
Erfahren Sie in einem Artikel mehr über das neue Open-Source-FlashMLA von DeepSeek. Diese Details sind erwähnenswert.

Ab heute starten wir offiziell in die DeepSeek Open Source Week.
Die erste Version des Open-Source-Projekts von DeepSeek, FlashMLA, wurde innerhalb kürzester Zeit im gesamten Netzwerk verbreitet. In nur wenigen Stunden hat das Projekt mehr als 3,5.000 Sterne gewonnen und ist immer noch auf dem Vormarsch.
Obwohl ich jeden Buchstaben in FlashMLA kenne, kann ich sie nicht zusammen verstehen. Keine Sorge, wir haben eine Anleitung zum Speedrunning von FlashMLA zusammengestellt.
▲
Organisiert von Grok 3, überprüft von APPSO
Lassen Sie die Leistung des H800 dramatisch steigen. Was ist der Ursprung von FlashMLA?
Laut der offiziellen Einführung handelt es sich bei FlashMLA um einen effizienten MLA-Dekodierungskern (Multi-Head Latent Attention), der für die Hopper-GPU optimiert ist, die Sequenzverarbeitung variabler Länge unterstützt und nun in Produktion genommen wurde.
FlashMLA kann die Effizienz der LLM-Inferenz (Large Language Model) verbessern, indem es die MLA-Dekodierung und den Paging-KV-Cache optimiert, insbesondere auf High-End-GPUs wie H100/H800, um ultimative Leistung zu erzielen.
In menschlicher Hinsicht handelt es sich bei FlashMLA um eine fortschrittliche Technologie, die speziell für die Hochleistungs-KI-Chips von Hopper entwickelt wurde – ein „mehrschichtiger Aufmerksamkeitsdekodierungskern“.
Es klingt kompliziert, aber vereinfacht gesagt ist es wie ein supereffizienter „Übersetzer“, der es Computern ermöglicht, Sprachinformationen schneller zu verarbeiten. Es ermöglicht Computern, Sprachinformationen unterschiedlicher Länge sehr schnell zu verarbeiten.
Wenn Sie beispielsweise einen Chatbot verwenden, können Sie so schneller und ohne Verzögerung auf Ihre Gespräche reagieren. Um die Effizienz zu verbessern, werden hauptsächlich einige komplexe Berechnungsprozesse optimiert. Es ist, als würde man das „Gehirn“ des Computers verbessern, um ihn intelligenter und effizienter bei der Verarbeitung von Sprachaufgaben zu machen.
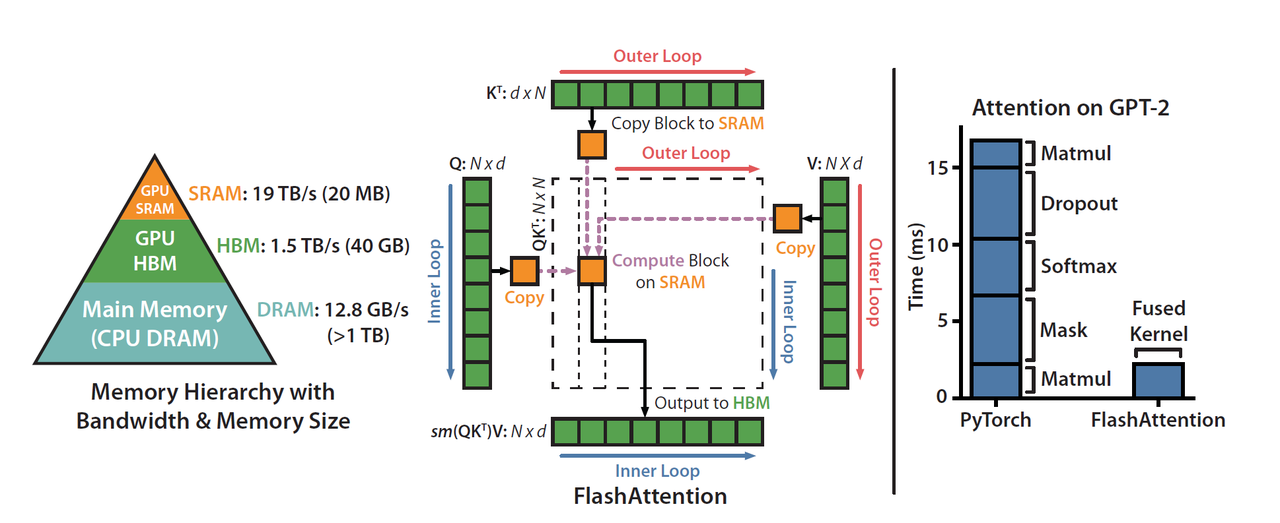
DeepSeek erwähnte offiziell, dass FlashMLA von FlashAttention 2&3 und Cutlass-Projekten inspiriert ist.
FlashAttention ist eine effiziente Aufmerksamkeitsberechnungsmethode, die speziell für den Selbstaufmerksamkeitsmechanismus von Transformer-Modellen (wie GPT und BERT) optimiert ist. Sein Hauptziel besteht darin, die Videospeichernutzung zu reduzieren und Berechnungen zu beschleunigen. Cutlass ist auch ein Optimierungstool, das hauptsächlich zur Verbesserung der Recheneffizienz beiträgt.
Die Beliebtheit von DeepSeek ist größtenteils auf die Entwicklung leistungsstarker Modelle zu geringen Kosten zurückzuführen.
Das Geheimnis dahinter liegt hauptsächlich in der Innovation in der Modellarchitektur und Trainingstechnologie, insbesondere in der Anwendung gemischter Experten (MoE) und der Multi-Head Latent Attention (MLA)-Technologie.
Aufbau von KI-Lösungen mit DeepSeek: Ein praktischer Workshop – Association of Data Scientists
FlashMLA ist eine Implementierungs- und Optimierungsversion der von DeepSeek entwickelten Multi-Head Latent Attention (MLA)-Technologie. Die Frage ist also: Was ist der MLA-Mechanismus (Multiple Latent Attention)?
In traditionellen Sprachmodellen gibt es eine Technologie namens „Multi-Head Attention (MHA)“. Es ermöglicht Computern, Sprache besser zu verstehen, ähnlich wie ein menschliches Auge sich auf mehrere Orte gleichzeitig konzentrieren kann.
Diese Technologie hat jedoch einen Nachteil: Sie erfordert viel Speicher zum Speichern von Informationen, was einem „Lager“ ähnelt, das geladen werden kann. Wenn das Lager jedoch zu groß ist, wird Platz verschwendet.
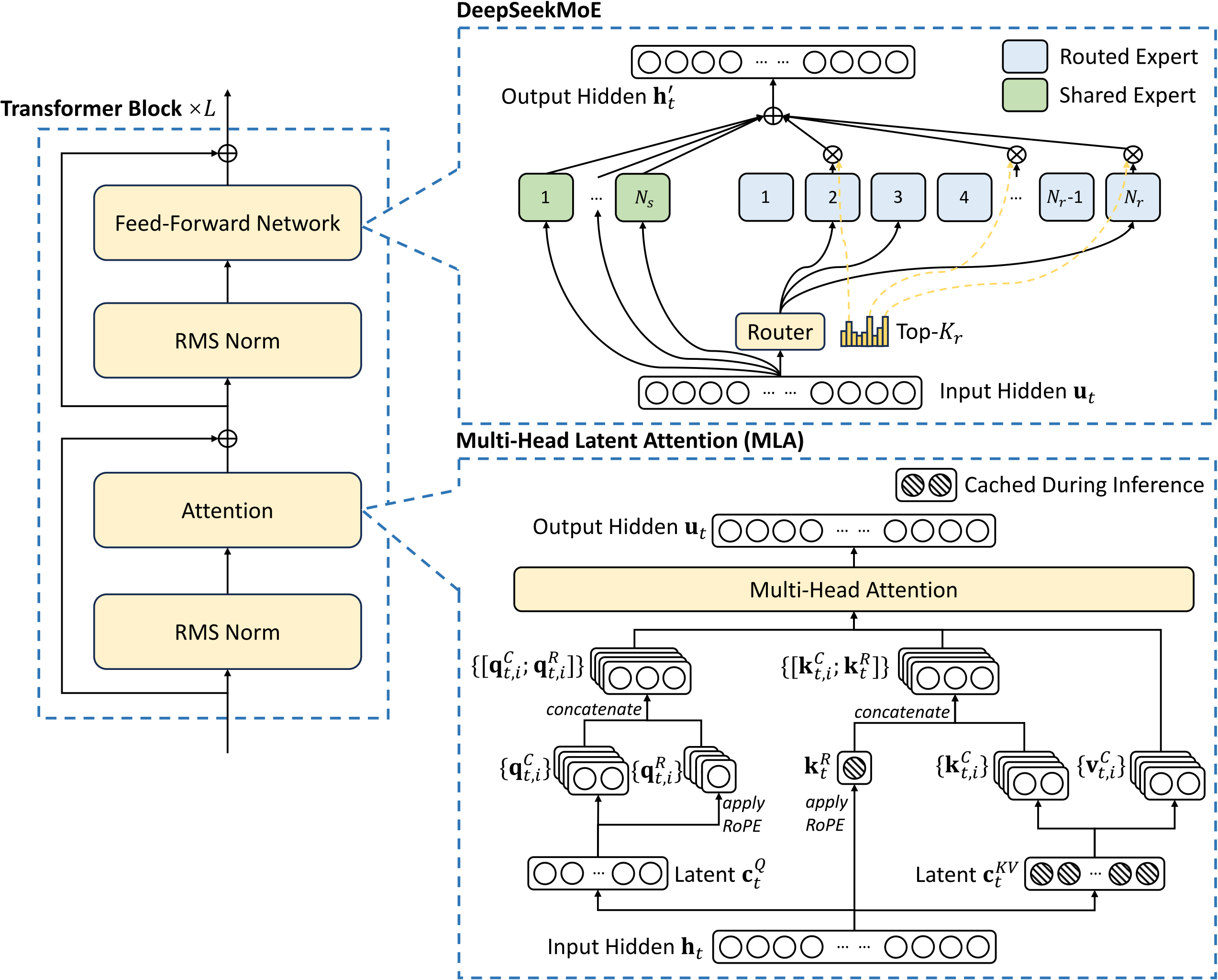
Die Aufwertung von MLA erfolgt in einer Methode namens „Low-Rank-Zerlegung“.
Es komprimiert dieses große Lagerhaus in ein kleines Lagerhaus, aber die Funktion ist immer noch genauso gut, genau wie das Ersetzen eines großen Kühlschranks durch einen kleinen Kühlschrank, aber die Dinge darin können immer noch aufbewahrt werden. Auf diese Weise,
Bei der Bearbeitung von Sprachaufgaben spart es nicht nur Platz, sondern macht es auch schneller.
Obwohl MLA das Lager komprimiert hat, ist seine Arbeitswirkung ohne Kompromisse immer noch so gut wie zuvor.
Neben MLA und MoE nutzt DeepSeek natürlich auch einige andere Technologien, um die Trainings- und Inferenzkosten erheblich zu senken, darunter unter anderem Training mit geringer Präzision, Lastausgleichsstrategien ohne Hilfsverluste und Multi-Token-Vorhersage (MTP).
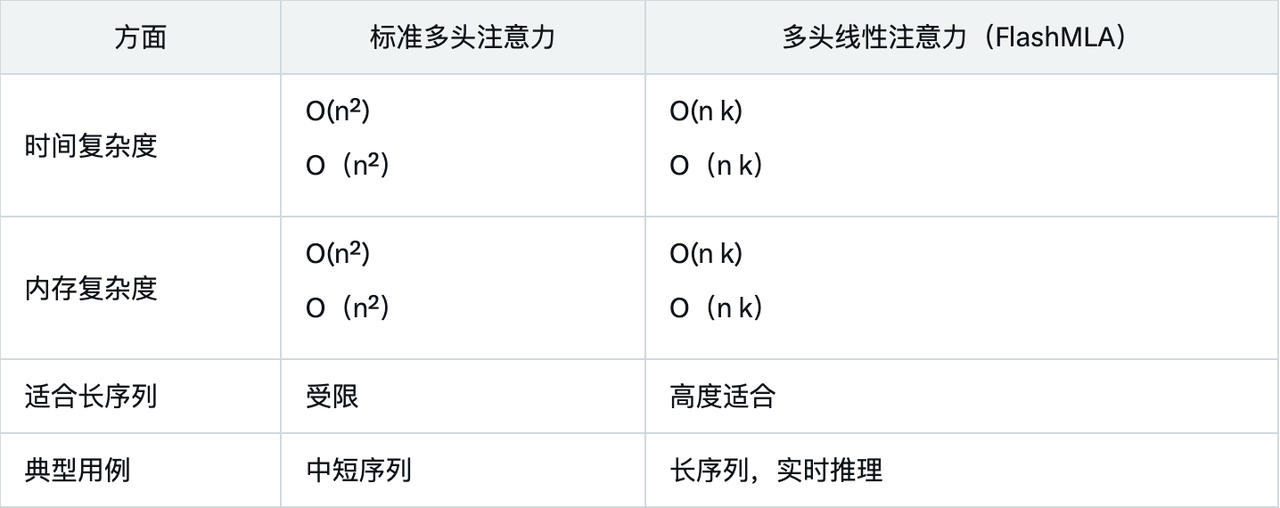
Leistungsdaten zeigen, dass FlashMLA dank seines linearen Komplexitätsdesigns und der Optimierung für Hopper-GPUs herkömmliche Methoden bei Speicher- und Rechenbeschränkungen bei weitem übertrifft.
Der Vergleich mit der Standard-Mehrkopfaufmerksamkeit verdeutlicht die Vorteile von FlashMLA zusätzlich:
Zu den Hauptanwendungsszenarien von FlashMLA gehören:
- Verarbeitung langer Sequenzen: Geeignet für die Verarbeitung von Texten mit Tausenden von Tags, z. B. für die Dokumentenanalyse oder lange Gespräche.
- Echtzeitanwendungen: wie Chatbots, virtuelle Assistenten und Echtzeit-Übersetzungssysteme zur Reduzierung der Latenz.
- Ressourceneffizienz: Reduziert Speicher- und Rechenanforderungen für eine einfache Bereitstellung auf Edge-Geräten.
Derzeit basiert das KI-Training oder Denken hauptsächlich auf NVIDIA H100/H800, aber das Software-Ökosystem verbessert sich immer noch.
Da FlashMLA Open Source ist, kann es in Zukunft in das Ökosystem vLLM (effizientes LLM-Inferenz-Framework), Hugging Face Transformers oder Llama.cpp (leichte LLM-Inferenz) integriert werden, wodurch große Open-Source-Sprachmodelle (wie LLaMA, Mistral, Falcon) voraussichtlich effizienter laufen.
Die gleichen Ressourcen können mehr Arbeit leisten und Geld sparen.
Da FlashMLA über eine höhere Recheneffizienz (580 TFLOPS) und eine bessere Optimierung der Speicherbandbreite (3000 GB/s) verfügt, können dieselben GPU-Ressourcen mehr Anforderungen verarbeiten, wodurch die Inferenzkosten pro Einheit gesenkt werden.
Für KI-Unternehmen oder Cloud-Computing-Dienstleister bedeutet die Verwendung von FlashMLA niedrigere Kosten und schnellere Schlussfolgerungen, was direkt mehr KI-Unternehmen, akademischen Einrichtungen und Unternehmensbenutzern zugute kommt und die Nutzung von GPU-Ressourcen verbessert.
Darüber hinaus können Forscher und Entwickler auch weitere Optimierungen auf Basis von FlashMLA vornehmen.
In der Vergangenheit befanden sich diese effizienten KI-Inferenzoptimierungstechnologien normalerweise in den Händen von Giganten wie OpenAI und NVIDIA. Mit der offenen Quelle von FlashMLA können sie jetzt auch von kleinen KI-Unternehmen oder unabhängigen Entwicklern genutzt werden, um Unternehmen zu gründen, was natürlich zu mehr KI-Unternehmerprojekten führen wird.
Kurz gesagt: Wenn Sie ein KI-Praktiker oder -Entwickler sind und kürzlich H100/H800 zum Trainieren oder Ableiten von LLM verwendet haben, dann ist FlashMLA möglicherweise ein Projekt, das Aufmerksamkeit oder Forschung verdient.
Ähnlich wie Internetnutzer im DeepSeek V3-Papier während des Frühlingsfestes Einzelheiten zu PTX entdeckten, entdeckten X-Internetnutzer, dass das von DeepSeek veröffentlichte FlashMLA-Projekt auch eine Zeile Inline-PTX-Code enthielt.
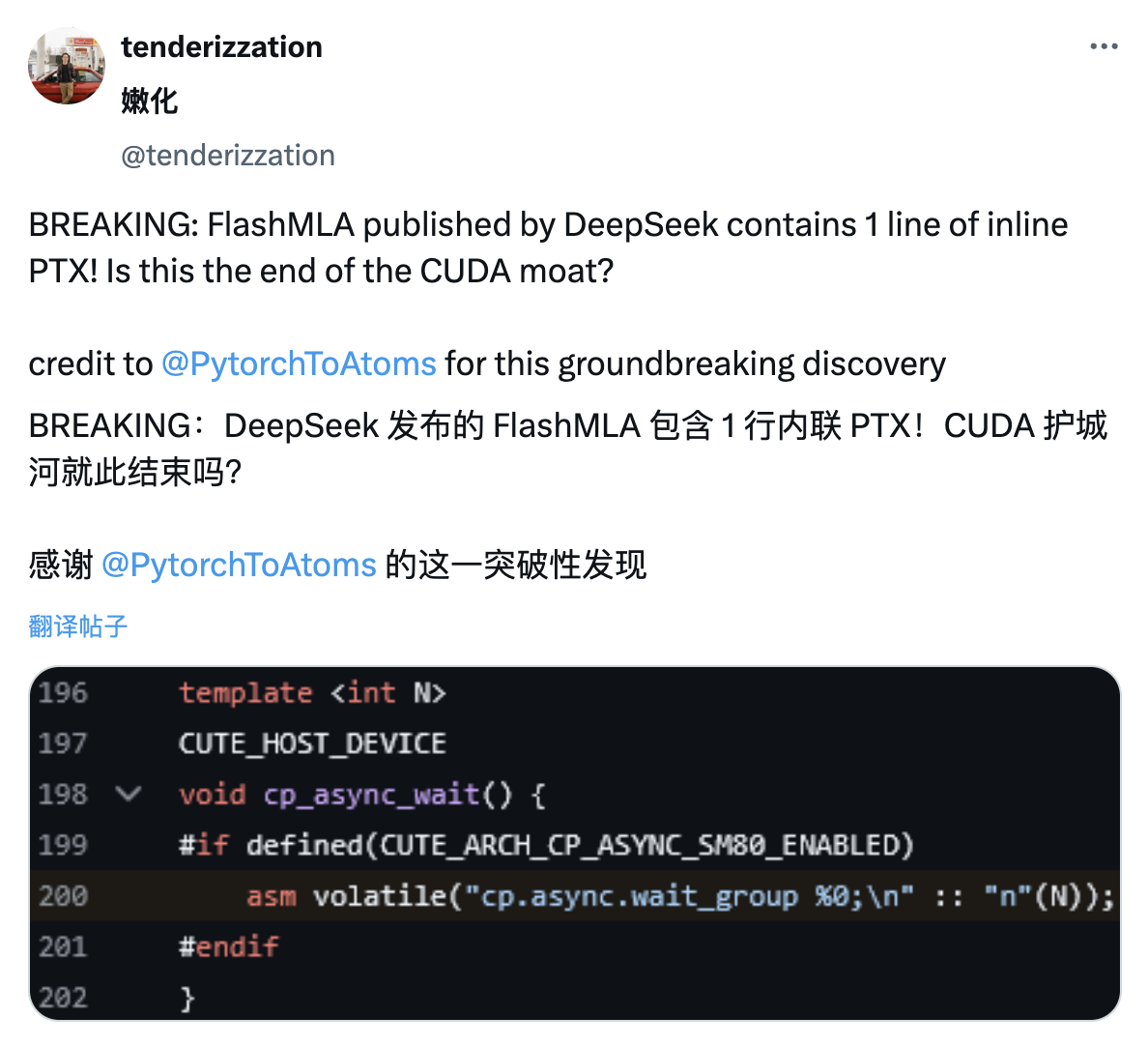
PTX ist die Zwischenbefehlssatzarchitektur der CUDA-Plattform, die zwischen High-Level-GPU-Programmiersprachen und Low-Level-Maschinencode angesiedelt ist. Sie wird oft als einer der technischen Gräben von NVIDIA angesehen.
Durch die Inline-Einbindung von PTX können Entwickler den Ausführungsprozess der GPU genauer steuern und so möglicherweise eine effizientere Rechenleistung erzielen.
Darüber hinaus wird die direkte Nutzung der zugrunde liegenden Funktionen von NVIDIA-GPUs, ohne sich vollständig auf CUDA verlassen zu müssen, auch dazu beitragen, den technischen Barrierenvorteil von NVIDIA im Bereich der GPU-Programmierung zu verringern.
Mit anderen Worten: Dies kann auch bedeuten, dass DeepSeek möglicherweise absichtlich das geschlossene Ökosystem von Nvidia umgeht.
Wenn nichts Unerwartetes passiert, werden laut ausländischen Medienberichten natürlich nächste Woche Modelle wie GPT-4.5 und Claude 4 veröffentlicht. Der KI-Krieg, der Ende letzten Jahres nicht zu sehen war, könnte diese Woche stattfinden.
Es ist keine allzu große Sache, dem Spaß zuzuschauen, einen Kampf zu beginnen, einen Kampf zu beginnen.
Offizieller Bereitstellungsleitfaden
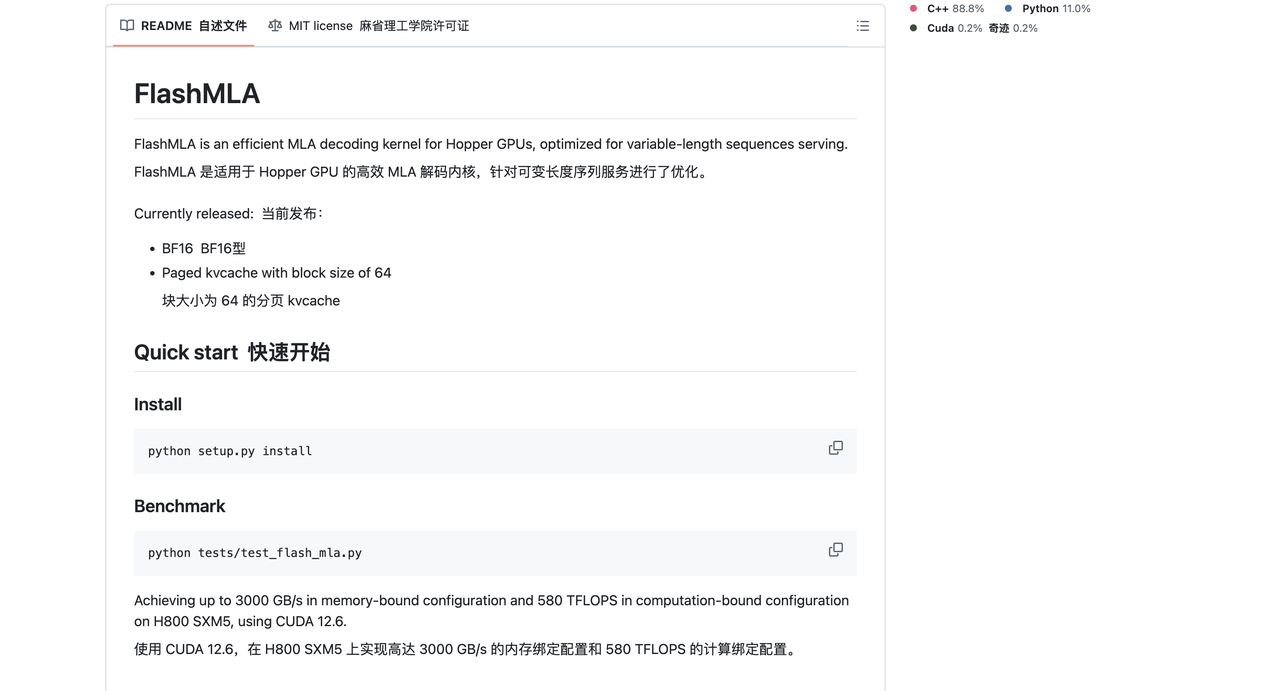
FlashMLA ist ein effizienter MLA-Dekodierungskern, der für Hopper-GPUs optimiert ist und zur Verarbeitung von Sequenzinferenzen variabler Länge verwendet werden kann.
Die aktuell veröffentlichte Version unterstützt:
- BF16
- Ausgelagerter KV-Cache, Blockgröße 64
Mit CUDA 12.6 auf H800 SXM5 kann FlashMLA 3000 GB/s in einer durch die Speicherbandbreite begrenzten Konfiguration und bis zu 580 TFLOPS in einer durch die Rechenleistung begrenzten Konfiguration erreichen.
Projektausrüstung:
- Hopper-GPU
- CUDA 12.3 und höher
- PyTorch 2.0 und höher
Im Anhang finden Sie die GitHub-Projektadresse:
https://github.com/deepseek-ai/FlashMLA
Installieren
Python setup.py installieren
Maßstab
Python-Tests/test_flash_mla.py
python tests/test_flash_mla.py ist eine Befehlszeilenanweisung zum Ausführen der Python-Testdatei test_flash_mla.py, die normalerweise zum Testen von flash_mla-bezogenen Funktionen oder Modulen verwendet wird.
aus flash_mla import get_mla_metadata, flash_mla_with_kvcache
Tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
für i in range(num_layers):
…
o_i, lse_i = flash_mla_with_kvcache(
q_i, kvcache_i, block_table, cache_seqlens, dv,
Tile_scheduler_metadata, num_splits, causal=True,
)
…
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo