
Der größte Skandal im KI-Kreis dieses Jahres wurde aufgedeckt! Llama 4 wurde im Training als Betrüger entlarvt, der eigentliche Test scheiterte kläglich und das Kernpersonal trat verärgert zurück

Gestern wurde Meta Llama 4 aus heiterem Himmel veröffentlicht.
Die Parameter auf dem Papier sind sehr hoch. Es soll ein natives multimodales MOE-Modell sein, das DeepSeek V3 übertrifft, und ein Biest mit 2 Billionen Parametern. Sogar Meta-CEO Zuckerberg hat ein Video gepostet, in dem er die Flagge schwenkt und „Llama 4th“ zur Begrüßung ruft.
Der Jubel war nur von kurzer Dauer. Als Internetnutzer mit dem Testen begannen, erhielten sie fast überwiegend negative Bewertungen. Es kann als das größte „Rollover“-Event in der KI-Branche in diesem Jahr bezeichnet werden.
In der Community r/LocalLLaMA (die als Llama-„Postleiste“ verstanden werden kann), die sich der lokalen Bereitstellung großer Sprachmodelle widmet, erlangte ein Beitrag mit dem Titel „Ich bin unglaublich enttäuscht von Llama 4“ schnell große Aufmerksamkeit und Resonanz.
Es gibt sogar treue Llama-Fans, die die Verteidigung gebrochen und unverblümt gesagt haben, dass es an der Zeit sei, „LocalLLaMA“ in „LocalGemma“ umzubenennen. Sich über die Veröffentlichung von Llama 4 lustig zu machen, gleicht eher einem verspäteten Aprilscherz.

Der eigentliche Test ergab, dass das Produkt nicht korrekt war, und es stellte sich heraus, dass Llama 4 vor der Veröffentlichung verrückt danach war, „Fragen auszufüllen“.
In diesem ursprünglichen Beitrag auf Reddit rät Netizen Karminski dringend davon ab, Llama 4 für die Kodierung zu verwenden.
Er sagte, dass Llama-4-Maverick – ein Modell mit einem Gesamtparameter von 402B – in Bezug auf die Kodierungsfunktionen nur knapp mit Qwen-QwQ-32B mithalten könne. Die Leistung von Llama-4-Scout (Modell mit Gesamtparametern 109B) ähnelt in etwa der von Grok-2 oder Ernie 4.5.
Tatsächlich erzielte Llama 4 Maverick laut den neuesten Benchmark-Ergebnissen für die Polyglot-Kodierung von Aider nur 16 %.
Dieser Benchmark soll die Leistung großer Sprachmodelle (LLM) bei mehrsprachigen Programmieraufgaben bewerten und deckt sechs gängige Programmiersprachen C++, Go, Java, JavaScript, Python und Rust ab.
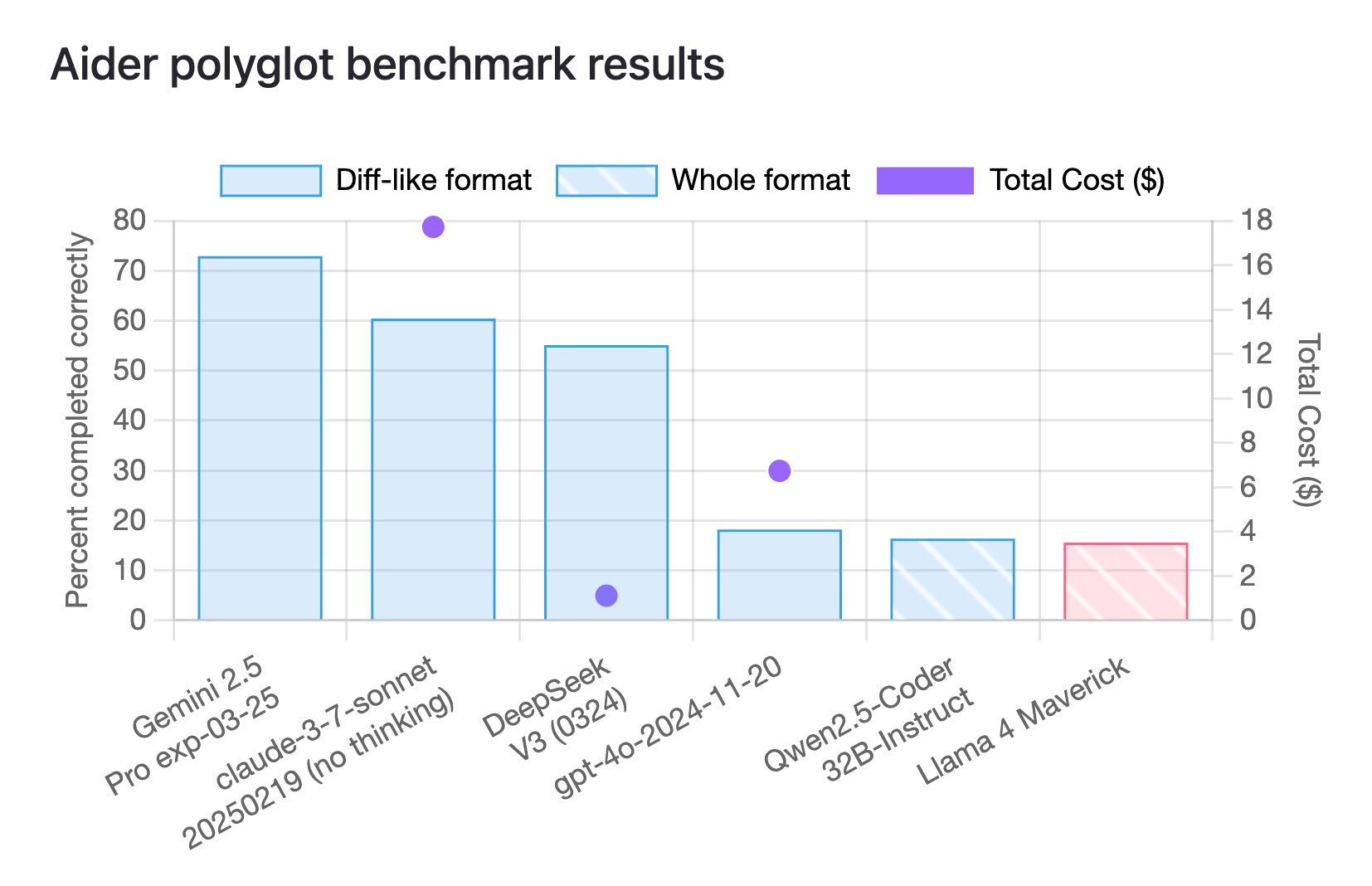
Und auch dieser Wert liegt bei vielen Modellen auf dem untersten Niveau.
Auch Blogger @deedydas äußerte seine Enttäuschung über Llama 4 und nannte es „ein schreckliches Programmiermodell“.
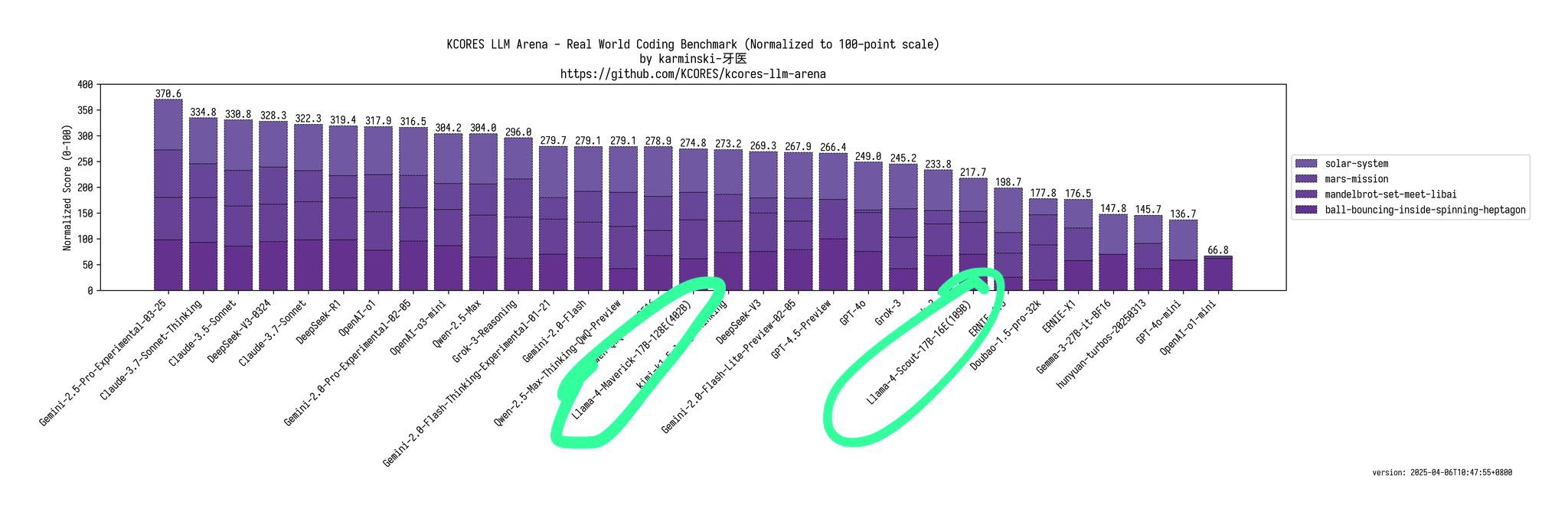
Er wies darauf hin, dass Scout (109B) und Maverick (402B) im Kscores-Benchmarktest für Programmieraufgaben deutlich schlechter abschneiden als 4o, Gemini Flash, Grok 3, DeepSeek V3 und Sonnet 3,5/7.
Ein anderer Internetnutzer, Flavio Adamo, bat Llama 4 Maverick und GPT-4o, eine Animation eines kleinen Balls zu erstellen, der in einem rotierenden Polygon springt, und der Ball muss während des Sprungvorgangs dem Einfluss von Schwerkraft und Reibung folgen.
Die Ergebnisse zeigen, dass die von Llama 4 Maverick erzeugte Polygonform keine Öffnungen aufweist und die Bewegung des Balls auch gegen die Gesetze der Physik verstößt. Im Vergleich ist die Leistung der neuen Version von GPT-4o deutlich besser und die Leistung von Gemini 2.5 Pro ist der König.

Rückblickend behauptete Zuckerberg im Januar dieses Jahres auch, dass KI das Programmierniveau eines fortgeschrittenen Softwareentwicklers erreichen würde. Die derzeit schlechte Leistung von Llama 4 ist in der Tat ein Schlag ins Gesicht, ein bisschen schnell.
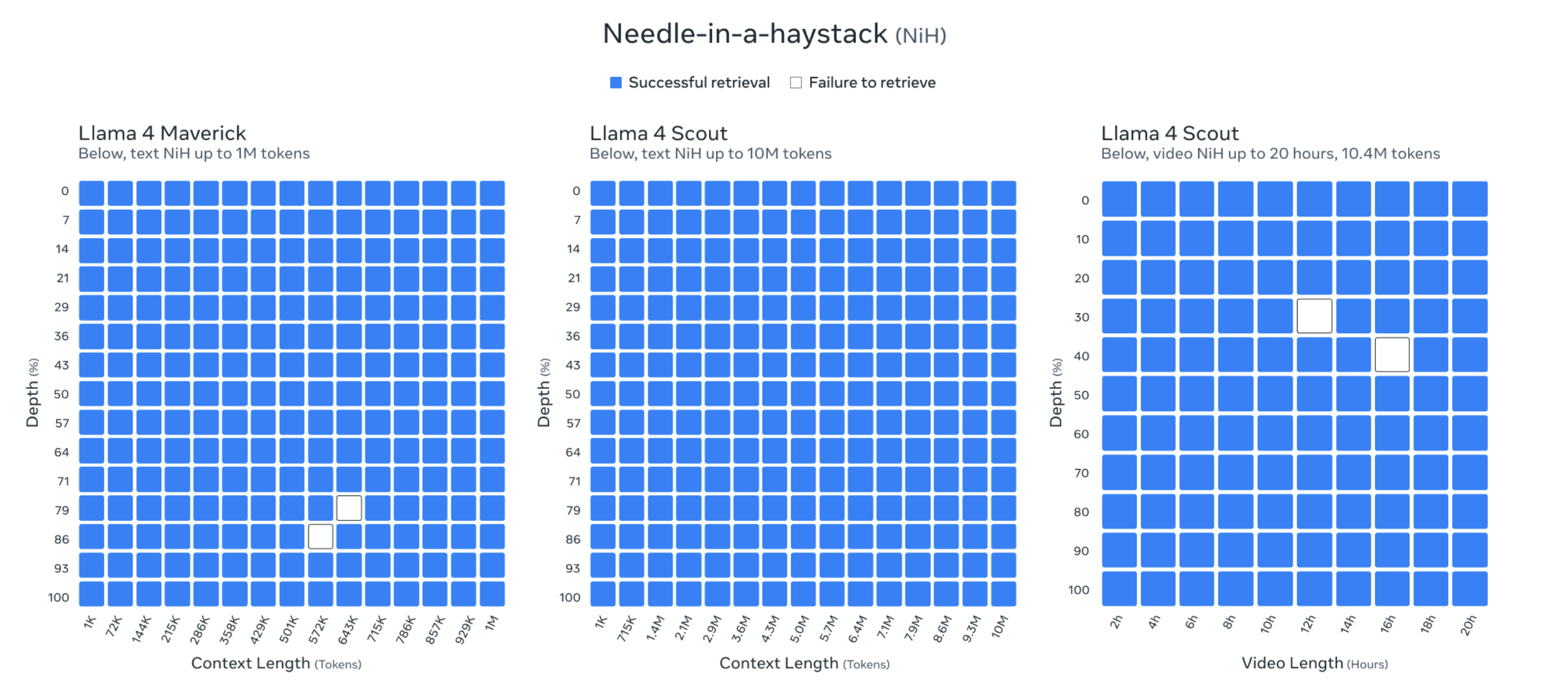
Darüber hinaus erreicht die Kontextlänge von Llama 4 Scout 10 Millionen Token. Diese extrem lange Kontextlänge ermöglicht es Llama 4 Scout, extrem lange Textinhalte, wie beispielsweise ganze Bücher, große Codebibliotheken oder Multimedia-Archive, zu verarbeiten und zu analysieren.
Meta-Beamte zeigten sogar die Testergebnisse von „Eine Nadel im Heuhaufen finden“, um ihre Fähigkeiten zu beweisen.
Den neuesten Ergebnissen von Fiction.LiveBench zufolge ist die Wirkung des Llama 4-Modells jedoch ebenfalls mittelmäßig und nutzlos, und die Gesamtwirkung ist nicht so gut wie bei Gemini 2.0 Flash, während Gemini 2.5 Pro immer noch der wohlverdiente König von Langtexten ist.
+1 für Oita bei Google.
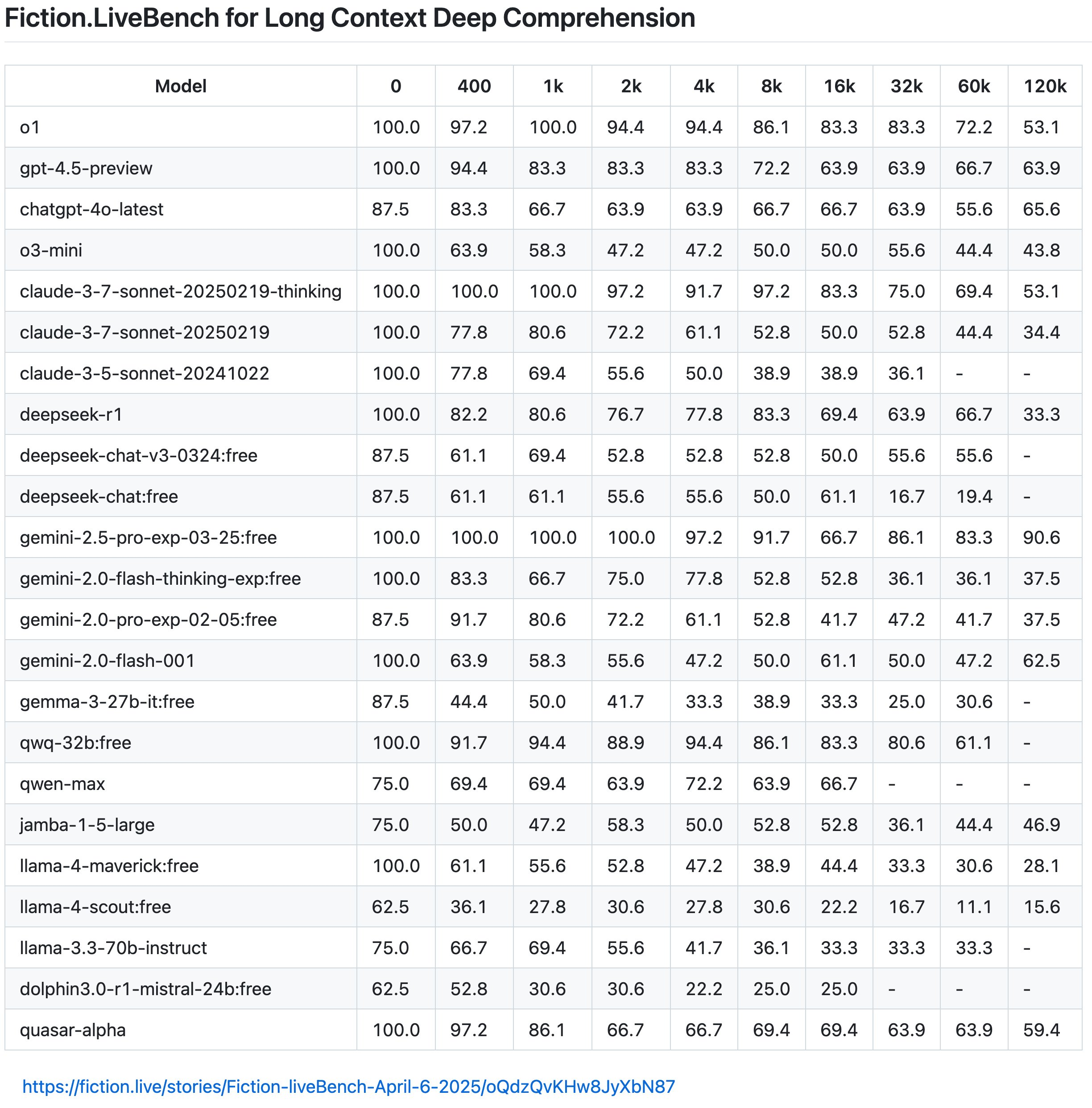
Netizen Karminski wies weiter darauf hin, dass Llama 4 unter 60 % gesunken sei, wenn die Kontexterinnerungsrate 1.000 betrage (ungefähr verstanden als die Rate der korrekten Beantwortung von Fragen), und dass selbst Llama-4-Scout nur 22 % habe, wenn sie 16.000 übersteige.
Er gab auch ein anschauliches Beispiel: „Die Textlänge von „Harry Potter und der Stein der Weisen“ beträgt zufällig etwa 16 KB.
Das heißt, wenn Sie das gesamte Buch in das Modell eingeben und dann fragen: „Hat Harry als Kind im Schlafzimmer oder im Abstellraum unter der Treppe gewohnt?“, erhält Llama-4-Scout nur in 22 % der Fälle die richtige Antwort (ungefähres Verständnis, der tatsächliche Erinnerungsmechanismus ist komplizierter). Und dieses Ergebnis liegt naturgemäß weit unter dem Durchschnittsniveau des Kopfmodells.
Nicht nur das Modell selbst ist etwas gestreckt, auch der Ruf von Llama 4 als „Open-Source-Führer“ schwindet allmählich.
Meta eröffnet die Gewichte von Llama 4, aber selbst mit Quantisierung kann es nicht auf GPUs der Verbraucherklasse ausgeführt werden. Es soll angeblich auf einer einzigen Karte laufen, bezieht sich aber tatsächlich auf H100. Der hohe Schwellenwert ist für Entwickler ziemlich unfreundlich.
Darüber hinaus weist die neue Lizenz von Llama 4 mehrere Einschränkungen auf. Die am meisten kritisierte davon ist, dass Unternehmen mit mehr als 700 Millionen aktiven Benutzern pro Monat eine spezielle Lizenz bei Meta beantragen müssen, über deren Genehmigung oder Ablehnung Meta nach eigenem Ermessen entscheiden kann.

Warten Sie, das ist nicht das, was die gestern von Meta angekündigten Papierparameter besagten. Warum sich die Windrichtung einen Tag später völlig geändert hat.
In der Arena-Rangliste der großen Modelle belegte Llama 4 Maverick den zweiten Platz in der Gesamtliste und war damit das vierte Modell, das 1.400 Punkte überschritt. Es führte die Liste der Open-Source-Modelle an und übertraf DeepSeek V3.
Angesichts der Tatsache, dass die gemessene Leistung „nicht stimmte“, witterten aufmerksame Internetnutzer schnell etwas Verdächtiges. Maverick, der in der LM Arena hohe Punktzahlen erzielte, nutzte tatsächlich eine „experimentelle Chat-Version“.

Das ist noch nicht vorbei. Der heutige Eilmeldungsbeitrag über die Gemeinde One Acre Three-quarter Land scheint einige Insider-Geschichten enthüllt zu haben. Es wurde berichtet, dass Llama 4 nach wiederholtem Training das Open-Source-SOTA nicht erhalten konnte und sogar weit davon entfernt war.
Die von Meta Company intern festgelegte Frist für die Veröffentlichung ist Ende April.
Daher schlug die Unternehmensführung vor, die Testsätze verschiedener Benchmarks im Nachschulungsprozess zu mischen, in der Hoffnung, eine gegenseitige Befruchtung verschiedener Indikatoren zu erreichen. Überlegen Sie sich ein Ergebnis, das „gut aussieht“.
Das hier erwähnte Mischen der Testsätze verschiedener Benchmarks im Post-Training-Prozess bedeutet, dass das Modell in der Post-Training-Phase des Modells durch Mischen von Datensätzen aus verschiedenen Benchmarks in einer Vielzahl von Aufgaben und Szenarien lernen kann, wodurch seine Generalisierungsfähigkeit verbessert wird.
Um eine einfache Analogie zu verwenden: Das ist so, als würde man bei einer Prüfung schummeln. Die Testfragen sollten zufällig aus einer vertraulichen Fragendatenbank (Benchmark-Testset) ausgewählt werden, und niemand wusste es vor dem Test. Aber wenn sich jemand die Fragen im Voraus ansieht und sie wiederholt übt (gleichbedeutend mit dem Mischen des Testsatzes in das Training), wird er in der Prüfung auf jeden Fall gut abschneiden.
Das Poster erklärte weiter, dass nach der Veröffentlichung von Llama 4 die tatsächlichen Testergebnisse von X- und Reddit-Internetnutzern kritisiert wurden. Als jemand, der derzeit in der Wissenschaft tätig ist, behauptete er, dass er Metas Ansatz wirklich nicht akzeptieren könne. Er hatte seinen Rücktrittsantrag eingereicht und ausdrücklich darum gebeten, dass sein Name aus dem technischen Bericht von Llama 4 entfernt wird.
Er sagte auch, dass Metas Vizepräsident für KI ebenfalls aus diesem Grund zurückgetreten sei. Vor einigen Tagen wurde berichtet, dass Meta AI-Forschungsleiterin Joelle Pineau angekündigt habe, dass sie ihren Posten am 30. Mai verlassen werde.

Möglicherweise sind jedoch weitere Beweise für den Wahrheitsgehalt dieses angeblichen Vorwurfs des „Listenbetrugs“ erforderlich. Ein Meta-Mitarbeiter namens LichengYu antwortete ebenfalls mit seinem richtigen Namen im Kommentarbereich:
„In den letzten zwei Tagen habe ich demütig auf das Feedback aller Beteiligten gehört (z. B. Codierung, kreatives Schreiben und andere Mängel, die verbessert werden müssen) und hoffe, dass ich mich in der nächsten Version verbessern kann. Allerdings haben wir den Testsatz nie übermäßig angepasst, um Punkte aufzufrischen. Der richtige Name ist Licheng Yu. Ich habe das Nachtraining von zwei Oss-Modellen übernommen. Bitte sagen Sie mir, welche Eingabeaufforderung aus dem Testsatz ausgewählt und in den Trainingssatz eingefügt wurde. Ich werde Ihnen ein + entschuldigen!“

Aus öffentlichen Informationen geht hervor, dass Licheng Yu seinen Abschluss an der Shanghai Jiao Tong University machte, 2014 einen Doppel-Master-Abschluss vom Georgia Institute of Technology und der Shanghai Jiao Tong University erhielt und im Mai 2019 einen Doktortitel in Informatik von der University of North Carolina in Chapel Hill erhielt.
Seine Forschungsgebiete konzentrieren sich auf Computer Vision und Verarbeitung natürlicher Sprache, und viele Beiträge wurden von führenden Konferenzen wie CVPR, ICLR, ECCV und KDD angenommen.
Licheng Yu verfügt über Berufserfahrung in großen Unternehmen wie Microsoft und Adobe. Derzeit ist er wissenschaftlicher Leiter von Meta (2023.06 bis heute). Er war an der Veröffentlichung des multimodalen Modells Llama3.2 (11B+90B) beteiligt und leitete die Lernphase zur Text- und Bildverstärkung von 17Bx128 und 17Bx16 im Llama 4-Projekt.
Es ist schwer zu sagen, ob es wahr ist oder nicht, und vielleicht kann es die Kugeln noch eine Weile weiter fliegen lassen.
Der „Thron“ großer Open-Source-Modelle kann nicht mit roher Gewalt erobert werden
Letztes Jahr um diese Zeit wurde Meta als die Auserwählte der KI-Branche gefeiert.
Natürlich begann Zuckerberg, nachdem er sein schlichtes graues T-Shirt, seine Jeans und seinen Kapuzenpullover ausgezogen hatte, auch häufig Markenkleidung mit großen Logos zu tragen, sich große und grobe Goldketten um den Hals zu hängen und sogar selbstbewusst seine Fitnessergebnisse in der Öffentlichkeit zur Schau zu stellen.
Zuckerberg, der kein Interesse am Trinken hat, versucht, der Öffentlichkeit näher zu kommen, indem er eine „realere“ und „bodenständigere“ Seite zeigt. Dies macht Meta nicht nur benutzerfreundlicher, sondern macht es auch zum Open-Source-Standardträger gegenüber dem Closed-Source-Modell von OpenAI mit beispielloser Dynamik.

Gleichzeitig bietet Metas starke Stärke einen soliden Rückhalt für die Transformation. Berichten zufolge plant Meta, im Jahr 2025 bis zu 65 Milliarden US-Dollar in den Ausbau seiner KI-Infrastruktur zu investieren, was in der Branche eine große Summe darstellt. Bis Ende 2025 will Meta über mehr als 1,3 Millionen GPUs verfügen.
Zweitens verfügt Meta über reichlich Daten zu sozialen Plattformen, was ihm einzigartige Vorteile in der KI-Forschung und -Entwicklung verschafft.
Als Muttergesellschaft weltbekannter sozialer Plattformen wie Facebook, Instagram und WhatsApp verfügt Meta über Daten zu den täglichen Interaktionen von Milliarden von Nutzern. Laut Statistik wird die Zahl der weltweit täglich aktiven Nutzer (DAU) seiner Plattform im Jahr 2024 3 Milliarden überschreiten. Dieses riesige Datenvolumen liefert enorme Rohstoffe für das Training von KI-Modellen.
Darüber hinaus ist Meta in seinem Talentpool nicht weniger großzügig. Der Leiter der KI-Abteilung ist der renommierte Turing-Award-Gewinner der Branche, Yann LeCun. Unter seiner Führung hielt Meta an der Open-Source-Strategie fest und brachte die Modellreihe Llama auf den Markt.
Daher ist Meta auch sehr ehrgeizig – es will nicht nur seine Position im sozialen Bereich festigen, sondern hofft auch auf das Kurvenüberholen im KI-Bereich, mit dem Ziel, bis Ende 2025 starke Konkurrenten wie OpenAI zu übertreffen.

Aber ich sah, wie er ein Zhulou baute, ich sah, wie er Gäste bewirtete, und ich sah, wie sein Turm einstürzte.
Wenn die Nachricht von One Third Acre wahr ist, kann es im Entwicklungsprozess von Llama 4 zu „Betrug“ kommen, um Benchmark-Testergebnisse zu erzielen. Durch das Mischen des Testsatzes mit den Trainingsdaten handelt es sich eher um eine betriebliche Verformung unter „KI-Verkehrsangst“.
Anfang des Jahres gab es Neuigkeiten, dass DeepSeek das Meta AI-Team in Panik versetzte:
„Wenn das Gehalt jeder Führungskraft in der generativen KI-Organisation höher ist als die Kosten für die Schulung des gesamten DeepSeek-V3 und wir Dutzende solcher Führungskräfte haben, wie werden sie dann dem Top-Management gegenübertreten?“
Im Jahr 2023 etablierte Meta mit der Llama-Serie nahezu ein Monopol im Bereich der Open-Source-Großmodelle und wurde zum Synonym und Maßstab für Open-Source-KI.
Allerdings ein Tag für die KI und ein Jahr für den Menschen. Im Kommentarbereich, wo Llama 4 auf „Waterloo“ stieß, ist überall Lob von anderen Open-Source-Modellen zu sehen. Unter ihnen hat Google Gemma große Anerkennung für sein geringes Gewicht, seine hohe Effizienz und seine multimodalen Fähigkeiten erhalten, Alibabas Basismodelle der Qwen-Serie sind auf den Markt gekommen und DeepSeek hat die gesamte Branche mit seinem Status als kostengünstiges und leistungsstarkes Dark Horse schockiert.
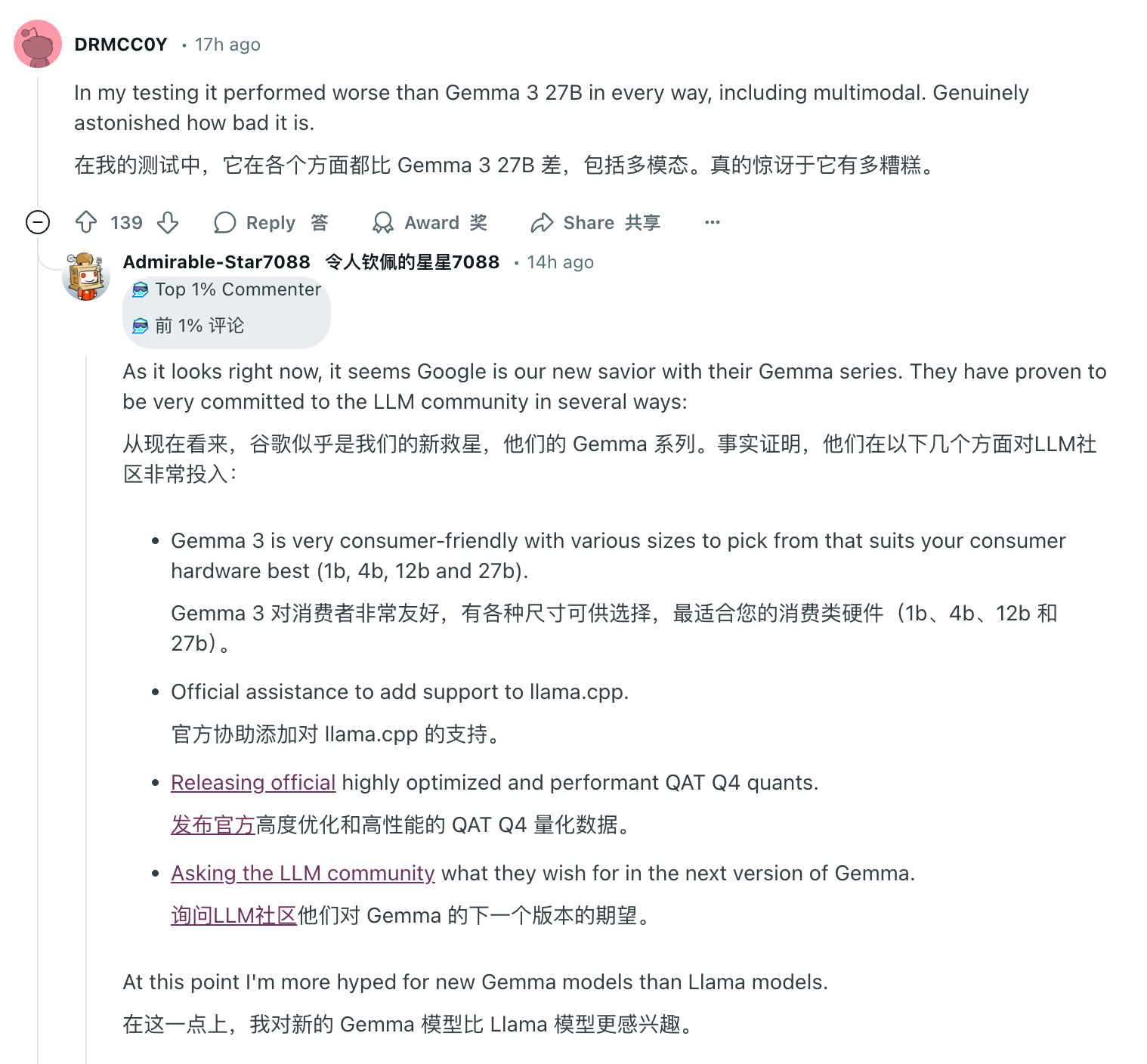
Es ist noch nicht bekannt, ob Meta seine Strategie anpassen und zur führenden Position der Open-Source-KI-Modelle zurückkehren kann, aber auf jeden Fall ist die Blüte der Open-Source-KI unwiderruflich angekommen.
Meta hält sich an den Grundsatz, welche KI einfach zu nutzen ist und welche man nutzen sollte, und kann den Nutzern nicht die ganze Schuld geben. Darüber hinaus bedeutet die selbst auferlegte Einschränkung von Llama 4 im Hinblick auf die Open-Source-Transparenz im Vergleich zu den Open-Source-Modellen der oben genannten Unternehmen auch, dass es einen Arm abgeschnitten hat.
Die aktuellen Schwierigkeiten von Meta könnten auch zeigen, dass Ressourcenvorteile nicht mehr der entscheidende Faktor sind, selbst wenn das Unternehmen über die gesamte GPU-Rechenleistung und die riesigen Datenmengen der Welt verfügt. Der „Thron“ großer Open-Source-Modelle kann nicht mit roher Gewalt erobert werden.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo