
Dialog mit Jiang Daxin, Gründer von Step Star: Multimodale Modelle haben den GPT-4-Moment noch nicht erreicht, und wir bestehen darauf, die „Obergrenze der Intelligenz“ zu verfolgen.
Ob die KI es in die zweite Halbzeit schafft, mag umstritten sein, aber es ist sicher, dass die großen Modelle es in die K.-o.-Runde schaffen werden.
Nach dem Erscheinen von DeepSeek R1 hat sich der Trend verstärkt. Allein in diesem Jahr haben OpenAI, Anthropic, Google, Meta und Grok mindestens 8 neue Modelle veröffentlicht. Einige der einheimischen KI-Tiger haben auch begonnen, das Vortraining aufzugeben und den Idealismus der AGI auf Eis zu legen.
Unter ihnen ist Step Star ein etwas besonderes Unternehmen. Bis zum Ende des letzten Jahres gab es kaum Nachrichten über die Finanzierung, aber es wurde zum „Volume King“ bei multimodalen Modellen. In den zwei Jahren seines Bestehens hat es 22 selbst entwickelte Basismodelle herausgebracht und sich damit zum zurückhaltendsten und geheimnisvollsten KI-Einhorn entwickelt.
Jiang Daxin, der Gründer und CEO von Step Star, ist ebenso zurückhaltend wie das Unternehmen und taucht selten im lebhaften öffentlichen Meinungsfeld der KI-Branche auf.
Gestern hielt Jiang Daxin ein ausführliches Kommunikationstreffen mit APPSO und anderen Medien ab. Er teilte uns seine Ansichten zu AGI-Pfaden, multimodalen Modellen und anderen Technologien sowie die Zukunftspläne von Step Star mit.

Multimodale Modelle sind in GPT-4 noch nicht erschienen und verfolgen die „Intelligenzobergrenze“.
Die aktuelle Entwicklung im Bereich der großen KI-Modelle nimmt kein Ende, und unter führenden Unternehmen werden ständig heftige Dramen um „nahe Veröffentlichungen“ inszeniert.
Allerdings glaubt Jiang Daxin immer noch, dass „ das Streben nach der Obergrenze der Intelligenz zum jetzigen Zeitpunkt immer noch im Mittelpunkt der KI-Branche steht. “ Mit anderen Worten: Obwohl es mittlerweile viele Modelle auf dem Markt gibt und sie alle recht leistungsfähig zu sein scheinen, sind sie noch weit davon entfernt, wirklich „intelligent“ zu sein.
Alle beeilen sich, neue Modelle herauszubringen, und es sieht lebhaft aus, aber wenn man nur am aktuellen Niveau herumbastelt, wird es nur eine „Involution“ des Stillstands sein.
Jiang Daxin ist der Meinung, dass es jetzt am wichtigsten ist, einen Weg zu finden, den „IQ“ der KI zu steigern, sonst wird sie immer noch weit von der AGI (künstliche Intelligenz) entfernt sein, an die jeder denkt.

Nach der Einführung von DeepSeek R1 und dem viel beachteten Einstieg großer Hersteller begannen viele Start-up-Unternehmen, die Entwicklung von Basismodellen aufzugeben. Allerdings sagte Jiang Daxin in einem Interview mit APPSO:
Die Technologie in der KI-Branche entwickelt sich sehr schnell und befindet sich immer noch in einem sehr steilen Bereich. Wir wollen in diesem Prozess weder das Mainstream-Wachstum noch den Vorwärtstrend aufgeben und bleiben daher weiterhin bei der Forschung und Entwicklung grundlegender Modelle.
Gleichzeitig sagte Jiang Daxin, dass Anwendungen und Modelle einander ergänzten. Das Modell kann die Obergrenze der Anwendung bestimmen und die Anwendung stellt dem Modell spezifische Anwendungsszenarien und Daten zur Verfügung.
Wie können wir KI intelligenter machen? Ein von Jiang Daxin genannter Schlüsselpfad lautet: „ Multimodalität ist der einzige Weg, AGI zu erreichen. “
Viele Leute sagen, dass dieses Jahr das erste Jahr von Agent ist. Jiang Daxin glaubt, dass der Ausbruch des Agenten zwei notwendige Bedingungen erfordert: eine multimodale Fähigkeit und die andere die Fähigkeit, langsam zu denken .
Multimodalität bedeutet, salopp ausgedrückt, dass KI nicht nur Texte verstehen, sondern auch Bilder sehen, Töne hören und Videos verstehen kann.
Wenn Sie darüber nachdenken, brauchen Menschen nur ihre Augen, Ohren, ihren Mund und ihre Nase, um die Welt vollständig zu verstehen. Auch die KI muss so sein und zum „Allrounder“ werden, der zuhören, sehen und sprechen kann.
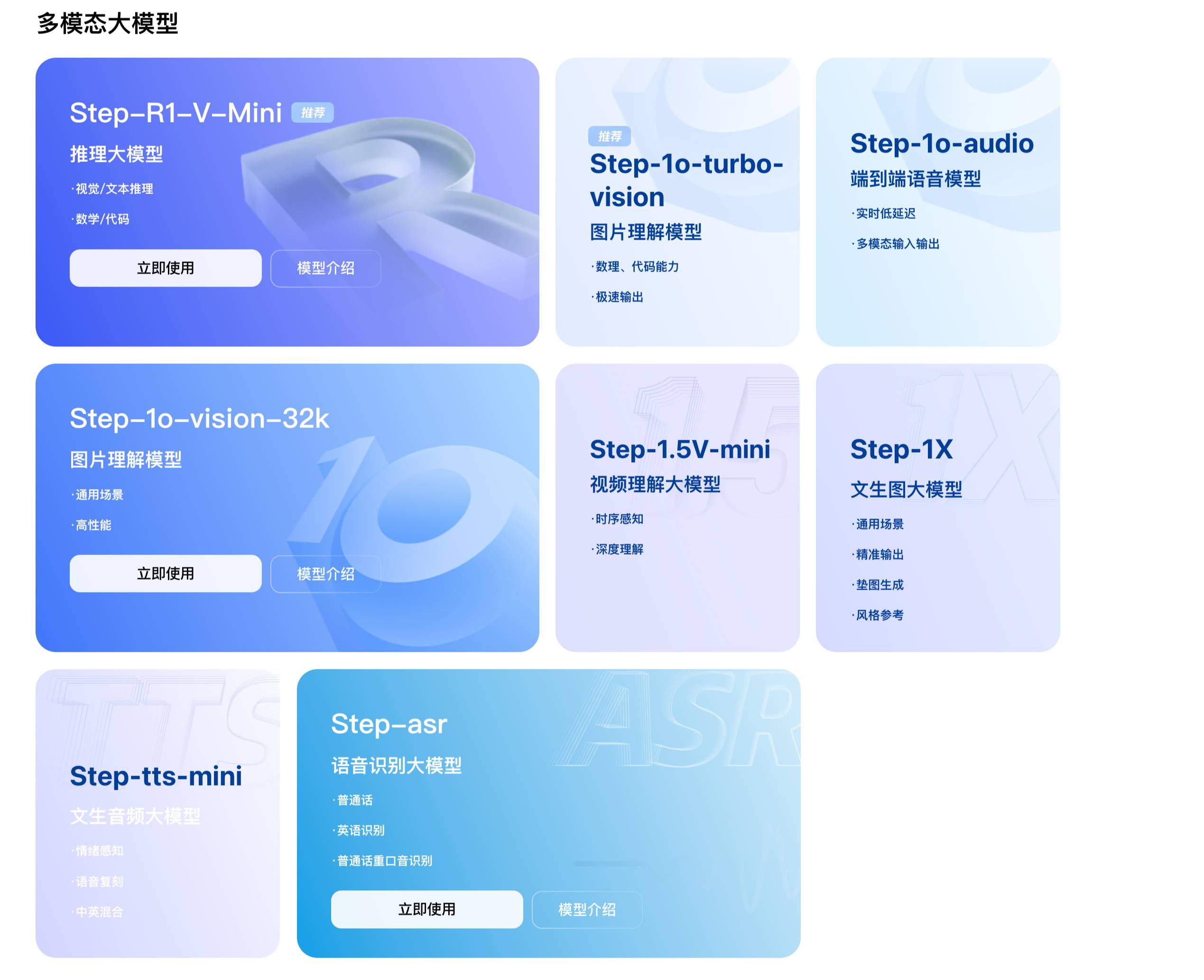
Man kann Step Star als den „König der Volumina“ unter den multimodalen Modellen bezeichnen. Fast jeden Monat wird ein großes Basismodell veröffentlicht, darunter 16 multimodale Modelle. Es umfasst das Verstehen und Generieren von Bildern, Videos, Sprache und Musik. In den Worten von Jiang Daxin folgt es dem „nativen multimodalen Konzept“.
Allerdings ist Jiang Daxin auch ganz ehrlich. Er erklärte offenherzig, dass „ es im Bereich der multimodalen Modelle noch keinen GPT-4-Moment gegeben hat. “
Obwohl Multimodalität mittlerweile sehr beliebt ist und von allen befürwortet wird, gab es im Textbereich noch kein Benchmark-Produkt wie GPT-4. Wenn es herauskommt, wird es „Wow“ sagen und alle denken lassen: „Das ist es.“ Es gibt technisch noch viele harte Knochen, an denen man nagen muss.
KI-verbesserte Monster-Kampf-Trilogie
In Bezug darauf, wie sich das Modell Schritt für Schritt der Obergrenze der Intelligenz nähert, zeichnete Jiang Daxin einen klaren Entwicklungsfahrplan für die „Trilogie“. Man kann auch sagen, dass dies die von Step Star verstandene AGI-Evolutionsrichtung ist.

Simulierte Welt (Nachahmungslernphase) : Die KI in dieser Phase ist wie ein Kind, das gerade sprechen gelernt hat. Füttere es mit einer großen Datenmenge und es wird lernen. Die Hauptaufgabe besteht darin, „nächstes Token vorherzusagen“ (nächstes Wort vorherzusagen) oder „nächsten Frame vorherzusagen“ (nächsten Frame vorherzusagen). Der Zweck besteht darin, dass die KI zunächst lernt, wie die Welt aussieht und welche Eigenschaften verschiedene Dinge haben.
Die Welt erkunden (Stufe des verstärkenden Lernens) : Nur die Fähigkeit zur Nachahmung reicht nicht aus, man muss auch die Fähigkeit entwickeln, komplexe Probleme zu lösen. Beispielsweise erfordert die Lösung einer Mathematikolympiade-Aufgabe oder das Schreiben eines komplexen Codestücks „langsames Denken“. Zu diesem Zeitpunkt ist verstärktes Lernen erforderlich, damit die KI durch kontinuierliches Ausprobieren Schritt für Schritt lernen kann, wie das Problem gelöst werden kann.
Induktive Welt (maschinelles autonomes Lernstadium) : Dies ist der höchste Zustand. KI kann nicht nur bekannte Probleme lösen, sondern auch selbst neue Gesetze entdecken und Innovationen schaffen, an die der Mensch nicht gedacht hat. Im Bereich der wissenschaftlichen Forschung unterstützen wir beispielsweise Wissenschaftler bei der Entdeckung neuer Materialien, neuer Medikamente usw.
Diese drei Stufen stimmen mit den Kernkonzepten der fünf von OpenAI vorgeschlagenen AGI-Stufen überein. Die aktuelle Entwicklung der gesamten KI-Branche verläuft grundsätzlich nach diesem Drehbuch.
Warum ist es so wichtig, die Integration der Generationen zu verstehen?
In Bezug auf Multimodalität, insbesondere Bilder und Videos, betonte Jiang Daxin in der Kommunikationssitzung mehrfach ein Wort: die Integration von Verständnis und Erzeugung.
Das Verständnis der generativen Integration ist ein Kernthema im Bereich Computer Vision und von entscheidender Bedeutung für die Realisierung von AGI.
Vereinfacht ausgedrückt bedeutet dies, dass das Modell nicht nur verstehen kann, was ein Bild oder Video bedeutet, sondern auf der Grundlage dieses Verständnisses auch neue und relevante Bilder und Videos erstellen kann. Heutzutage heißt es oft: „Verwenden Sie Modell A, um Bilder zu sehen, und verwenden Sie Modell B, um Bilder zu zeichnen“, was so ist, als ob zwei Abteilungen nicht zusammenarbeiten können.
Er nannte ein Beispiel, etwa einen Lehrer, der an die Tafel schreibt. Jetzt kann Sora die Schreibbewegungen des Lehrers nachahmen, aber was der Lehrer denkt und was er als nächstes schreiben wird, hängt vom „Verstehen“ ab. Wenn Verstehen und Generieren zwei Systeme sind, wird es für das Modell schwierig sein, Sie wirklich zu „verstehen“, und die generierten Dinge sind möglicherweise auch irrelevant.
Sprachmodelle wie ChatGPT haben in dieser Hinsicht gute Arbeit geleistet, aber im visuellen Bereich sind die Daten zu komplex, sodass diese Angelegenheit noch nicht vollständig gelöst ist. Step Star hat hier weiter investiert und möchte diesen technischen Engpass überwinden.
Letztendlich müssen leistungsstarke Modellfunktionen eingesetzt werden, um den Wert zu verkörpern. Step Star verfolgt die Strategie „Supermodell und Superanwendung Zweiradantrieb“.

Auf Anwendungsebene betrachtet Step Star den „intelligenten Terminal-Agenten“ als seine wichtigste Entwicklungsrichtung. Jiang Daxin glaubt, dass intelligente Terminals, seien es Mobiltelefone in unserer Tasche, Autos, die wir täglich fahren, oder Roboter, die in der Zukunft populär sein könnten, nicht nur kalte Hardware, sondern auch „eine Erweiterung der Wahrnehmung und Erfahrung der Benutzer“ sind.
Das heißt, wenn KI tief in diese Terminals integriert werden kann, kann sie „Benutzerbedürfnisse und Aufgabenkontext besser verstehen“.
Beispielsweise hat OPPOs Flaggschiff Find X8 Ultra offiziell seine erste „One-Click-Flash-Speicher“-Funktion eingeführt. KI kann den Inhalt auf dem Telefonbildschirm intelligent identifizieren, Zusammenfassungen für Benutzer erstellen und fragmentierte Informationen in verschiedene Speichersammlungen klassifizieren.

Dahinter steckt eigentlich das multimodale Step-Star-Modell, das den auf dem Bildschirm angezeigten Inhalt verstehen kann, egal ob es sich um Bilder oder Text handelt, und Benutzer können Fragen dazu stellen. KI kann nicht nur antworten, sondern auch Bildverarbeitung durchführen und Benutzern sogar dabei helfen, einige In-App-Vorgänge auszuführen, wie z. B. das direkte Springen zur Flugbuchungsseite und das Ausfüllen der Informationen.
Diese Art der Zusammenarbeit integriert die Fähigkeiten großer Modelle und Systeme tiefer und bettet sie in die häufigsten Nutzungsszenarien von Mobiltelefonen für Benutzer ein. Der Wert der Wahl von Mobiltelefonen als Einstiegspunkt liegt in den natürlichen multimodalen Interaktionseigenschaften von Mobiltelefonen und der riesigen Benutzerbasis, die umfangreiche reale Daten und sofortiges Feedback für die Modelliteration liefert.
Generell ist die Idee von Step Star ganz klar: Technisch auf AGI abzielen und sich auf Kernthemen wie Multimodalität und Integration von Verständnis und Generierung konzentrieren. Im Hinblick auf die Anwendung müssen wir den Durchbruch intelligenter Terminals identifizieren und mit Hardwareherstellern zusammenarbeiten, um das Szenario gründlich zu verstehen.
Dieser Weg ist nicht einfach zu gehen, aber Jiang Daxin und sein Team scheinen ziemlich entschlossen zu sein. Denn um KI zur Lösung realer Probleme einzusetzen, müssen Sie zunächst die Anerkennung der Benutzer auf dem Markt gewinnen, bevor Sie die Möglichkeit haben, die Grenzen von AGI zu erkunden. Lassen Sie uns sehen, was sich der multimodale König der Step Stars für Neues einfallen lässt.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner: aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo