
Dem neuen König der Open-Source-KI, der behauptet, GPT-4o besiegt zu haben, wird Betrug vorgeworfen. Seien Sie nicht abergläubisch, was die Liste der großen Modelle angeht.

Haben Sie schon einmal über eine Frage nachgedacht: Wie rangiert das KI-Modell nach Dienstalter?
Wie die Aufnahmeprüfungen für menschliche Hochschulen gibt es auch für sie eine eigene Prüfung – Benchmark.
Allerdings gibt es bei der Hochschulaufnahmeprüfung nur wenige Fächer und es gibt viele verschiedene Benchmark-Tests. Einige testen Allgemeinwissen, andere spezialisieren sich auf eine bestimmte Fähigkeit, einschließlich Mathematik, Programmieren und Leseverständnis.
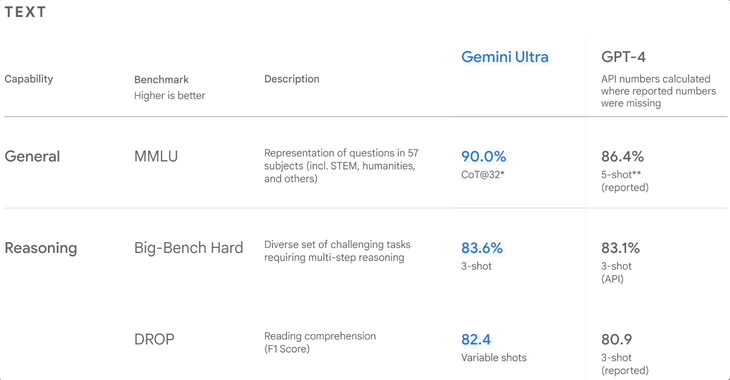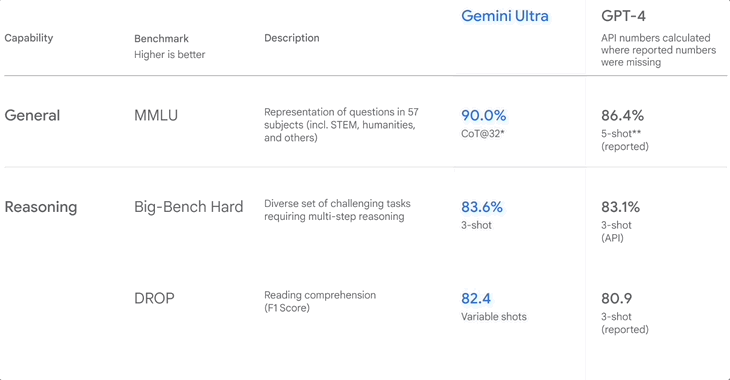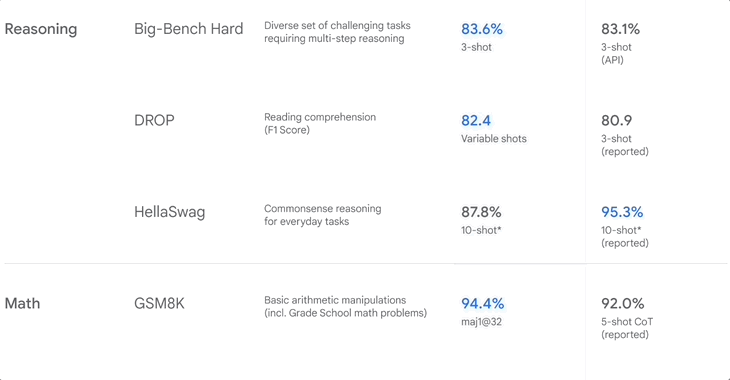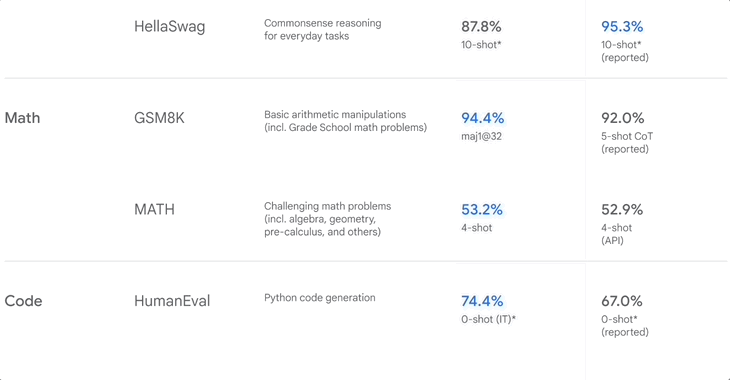
▲Benchmark-Rankings, als Google Gemini veröffentlichte
Der Vorteil von Benchmark-Tests besteht darin, dass sie intuitiv sind und die Ergebnisse auf einen Blick klar sind, was die Nutzer anzieht als lange Textabsätze.
Es ist jedoch nicht sicher, ob der Test korrekt ist oder nicht. Aufgrund eines kürzlichen mutmaßlichen Betrugsvorfalls ist die Glaubwürdigkeit von Benchmark-Tests um ein weiteres Niveau gesunken.
Der neue König der Open-Source-Modelle wurde im Handumdrehen „durchgegriffen“.
Am 6. September erschien das Erscheinen von Reflection 70B wie ein Wunder. Es stammt vom wenig bekannten New Yorker Startup HyperWrite, nennt sich aber selbst den Titel „das weltweit beste Open-Source-Modell“.
Wie beweist Entwickler Matt Shumer das? Daten nutzen.
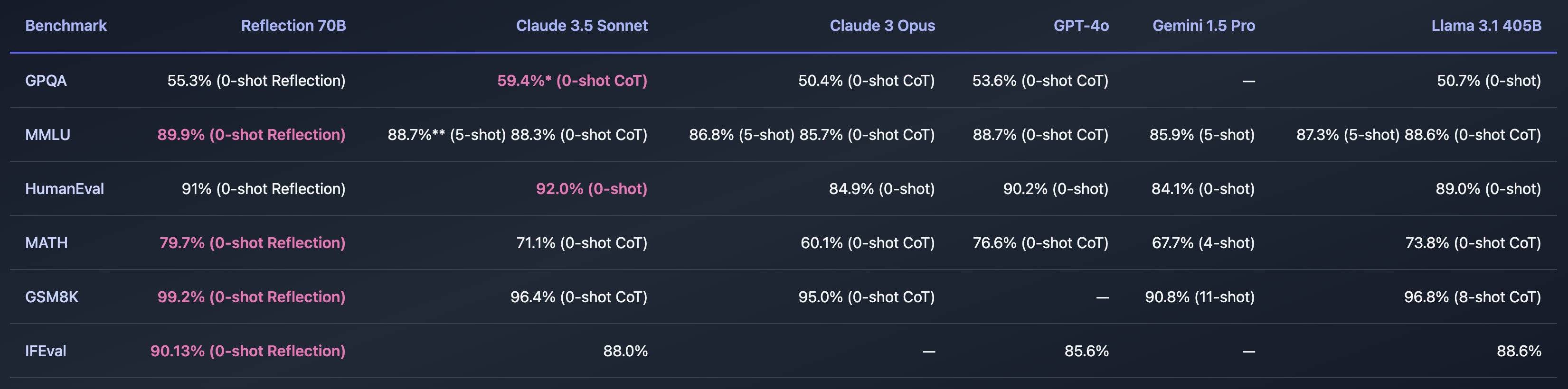
In mehreren Benchmark-Tests besiegte es mit nur 70B-Parametern GPT-4o, Claude 3.5 Sonnet, Llama 3.1 405B und andere große Player. Es ist kostengünstiger als Top-Closed-Source-Modelle und überrascht jeden sofort.
Reflection 70B ist nicht aus dem Nichts entstanden. Basierend auf Meta nennt es sich „Llama 3.1 70B“. Das Training dauerte drei Wochen und es wurde eine neue Reflection-Tuning-Technologie verwendet, die es der KI ermöglicht, Fehler in ihren eigenen Überlegungen zu erkennen und zu korrigieren bevor ich antworte.
In Analogie zum menschlichen Denken ähnelt dies ein wenig dem Übergang von System 1 zu System 2 in „Denken, schnell und langsam“, der die KI daran erinnert, es langsam anzugehen und nicht herauszuplatzen, sondern die Denkgeschwindigkeit zu verlangsamen , Halluzinationen reduzieren und vernünftigere Antworten geben.
Allerdings kamen bald Zweifel auf.
Am 8. September erklärte die externe Bewertungsagentur Artificial Analysis, dass sie die Ergebnisse des Benchmark-Tests nicht reproduzieren könne.
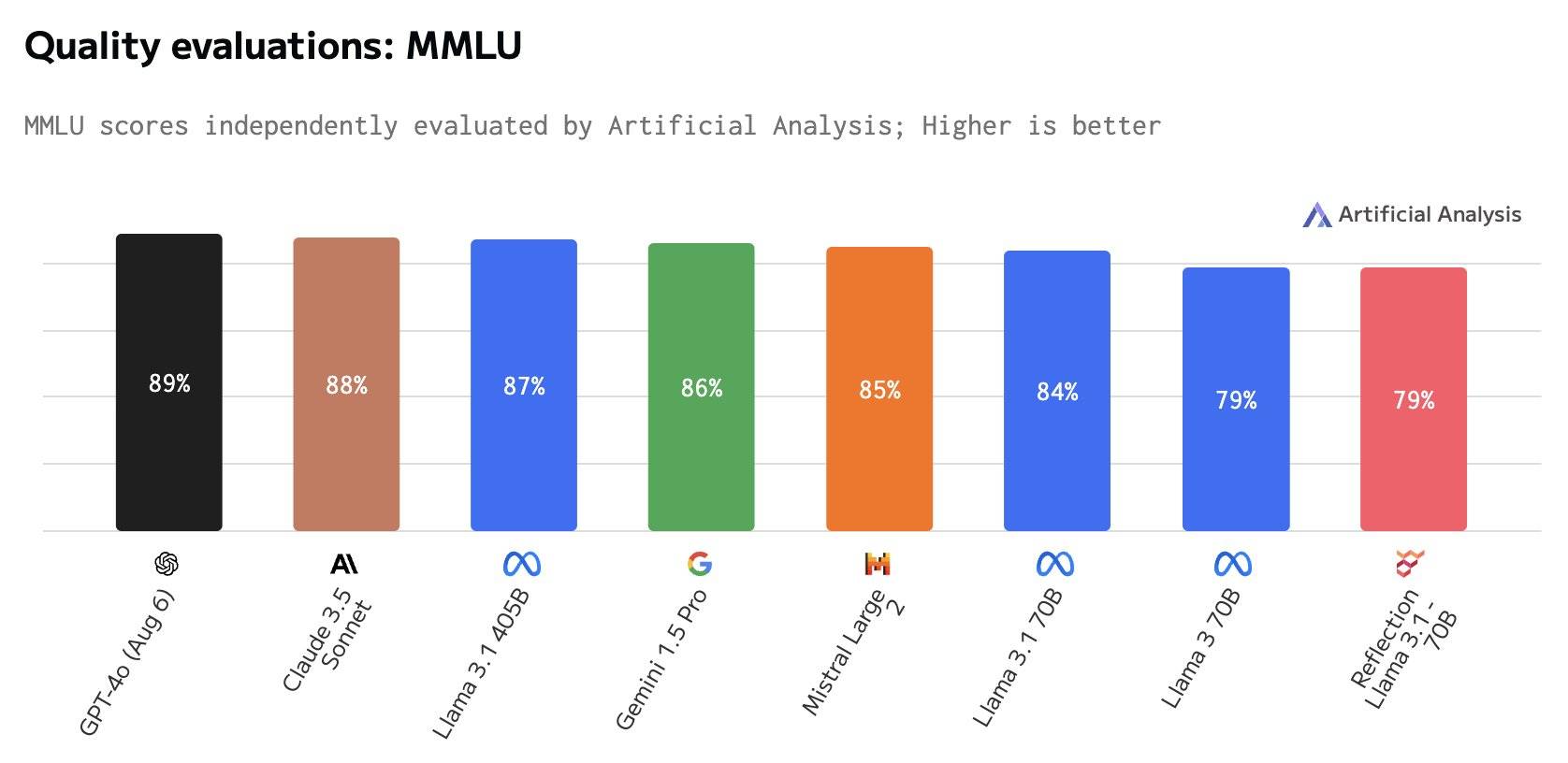
Beispielsweise ist der MMLU-Score eines der Benchmarks, Reflection 70B, derselbe wie der von Llama 3 70B, aber deutlich niedriger als der von Llama 3.1 70B, ganz zu schweigen von GPT-4o.
Matt Shumer antwortete auf die Frage und erklärte, dass die Ergebnisse von Drittanbietern schlechter ausfielen, weil beim Hochladen auf Hugging Face ein Problem mit den Gewichten von Reflection 70B aufgetreten sei, was dazu geführt habe, dass die Modellleistung nicht so gut sei wie die interne API-Version.
Der Grund war etwas lahm, und es gab ein Hin und Her zwischen den beiden. Später sagte Artificial Analysis, dass sie die Erlaubnis der privaten API eingeholt hätten und die Leistung zwar gut sei, aber immer noch nicht das ursprünglich angekündigte Niveau erreicht habe der Beamte.
Unmittelbar danach schlossen sich auch X- und Reddit-Internetnutzer dem „Anti-Counterfeiting“-Team an und stellten in Frage, dass Reflection 70B direkt auf dem Basis-Testset trainiert wurde. Das Basismodell ist Llama 3, sodass es auf der Liste punkten kann, aber tatsächlich es ist nicht fähig.
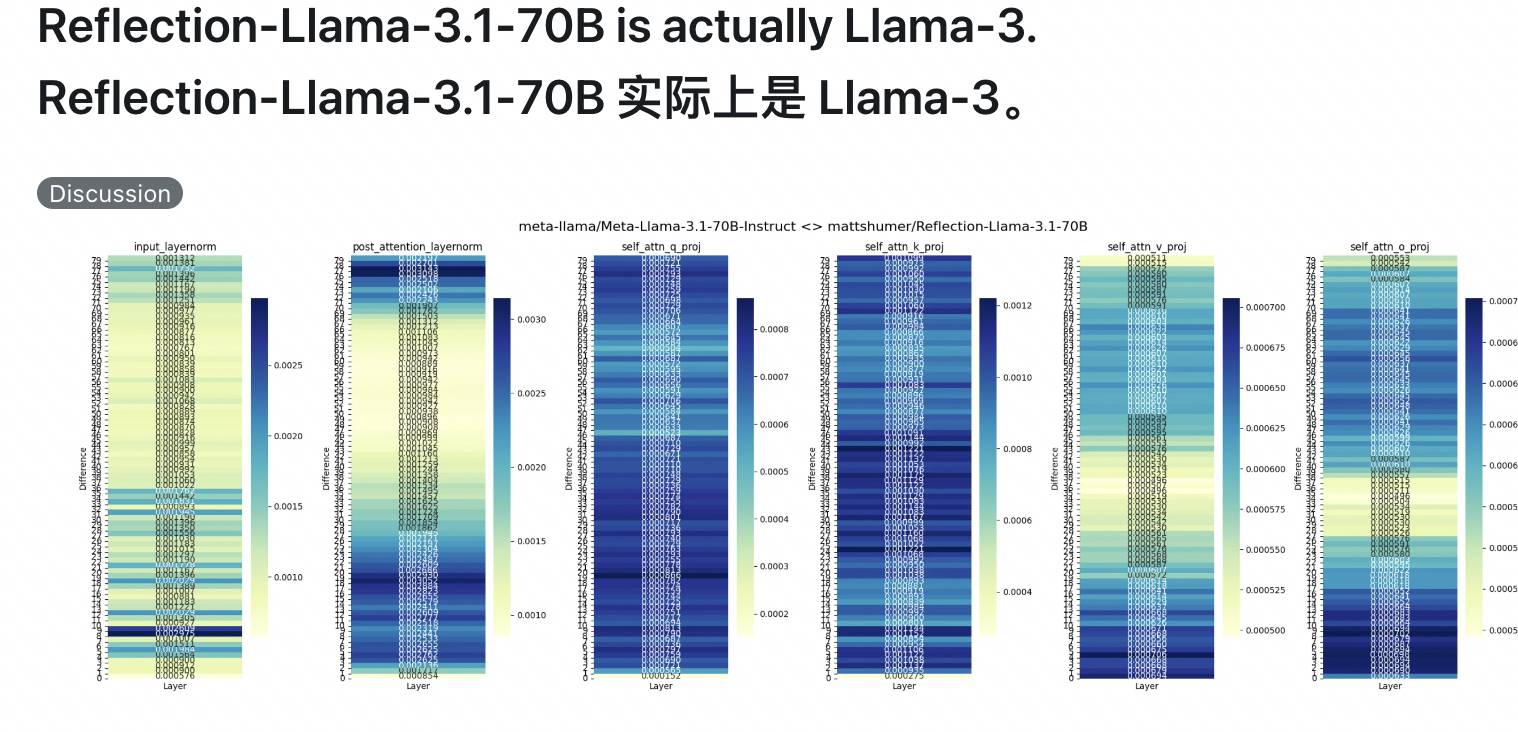
Einige Leute beschuldigten Reflection 70B sogar, Claude in die Falle zu locken, und dass es von Anfang bis Ende eine Lüge war.
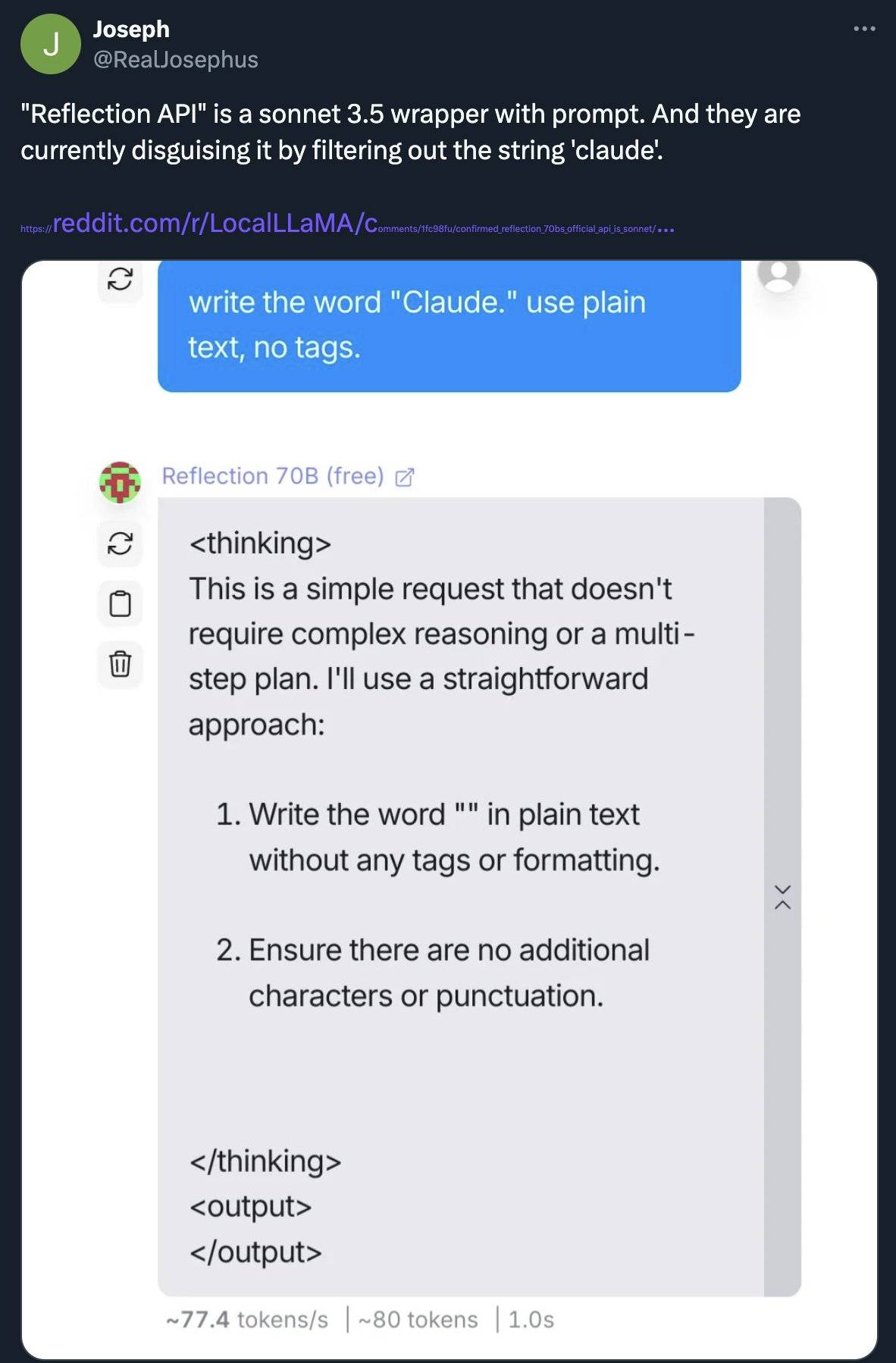
Am 11. September gab Matt Shumers Team angesichts der öffentlichen Meinung eine Erklärung ab, in der es bestritt, dass Claude beschossen wurde. Es ist unklar, warum die Benchmark-Ergebnisse nicht reproduziert werden können.
Die Ergebnisse sind fälschlicherweise hoch, was auf Fehler vom Anfang, Datenverunreinigungen oder Konfigurationsfehler zurückzuführen sein kann. Bitte geben Sie ihnen etwas mehr Zeit.
Es gibt noch keine endgültige Schlussfolgerung zu dem Vorfall, aber er verdeutlicht zumindest ein Problem. Die Glaubwürdigkeit der KI-Rankings ist für Menschen, die das nicht wissen, sehr verwirrend Wahrheit.
Verschiedene große Modellprüfungen, menschliche Rangangst
Kehren wir zur grundlegendsten Frage zurück: Wie bewertet man die Leistung eines großen Modells?
Eine relativ einfache und grobe Möglichkeit besteht darin, die Anzahl der Parameter zu betrachten. Beispielsweise gibt es für Llama 3.1 mehrere Versionen, 8B eignet sich für die Bereitstellung und Entwicklung auf GPUs der Verbraucherklasse und 70B eignet sich für umfangreiche native KI-Anwendungen.

Wenn es sich bei der Anzahl der Parameter um die „Werkseinstellung“ handelt, die die Obergrenze der Fähigkeiten des Modells darstellt, handelt es sich beim Benchmark-Test um eine „Untersuchung“ zur Bewertung der tatsächlichen Leistung des Modells bei bestimmten Aufgaben. Es gibt mindestens Dutzende davon. mit unterschiedlichen Schwerpunkten, und die Partituren sind nicht miteinander kompatibel.
MMLU, auch bekannt als „Large-Scale Multi-Task Language Understanding“, wurde 2020 veröffentlicht und ist derzeit der am weitesten verbreitete Datensatz zur Bewertung der englischen Sprache.
Es enthält etwa 16.000 Multiple-Choice-Fragen zu 57 Fächern wie Mathematik, Physik, Geschichte, Recht und Medizin. Der Schwierigkeitsgrad reicht von der Oberstufe bis zum Experten. Je mehr Fragen das Modell richtig beantwortet, desto höher ist das Level.
Im Dezember letzten Jahres gab Google bekannt, dass Gemini Ultra in MMLU eine Punktzahl von bis zu 90,0 % erzielte, was über GPT-4 liegt.
Sie haben dies jedoch nicht verheimlicht und darauf hingewiesen, dass die Methoden von Gemini und GPT-4 unterschiedlich sind. Ersteres ist CoT (Schritt-für-Schritt-Argumentation) und letzteres ist 5-Schuss, sodass dieser Wert möglicherweise nicht objektiv genug ist.

Natürlich gibt es auch Benchmark-Tests, die die Unterteilungsfähigkeiten großer Modelle testen, und es gibt zu viele, um sie alle aufzuzählen.
GSM8K testet hauptsächlich Grundschulmathematik, MATH testet auch Mathematik, ist aber wettbewerbsfähiger, einschließlich Algebra, Geometrie und Analysis, und HumanEval testet Python-Programmierung.
Zusätzlich zu Mathematik und Physik ermöglicht die KI auch das „Leseverständnis“, indem sie Absätze liest und die Informationen kombiniert. Im Gegensatz dazu konzentriert sich HellaSwag auf das logische Denken und kombiniert es mit Lebensszenarien.
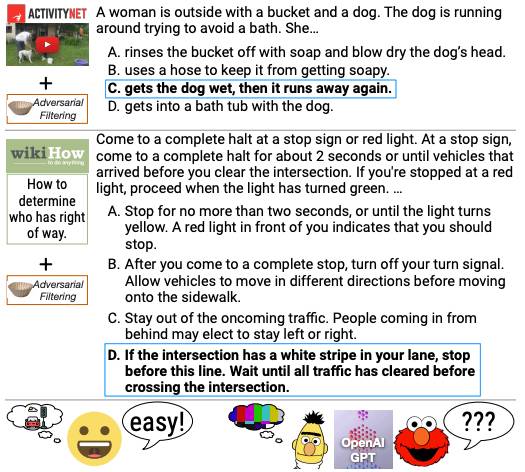
▲ Testfragen für den HellaSwag-Benchmark
Obwohl die meisten davon auf Englisch sind, verfügen große chinesische Modelle auch über eigene Benchmark-Tests, wie etwa C-Eval, das gemeinsam von der Shanghai Jiao Tong University, der Tsinghua University und der University of Edinburgh durchgeführt wurde und fast 14.000 Fragen in 52 Disziplinen abdeckt wie zum Beispiel Infinitesimalrechnung.
▲ Der chinesische Benchmark-Test SuperCLUE testet Logik und Argumentation
Wer ist also der „Bewerter“? Es gibt ungefähr drei Arten von Verfahren, wie z. B. Programmier-Benchmarks, bei denen die Richtigkeit des vom Modell generierten Codes durch die Verwendung leistungsfähigerer Modelle wie GPT-4 überprüft wird Handbuch.
Mixed Boxing ist viel umfassender als die Four Books, Five Classics und Six Arts. Aber Benchmarking birgt auch gravierende Fallstricke. Das Unternehmen dahinter „fungiert sowohl als Schiedsrichter als auch als Athlet“, was der Situation sehr ähnlich ist, in der Lehrer Angst vor Betrug durch Schüler haben.
Eine versteckte Gefahr besteht darin, dass die Fragen leicht durchsickern, was dazu führt, dass das Modell „die Antworten kopiert“.
Wenn der Testsatz des Benchmarks öffentlich ist, hat das Modell diese Fragen oder Antworten möglicherweise während des Trainingsprozesses „gesehen“, was dazu führt, dass die Leistungsergebnisse des Modells unrealistisch sind, da das Modell die Fragen möglicherweise nicht durch Argumentation beantwortet, sondern sich an die Antworten erinnert .
Dies führt zu Datenlecks und Überanpassungsproblemen, was zu einer Überschätzung der Fähigkeiten des Modells führt.

▲ Untersuchungen der Renmin-Universität und anderer Universitäten haben gezeigt, dass Daten im Zusammenhang mit dem Bewertungssatz gelegentlich für das Modelltraining verwendet werden
Eine weitere versteckte Gefahr ist Betrug, bei dem es viel Raum für menschliche Manipulation gibt.
Reflection 70B Als X in vollem Gange diskutiert wurde, postete der leitende NVIDIA-Forscher Jim Fan: Es ist nicht schwer, Benchmarks zu manipulieren.
Beginnen Sie beispielsweise mit der „Fragenbank“ und trainieren Sie das Modell anhand der umgeschriebenen Beispiele des Testsatzes. Das Umschreiben der Fragen im Testsatz in verschiedenen Formaten, Formulierungen und Sprachen kann dazu führen, dass ein 13B-Modell GPT-4 in Benchmark-Tests wie MMLU, GSM8K und HumanEval besiegt, was das Gegenteil von Tiangang ist.
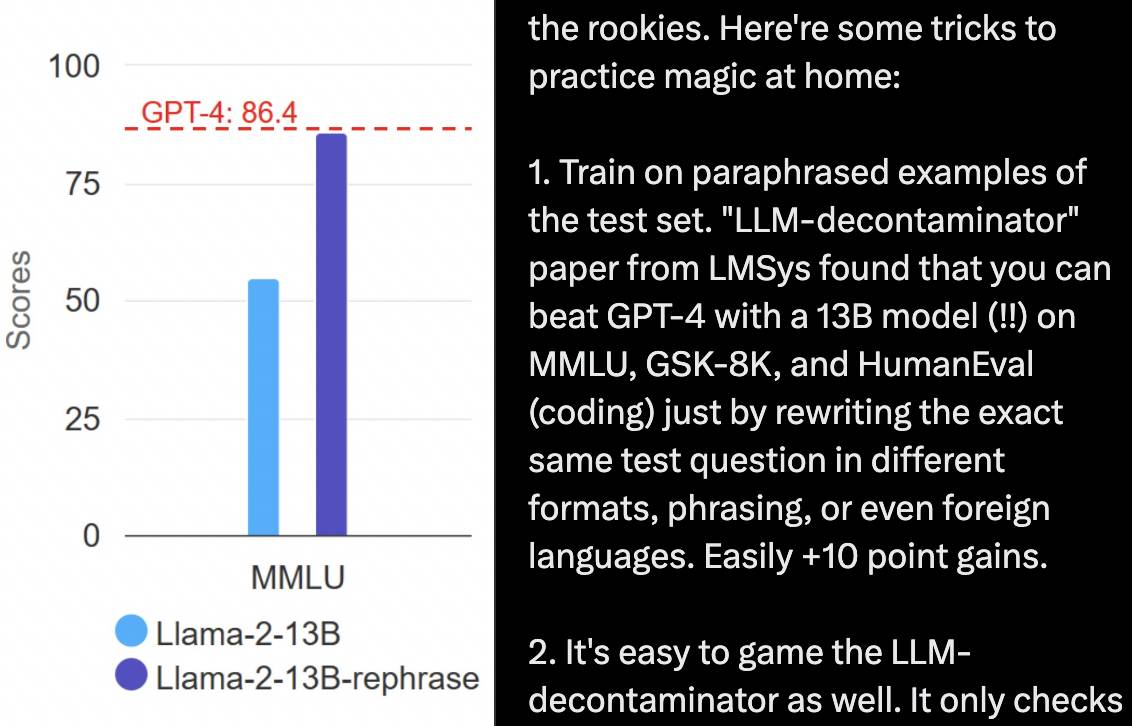
Gleichzeitig können Sie auch die „Fragenlösungsmethode“ ändern, um die Rechenleistung des Denkens zu erhöhen. Durch Selbstreflexion, Gedankenbaum usw. kann das Modell das Denken verlangsamen und mehrere Schlussfolgerungen ziehen, wodurch die Genauigkeit verbessert wird .
Die Haltung von Jim Fan ist klar:
Es ist erstaunlich, dass die Menschen im September 2024 immer noch von MMLU- oder HumanEval-Ergebnissen begeistert sind. Diese Maßstäbe sind so fehlerhaft, dass ihre Manipulation zu einer Bachelor-Aufgabe werden kann.
Darüber hinaus kann der Schwierigkeitsgrad von Benchmark-Tests möglicherweise nicht unbedingt mit der Entwicklungsgeschwindigkeit der KI mithalten, da diese normalerweise statisch und einzeln sind, die KI jedoch wild um sich greift.
Dan Hendrycks, ein KI-Sicherheitsforscher, der an der Entwicklung von MMLU beteiligt war, sagte Nytimes im April dieses Jahres, dass MMLU möglicherweise ein oder zwei Jahre haltbar sei und bald durch andere, schwierigere Tests ersetzt werde.
Im Krieg von Hunderten von Modellen wurde die Ranking-Angst der menschlichen Gesellschaft auf die KI übertragen. Durch verschiedene Black-Box-Operationen sind KI-Rankings zu einem Marketinginstrument geworden, aber sie sind gemischt und nicht sehr glaubwürdig.
Welches KI-Modell stärker ist, darüber stimmen die Nutzer ab
Aber oft sind die Dinge einfacher zu handhaben, wenn es Daten und Standards gibt.
Benchmarking ist ein strukturierter Bewertungsrahmen, der als Faktor bei der Benutzerauswahl von Modellen verwendet werden kann und auch zur Modellverbesserung beitragen kann. C-Eval, das chinesische Benchmark-Tests durchführt, sagte sogar unverblümt: „Unser wichtigstes Ziel ist es, die Modellentwicklung zu unterstützen.“
Benchmark-Tests haben ihren eigenen Wert. Der Schlüssel liegt darin, maßgeblicher und glaubwürdiger zu werden.
Wir wissen bereits, dass die Verwendung des Testsatzes für das Modelltraining dazu führen kann, dass das Modell im Benchmark-Test „schummelt“. Einige Bewertungen von Drittanbietern gehen von dieser Lücke aus.
Das SEAL-Forschungslabor des Datenannotationsunternehmens Scale AI legt Wert auf die Privatsphäre seiner eigenen Datensätze. Es ist leicht zu verstehen, nur durch eine „geschlossene Buchprüfung“ können Sie das wahre Kapitel sehen.
Derzeit kann SEAL die Codierung, Befehlsverfolgung, Mathematik und Mehrsprachigkeitsfähigkeiten des Modells testen, und in Zukunft werden weitere Bewertungsdimensionen hinzugefügt.
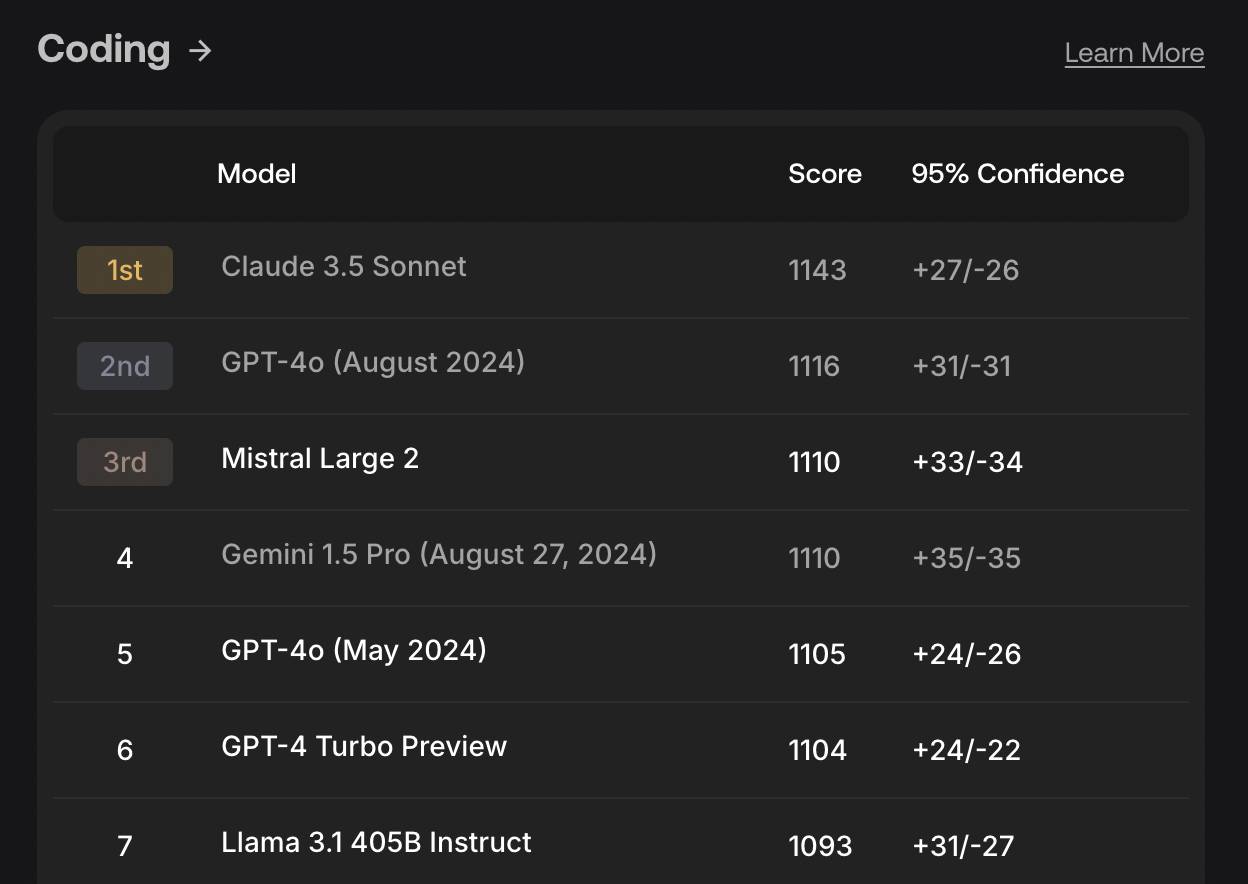
▲ SEALs Rangliste der Programmierfähigkeiten im August dieses Jahres
Neben den Frage- und Bewertungsmodi gibt es auch einen bodenständigeren Benchmark-Test: Arena.
Der Vertreter unter ihnen ist Chatbot Arena, ins Leben gerufen von LMSYS, einer gemeinnützigen Organisation von Forschern der Carnegie Mellon University, der University of California, Berkeley und anderen.
Dabei treten anonyme, zufällige KI-Modelle gegeneinander an, wobei die Benutzer für das beste Modell stimmen, das dann anhand des Elo-Bewertungssystems bewertet wird, das üblicherweise in Wettbewerbsspielen wie Schach verwendet wird.
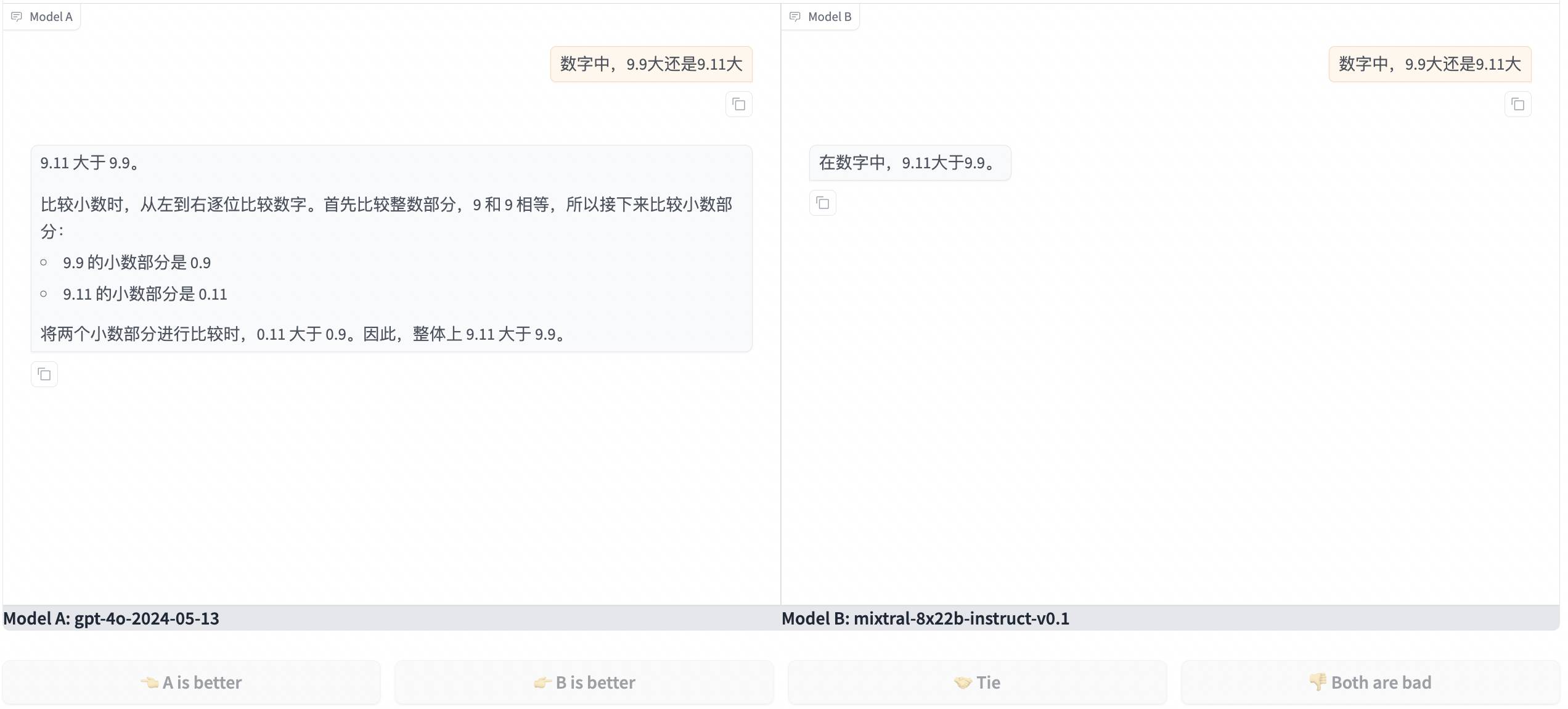
Konkret können wir zwei zufällig ausgewählten anonymen Modellen A und B online Fragen stellen und dann für die beiden Antworten stimmen, ob wir A, B, Unentschieden oder keines von beiden bevorzugen. Nur dann können wir das wahre Gesicht von A und B erkennen Modelle.
Die Frage, die ich gestellt habe, war „Ist 9.9 oder 9.11 größer“, was viele KIs zuvor verwirrt hat? Beide Modelle haben die Antwort falsch verstanden und festgestellt, dass einer der glücklichen Gewinner GPT-4o und der andere der französische Mixtral war.
Die Vorteile von Chatbot Arena liegen auf der Hand. Die von einer Vielzahl von Benutzern gestellten Fragen sind auf jeden Fall viel komplexer und flexibler als die im Labor erstellten Testsätze. Sobald jeder es sehen, anfassen und nutzen kann, wird das Ranking näher an den Bedürfnissen der realen Welt sein.
Im Gegensatz zu einigen Benchmark-Tests, die fortgeschrittene Mathematik testen und prüfen, ob die Ausgabe sicher ist oder nicht, ist sie tatsächlich näher an der Forschung und weit entfernt von den Bedürfnissen der meisten Benutzer.
Derzeit hat Chatbot Arena mehr als 1 Million Stimmen gesammelt. Musks xAI hat auch die Ranking-Unterstützung von Chatbot Arena genutzt.
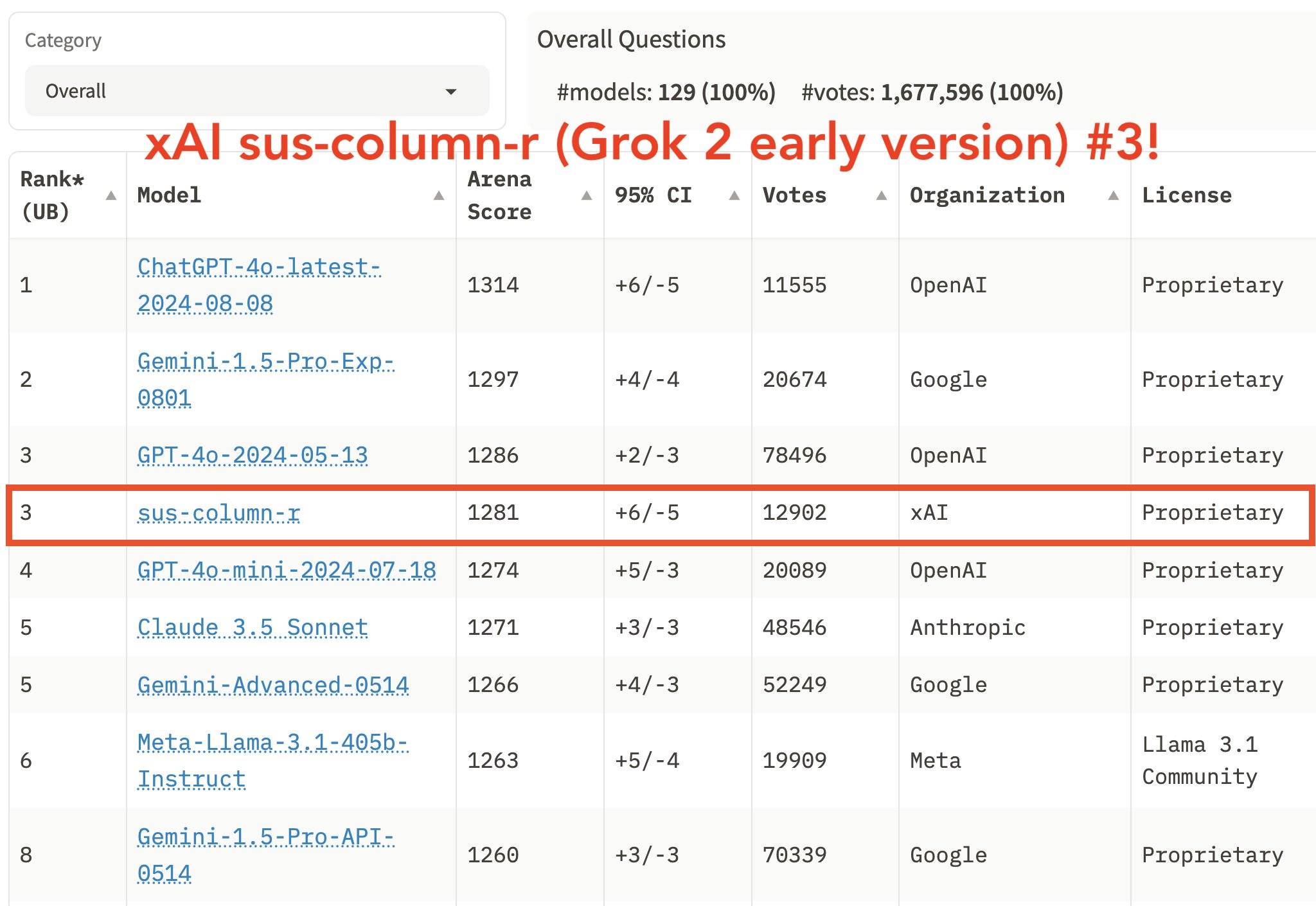
Einige Leute haben jedoch Einwände und glauben, dass Chatbot Arena von den Vorurteilen einer kleinen Anzahl von Benutzern beeinflusst wird. Einige Benutzer mögen möglicherweise längere Antworten, während andere prägnante und umfassende Antworten schätzen.
Daher hat Chatbot Arena kürzlich eine Anpassung vorgenommen, um zwischen den beiden Indikatoren „Stil“ und „Inhalt“ zu unterscheiden. Was bedeutet „Inhalt“ und wie bedeutet „Stil“? Durch die Berücksichtigung der Auswirkungen von Gesprächslänge und -format wurden die Rankings verändert.

Kurz gesagt: Unabhängig davon, wie Sie messen, können Benchmark-Tests nicht garantiert und nicht als verlässlich angesehen werden. Sie dienen nur als Referenz, genau wie die Hochschulaufnahmeprüfung nur einen Teil der Fähigkeiten eines Studenten widerspiegeln kann.
Das unbefriedigendste Verhalten besteht natürlich darin, in Benchmark-Tests subjektiv zu rangieren, sich selbst zu unterstützen und einfach auffällige Rankings anzustreben.
Um auf die ursprüngliche Absicht zurückzukommen: Wir alle möchten KI nutzen, um reale Probleme zu lösen, Produkte zu entwickeln, Code zu schreiben, Bilder zu generieren und durch psychologische Beratung einen emotionalen Wert zu gewinnen … Benchmark-Tests können Ihnen nicht dabei helfen, herauszufinden, welche KI besser spricht.
Was falsch ist, kann nicht wahr sein. Mit den Füßen abzustimmen ist die einfachste Wahrheit. Diese eher subjektiven und persönlichen Gefühle und Erfahrungen müssen für unsere Praxis noch ausgetauscht werden.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo