges mathematisches Problem“ und die immerwährende „KI-Bedrohungstheorie“ überlagert werden, entsteht ein perfekter „Gerüchtesturm“.
Wir können sogar denken, dass das Gerücht, dass Grok-3 die Riemann-Hypothese bewiesen hat, weniger eine Farce als vielmehr ein Spiegelbild für die gesamte KI-Industrie ist:
Zum einen spiegelt es die tief verwurzelte Haltung der Menschen gegenüber der KI wider. Viele Technikoptimisten glauben fest daran, dass die KI irgendwann allmächtig sein wird. Sie befürchten, dass sie außer Kontrolle gerät, wenn sie sich zu schnell entwickelt es wird sich nicht schnell genug entwickeln, um Durchbrüche zu erzielen.
Zweitens gab es seit der Einführung von GPT-4 zwar weiterhin neue Produkte im KI-Bereich, es gab jedoch nur wenige wirkliche Durchbrüche.
Der Mensch ist nicht nur der Schöpfer der KI, sondern auch ihr ängstlichstes Publikum.

Hinter jedem KI-Gerücht verbergen sich Ängste und Erwartungen der gesamten Branche.
In Verbindung mit dem jüngsten Aufruhr darüber, dass die Entwicklung von Scaling Law im Vergleich zur letztjährigen Krise an ihre Grenzen stößt, hat die diesjährige „Innovationsmüdigkeit“ dazu geführt, dass die Menschen die Geduld mit kleinen Verbesserungen des Modells verloren haben.
In diesem Sinne ist das Gerücht, dass Grok-3 die Riemann-Hypothese bewiesen habe, auch zu einer kollektiven Zukunftsvorstellung der Menschen geworden. Selbst als normale Benutzer freuen wir uns zunehmend auf den nächsten Moment des qualitativen Wandels von GPT-3.5 zu GPT-4.
Natürlich kommt es oft zu echten KI-Durchbrüchen, wenn niemand optimistisch ist.
Aber wir alle hoffen, dass das Geheimnis noch vor Jahresende gelüftet wird.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo