
Der umfassendste Leitfaden! OpenAI veröffentlicht den GPT-4-Nutzungsleitfaden. Alle nützlichen Informationen finden Sie hier

Seit seiner Gründung wurde ChatGPT mit seiner bahnbrechenden Innovation von unzähligen Menschen auf den Altar der generativen KI befördert.
Wir erwarten immer, dass es unsere Absichten genau versteht, aber wir stellen oft fest, dass seine Antworten oder Kreationen nicht zu 100 % unseren Erwartungen entsprechen. Diese Lücke kann auf unsere überzogenen Erwartungen an die Modellleistung oder darauf zurückzuführen sein, dass wir es nicht geschafft haben, bei der Nutzung den effektivsten Kommunikationskanal zu finden.
So wie Entdecker Zeit brauchen, um sich an neues Terrain zu gewöhnen, erfordert auch unsere Interaktion mit ChatGPT Geduld und Fähigkeiten. Zuvor veröffentlichte OpenAI offiziell den GPT-4-Nutzungsleitfaden Prompt Engineering, in dem sechs Strategien zur Steuerung von GPT-4 aufgezeichnet wurden.
Ich glaube, dass Ihre Kommunikation mit ChatGPT damit in Zukunft reibungsloser verlaufen wird.
Fassen wir diese sechs Strategien kurz zusammen:
- Schreiben Sie klare Anweisungen
- Geben Sie Referenztext an
- Teilen Sie komplexe Aufgaben in einfachere Teilaufgaben auf
- Geben Sie dem Modell Zeit zum „Nachdenken“
- Nutzen Sie externe Tools
- Testen Sie Änderungen systematisch
Schreiben Sie klare Anweisungen
Beschreiben Sie detaillierte Informationen
ChatGPT kann unsere impliziten Gedanken nicht beurteilen, daher sollten wir Sie so klar wie möglich über Ihre Anforderungen informieren, wie z. B. die Länge der Antwort, den Schreibgrad, das Ausgabeformat usw.
Je weniger wir ChatGPT unsere Absichten erraten und ableiten lassen, desto wahrscheinlicher ist es, dass die Ausgabe unseren Anforderungen entspricht. Wenn wir ihn beispielsweise bitten, eine psychologische Arbeit zu schreiben, sollten die vorgegebenen Worte so aussehen 
Bitte helfen Sie mir, eine psychologische Arbeit über „Die Ursachen und Behandlung von Depressionen“ zu schreiben. Anforderungen: Ich muss relevante Literatur durchsuchen und darf weder plagiieren noch plagiieren; ich muss mich an das wissenschaftliche Papierformat halten, einschließlich Zusammenfassung, Einleitung, Hauptteil, Schlussfolgerung usw .; Die Wortanzahl beträgt 2000 Wörter oder mehr.

Lassen Sie das Modell eine Rolle spielen
Es gibt Spezialisierungen in der Branche, und das designierte Modell spielt eine spezielle Rolle, und die von ihm ausgegebenen Inhalte werden professioneller erscheinen.
Zum Beispiel: Spielen Sie bitte einen Kriminalromanautor der Polizei und verwenden Sie Argumente im Conan-Stil, um einen bizarren Mordfall zu beschreiben. Anforderungen: Eine anonyme Behandlung ist erforderlich, die Wortzahl beträgt mehr als 1.000 Wörter und die Handlung weist Höhen und Tiefen auf.
Verwenden Sie Trennzeichen, um verschiedene Abschnitte klar zu trennen
Trennzeichen wie dreifache Anführungszeichen, XML-Tags und Abschnittsüberschriften können dabei helfen, Textabschnitte, die unterschiedlich behandelt werden müssen, zu unterteilen und das Modell besser eindeutig zu machen.

Geben Sie die Schritte an, die zum Abschließen der Aufgabe erforderlich sind
Die Aufteilung einiger Aufgaben in eine Reihe klar definierter Schritte erleichtert dem Modell die Ausführung dieser Schritte.

Geben Sie Beispiele an
Oft ist es effektiver, eine allgemeine Erklärung zu geben, die für alle Beispiele gilt, als dies anhand von Beispielen zu demonstrieren, aber in manchen Fällen kann es einfacher sein, Beispiele zu liefern.
Wenn ich dem Modell zum Beispiel sage, dass man zum Schwimmenlernen nur mit den Beinen treten und die Arme schwingen muss, dann ist das eine allgemeine Aussage. Und wenn ich dem Model ein Schwimmvideo zeige, in dem die spezifischen Bewegungen des Tretens und Schwingens der Arme gezeigt werden, wird das anhand von Beispielen erklärt.
Geben Sie die Ausgabelänge an
Wir können dem Modell mitteilen, wie lang die von ihm generierte Ausgabe sein soll, und diese Länge kann in Wörtern, Sätzen, Absätzen, Aufzählungspunkten usw. gezählt werden.
Aufgrund der internen Mechanismen des Modells und der Komplexität der Sprache ist es am besten, sie nach Absätzen und Schlüsselpunkten zu unterteilen, damit die Wirkung besser ist.
Geben Sie Referenztext an
Lassen Sie das Modell mit Referenztext antworten
Wenn wir mehr Referenzinformationen zur Hand haben, können wir diese dem Modell „füttern“ und das Modell die bereitgestellten Informationen zur Beantwortung verwenden lassen.

Lassen Sie das Modell den Referenztext zur Antwort zitieren
Wenn die Eingabe bereits relevante Wissensdokumente enthält, können Benutzer das Modell direkt bitten, Verweise auf seine Antworten hinzuzufügen, indem sie Passagen im Dokument zitieren, wodurch die Möglichkeit minimiert wird, dass das Modell Unsinn redet.
In diesem Fall können die Zitate in der Ausgabe auch programmgesteuert überprüft werden, indem Zeichenfolgen im bereitgestellten Dokument abgeglichen werden, um die Richtigkeit des Zitats zu bestätigen.

Teilen Sie komplexe Aufgaben in einfachere Teilaufgaben auf
Verwenden Sie die Absichtsklassifizierung, um Anweisungen zu identifizieren, die für Benutzeranfragen am relevantesten sind
Bei der Bewältigung von Aufgaben, die viele verschiedene Vorgänge erfordern, können wir einen intelligenteren Ansatz wählen. Teilen Sie das Problem zunächst in verschiedene Typen auf und sehen Sie, welche Operationen jeder Typ erfordert. Wenn wir Dinge organisieren, stellen wir zunächst ähnliche Dinge zusammen.
Dann können wir einige Standardoperationen für jeden Typ definieren, genau wie das Beschriften jeder Art von Dingen. Auf diese Weise können einige allgemeine Schritte im Voraus definiert werden, wie z. B. Suche, Vergleich, Verständnis usw.
Diese Verarbeitungsmethode kann Schicht für Schicht weiterentwickelt werden. Wenn wir spezifischere Fragen stellen möchten, können wir sie basierend auf vorherigen Vorgängen weiter verfeinern.
Dies hat den Vorteil, dass Sie bei jeder Beantwortung einer Benutzerfrage nur die für den aktuellen Schritt erforderlichen Vorgänge ausführen müssen und nicht die gesamte Aufgabe auf einmal erledigen müssen. Dies verringert nicht nur die Fehlerwahrscheinlichkeit, sondern spart auch Zeit, da es kostspielig sein kann, die gesamte Aufgabe auf einmal zu erledigen.

Fassen Sie für Anwendungsszenarien, die lange Gespräche bewältigen müssen, frühere Gespräche zusammen oder filtern Sie sie
Wenn das Modell Dialoge verarbeitet, ist es durch die feste Kontextlänge begrenzt und kann sich nicht an den gesamten Dialogverlauf erinnern.
Eine Möglichkeit, dieses Problem zu lösen, besteht darin, die vorherige Konversation zusammenzufassen. Wenn die Länge der eingegebenen Konversation eine bestimmte Grenze erreicht, kann das System den vorherigen Chat-Inhalt automatisch zusammenfassen und einen Teil der Informationen als Zusammenfassung anzeigen oder dies tun Während dies der Fall ist Im weiteren Verlauf werden die bisherigen Chatinhalte leise im Hintergrund zusammengefasst.
Eine andere Lösung besteht darin, während der Bearbeitung dynamisch die Teile des Gesprächs auszuwählen, die für das aktuelle Problem am relevantesten sind. Dieser Ansatz beinhaltet eine Strategie namens „Effizienter Wissensabruf mithilfe einbettungsbasierter Suche“.
Vereinfacht ausgedrückt geht es darum, anhand des Inhalts der aktuellen Frage die relevanten Teile des vorherigen Gesprächs zu finden. Dadurch werden frühere Informationen effektiver genutzt und das Gespräch fokussierter.
Fassen Sie lange Dokumente segmentweise zusammen und erstellen Sie rekursiv eine vollständige Zusammenfassung
Da sich das Modell nur begrenzte Informationen merken kann, kann es nicht direkt zum Zusammenfassen sehr langer Texte verwendet werden. Um lange Dokumente zusammenzufassen, können wir eine schrittweise Zusammenfassungsmethode verwenden.
Genau wie beim Lesen eines Buches können wir jeden Abschnitt zusammenfassen, indem wir Kapitel für Kapitel Fragen stellen. Die Zusammenfassungen der einzelnen Abschnitte können zu einer Zusammenfassung des gesamten Dokuments aneinandergereiht werden. Dieser Prozess kann Schicht für Schicht rekursiv erfolgen, bis das gesamte Dokument zusammengefasst ist.
Wenn Sie verstehen möchten, was folgt, müssen Sie möglicherweise die vorherigen Informationen verwenden. Ein weiterer nützlicher Tipp in diesem Fall ist, sich vor dem Lesen bis zu einem bestimmten Punkt die Zusammenfassung anzusehen und sich eine Vorstellung davon zu machen, worum es bei diesem Punkt geht.
Geben Sie dem Modell Zeit zum „Nachdenken“
Weisen Sie das Modell an, eine eigene Lösung zu finden, bevor Sie voreilige Schlussfolgerungen ziehen
In der Vergangenheit haben wir das Modell möglicherweise direkt gebeten, sich die Antwort des Schülers anzusehen und es dann zu fragen, ob die Antwort richtig ist. Manchmal ist die Antwort des Schülers jedoch falsch. Wenn das Modell direkt gebeten wird, die Antwort des Schülers zu beurteilen, ist dies der Fall ist möglicherweise nicht genau.
Um das Modell genauer zu machen, können wir das Modell dieses mathematische Problem zunächst selbst lösen lassen und zuerst die eigene Antwort des Modells berechnen. Lassen Sie das Modell dann die Antworten des Schülers mit den eigenen Antworten des Modells vergleichen.
Indem das Modell die Berechnungen zunächst selbst durchführt, kann es leichter feststellen, ob die Antwort des Schülers richtig ist. Wenn die Antwort des Schülers von der Antwort des Modells selbst abweicht, weiß es, dass der Schüler falsch geantwortet hat. Dies ermöglicht es dem Modell, mit dem Denken beim grundlegendsten ersten Schritt zu beginnen, anstatt die Antwort des Schülers direkt zu beurteilen, was die Beurteilungsgenauigkeit des Modells verbessern kann.

Verwenden Sie einen inneren Monolog, um den Denkprozess des Modells zu verbergen
Manchmal ist es bei der Beantwortung einer bestimmten Frage für das Modell wichtig, das Problem im Detail zu begründen. Für einige Anwendungsszenarien ist der Inferenzprozess des Modells jedoch möglicherweise nicht für die gemeinsame Nutzung mit Benutzern geeignet.
Um dieses Problem zu lösen, gibt es eine Strategie namens interner Monolog. Die Idee dieser Strategie besteht darin, das Modell anzuweisen, einen Teil der Ausgabe, die der Benutzer nicht sehen möchte, in einer strukturierten Form zu organisieren und dann nur einen Teil davon, nicht alles, anzuzeigen, wenn er dem Benutzer präsentiert wird.
Angenommen, wir unterrichten ein bestimmtes Fach und müssen die Fragen der Schüler beantworten. Wenn wir den Schülern alle Argumentationsideen des Modells direkt mitteilen, müssen die Schüler nicht selbst darüber nachdenken.
Daher können wir die Strategie des „inneren Monologs“ verwenden: Lassen Sie das Modell zunächst vollständig über das Problem nachdenken, denken Sie alle Lösungsideen durch und wählen Sie dann nur einen kleinen Teil der Ideen des Modells aus und erzählen Sie es den Schülern in einfacher Sprache.
Oder wir können eine Reihe von Fragen entwerfen: Lassen Sie das Modell zunächst selbst über die gesamte Lösung nachdenken, ohne den Schülern eine Antwort zu erlauben, und geben Sie den Schülern dann eine einfache, ähnliche Frage basierend auf den Ideen des Modells. Nachdem die Schüler geantwortet haben, lassen Sie das Modell urteilen ob die Antworten der Schüler richtig sind. falsch.
Schließlich erklärt das Modell den Schülern in leicht verständlicher Sprache die richtigen Lösungsideen. Dies schult nicht nur die Denkfähigkeit des Modells, sondern ermöglicht es den Schülern auch, selbst zu denken, ohne ihnen alle Antworten direkt mitzuteilen.

Fragen Sie das Modell, ob es im vorherigen Durchgang etwas übersehen hat
Angenommen, wir bitten das Modell, in einer großen Datei Sätze zu finden, die sich auf eine bestimmte Frage beziehen, und das Modell teilt uns jeweils einen Satz mit.
Aber manchmal macht das Modell eine Fehleinschätzung und hört auf, wenn es weiter nach verwandten Sätzen suchen sollte, was dazu führt, dass verwandte Sätze übersehen und uns später nicht erzählt werden.
Zu diesem Zeitpunkt können wir das Modell daran erinnern: „Gibt es noch andere verwandte Sätze?“ und dann weiterhin verwandte Sätze abfragen, damit das Modell umfassendere Informationen finden kann.
Nutzen Sie externe Tools
Effizienter Wissensabruf durch einbettungsbasierte Suche
Wenn wir der Eingabe des Modells einige externe Informationen hinzufügen, kann das Modell Fragen intelligenter beantworten. Wenn ein Benutzer beispielsweise eine Frage zu einem bestimmten Film stellt, können wir einige wichtige Informationen über den Film (z. B. Schauspieler, Regisseure usw.) in das Modell eingeben, damit das Modell intelligentere Antworten geben kann.
Texteinbettung ist ein Vektor, der die Beziehung zwischen Texten misst. Ähnliche oder verwandte Textvektoren sind näher, während nicht verwandte Textvektoren relativ weit entfernt sind, was bedeutet, dass wir Einbettungen für einen effizienten Wissensabruf nutzen können.
Konkret können wir den Textkorpus in Stücke schneiden und jeden Teil einbetten und speichern. Wir können dann eine bestimmte Abfrage einbetten und über die Vektorsuche den relevantesten eingebetteten Textblock im Korpus finden (d. h. den Textblock, der der Abfrage im Einbettungsraum am nächsten liegt).
Verwenden Sie die Codeausführung für genauere Berechnungen oder den Aufruf externer APIs
Sprachmodelle sind nicht immer in der Lage, komplexe mathematische Operationen oder Berechnungen, die viel Zeit in Anspruch nehmen, genau auszuführen. In diesem Fall können wir das Modell anweisen, Code zu schreiben, um die Aufgabe abzuschließen, anstatt es die Berechnungen selbst durchführen zu lassen.
Konkret können wir das Modell anweisen, den Code zu schreiben, der in einem bestimmten Format ausgeführt werden muss, indem wir ihn beispielsweise mit dreifachen Backticks umgeben. Wenn der Code Ergebnisse generiert, können wir diese extrahieren und ausführen.
Schließlich kann bei Bedarf die Ausgabe einer Codeausführungs-Engine (z. B. des Python-Interpreters) als Eingabe für die nächste Frage im Modell verwendet werden. Dadurch können Aufgaben, die Berechnungen erfordern, effizienter erledigt werden.

Ein weiteres großartiges Beispiel für die Codeausführung ist die Verwendung externer APIs (Application Programming Interfaces). Wenn wir dem Modell mitteilen, wie es eine API richtig verwenden soll, kann es Code schreiben, der diese API aufruft.
Wir können dem Modell einige Dokumentationen oder Codebeispiele zur Verfügung stellen, die die Verwendung der API zeigen, damit das Modell angeleitet werden kann, die Verwendung der API zu erlernen. Einfach ausgedrückt: Indem dem Modell einige Anleitungen zur API gegeben werden, kann es Code erstellen, um mehr Funktionen zu erreichen.

Warnung: Das Ausführen von von einem Modell generiertem Code ist von Natur aus unsicher und jede Anwendung, die dies versucht, sollte Vorsichtsmaßnahmen treffen. Insbesondere sind Sandbox-Codeausführungsumgebungen erforderlich, um den potenziellen Schaden zu begrenzen, den nicht vertrauenswürdiger Code verursachen kann.
Lassen Sie das Modell bestimmte Funktionen bereitstellen
Wir können ihm über eine API-Anfrage eine Liste übergeben, die die Funktionalität beschreibt. Auf diese Weise ist das Modell in der Lage, Funktionsparameter basierend auf dem bereitgestellten Muster zu generieren. Die generierten Funktionsparameter werden im JSON-Format zurückgegeben, das wir dann zur Durchführung des Funktionsaufrufs verwenden.
Anschließend kann eine Schleife implementiert werden, indem die Ausgabe des Funktionsaufrufs in der nächsten Anfrage an das Modell zurückgegeben wird. Dies ist die empfohlene Methode zum Aufrufen externer Funktionen mithilfe des OpenAI-Modells.
Testen Sie Änderungen systematisch
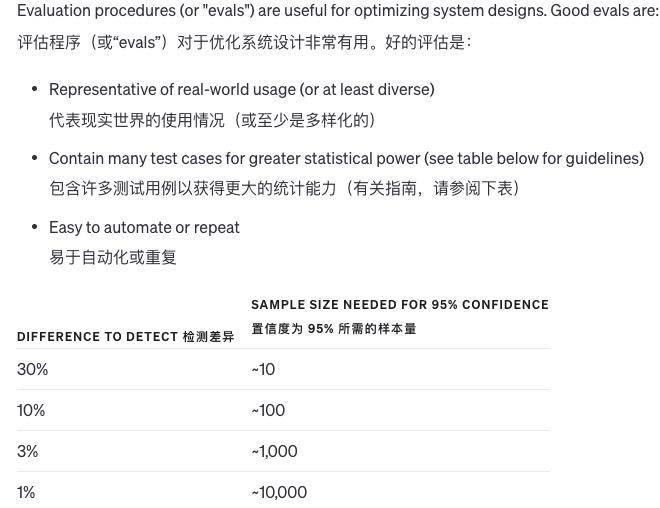
Wenn wir Änderungen an einem System vornehmen, ist es schwierig zu beurteilen, ob die Änderungen gut oder schlecht sind. Da es so wenige Beispiele gibt, ist es schwierig festzustellen, ob die Ergebnisse wirklich besser sind oder nur eine Frage des Glücks. Manchmal ist eine Änderung in manchen Situationen gut und in anderen schlecht.
Wie bewerten wir also die Qualität der Systemausgabe? Gibt es auf eine Frage nur eine Standardantwort, kann der Computer automatisch feststellen, ob diese richtig oder falsch ist. Gibt es keine einheitliche Antwort, können andere Modelle zur Qualitätsbeurteilung herangezogen werden.
Darüber hinaus können wir die subjektive Qualität auch von Menschen bewerten lassen oder die Bewertung durch Computer und Menschen kombinieren. Wenn die Antwort auf die Frage sehr lang ist und sich die Qualität der verschiedenen Antworten nicht stark unterscheidet, kann das Modell die Qualität selbst bewerten .
Mit zunehmender Weiterentwicklung des Modells können natürlich immer mehr Inhalte automatisch ausgewertet werden und es ist immer weniger manuelle Auswertung erforderlich. Es ist sehr schwierig, das Auswertungssystem zu verbessern, und die Kombination von Computern und künstlicher Intelligenz ist die beste Methode.
Bewerten Sie die Modellausgabe anhand von Goldstandard-Antworten
Angenommen, wir stehen vor einem Problem und brauchen eine Antwort. Wir kennen bereits die richtige Antwort auf diese Frage, basierend auf einigen Fakten. Die Frage lautet beispielsweise: „Warum ist der Himmel blau?“ Die richtige Antwort könnte lauten: „Denn wenn Sonnenlicht durch die Atmosphäre dringt, dringt das Licht im blauen Lichtband besser durch als andere Farben.“
Diese Antwort basiert auf den folgenden Fakten:
Sonnenlicht enthält verschiedene Farben (Lichtbänder)
Das blaue Lichtband hat beim Durchgang durch die Atmosphäre weniger Verluste
Nachdem wir die Frage und die richtige Antwort haben, können wir ein Modell (z. B. ein Modell für maschinelles Lernen) verwenden, um die Bedeutung jeder Tatsache bei der Antwort auf die richtige Antwort zu beurteilen.
Beispielsweise ermittelt das Modell, dass die Tatsache, dass „Sonnenlicht verschiedene Farben enthält“ in der Antwort für die Richtigkeit der Antwort sehr wichtig ist. Für die Antwort ist auch die Tatsache wichtig, dass „das blaue Lichtband weniger Verluste aufweist“. Auf diese Weise können wir wissen, von welchen wichtigen bekannten Fakten die Antwort auf diese Frage abhängt.

Im Prozess der Mensch-Maschine-Kommunikation mit ChatGPT scheinen Aufforderungswörter einfach zu sein, sind aber die kritischste Existenz. Im digitalen Zeitalter sind Aufforderungswörter der Ausgangspunkt für die Aufteilung von Anforderungen. Durch die Gestaltung cleverer Aufforderungswörter können wir das Ganze aufteilen Aufgabe. Unterteilt in eine Reihe prägnanter Schritte.
Eine solche Zerlegung hilft dem Modell nicht nur, die Absicht des Benutzers besser zu verstehen, sondern bietet dem Benutzer auch einen klareren Betriebspfad, genau wie ein Hinweis, der uns Schritt für Schritt anleitet, die Antwort auf das Problem aufzudecken.
Ihre und meine Bedürfnisse sind wie ein wogender Fluss, und das schnelle Wort ist wie eine Schleuse, die die Richtung des Flusses reguliert. Es fungiert als Drehscheibe und verbindet das Denken des Benutzers und das Verständnis der Maschine. Es ist keine Übertreibung zu sagen, dass ein gutes Aufforderungswort nicht nur einen Einblick in das tiefe Verständnis des Benutzers bietet, sondern auch ein stillschweigendes Verständnis der Mensch-Maschine-Kommunikation.
Wenn Sie die Fähigkeiten der Verwendung von Prompt-Wörtern wirklich beherrschen möchten, reicht es natürlich nicht aus, sich nur auf die Prompt-Technik zu verlassen, aber der offizielle Verwendungsleitfaden von OpenAI bietet uns immer wertvolle Einführungsleitfäden.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo