
Die inländische „kleine Stahlkanone“, die GPT-4V über Nacht umgeworfen hat, könnte für Huawei und Xiaomi die Schlüsselwaffe im Kampf gegen das KI-iPhone sein
Wie viele Schritte sind nötig, um ein großes Modell in ein Mobiltelefon zu integrieren?
Wenn 2023 das erste Jahr der Explosion der generativen KI ist, dann haben verschiedene Hersteller in diesem Jahr einen seltenen Konsens erzielt – sie setzen vollständig auf große End-Side-Modelle.
Als neues KI-Unternehmen, das sich auf „effiziente große Modelle“ spezialisiert hat, lässt Wallface Intelligence heute erneut seine Muskeln spielen, indem es das leistungsstärkste endseitige multimodale Open-Source-Modell MiniCPM-Llama3-V 2.5 auf den Markt bringt.
- Die stärkste endseitige multimodale Gesamtleistung: übertrifft die multimodalen Giganten Gemini Pro und GPT-4V
- OCR-Funktionen SOTA! 9-mal klarere Pixel, wodurch es schwierig ist, lange Bilder und langen Text genau zu erkennen
- Die Bildkodierung ist 150-mal schneller! Die erste endseitige multimodale Beschleunigung auf Systemebene

Die dritte Kugel der heimischen „kleinen Stahlkanone“ ist da und überwältigt die GPT-4V
So wie sich der Mensch bei der Erkundung der Welt auf seine fünf Sinne verlässt, sind multimodale Fähigkeiten eine notwendige Voraussetzung für die Entwicklung der KI.
Mit nur einem 8B-End-Side-Modell erzielte MiniCPM-Llama3-V 2.5, das „groß mit klein“ ist, auf der Bewertungsplattform OpenCompass nicht nur eine vergleichbare Note wie das Closed-Source-Modell Qwen-VL-Max Die Gesamtleistung übertrifft auch die Schwergewichte GPT-4V und Gemini Pro.
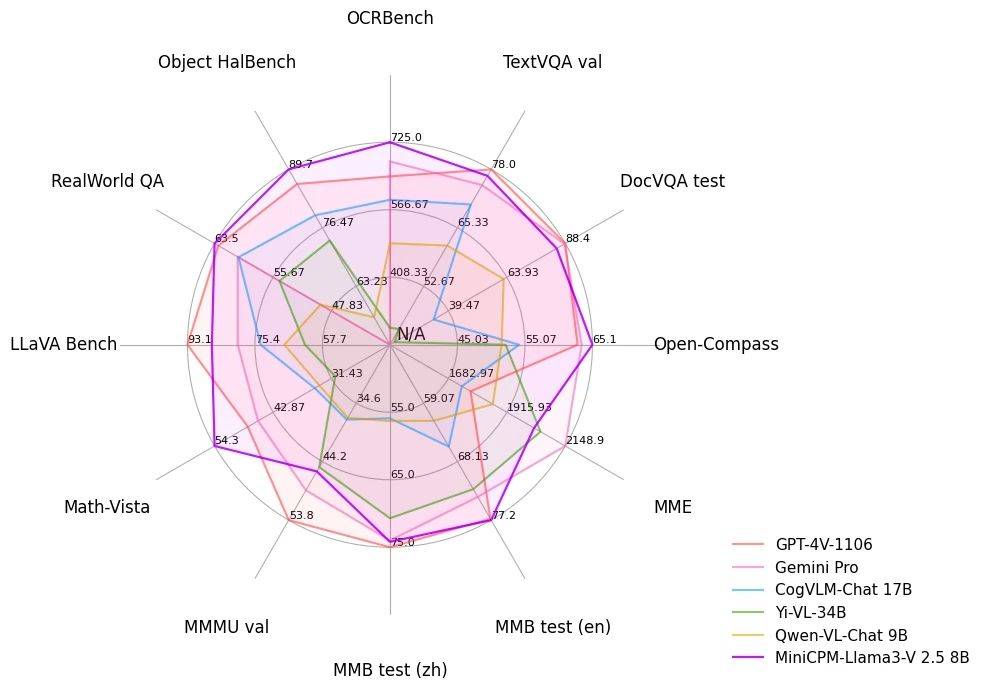
Im umfassenden Benchmark-Test der OCR (Optical Character Recognition) erreichte MiniCPM-Llama3-V 2.5 eine Punktzahl von 725 Punkten und übertraf damit GPT-4V bei weitem und übertraf Leapfrog-Modelle wie Claude 3V Opus.
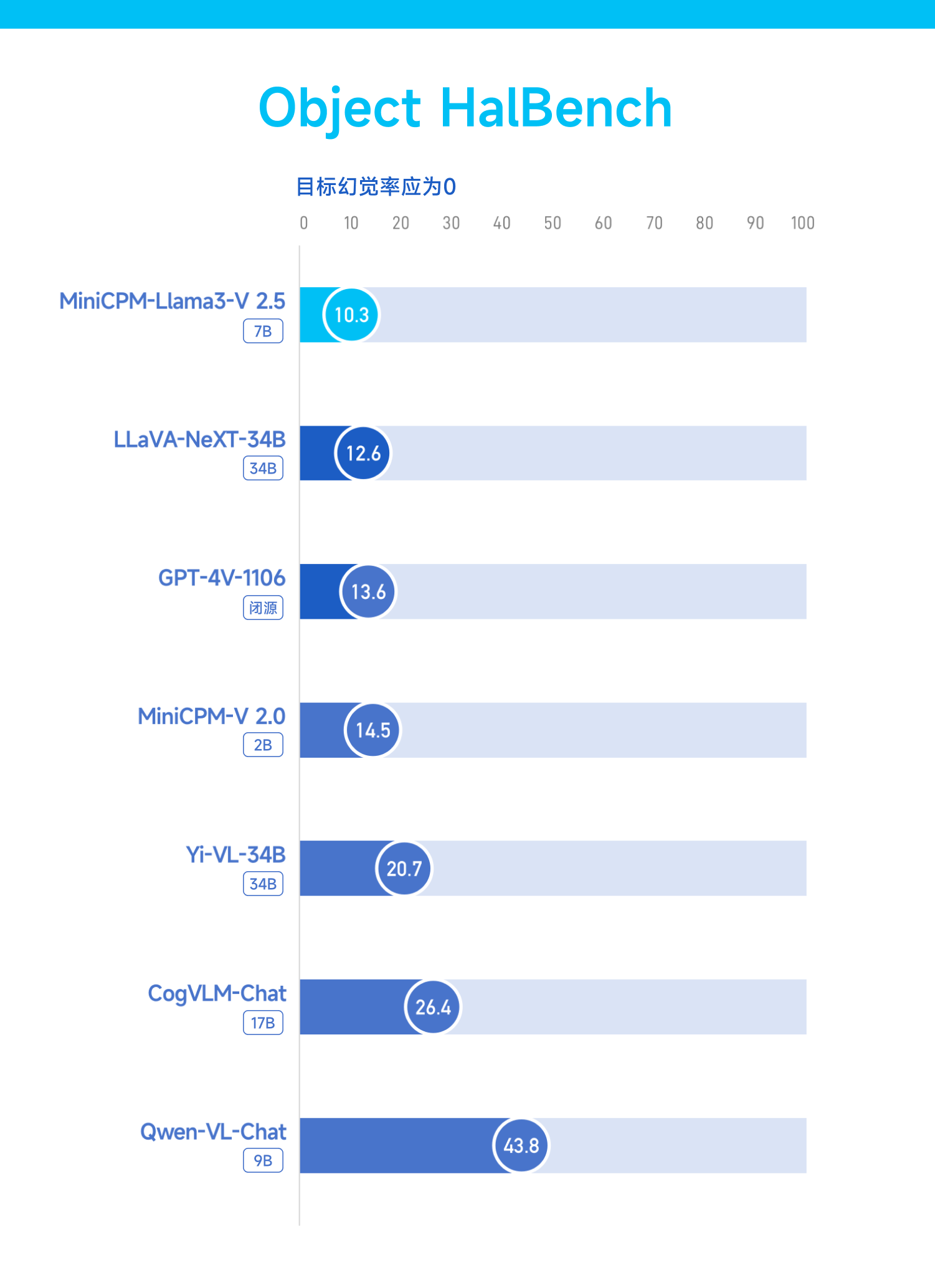
Die Fähigkeit zur Halluzination ist das größte hartnäckige Problem, das große Modelle in kurzer Zeit plagt. MiniCPM-Llama3-V 2.5 hat auch dieses Problem verbessert.
Im Object HalBench-Benchmark-Test zeigte sich, dass die Halluzinationsrate stark von 14,5 in MiniCPM-V 2.0 (2B) auf 10,3 sank und damit erneut GPT-4 V und LLaVA-NeXT-34B übertraf.
Der RealWorldQA-Benchmark ist ein Test des Realitätsverständnisses eines Modells.
MiniCPM-Llama3-V 2.5 lieferte einen Antwortbogen von 63,5 und lag damit nur hinter InternVL-Chat-V1.5 (26B) an zweiter Stelle, übertraf aber immer noch GPT-4V und Gemini Pro.
MiniCPM-Llama3-V 2.5 basiert auf der selbst entwickelten effizienten Kodierungstechnologie für hochauflösende Bilder und unterstützt die effiziente Kodierung und verlustfreie Erkennung von 1,8 Millionen hochauflösenden Pixelbildern sowie jedes Seitenverhältnis, sogar das extreme Bildverhältnis von 1:9 . Dafür ist es nur ein Kinderspiel.

„Sehen können“ ist nur der Anfang, wichtiger ist die Fähigkeit zu „denken“. MiniCPM-Llama3-V 2.5 hebt komplexe Denkfähigkeiten auf ein neues Niveau.

Beamte sagten, dass bei einem Beispiel eines künstlerischen Gebäudes, in das berühmte Zitate aus „Das Drei-Körper-Problem“ eingraviert sind, ein allgemeines großes Modell das Modell des Bildes nur grob beschreiben kann, MiniCPM-Llama3-V 2.5 es jedoch mit „The“ assoziieren kann „Drei-Körper-Problem“ basierend auf den erkannten Informationen. „Bücher.
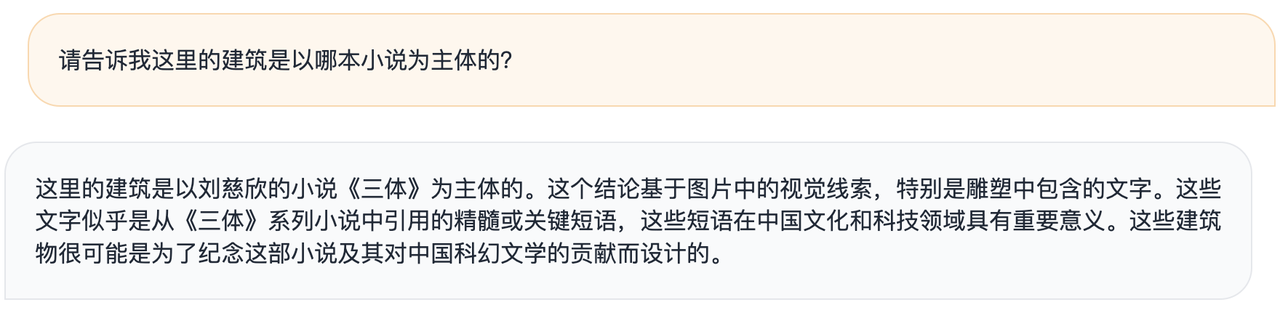
▲MiniCPM-Llama3-V 2.5

▲GPt-4V
Sie können auch Ihre eigenen Einblicke geben – diese Gebäude wurden wahrscheinlich zum Gedenken an den Roman und seinen Beitrag zur chinesischen Science-Fiction-Literatur entworfen.
Oder geben Sie ihm eine englische Version der asiatischen Diätpyramide, und er kann sofort zum persönlichen Ernährungsberater werden und Rezepte für die Woche anpassen.

Wenn Sie zu faul sind, lange Artikel zu lesen, überlassen Sie es MiniCPM-Llama3-V 2.5 und stellen Sie dann Fragen, es wird so schnell wie möglich Antworten geben.
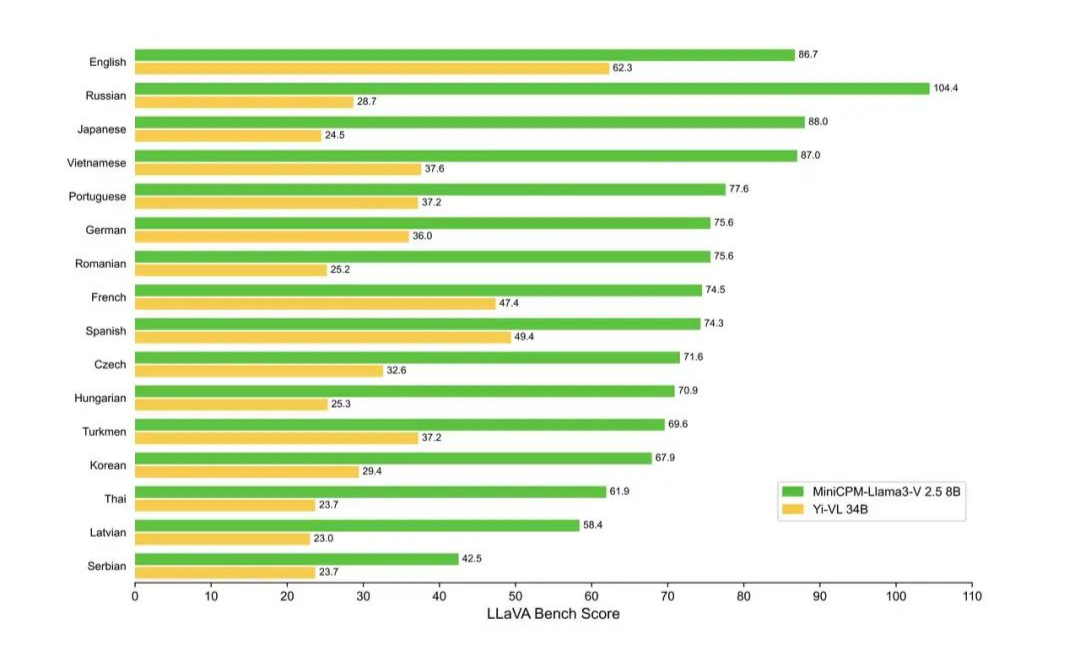
Jetzt unterstützt MiniCPM-Llama3-V 2.5 mehr als 30 Sprachen, darunter Deutsch, Französisch, Spanisch, Italienisch, Russisch und andere gängige Sprachen. Die Sprachen der Länder entlang der Seidenstraße stehen Ihnen grundsätzlich zur Verfügung.
Es ist zu beachten, dass es sich bei MiniCPM-Llama3-V 2.5 tatsächlich um ein fein abgestimmtes Modell handelt, das auf dem Open-Source-Modell Llama3-8B-Instruct basiert.
In der Vergangenheit war es ein großes Problem, KI verschiedene Informationen wie Bilder und Text gleichzeitig und mit hoher Geschwindigkeit verarbeiten zu lassen. Wall-Facing Intelligence verwendet jedoch ein NPU-Beschleunigungsframework, das speziell zur Beschleunigung entwickelt wurde Die Verarbeitung von Bildern soll dazu beitragen, dass die KI auf Mobiltelefonen effizienter arbeitet.
Laut der offiziellen Einführung kann die Wandverkleidung erstmals nur eine endseitige Systembeschleunigung durchführen. Derzeit wurde MiniCPM-Llama3-V 2.5 effizient auf Mobiltelefonen eingesetzt und hat eine 150-fache Beschleunigung bei der Bildkodierung erreicht.
Beispielsweise beträgt die Dekodierungsgeschwindigkeit des Sprachmodells Llama 3 auf dem Mobiltelefon etwa 0,5 Token/s, während das multimodale Modell MiniCPM-Llama3-V 2.5 die Sprachdekodierungsgeschwindigkeit auf dem Mobiltelefon durch mehrfache Optimierung auf 3 verbessert hat Methoden wie CPU. -4 Token/s.
Im Anhang finden Sie die Open-Source-Adresse von MiniCPM-Llama3-V 2.5:  https://github.com/OpenBMB/MiniCPM-V
https://github.com/OpenBMB/MiniCPM-V
Geräteseitiges Modell, ein Schlachtfeld für Mobiltelefonhersteller
In den letzten zwei Jahren tauchten geräteseitige Modelle häufig in Sprach-PPTs großer Terminalhersteller auf.
Bei den sogenannten End-Side-Modellen handelt es sich um jene Modelle der künstlichen Intelligenz, die auf Endgeräten laufen. Diese Modelle sind in der Regel so konzipiert, dass sie leicht genug sind, um der Rechenleistung und den Ressourcenbeschränkungen des Endgeräts gerecht zu werden.
Nachdem GPT-4 online ging, wies „AI Godfather“ Geoffrey Hinton einmal darauf hin, dass es meiner Meinung nach eine Phase geben wird, in der wir auf Computern mit großer Rechenleistung trainieren. Sobald das Modell trainiert ist, kann es auf Geräten mit geringem Stromverbrauch ausgeführt werden. .
Das Merkmal des End-Side-Modells besteht darin, dass es auf der Geräteseite (z. B. Smartphones, eingebettete Systeme usw.) ausgeführt werden kann, um Daten zu verarbeiten und Entscheidungen zu treffen, ohne die Daten an einen Remote-Server zu senden.
Wenn wir die obigen Wörter auseinandernehmen, können wir die Vorteile des Endseitenmodells entdecken:
- Lokale Ausführung: Das Modell wird lokal auf dem Gerät ausgeführt, ohne auf einen Remote-Server angewiesen zu sein.
- Echtzeitverarbeitung: Möglichkeit, Daten in Echtzeit auf dem Gerät zu verarbeiten und so eine schnelle Reaktion zu ermöglichen.
- Geringe Latenz: Da keine Daten zwischen Gerät und Server übertragen werden müssen, ist die Latenz geringer.
- Datenschutz: Daten werden lokal verarbeitet, wodurch das Risiko von Datenlecks verringert und der Datenschutz verbessert wird.
- Netzwerkunabhängigkeit: Das End-Side-Modell funktioniert auch ohne Netzwerkkonnektivität.
- Ressourcenoptimierung: Das endseitige Modell muss in der Regel optimiert werden, um es an die begrenzten Rechenressourcen und den begrenzten Speicherplatz des Endgeräts anzupassen.
- Anwendbar auf eine Vielzahl von Geräten: Das clientseitige Modell kann auf verschiedenen Arten von Endgeräten eingesetzt werden, einschließlich, aber nicht beschränkt auf Smartphones, Smart-Home-Geräte, tragbare Geräte usw.
- Miniaturisierung und Optimierung: Modelle müssen möglicherweise einer Komprimierung, Bereinigung, Quantisierung und anderen technischen Prozessen unterzogen werden, um die Modellgröße zu reduzieren und die Betriebseffizienz zu verbessern.
Natürlich sind das große Client-seitige Modell und das große Cloud-Modell synergetisch und nicht das Produkt von Gegensätzen.
Wir sehen also, dass die Entwicklung großer Modelle wie Llama 3 und Claude zwar in vollem Gange ist, die Forschung zu End-Side-Modellen jedoch nicht ins Hintertreffen geraten ist.
Der NVIDIA-Wissenschaftler JImFan wies darauf hin, dass es sich beim neuesten GPT-4o höchstwahrscheinlich um ein destilliertes kleines Modell handelt und die Vorteile offensichtlich sind – raffinierter und effizienter.
Ob es sich um den letzten Monat von Microsoft herausgebrachten Phi-3, die von Wallface Intelligence veröffentlichte leistungsstarke kleine Stahlkanonenserie oder die kürzlich von Apple als Open Source angekündigte OpenELM-Modellserie handelt, es werden ständig neue kleine Modelle auf den Markt gebracht.

2024 ist ein entscheidendes Jahr für die Implementierung von KI-Anwendungen, und auch geräteseitige Modelle gewinnen an Dynamik und bereiten sich darauf vor, in diesem Jahr zu glänzen.
Eine unbestreitbare Tatsache ist, dass die meisten aktuellen Terminalinnovationen eine Engpassphase erreicht haben. Nehmen wir als Beispiel Mobiltelefone, die an unserem Körper „wachsen“. Das Gefühl der Überraschung und Innovation, als Steve Jobs das iPhone herausholte, ist im langen Fluss der Zeit längst verloren gegangen.
Der Vorschlag einer KI-gesteuerten Terminalinnovation, unabhängig davon, ob es sich eher um eine Spielerei als um die Realität handelt oder um die Nutzung zukünftiger Technologien, um der Gegenwart „Geld zu gewähren“, kann die Fantasie von Geräten wie Mobiltelefonen tatsächlich weiter beflügeln und zu einem Schlüsselpunkt werden, den es zu brechen gilt das Spiel.

Aufgrund dieses Trends ist das geräteseitige Modell nicht mehr nur ein Konzept, das in theoretischen Diskussionen oder Herstellerbroschüren verbleibt, sondern beginnt allmählich in unser tägliches Leben einzudringen.
Auf der HamonyOS 4-Konferenz im August letzten Jahres kündigte Yu Chengdong die Fähigkeit des intelligenten Assistenten Xiaoyi an, auf große KI-Modelle zuzugreifen. Unmittelbar danach gab Lei Jun bekannt, dass Xiaomi auf seinem Mobiltelefon ein großes Modell mit 1,3B-Parametern durchlaufen hat und die Auswirkungen einiger Szenen mit denen in der Cloud vergleichbar sind.
Keines der inländischen „Yuwujia“-Handys wurde zurückgelassen. OPPO Xiaobu Assistant basierend auf AndersGPT, Honor Magic 6 mit 7B-Terminal-seitigem KI-Großmodell und vivo mit Blue Heart-Großmodellmatrix wurden ebenfalls nacheinander offiziell angekündigt.
In den frühen Morgenstunden verbreitete Bloomberg-Reporter Mark Gurman die Nachricht, dass Apple die Sprachfunktion von Siri verbessern wird, um sie gesprächiger zu machen, und Funktionen hinzufügen wird, die Benutzern bei der Bewältigung des täglichen Lebens helfen, darunter:
- iPhone-Benachrichtigungen automatisch zusammenfassen
- Fassen Sie Nachrichtenartikel zusammen
- Sprachnotizen transkribieren
- Verbessern Sie vorhandene Funktionen zum automatischen Ausfüllen von Kalendern und zum Empfehlen von Apps
- KI bearbeitet Fotos
Was den Kern-Sprachassistenten Siri betrifft, dürfte er in Zukunft eng mit dem geräteseitigen Modell von OpenAI oder Gemini verbunden sein.
Obwohl die beliebte KI-Hardware Rabbit R1 als Android-Shell in Frage gestellt wird, zeigte sie auf der Pressekonferenz auch ein Profil des Idealzustands eines KI-Telefons – ein System ohne Barrieren zwischen Anwendungen und reibungsloser Interaktion.

Diese Situation tritt jedoch nicht über Nacht ein. Wenn der KI-Sprachassistent Benutzer wirklich verstehen und Anwendungen wie erwartet planen kann, wird dies nicht nur das Benutzererlebnis vollständig beeinträchtigen, sondern voraussichtlich auch die Beziehung zwischen Mobiltelefonherstellern und Dritten verändern -Party-Anwendungsentwickler.
Beispielsweise gab es Nachrichten darüber, dass Apple, das immer verschlossen war, angesichts dieser Flut technologischer Veränderungen begonnen hat, sich aktiv für Offenheit einzusetzen.
Laut Ben Reitzes von Melius Research wird Apple voraussichtlich auf der kommenden WWDC einen Store für KI-Anwendungen eröffnen. Dies ist nicht nur ein wichtiger Wendepunkt in Apples offener Strategie, sondern auch ein klares Signal seiner strategischen Transformation im KI-Zeitalter.
Dies zeigt auch, dass Apple versucht, durch den Aufbau eines offenen KI-Ökosystems mehr Mehrwert für Entwickler und Benutzer zu schaffen und gleichzeitig einen breiteren Marktraum für sich zu gewinnen.
Näher an der Heimat haben endseitige Modelle wie MiniCPM-Llama3-V 2.5 ihre Stärke bewiesen – das Modell hat nicht nur „je größer die Parameter, desto besser die Leistung“, sondern kann auch die stärkste Leistung mit den kleinsten Parametern nutzen!
Gleichzeitig ist der Eintritt ins Leben nur der erste Schritt. Wenn die Reise der Daten auf Null verkürzt wird, ermöglicht das geräteseitige Modell, dass die KI einen Schritt schneller reagiert als das menschliche Denken, was bedeuten kann, dass der nächste Frühling der Endgeräte beginnt wirklich angekommen.
Bis dahin löst jede Interaktion zwischen Nutzer und Endprodukt ein unwillkürliches „Wow“-Geräusch aus.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo