
Diese neue Funktion ist das heimische Licht des KI-Videos und macht die Hände von Kartenzeichnern völlig frei

Nicht zufrieden, nachdem Sie „Squid Game“ gesehen haben? Machen Sie einfach Ihr eigenes Ende.


Sie möchten nicht auf den dritten Teil von „Dune“ warten? Machen Sie selbst eins.


In der Vergangenheit hätte es lange gedauert, diese Schauspieler davor zu bewahren, ihre Form zu verlieren und zusammenzubrechen. Jetzt müssen Sie nur noch einen Screenshot an die KI senden und können mit dem Erstellen von Filmen beginnen.
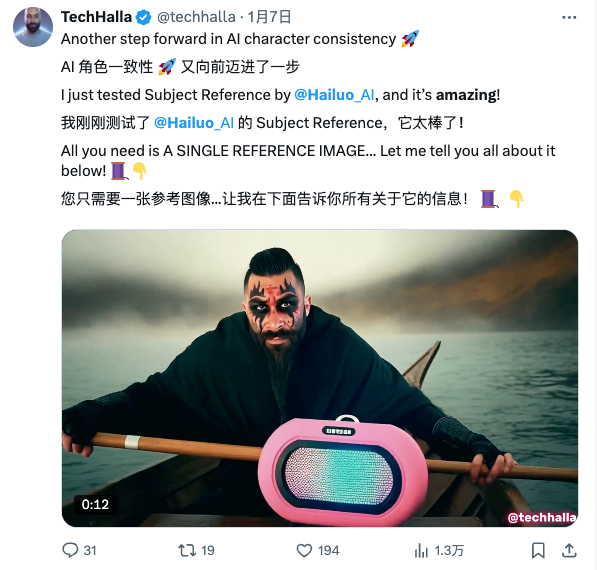
Dies ist die von Conch AI eingeführte „Subjektreferenz“-Funktion. Sie wird vom neuen S2V-01-Modell unterstützt und kann das Motiv im hochgeladenen Bild genau identifizieren und als Figur im generierten Video festlegen. Der Rest kann mit einfachen Anweisungen nach Belieben verwendet werden.

▲Erstellung durch X-Benutzer @KarolineGeorges, Gesichtsinformationen werden genau beibehalten

▲Erstellung vom X-Benutzer @Apple_Dog_Sol, mit mehreren Themen
Warum ist „Subject Reference“ so großartig?
Tatsächlich nutzen viele Hersteller die Funktion „Betreffreferenz“. Aber nicht jeder kann die mit dieser Funktion verbundenen Schwierigkeiten überwinden: Stabilität, Konsistenz und konsistente Bewegung.
Andere sind vielleicht nicht dazu in der Lage, aber Conch AI kann es. Mit nur einem Bild können Sie die Eigenschaften der Charaktere genau verstehen, sie als Motive identifizieren und die Charaktere dann in verschiedenen Szenen und Umgebungen erscheinen lassen.
Spider-Man, der gerade die Welt rettete, saß im nächsten Moment auf einem Motorrad.


Die Drachenmutter, die den Drachen in Game of Thrones trainieren sollte, neckte nun den kleinen Wolf.


Der bahnbrechende Fortschritt von „Main Reference“ besteht darin, die perfekte Balance zwischen kreativer Freiheit und Reduktion zu erreichen. Das ist, als würde man dem Schöpfer einen „Universalschauspieler“ geben. Das Aussehen des Schauspielers wird nicht zusammenbrechen, sondern er kann jede Aktion in jeder Szene entsprechend den Anforderungen des Regisseurs ausführen.
Nicht nur neue Features, sondern auch einzigartige technische Lösungen
Das Gefühl aus der tatsächlichen Messung ist: Die Hauptreferenz ist eine völlig andere Funktion, die sich von den von Vincent und Tusheng erzielten Effekten unterscheidet. Die dahinter stehenden technischen Schwierigkeiten sind unterschiedlich, und auch die Anforderungen an technische Ideen sind unterschiedlich.
Traditionelle Tusheng-Videos animieren nur statische Bilder und nehmen hauptsächlich lokale Änderungen vor. Nehmen Sie als Beispiel dieses Standbild von Song Hye Kyo. Tu Sheng hat gerade das ursprüngliche statische Bild in ein dynamisches Bild umgewandelt, und der Umfang ist begrenzt und es wird keine großen Bewegungen geben.

▲ Originalfotos

▲ Film basierend auf Tusheng-Video
Für dasselbe Foto kann die „Themenreferenz“ ein vollständiges Fragment basierend auf dem Text der Aufforderung bilden. Während die Bewegungen frei sind, werden die Gesichtszüge immer noch stabil realisiert.

▲ Aufforderung: Warme Innenbeleuchtung. Im Theatersaal trägt der Protagonist einen schwarzen Anzug und sitzt in der mittleren Reihe links. Ihr Gesichtsausdruck ist voller Konzentration, manchmal zeigt sie ein entspanntes Lächeln, klatscht in die Hände und ihre Bewegungen sind natürlich und rhythmisch. Die Kamera beginnt an der Seite der Protagonistin und fängt die Silhouetten anderer Zuschauer um sie herum sowie die matte Textur der Sitze ein und betont so das vielschichtige Gefühl der Umgebung. Während die Kamera weiterfährt, steht der Protagonist auf.
Derzeit gibt es zwei technische Möglichkeiten, Videos basierend auf Personen zu generieren. Eine davon basiert auf der LoRA-Technologie, um eine spezifische Feinabstimmung an vorab trainierten generativen Großmodellen durchzuführen. LoRA erfordert beim Generieren neuer Videos viele Berechnungen. Dies führt dazu, dass Benutzer Materialien zum gleichen Thema und aus unterschiedlichen Blickwinkeln hochladen und sogar genau angeben müssen, welche unterschiedlichen Elemente ein einzelner Clip enthalten muss, um die Qualität der Produktion sicherzustellen. Gleichzeitig ist ein hoher Token-Verbrauch und eine lange Wartezeit erforderlich.
Basierend auf umfangreichen technischen Untersuchungen entschied sich MiniMax für einen technischen Weg, der auf Bildreferenzen basiert: Bilder enthalten die genauesten visuellen Informationen, beginnend mit Bildern und im Einklang mit der kreativen Logik physischer Aufnahmen. Auf diesem technischen Weg hat das Modell für die Identifizierung des Protagonisten des Bildes unter allen visuellen Informationen oberste Priorität – ganz gleich, welches Bild als nächstes erscheint oder was die Handlung ist, das Motiv muss konsistent bleiben.
Andere visuelle Informationen sind offener und werden durch Textaufforderungen gesteuert. Auf diese Weise kann das Generationsziel „genaue Wiederherstellung + hoher Freiheitsgrad“ erreicht werden.


▲Auf der Lichtung des Tals steht der Protagonist vor dem riesigen Drachen, dessen langes Haar im Wind flattert. Die Kamera zoomt nach und nach heran, um die Bewegung der Protagonistin einzufangen, die sich umdreht und in die Ferne blickt. Die Flügel des Drachens breiten sich aus und wehen durch die Haare und den Rock der Protagonistin. Das Bild endet mit einer Aufnahme von oben.
In diesem Video wurde dem Model nur ein Bild der Drachenmutter zugesandt. Im Abschlussvideo präsentierte das Modell die Linsensprache und Bildelemente, die an der Aufforderung beteiligt sind, genau und demonstrierte so seine ausgeprägte Verständnisfähigkeit.
Im Vergleich zur LoRA-Lösung kann der technische Weg der Bildreferenz die von Benutzern hochgeladenen Materialien sichtbar reduzieren und Dutzende Videos in ein Bild verwandeln. Gleichzeitig wird die Wartezeit in Sekunden berechnet, was sich nicht wesentlich von der Zeit unterscheidet, die zum Generieren von Text und Bildern benötigt wird – es bietet die Genauigkeit von Tusheng-Videos und die Freiheit von Vincent-Videos.
Heimlicht kann „sowohl Ihre Wünsche als auch Ihre Bedürfnisse“ befriedigen.
„Beides zu haben“ ist keine überzogene Forderung. Nur wenn gleichzeitig eine genaue Konsistenz und freie Bewegung der Charaktere erreicht werden, kann das Modell über den Rahmen des Lebens und des Anfertigens von Skizzen hinausgehen und in Industrieanwendungsszenarien einen größeren Nutzen haben.
Beispielsweise können in der Produktwerbung aus einem Modellbild direkt Videos für mehrere Produkte generiert werden, und zwar durch einfaches Ändern der Eingabeaufforderung.


Wenn es mit Tusheng Video implementiert wird, besteht die aktuelle Mainstream-Lösung darin, das erste und das letzte Bild festzulegen, und die erzielbaren Effekte sind auch durch die vorhandenen Bilder begrenzt. Gleichzeitig müssen Sie wiederholt Karten ziehen, verschiedene Winkel sammeln und schließlich die Materialien zusammenfügen, um eine Reihe von Totalen zu vervollständigen.
Durch die Kombination der Eigenschaften verschiedener Technologien entspricht es besser dem Workflow der Videoerstellung, was den Vorteil von „Subject Reference“ darstellt. In Zukunft werden mehr als 80 % der Marketingfachleute generative Tools in verschiedenen Bereichen einsetzen. Sie müssen sich nur auf die Konzeption der Geschichte und Handlung konzentrieren und haben die Hände für das Zeichnen von Karten frei.
Statistiken von Statista zeigen, dass die Marktgröße generativer KI-Produkte im Werbemarketing im Jahr 2021 15 Milliarden US-Dollar überschreiten wird. Bis 2028 wird diese Zahl 107,5 Milliarden US-Dollar erreichen. Im vorherigen Workflow waren reine Vincent-Videos zu unkontrollierbar und eigneten sich daher für den Einsatz in den frühen Phasen der Erstellung. Generative KI ist in der Werbe- und Marketingbranche in Europa und den Vereinigten Staaten weit verbreitet, wobei 52 % ihrer Anwendungsfälle in der ersten Konzeption und Planung liegen und 48 % im Brainstorming eingesetzt werden.
Derzeit eröffnet Conch AI zunächst die Referenzfähigkeit für einen einzelnen Charakter. In Zukunft wird es um umfassendere Referenzfähigkeiten für mehrere Personen, Objekte, Szenen usw. erweitert, um der Kreativität noch mehr freien Lauf zu lassen. „Jeder hat die Idee, ein Blockbuster-Film zu werden.“
Seit der Veröffentlichung des Videomodells von MiniMax im August letzten Jahres hat es in Bezug auf Bildqualität und -flüssigkeit, Konsistenz und Stabilität weiterhin die Aufmerksamkeit und Erfahrung einer großen Anzahl von Benutzern im Ausland auf sich gezogen, darunter auch viele Praktiker mit Erfahrung in der Bilderstellung viel positives Feedback und berufliche Anerkennung.
Im technologischen Wettbewerb des letzten Jahres hat sich zunächst die Wettbewerbslandschaft im Bereich der KI-Videogenerierung herausgebildet. Die Implementierung von Sora ließ die Menschen das Potenzial im Bereich der Videoerzeugung erkennen. Anschließend investierten große Technologieunternehmen Ressourcen in diesen Bereich und investierten stark in Forschung und Entwicklung.
Aufgrund der Verzögerung bei der Produkteinführung von Sora am Ende des Jahres und des mittelmäßigen Rufs der Benutzertests konnte das Unternehmen die Markterwartungen nicht erfüllen. Dies gibt auch anderen Akteuren die Möglichkeit, den Markt zu erobern.
Heute, da generatives Video in die zweite Hälfte geht, gibt es nur drei Unternehmen, die ihre technische Stärke und ihr Entwicklungspotenzial wirklich unter Beweis gestellt haben: Conch AI von MiniMax, Keling AI von Kuaishous und Jimeng AI von ByteDe.
Als neu gegründetes Start-up-Unternehmen, das erst vor drei Jahren gegründet wurde, bringt MiniMax mit seinem kompetenten Start-up-Gremium Produkte und Technologien ein, die in der Lage sind, das T0-Niveau zu erreichen. Vom Tusheng-Videomodell I2V-01-Live im Dezember letzten Jahres bis zum aktuellen neuen Modell S2V-01 lösen sie alle die heiklen Probleme der Videogenerierung in der Vergangenheit.
Da die Technologie immer ausgereifter wird und sich die Anwendungsszenarien allmählich erweitern, wird die KI zur Videogenerierung eine neue Runde der Revolution in der Inhaltserstellung, Film- und Fernsehproduktion, Marketingkommunikation und anderen Bereichen einleiten. Diese Hersteller, die das höchste Niveau in Chinas KI-Bereich für die Videoerzeugung repräsentieren, sind nicht nur weiterhin führend auf dem Inlandsmarkt, sondern werden voraussichtlich auch auf globaler Ebene mit internationalen Giganten konkurrieren. Gleichzeitig wird die Gewährleistung der Produktstabilität und Kontrollierbarkeit bei gleichzeitiger Aufrechterhaltung der technologischen Innovation eine ständige Herausforderung für diese Unternehmen sein.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo