
AGI kommt bald! Das multimodale Modell der Abteilung des Nationalen Volkskongresses realisiert erstmals eine unabhängige Aktualisierung und die Foto-Video-Generierung übertrifft Sora

AGI (künstliche allgemeine Intelligenz) ist der heilige Gral der gesamten KI-Branche.
Der frühere OpenAI-Chefwissenschaftler Ilya Sutskeve äußerte letztes Jahr eine Ansicht: „Solange wir den nächsten Token sehr gut vorhersagen können, können wir Menschen dabei helfen, AGI zu erreichen.“
Turing-Award-Gewinner Geoffrey Hinton, bekannt als Vater des Deep Learning, und OpenAI-CEO Sam Altman glauben beide, dass AGI innerhalb von zehn Jahren oder sogar früher eintreffen wird.
AGI ist nicht das Ende, sondern ein neuer Ausgangspunkt in der Geschichte der menschlichen Entwicklung. Auf dem Weg zu AGI gibt es viele Dinge zu beachten, und auch Chinas KI-Industrie ist eine Kraft, die nicht ignoriert werden darf.
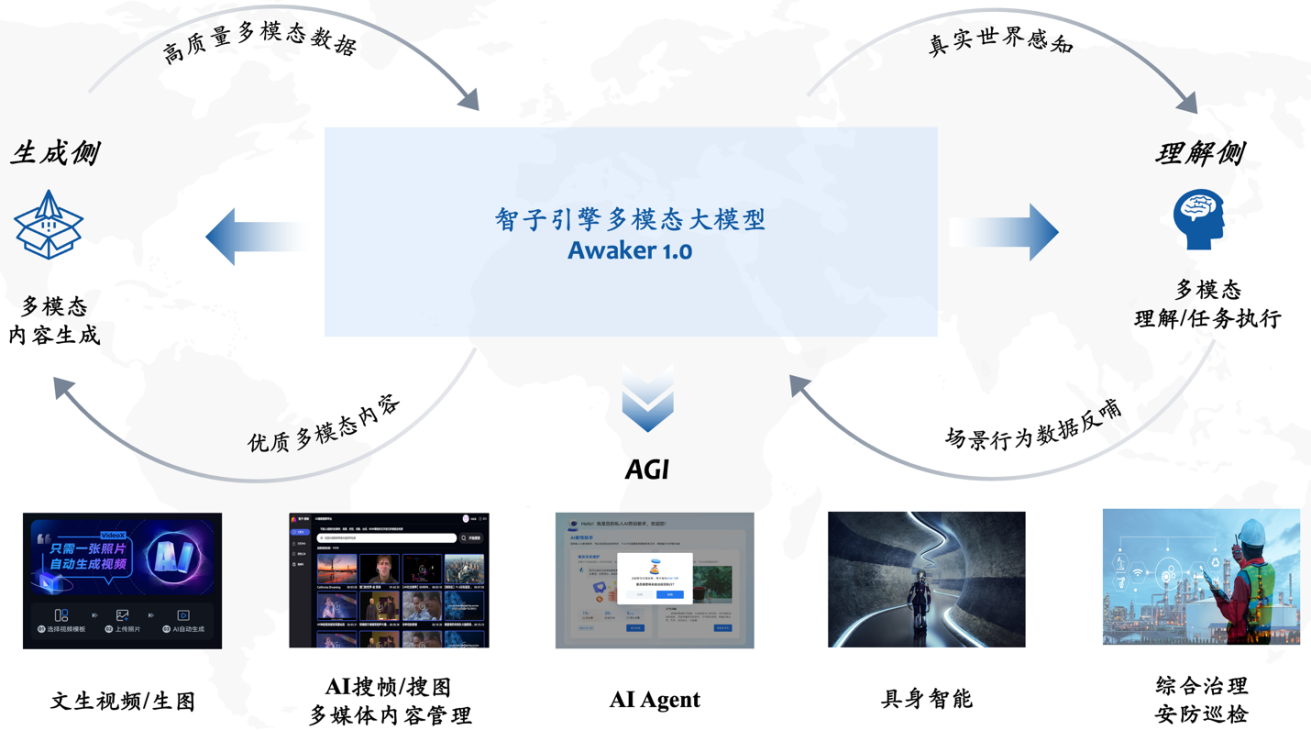
Auf dem Zhongguancun Forum General Artificial Intelligence Parallel Forum am 27. April veröffentlichte Sophon Engine, ein mit der Renmin-Universität Chinas verbundenes Startup-Unternehmen, feierlich ein neues multimodales Großmodell Awaker 1.0 und machte damit einen entscheidenden Schritt in Richtung AGI.
Im Vergleich zum ChatImg-Sequenzmodell der vorherigen Generation der Sophon-Engine übernimmt Awaker 1.0 eine neue MOE-Architektur und verfügt über unabhängige Update-Funktionen. Es ist das erste multimodale große Modell in der Branche, das eine „echte“ unabhängige Aktualisierung erreicht . In Bezug auf die visuelle Generierung verwendet Awaker 1.0 eine vollständig selbst entwickelte Videogenerierungsbasis VDT, die bei der Generierung von Fotovideos bessere Ergebnisse als Sora erzielt und die Schwierigkeit der „letzten Meile“ bei der Landung großer Modelle überwindet.

Das MOE-Basismodell von Awaker
Auf der Verständnisseite löst das Basismodell von Awaker 1.0 hauptsächlich das Problem schwerwiegender Konflikte im multimodalen und multitaskigen Vortraining. Das Basismodell von Awaker 1.0 profitiert von der sorgfältig entwickelten Multitask-MOE-Architektur und kann nicht nur die Grundfunktionen des multimodalen Großmodells ChatImg der vorherigen Generation der Sophon Engine übernehmen, sondern auch die einzigartigen Fähigkeiten erlernen, die für jede multimodale Aufgabe erforderlich sind . Im Vergleich zum multimodalen Großmodell ChatImg der vorherigen Generation wurden die Basismodellfunktionen von Awaker 1.0 in mehreren Aufgaben erheblich verbessert.
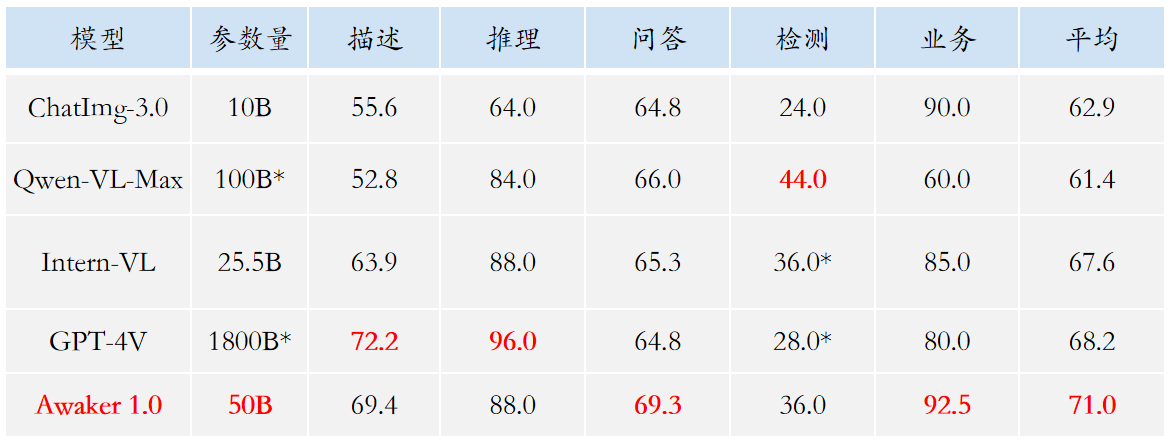
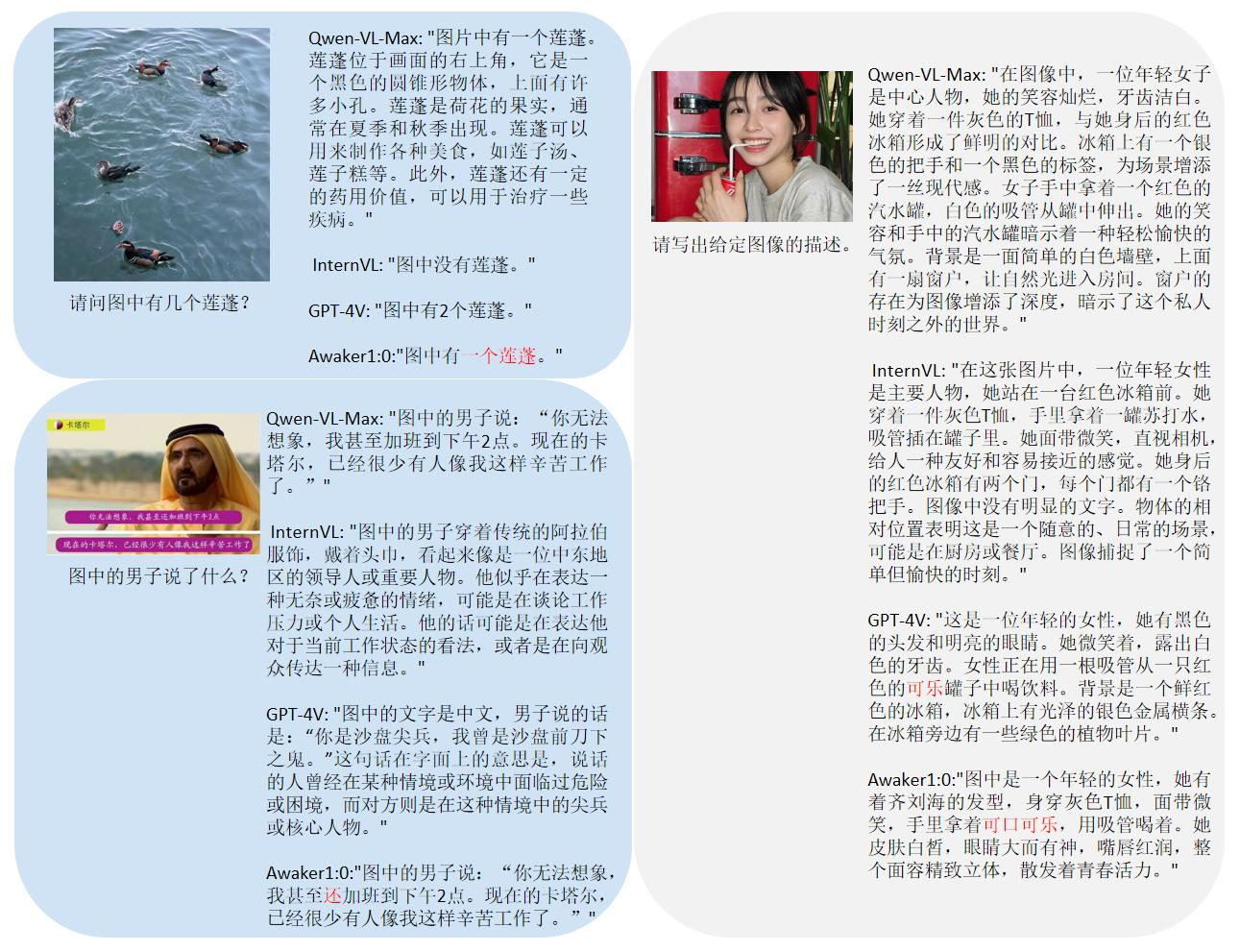
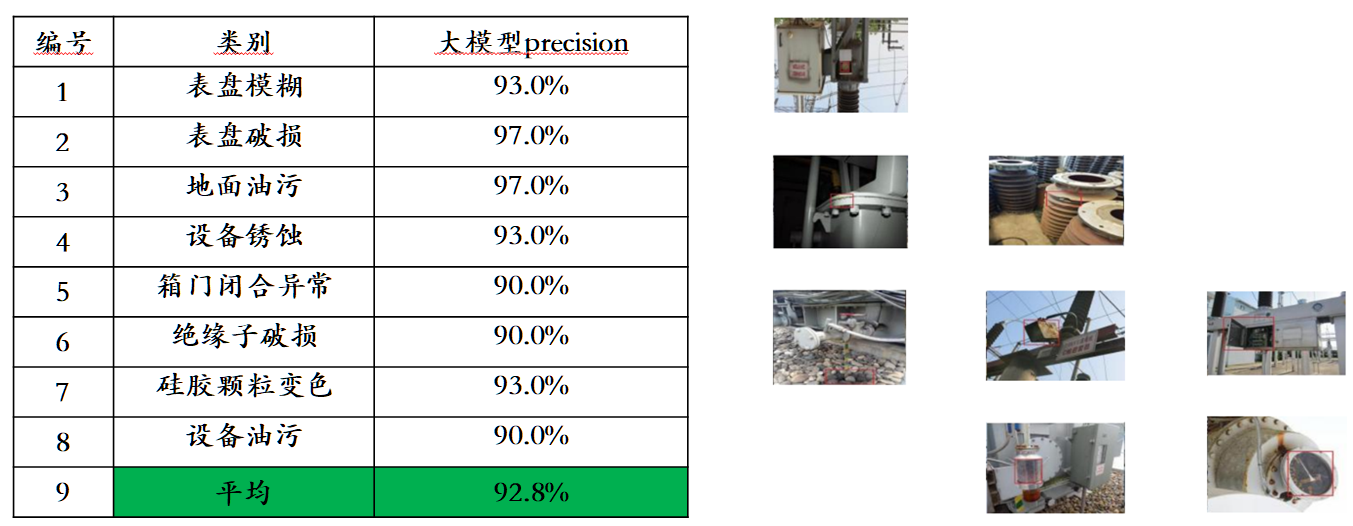
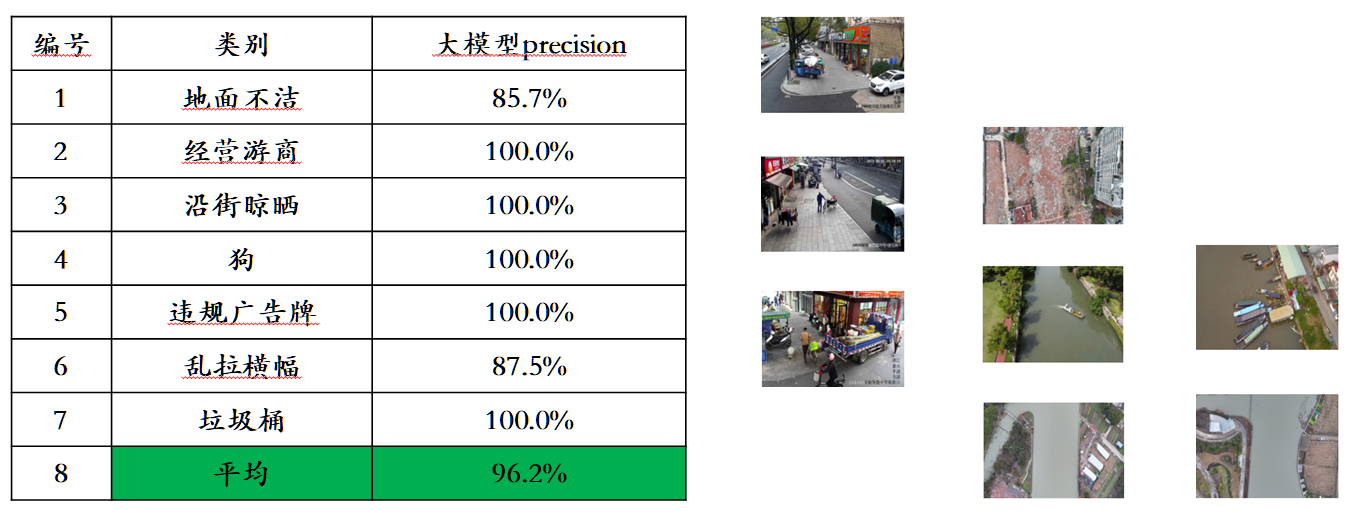
Angesichts des Problems der Leckage von Bewertungsdaten in gängigen multimodalen Bewertungslisten hat Sophon Engine einen strengen Standard für den Aufbau eines eigenen Bewertungssatzes veröffentlicht, bei dem die meisten Testbilder aus persönlichen Mobiltelefonalben stammen. In diesem multimodalen Bewertungssatz werden faire manuelle Bewertungen für Awaker 1.0 und die drei fortschrittlichsten multimodalen Großmodelle im In- und Ausland durchgeführt. Die detaillierten Bewertungsergebnisse sind in der folgenden Tabelle aufgeführt. Beachten Sie, dass GPT-4V und Intern-VL Erkennungsaufgaben nicht direkt unterstützen. Ihre Erkennungsergebnisse werden dadurch erhalten, dass das Modell die Objektorientierung mithilfe von Sprache beschreiben muss.
Awaker+ Verkörperte Intelligenz: Auf dem Weg zu AGI
Die Kombination aus multimodalen Großmodellen und verkörperter Intelligenz ist sehr natürlich, da die visuellen Verständnisfähigkeiten multimodaler Großmodelle auf natürliche Weise mit verkörperten intelligenten Kameras kombiniert werden können. Im Bereich der künstlichen Intelligenz gilt „multimodales großes Modell + verkörperte Intelligenz“ sogar als gangbarer Weg zur Erreichung allgemeiner künstlicher Intelligenz (AGI).
Einerseits erwarten die Menschen, dass die verkörperte Intelligenz anpassungsfähig ist, das heißt, der Agent kann sich durch kontinuierliches Lernen an sich ändernde Anwendungsumgebungen anpassen. Er kann nicht nur bekannte multimodale Aufgaben immer besser erledigen, sondern sich auch schnell an unbekannte Multis anpassen -modale Aufgaben. Andererseits erwarten die Menschen auch, dass verkörperte Intelligenz wirklich kreativ ist, und hoffen, dass sie durch autonome Erkundung der Umwelt neue Strategien und Lösungen entdecken und die Grenzen der Fähigkeiten künstlicher Intelligenz erkunden kann. Durch die Verwendung großer multimodaler Modelle als „Gehirne“ der verkörperten Intelligenz ist es möglich, die Anpassungsfähigkeit und Kreativität der verkörperten Intelligenz erheblich zu verbessern und so schließlich die Schwelle von AGI zu erreichen (oder sogar AGI zu erreichen).
Bei bestehenden großen multimodalen Modellen gibt es jedoch zwei offensichtliche Probleme: Erstens ist der iterative Aktualisierungszyklus des Modells lang und erfordert große personelle und finanzielle Investitionen. Zweitens werden die Trainingsdaten des Modells alle aus vorhandenen Daten abgeleitet , und das Modell ist nicht in der Lage, kontinuierlich große Mengen an neuem Wissen zu erwerben. Obwohl durch RAG und langen Kontext auch kontinuierlich neues Wissen eingebracht werden kann, lernt das multimodale große Modell selbst dieses neue Wissen nicht, und diese beiden Sanierungsmethoden bringen auch zusätzliche Probleme mit sich. Kurz gesagt, die aktuellen großen multimodalen Modelle sind in tatsächlichen Anwendungsszenarien nicht sehr anpassungsfähig, geschweige denn kreativ, was bei der Implementierung in der Branche zu verschiedenen Schwierigkeiten führt.
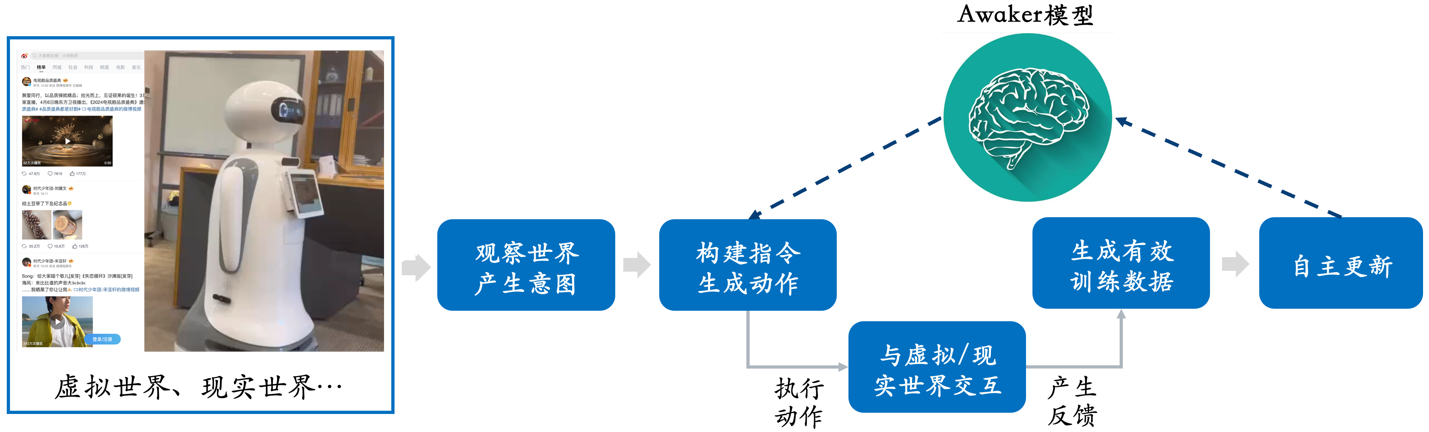
Awaker 1.0, veröffentlicht von Sophon Engine, ist dieses Mal das weltweit erste multimodale Großmodell mit einem autonomen Aktualisierungsmechanismus, der als „Gehirn“ der verkörperten Intelligenz verwendet werden kann. Der autonome Aktualisierungsmechanismus von Awaker 1.0 umfasst drei Schlüsseltechnologien: aktive Datengenerierung, Modellreflexion und -bewertung sowie kontinuierliche Modellaktualisierung .
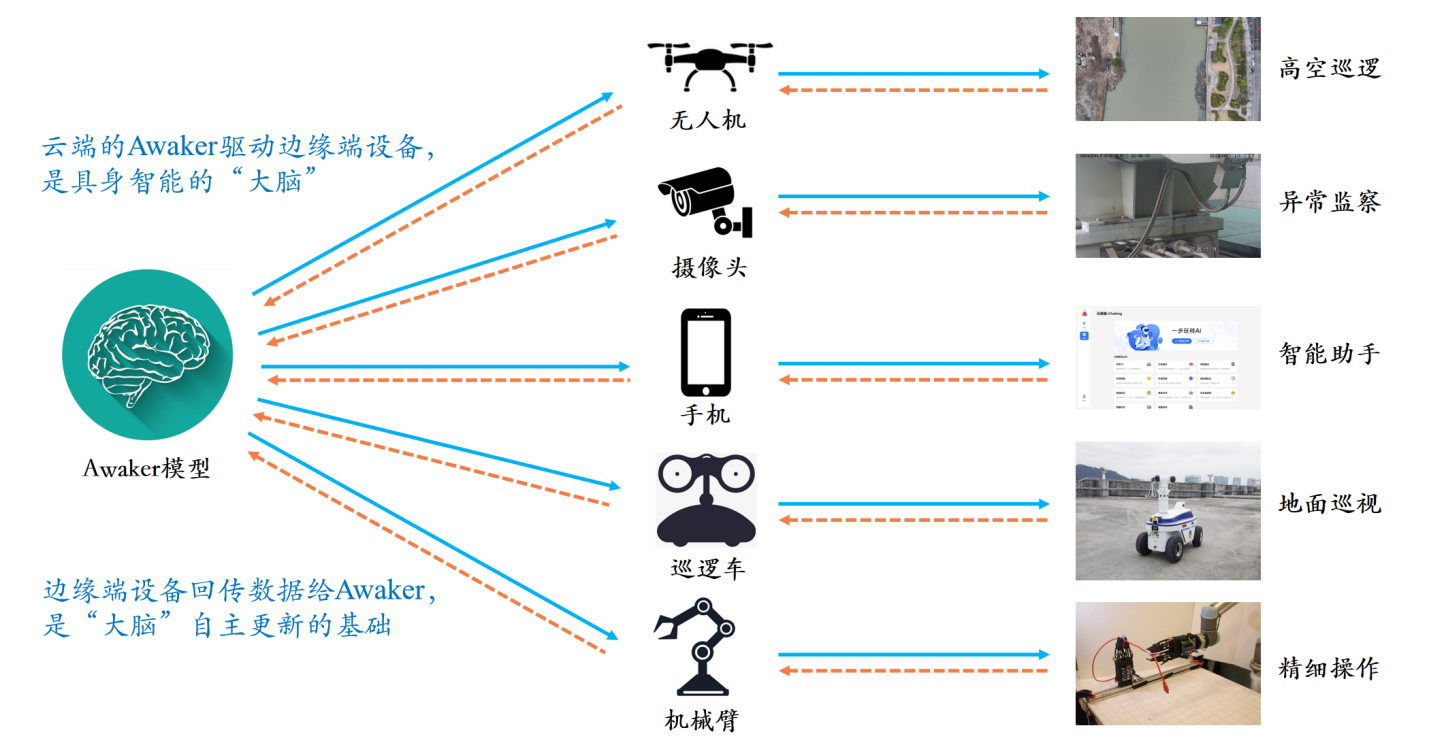
Anders als alle anderen großen multimodalen Modelle ist Awaker 1.0 „live“ und seine Parameter können kontinuierlich in Echtzeit aktualisiert werden. Wie aus dem Rahmendiagramm oben ersichtlich ist, kann Awaker 1.0 mit verschiedenen Smart-Geräten kombiniert werden, die Welt über Smart-Geräte beobachten, Handlungsabsichten generieren und automatisch Anweisungen erstellen, um Smart-Geräte zu steuern, um verschiedene Aktionen auszuführen. Intelligente Geräte generieren nach Abschluss verschiedener Aktionen automatisch verschiedene Rückmeldungen. Aus diesen Aktionen und Rückmeldungen kann Awaker 1.0 effektive Trainingsdaten zur kontinuierlichen Selbstaktualisierung abrufen und die verschiedenen Fähigkeiten des Modells kontinuierlich stärken.
Am Beispiel der Einspeisung neuen Wissens kann Awaker 1.0 kontinuierlich die neuesten Nachrichteninformationen im Internet lernen und auf der Grundlage der neu erlernten Nachrichteninformationen verschiedene komplexe Fragen beantworten. Im Gegensatz zu den herkömmlichen RAG- und Long-Context-Methoden kann Awaker 1.0 wirklich neues Wissen erlernen und es anhand der Parameter des Modells „auswendig lernen“.

Wie aus dem obigen Beispiel ersichtlich ist, konnte Awaker 1.0 an drei aufeinanderfolgenden Tagen der Selbstaktualisierung jeden Tag die Nachrichteninformationen des Tages lernen und die entsprechenden Informationen bei der Beantwortung von Fragen genau aussprechen. Gleichzeitig wird Awaker 1.0 das erlernte Wissen während des kontinuierlichen Lernprozesses nicht vergessen. Beispielsweise wird das Wissen von Zhijie S7 auch nach 2 Tagen von Awaker 1.0 noch gespeichert oder verstanden.
Awaker 1.0 kann auch mit verschiedenen Smart-Geräten kombiniert werden, um eine Cloud-Edge-Zusammenarbeit zu erreichen. Awaker 1.0 wird in der Cloud als „Gehirn“ eingesetzt, um verschiedene Edge-Smart-Geräte zur Ausführung verschiedener Aufgaben zu steuern. Das erhaltene Feedback, wenn das Edge-Smart-Gerät verschiedene Aufgaben ausführt, wird kontinuierlich an Awaker 1.0 zurückgesendet, sodass es kontinuierlich Trainingsdaten abrufen und sich kontinuierlich aktualisieren kann.
Real-World-Simulator: VDT
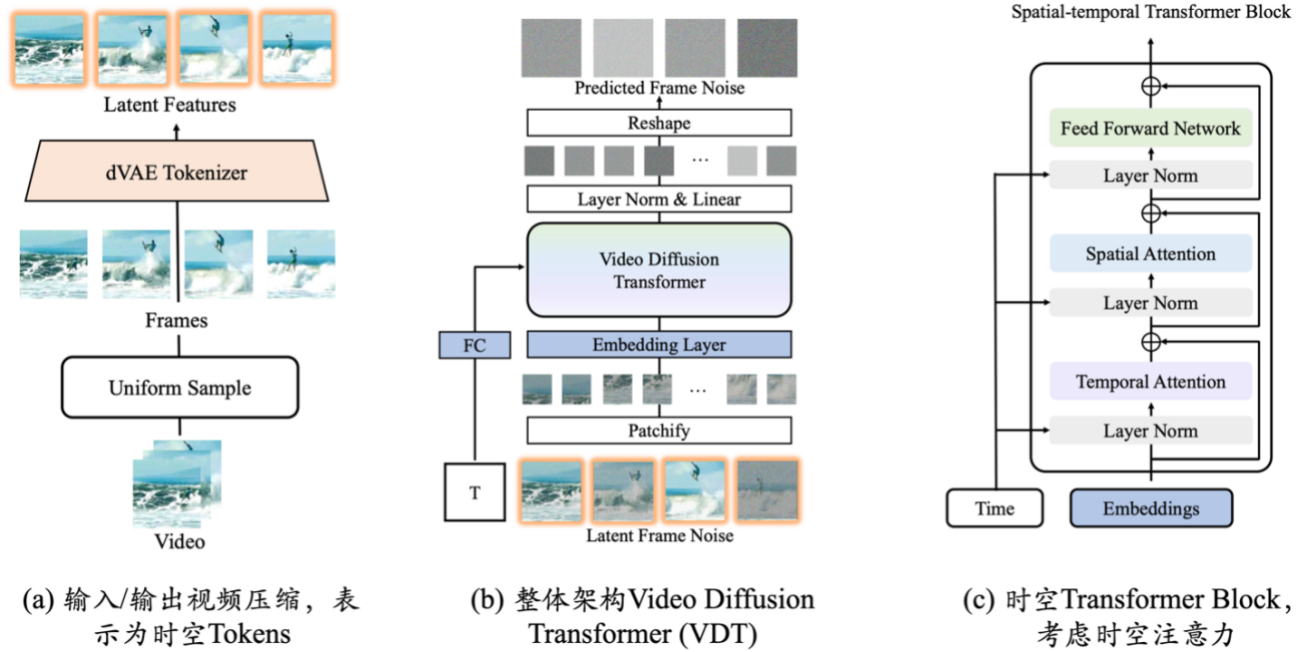
Zu den Neuerungen der Videogenerierungsbasis VDT zählen vor allem folgende Aspekte:
- Die Anwendung der Transformer-Technologie auf die diffusionsbasierte Videogenerierung zeigt das große Potenzial von Transformer im Bereich der Videogenerierung. Der Vorteil von VDT ist seine hervorragende zeitabhängige Erfassungsfähigkeit, die die Erzeugung zeitlich kohärenter Videobilder ermöglicht, einschließlich der Simulation der physikalischen Dynamik dreidimensionaler Objekte im Zeitverlauf.
- Es wird ein einheitlicher raumzeitlicher Maskenmodellierungsmechanismus vorgeschlagen, der es VDT ermöglicht, eine Vielzahl von Videogenerierungsaufgaben zu bewältigen und so die breite Anwendung dieser Technologie zu realisieren. Die flexiblen bedingten Informationsverarbeitungsmethoden von VDT, wie z. B. einfaches Token-Space-Splicing, vereinheitlichen effektiv Informationen unterschiedlicher Länge und Modalitäten. Gleichzeitig ist VDT durch die Kombination mit dem räumlich-zeitlichen Maskenmodellierungsmechanismus zu einem universellen Videodiffusionswerkzeug geworden, das auf die bedingungslose Generierung, die Vorhersage nachfolgender Videobilder, die Bildinterpolation, bildgenerierende Videos und Videobilder angewendet werden kann, ohne die Daten zu ändern Modellstruktur. Fertigstellung und andere Videogenerierungsaufgaben.
Das Sophon-Engine-Team konzentrierte sich auf die Erforschung der VDT-Simulation einfacher physikalischer Gesetze und trainierte VDT anhand des Physion-Datensatzes. Im folgenden Beispiel haben wir festgestellt, dass VDT physikalische Prozesse erfolgreich simuliert hat, z. B. die Bewegung des Balls entlang einer parabolischen Flugbahn und das Rollen des Balls auf einer Ebene und die Kollision mit anderen Objekten. Gleichzeitig ist aus dem zweiten Beispiel in Zeile 2 auch ersichtlich, dass VDT die Geschwindigkeit und den Impuls des Balls erfasst hat, da der Ball aufgrund unzureichender Aufprallkraft letztendlich nicht die Säule umschlug. Dies beweist, dass die Transformer-Architektur bestimmte physikalische Gesetze lernen kann.

Sie führten auch eine eingehende Untersuchung der Aufgabe zur Erstellung von Fotovideos durch. Diese Aufgabe stellt sehr hohe Anforderungen an die Qualität der Videogenerierung, da wir von Natur aus empfindlicher auf dynamische Veränderungen von Gesichtern und Charakteren reagieren. Angesichts der Besonderheit dieser Aufgabe müssen Forscher VDT (oder Sora) und steuerbare Erzeugung kombinieren, um die Herausforderungen der Foto-Video-Erzeugung zu bewältigen. Derzeit hat die Sophon-Engine die meisten Schlüsseltechnologien der Foto-Video-Generierung durchbrochen und eine bessere Qualität der Foto-Video-Generierung als Sora erreicht. Sophon Engine wird den steuerbaren Generierungsalgorithmus von Porträts weiterhin optimieren und erforscht auch aktiv die Kommerzialisierung. Derzeit wurde ein bestätigtes kommerzielles Landungsszenario gefunden, und es wird erwartet, dass die „letzte Meile“-Schwierigkeit bei der Landung großer Modelle in naher Zukunft überwunden wird.
In Zukunft wird ein vielseitigeres VDT ein leistungsstarkes Werkzeug zur Lösung des Problems multimodaler großer Modelldatenquellen sein. Mithilfe der Videogenerierung wird VDT in der Lage sein, die reale Welt zu simulieren, die Effizienz der visuellen Datenproduktion weiter zu verbessern und Unterstützung bei der unabhängigen Aktualisierung des multimodalen Großmodells Awaker zu leisten.
Abschluss
Awaker 1.0 ist ein wichtiger Schritt für das Sophon-Engine-Team auf dem Weg zum ultimativen Ziel, „AGI zu realisieren“. Sophon Engine teilte APPSO mit, dass das Team der Ansicht sei, dass die Selbsterforschung, Selbstreflexion und andere autonome Lernfähigkeiten der KI wichtige Bewertungskriterien für das Intelligenzniveau seien und ebenso wichtig seien wie die kontinuierliche Erhöhung der Parameterskala (Skalierungsgesetz).
Awaker 1.0 hat wichtige technische Frameworks wie „aktive Datengenerierung, Modellreflexion und -bewertung sowie kontinuierliche Modellaktualisierung“ implementiert und damit Durchbrüche sowohl auf der Verständnisseite als auch auf der Generierungsseite erzielt. Es wird erwartet, dass die Entwicklung des multimodalen Großen beschleunigt wird Modellindustrie und letztendlich den Menschen ermöglichen, AGI zu realisieren.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo