
5 Wahrheiten über DeepSeek, die missverstanden wurden, enthüllt vom KI-Chef selbst

Lassen Sie es uns noch einmal Revue passieren lassen: Xiaohong ist auf Unterstützung angewiesen, und Big Red ist auf Leben angewiesen.
DeepSeek ist während des Frühlingsfestes populär geworden, und wenn es populär wird, wird es natürlich noch mehr Probleme geben. Insbesondere angesichts der komplizierten Veränderungen in der Situation im Ausland hat die chinesische Herkunft von DeepSeek viele Gerüchte hervorgerufen.
Tanishq Mathew Abraham, der ehemalige Forschungsdirektor von Stability AI, trat gestern vor und wies als Brancheninsider auf einige ganz besondere Punkte von DeepSeek hin:
1. Die Leistung ist tatsächlich so gut wie bei o1 von OpenAI, einem hochmodernen Modell, das zeigt, dass Open Source tatsächlich zu Closed Source aufgeschlossen hat
2. Im Vergleich zu anderen hochmodernen Modellen ist DeepSeek mit relativ geringen Schulungskosten abgeschlossen
3. Die benutzerfreundliche Oberfläche, kombiniert mit sichtbaren Gedankenketten auf der Website und in den Apps, lockt Millionen neuer Benutzer an
Darüber hinaus verfasste er einen langen Blogbeitrag als Reaktion auf mehrere populäre Gerüchte, in dem er die (empörenden) Bemerkungen rund um DeepSeek analysierte und erklärte.
Das Folgende ist ein Blogbeitrag mit bearbeitetem Inhalt:
Am 20. Januar 2025 veröffentlichte ein chinesisches KI-Unternehmen namens DeepSeek sein Open-Source-Inferenzmodell R1. Da es sich bei DeepSeek um ein chinesisches Unternehmen handelt, haben die Vereinigten Staaten und ihr AGI-Unternehmen verschiedene „nationale Sicherheitsbedenken“. Aus diesem Grund haben sich Fehlinformationen darüber weit verbreitet. **
Der Zweck dieses Artikels besteht darin, die vielen extrem schlechten Ansichten in Bezug auf KI zu widerlegen, die seit seiner Veröffentlichung über DeepSeek geäußert wurden. Gleichzeitig biete ich als KI-Forscher, der an der Spitze der generativen KI arbeitet, eine ausgewogenere Perspektive.
Gerücht 1: Verdächtig! DeepSeek ist ein chinesisches Unternehmen, das plötzlich auftauchte
Völlig falsch, im Januar 2025 wird fast jeder generative KI-Forscher von DeepSeek gehört haben. DeepSeek hat sogar Monate vor der vollständigen Veröffentlichung eine Vorschau von R1 veröffentlicht!
Wer dieses Gerücht verbreitet, arbeitet wahrscheinlich nicht im Bereich der künstlichen Intelligenz – es ist lächerlich und äußerst eingebildet zu glauben, man wisse alles, was es zu wissen gibt, wenn man sich nicht auf diesem Gebiet auskennt.
Das erste Open-Source-Modell von DeepSeek, DeepSeek-Coder, wurde im November 2023 veröffentlicht. Zu dieser Zeit handelte es sich um die führenden Code-LLMs der Branche (Anmerkung des Herausgebers: Sprachmodelle konzentrierten sich auf das Verstehen und Generieren von Code). Wie die folgende Grafik zeigt, lieferte DeepSeek innerhalb eines Jahres weiter aus und erreichte R1: 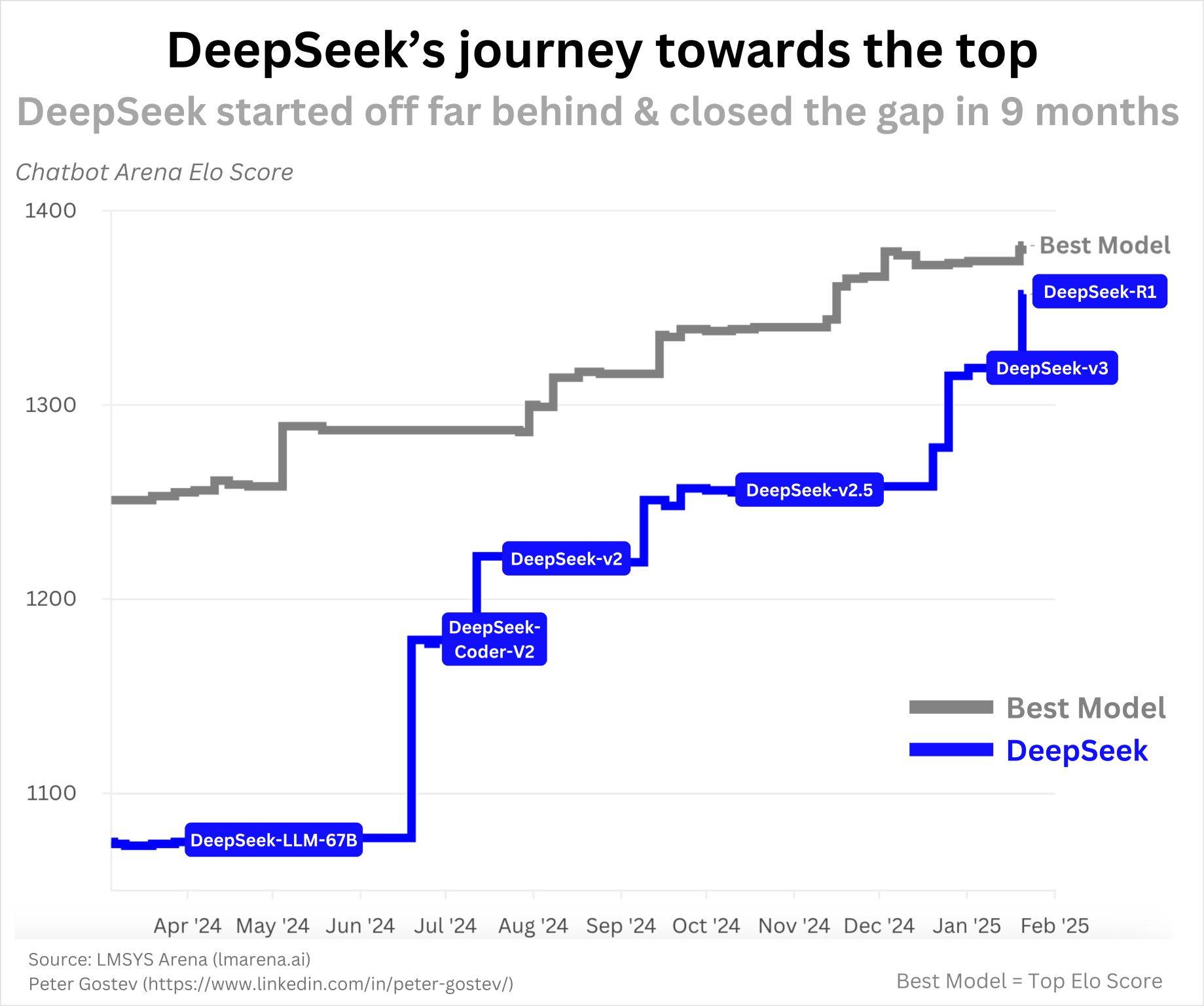
Das war kein Erfolg über Nacht und es gibt nichts Verdächtiges an der Geschwindigkeit ihrer Fortschritte. Da die KI so schnell voranschreitet und sie über ein offensichtlich effizientes Team verfügen, erscheint es mir sehr vernünftig, solche Fortschritte in einem Jahr zu erzielen.
Wenn Sie wissen möchten, welche Unternehmen nicht im Fokus der Öffentlichkeit stehen, aber im KI-Bereich vielversprechend sind, empfehle ich Ihnen, auf Qwen (Alibaba), YI (Zero Yiwu), Mistral, Cohere und AI2 zu achten. Es ist wichtig zu beachten, dass sie SOTA-Modelle nicht so regelmäßig veröffentlichen wie DeepSeek, aber beide haben das Potenzial, hervorragende Modelle zu veröffentlichen, wie sie in der Vergangenheit gezeigt haben.
Gerücht 2: Lügen! Dieses Modell kostet keine 6 Millionen Dollar
Das ist eine interessante Frage. Solche Gerüchte deuten darauf hin, dass DeepSeek vermeiden wollte, zuzugeben, dass sie illegale Hinterzimmergeschäfte abgeschlossen hatten, um Rechenressourcen zu erhalten, zu denen sie (aufgrund von Exportkontrollen) keinen Zugang haben sollten, und so die Wahrheit über die Kosten der Modellschulung verheimlichte.
Erstens verdient die Zahl von 6 Millionen US-Dollar einen genauen Blick. Es wird im DeepSeek-V3-Papier erwähnt, das einen Monat vor dem DeepSeek-R1-Papier veröffentlicht wurde:

DeepSeek-V3 ist das Basismodell von DeepSeek-R1, was bedeutet, dass DeepSeek-R1 DeepSeek-V3 plus einige zusätzliche Schulungen zum verstärkenden Lernen ist. In gewisser Weise sind die Kosten also bereits ungenau, da die zusätzlichen Kosten für die Schulung zum verstärkten Lernen nicht berücksichtigt sind. Aber das würde wahrscheinlich nur ein paar hunderttausend Dollar kosten.
Okay, sind die im DeepSeek-V3-Papier genannten 5,5 Millionen US-Dollar falsch? Zahlreiche Analysen basierend auf GPU-Kosten, Datensatzgröße und Modellgröße haben zu ähnlichen Schätzungen geführt. Beachten Sie, dass DeepSeek V3/R1 zwar ein 671B-Parametermodell, aber ein Expertenmischungsmodell ist, was bedeutet, dass alle Funktionsaufrufe/Weiterleitungsdurchgänge des Modells nur ~37B-Parameter verwenden, was der Wert ist, der zur Berechnung der Trainingskosten verwendet wird.
Bei den Kosten von DeepSeek handelt es sich jedoch um eine Schätzung der Kosten dieser GPUs basierend auf den aktuellen Marktpreisen. Wir kennen die Kosten ihres 2048 H800 GPU-Clusters nicht wirklich (Hinweis: nicht H100s, das ist ein weit verbreitetes Missverständnis und eine Verwirrung!). In der Regel kosten zusammenhängende GPU-Cluster weniger, wenn sie in großen Mengen gekauft werden, sodass sie möglicherweise sogar günstiger sind.
Aber hier ist der Haken: Am Ende sind es die Betriebskosten. Bevor dies erfolgreich war, wurden wahrscheinlich viele Experimente und Ablationen in kleinem Maßstab durchgeführt, was erhebliche Kosten verursacht hätte, über die hier jedoch nicht berichtet wird.
Darüber hinaus können viele weitere Kosten anfallen, beispielsweise das Gehalt des Forschers. SemiAnalysis berichtet, dass die Gehälter der DeepSeek-Forscher Gerüchten zufolge bei rund 1 Million US-Dollar liegen. Dies entspricht dem hohen Gehaltsniveau von AGI-Spitzenlaboren wie OpenAI oder Anthropic.
Bei der Berichterstattung und dem Vergleich der Schulungskosten für verschiedene Modelle sind in der Regel die Kosten für den endgültigen Schulungslauf von größter Bedeutung. Aufgrund der schlechten Rhetorik und der Verbreitung von Fehlinformationen wird jedoch argumentiert, dass die zusätzlichen Kosten die kostengünstige und effiziente Natur des Betriebs von DeepSeek in Frage stellen. Das ist äußerst ungerecht. Die Kosten sind erheblich, sowohl aus Sicht der Ablation/Experimente als auch aus Sicht der Forschervergütung in anderen AGI-Spitzenlabors, aber diese werden in Diskussionen wie dieser oft nicht erwähnt!
Gerücht 3: So günstig? Alle US-amerikanischen AGI-Unternehmen verschwenden Geld und sind pessimistisch gegenüber Nvidia
Ich denke, das ist eine weitere ziemlich dumme Idee. DeepSeek ist im Training tatsächlich effizienter als viele andere LLMs. Ja, es ist sehr wahrscheinlich, dass viele der hochmodernen Labore in Amerika rechnerisch ineffizient sind. Dies bedeutet jedoch nicht unbedingt, dass es eine schlechte Sache ist, über mehr Rechenressourcen zu verfügen.
Ehrlich gesagt, wenn ich solche Ansichten höre, ist mir klar, dass sie weder die Skalierungsgesetze noch die Denkweise des AGI-CEO (und jedes anderen, der als KI-Experte gilt) verstehen. Lassen Sie mich einige Gedanken zu diesem Thema äußern.
Skalierungsgesetze zeigen, dass wir eine bessere Leistung erzielen, solange wir weiterhin mehr Rechenleistung in das Modell stecken. Natürlich haben sich die genauen Methoden und Aspekte der KI-Skalierung im Laufe der Zeit geändert: zunächst Modellgröße, dann Datensatzgröße und jetzt Inferenzzeitberechnung und synthetische Daten.
Der allgemeine Trend, dass mehr Rechenleistung gleichbedeutend mit besserer Leistung ist, scheint sich seit dem ursprünglichen Transformer im Jahr 2017 fortzusetzen.
Ein effizienteres Modell bedeutet, dass Sie bei einem gegebenen Rechenbudget eine bessere Leistung erzielen, aber mehr Rechenressourcen sind immer noch besser. Ein effizienteres Modell bedeutet, dass Sie mit weniger Rechenressourcen mehr erreichen können, aber mit mehr Rechenressourcen mehr!
Möglicherweise haben Sie Ihre eigene Meinung zu Skalierungsgesetzen. Man könnte meinen, dass ein Plateau bevorsteht. Man könnte meinen, dass die Wertentwicklung in der Vergangenheit kein Hinweis auf zukünftige Ergebnisse ist, wie es in der Finanzwelt heißt.
Was aber, wenn alle größten AGI-Unternehmen darauf wetten, dass die Skalierungsgesetze lange genug gelten, um AGI und ASI zu ermöglichen? Davon sind sie überzeugt, dass die einzig logische Vorgehensweise darin besteht, sich mehr Rechenleistung anzuschaffen.
Jetzt denken Sie vielleicht: „NVIDIAs GPUs werden bald veraltet sein, schauen Sie sich AMD, Cerebras, Graphcore, TPUs, Trainium usw. an.“ Es gibt Millionen von Hardwareprodukten, die auf KI abzielen und alle versuchen, mit NVIDIA zu konkurrieren. Einer von ihnen könnte in Zukunft gewinnen. In diesem Fall werden sich diese AGI-Unternehmen vielleicht an sie wenden – aber das hat absolut nichts mit dem Erfolg von DeepSeek zu tun.
Persönlich glaube ich nicht, dass es angesichts der aktuellen Marktdominanz und des anhaltenden Innovationsniveaus von NVIDIA starke Beweise dafür gibt, dass andere Unternehmen NVIDIAs Dominanz bei KI-Beschleunigungschips in Frage stellen werden.
Insgesamt verstehe ich nicht, warum DeepSeek bedeutet, dass Sie gegenüber NVIDIA pessimistisch sein sollten. Möglicherweise haben Sie andere Gründe, NVIDIA gegenüber pessimistisch zu sein, und diese Gründe mögen sehr triftig und stichhaltig sein, aber DeepSeek scheint mir nicht der richtige zu sein.
Gerücht 4: Es ist nur eine Nachahmung! DeepSeek hat keine nennenswerten Neuerungen vorgenommen
Fehler. **Es gab viele Innovationen im Sprachmodelldesign und bei den Trainingsmethoden, einige wichtiger als andere**. Hier sind einige (keine vollständige Liste, Sie können die Dokumente zu DeepSeek-V3 und DeepSeek-R1 für weitere Details lesen):
Multi-Head Latent Attention (MLA) – LLMs beziehen sich im Allgemeinen auf Transformer, die den sogenannten Multi-Head-Attention-Mechanismus (MHA) nutzen. Das DeepSeek-Team hat eine Variante des MHA-Mechanismus entwickelt, die sowohl speichereffizienter ist als auch eine bessere Leistung bietet.
GRPO und Verifiable Rewards – KI-Praktiker versuchen seit seiner Veröffentlichung, o1 zu replizieren. Da OpenAI seine Funktionsweise ziemlich verschwiegen hat, mussten die Leute verschiedene Methoden ausprobieren, um o1-ähnliche Ergebnisse zu erzielen. Es gab verschiedene Versuche, wie zum Beispiel die Monte-Carlo-Baumsuche (die Methode, mit der Google DeepMind bei Go gewinnt), die sich als weniger vielversprechend herausstellte als zunächst erwartet.
DeepSeek zeigt, dass eine sehr einfache Reinforcement Learning (RL)-Pipeline tatsächlich o1-ähnliche Ergebnisse erzielen kann. Darüber hinaus haben sie eine eigene Variante des gängigen PPO-RL-Algorithmus namens GRPO entwickelt, die effizienter ist und eine bessere Leistung erbringt. Ich denke, viele Leute in der KI-Community fragen sich: Warum haben wir das nicht schon früher versucht?
DualPipe – Beim Training eines KI-Modells auf mehreren GPUs sind viele Effizienzaspekte zu berücksichtigen. Sie müssen herausfinden, wie das Modell und der Datensatz auf alle GPUs verteilt sind, wie die Daten durch die GPUs fließen usw. Außerdem müssen Sie die Datenübertragung zwischen GPUs reduzieren, da diese sehr langsam ist und nach Möglichkeit am besten auf jeder einzelnen GPU abgewickelt wird. Unabhängig davon gibt es viele Möglichkeiten, diese Art von Multi-GPU-Training einzurichten, und das DeepSeek-Team hat eine neue, effizientere und schnellere Lösung namens DualPipe entwickelt.
Wir haben großes Glück, dass DeepSeek im Gegensatz zum amerikanischen AGI-Unternehmen diese Innovationen vollständig als Open Source bereitgestellt und detaillierte Einführungen geschrieben hat. Jetzt kann jeder von diesen innovativen Möglichkeiten zur Verbesserung seines eigenen KI-Modelltrainings profitieren.
Gerücht 5: DeepSeek „bezieht“ Wissen aus ChatGPT
David Sacks (der KI- und Kryptografieriese der US-Regierung) und OpenAI behaupten, DeepSeek habe das Wissen von ChatGPT mithilfe einer Technik namens Destillation „abgesaugt“.
Zunächst einmal wird das Wort „Destillation“ hier sehr seltsam verwendet. Typischerweise bezieht sich Destillation auf das Training der vollständigen Wahrscheinlichkeiten (Logits) aller möglichen nächsten Wörter (Tokens), aber diese Informationen können nicht einmal über ChatGPT offengelegt werden.
Aber okay, sagen wir einfach, wir reden über Training mit Text, der von ChatGPT generiert wird, obwohl das nicht die typische Verwendung des Begriffs ist.
OpenAI und seine Mitarbeiter behaupten, dass DeepSeek selbst ChatGPT verwendet, um Text zu generieren und darauf zu trainieren. Sie haben keine Beweise vorgelegt, aber wenn das wahr ist, dann hat DeepSeek eindeutig gegen die Nutzungsbedingungen von ChatGPT verstoßen. Ich denke, die rechtlichen Konsequenzen für ein chinesisches Unternehmen sind unklar, aber ich weiß nicht viel darüber.
Beachten Sie, dass dies nur dann der Fall ist, wenn DeepSeek selbst die für das Training verwendeten Daten generiert hat. Wenn DeepSeek von ChatGPT generierte Daten aus anderen Quellen verwendet (derzeit gibt es viele öffentliche Datensätze), ist diese „Destillation“ oder das Training synthetischer Daten meines Wissens nach nicht durch die TOS verboten.
Dennoch schmälert dies meiner Meinung nach nicht die Erfolge von DeepSeek. Was mich als Forscher mehr beeindruckt hat als der Effizienzaspekt von DeepSeek, war die Nachbildung von o1. Ich bezweifle stark, dass die „Destillation“ von ChatGPT hilfreich sein wird. Dieser Zweifel rührt ausschließlich von der Tatsache her, dass der CoT-Denkprozess von o1 nie veröffentlicht wurde. Wie kann DeepSeek ihn also erfahren?
Darüber hinaus sind viele LLMs tatsächlich auf ChatGPT (sowie andere LLMs) trainiert, und in jedem neu gescrapten Internetinhalt wird es natürlich KI-Text geben.
Alles in allem bedeutet die Annahme, dass das Modell von DeepSeek gut funktioniert, nur weil es einfach die Perspektive von ChatGPT verdeutlicht, die Realität der Technik, Effizienz und architektonischen Innovation von DeepSeek zu ignorieren.
Sollten wir uns über Chinas Hegemonie in der künstlichen Intelligenz Sorgen machen?
Vielleicht ein bisschen? Ehrlich gesagt hat sich am chinesisch-amerikanischen KI-Wettbewerb im Vergleich zu vor zwei Monaten im Wesentlichen nicht viel geändert. Im Gegenteil, die Reaktion von außen ist ziemlich heftig, was sich durch Änderungen in der Finanzierung, Aufsicht usw. tatsächlich auf die gesamte KI-Landschaft auswirken kann.
Die Chinesen waren in der KI schon immer konkurrenzfähig, und DeepSeek macht es jetzt unmöglich, sie zu ignorieren.
Das typische Argument zu Open Source ist, dass wir unsere Technologie nicht offen teilen sollten, weil China hinterherhinkt, damit China aufholen kann. Aber offensichtlich hat China aufgeholt, sie haben tatsächlich schon vor langer Zeit aufgeholt, sie sind tatsächlich führend im Bereich Open Source, daher ist nicht klar, ob eine weitere Verschärfung unserer Technologie tatsächlich so viel helfen wird.
Beachten Sie, dass Unternehmen wie OpenAI, Anthropic und Google DeepMind definitiv bessere Modelle als DeepSeek R1 haben. Beispielsweise sind die Benchmark-Ergebnisse des o3-Modells von OpenAI ziemlich beeindruckend, und möglicherweise befindet sich bereits ein Nachfolgemodell in der Entwicklung.
Aufbauend auf dieser Grundlage und mit erheblichen zusätzlichen Investitionen wie Project Stargate und der bevorstehenden Finanzierungsrunde von OpenAI werden OpenAI und andere hochmoderne US-Labore über ausreichend Rechenleistung verfügen, um ihre Führungsposition zu behaupten.
Natürlich wird China erhebliche zusätzliche Mittel in die KI-Entwicklung investieren. Insgesamt wird die Konkurrenz also immer härter! Aber ich denke, dass der Weg für die Spitzenlabore der US-amerikanischen AGI, weiterhin an der Spitze zu bleiben, immer noch recht vielversprechend ist.
abschließend
Einerseits versuchen einige KI-Leute, insbesondere diejenigen bei OpenAI, DeepSeek herunterzuspielen. Andererseits haben einige Kritiker und selbsternannte Experten überreagiert auf DeepSeek.
Es sollte darauf hingewiesen werden, dass OpenAI/Anthropic/Meta/Google/xAI/NVIDIA usw. hier noch nicht abgeschlossen sind. Nein, DeepSeek hat (wahrscheinlich) nicht über das, was sie getan haben, gelogen. Unabhängig davon muss man zugeben: DeepSeek verdient Anerkennung, das R1 ist ein beeindruckendes Modell.
https://www.tanishq.ai/blog/posts/deepseek-delusions.html
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo