
Das leistungsstärkste Open-Source-Großmodell explodiert spät in der Nacht! Llama 3 Return of the King, fast so gut wie GPT-4, gefällt Musk Angehängter Erfahrungslink
Ohne allzu große Überraschungen hat Meta mit der Modellreihe Llama 3, die als „die leistungsstärksten Open-Source-Großmodelle der Geschichte“ gilt, „die Straßen in die Luft gesprengt“.
Konkret hat Meta zwei Modelle unterschiedlicher Größe als Open-Source-Lösung bereitgestellt: 8B und 70B.
- Llama 3 8B: Im Grunde so leistungsstark wie das größte Llama 2 70B.
- Llama 3 70B: Das KI-Modell der ersten Stufe, vergleichbar mit Gemini 1.5 Pro, übertrifft Claude Big Cup in allen Aspekten
Das Obige sind nur Vorgeschmack auf Meta, die eigentliche Mahlzeit steht noch bevor. In den nächsten Monaten wird Meta sukzessive eine Reihe neuer Modelle mit multimodalem, mehrsprachigem Dialog, längeren Kontextfenstern und anderen Fähigkeiten auf den Markt bringen. Darunter wird der Schwergewichtsspieler mit über 400B voraussichtlich mit Claude 3 Super Cup konkurrieren . .
Adresse des Lama-3-Erlebnisses: https://llama.meta.com/llama3/

Ein weiteres GPT-4-Level-Modell ist da, Llama 3 ist geöffnet
Im Vergleich zum Vorgängermodell Llama 2 kann man sagen, dass Llama 3 ein neues Niveau erreicht hat.
Dank der Verbesserungen im Pre-Training und Post-Training sind die dieses Mal veröffentlichten Pre-Training- und Instruktions-Feinabstimmungsmodelle die leistungsstärksten Modelle in den 8B- und 70B-Parameterskalen. Gleichzeitig wurde die Post optimiert -Trainingsprozess hat die Fehlerrate des Modells erheblich reduziert, die Konsistenz des Modells verbessert und die Vielfalt der Antworten bereichert.
Zuckerberg verriet einmal in einer öffentlichen Rede, dass die Optimierung von Llama 2 in diesem Bereich nicht herausragend sei, wenn man bedenke, dass Benutzer in WhatsApp keine Fragen zur Meta-KI-Codierung stellen würden.
Dieses Mal hat Llama 3 bahnbrechende Verbesserungen in den Bereichen Argumentation, Codegenerierung und Befolgen von Anweisungen erzielt, wodurch es flexibler und benutzerfreundlicher wird.
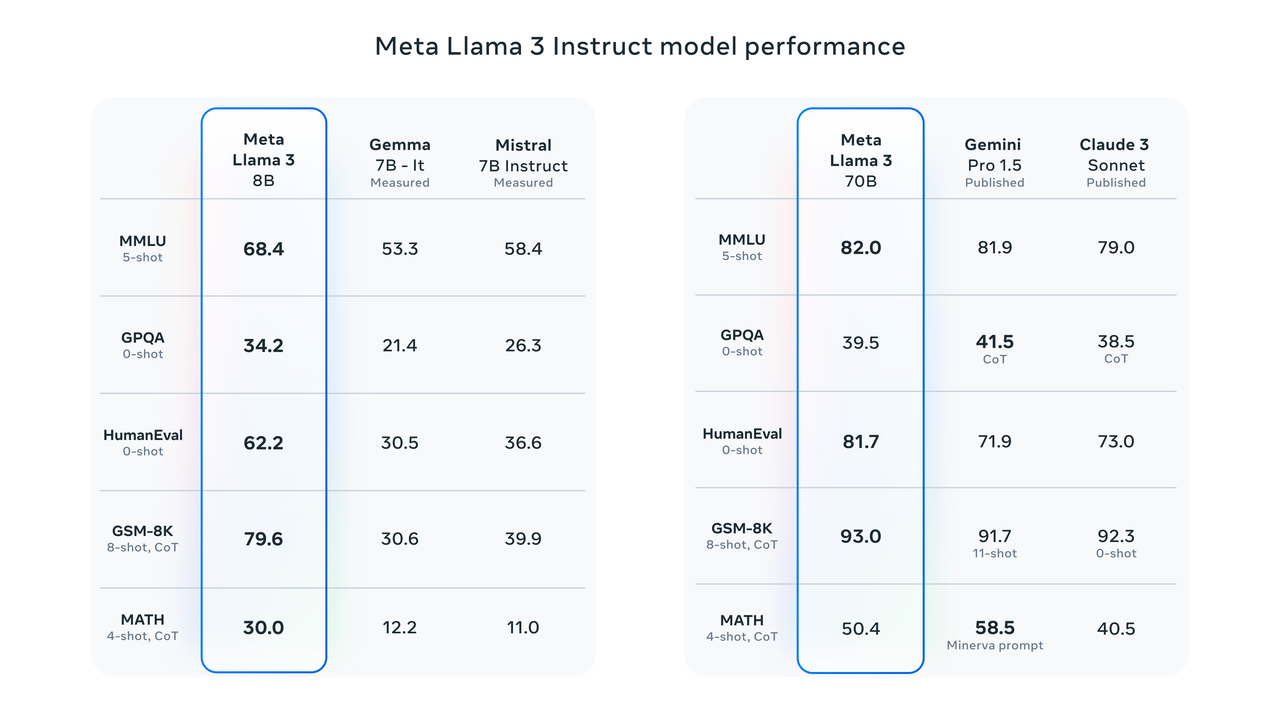
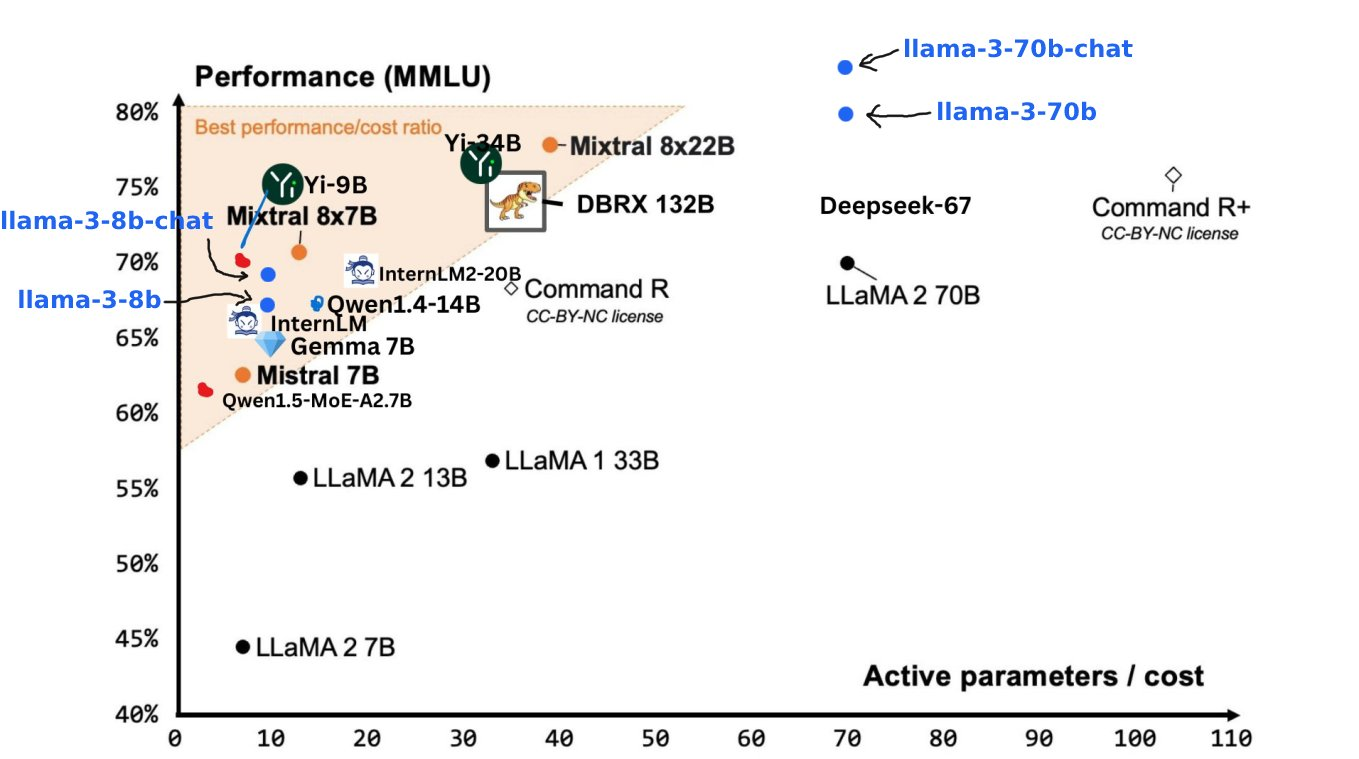
Benchmark-Testergebnisse zeigen, dass Llama 3 8B in MMLU-, GPQA-, HumanEval- und anderen Tests weitaus bessere Ergebnisse erzielt als Google Gemma 7B und Mistral 7B Instruct. In Zuckerbergs Worten ist das kleinste Llama 3 im Grunde genauso leistungsstark wie das größte Llama 2.
Llama 3 70B zählt zu den Top-KI-Modellen. Seine Gesamtleistung ist besser als die von Claude 3. Im Vergleich zu Gemini 1.5 Pro liegen sie gleichauf.
Um die Modellleistung unter Benchmarks genau zu untersuchen, hat Meta außerdem einen neuen hochwertigen Datensatz zur menschlichen Bewertung entwickelt.
Der Bewertungssatz enthält 1800 Eingabeaufforderungen, die 12 wichtige Anwendungsfälle abdecken: Um Rat fragen, Brainstorming, Kategorisierung, geschlossene Fragen und Antworten, Codierung, kreatives Schreiben, Extraktion, Persona, offene Fragen und Antworten, Begründung, Umschreiben und Zusammenfassung.

Um eine Überanpassung von Llama 3 an diesen Bewertungssatz zu verhindern, hat Meta seinem Forschungsteam sogar den Zugriff auf diesen Datensatz verboten. Im Einzelwettbewerb mit Claude Sonnet, Mistral Medium und GPT-3.5 beendete Meta Llama 70B den Wettbewerb mit einem „überwältigenden Sieg“.
Laut der offiziellen Einführung von Meta wählte Llama 3 in seiner Modellarchitektur eine relativ standardmäßige reine Decoder-Transformer-Architektur. Im Vergleich zu Llama 2 weist Llama 3 mehrere wichtige Verbesserungen auf:
- Llama 3 verwendet einen Tokenizer mit einem 128K-Token-Vokabular, um die Sprache effizienter zu kodieren und so die Modellleistung deutlich zu verbessern.
- Grouped Query Attention (GQA) wird sowohl im 8B- als auch im 70B-Modell verwendet, um die Inferenzeffizienz des Llama 3-Modells zu verbessern.
- Das Modell wird auf Sequenzen von 8192 Token trainiert, wobei Masken verwendet werden, um sicherzustellen, dass die Selbstaufmerksamkeit Dokumentgrenzen nicht überschreitet.
Die Quantität und Qualität der Trainingsdaten sind Schlüsselfaktoren für die Förderung der Entstehung großer Modellfähigkeiten in der nächsten Phase.
Meta Llama 3 war von Anfang an darauf ausgelegt, das leistungsstärkste Modell zu sein, das möglich ist. Meta investiert stark in Pre-Training-Daten. Es wird berichtet, dass Llama 3 mehr als 15T-Token aus öffentlichen Quellen verwendet, was dem Siebenfachen des von Llama 2 verwendeten Datensatzes entspricht, und dass die darin enthaltenen Codedaten viermal so hoch sind wie die von Llama 2.

In Anbetracht der praktischen Anwendung von Mehrsprachen bestehen mehr als 5 % des Llama 3-Vortrainingsdatensatzes aus hochwertigen nicht-englischen Daten, die mehr als 30 Sprachen abdecken. Meta-Beamte gaben jedoch auch zu, dass die Leistung im Vergleich zu Englisch höher ist Es wird erwartet, dass diese Sprachen etwas schlechter sind.
Um sicherzustellen, dass Llama 3 auf Daten höchster Qualität trainiert wird, verwendet das Meta-Forschungsteam im Voraus sogar heuristische Filter, NSFW-Filter, semantische Deduplizierungsmethoden und Textklassifikatoren, um die Datenqualität vorherzusagen.
Es ist erwähnenswert, dass das Forschungsteam auch herausfand, dass frühere Generationen von Llama-Modellen überraschend gut darin waren, qualitativ hochwertige Daten zu identifizieren. Daher ließen sie Llama 2 Trainingsdaten für den von Llama 3 unterstützten Textqualitätsklassifikator generieren und realisierten so wirklich „KI-Trainings-KI“. " .
Neben der Qualität des Trainings hat Llama 3 auch einen Quantensprung in der Trainingseffizienz gemacht.
Meta enthüllte, dass sie zum Trainieren des größten Llama-3-Modells drei Arten der Parallelisierung kombinierten: Datenparallelisierung, Modellparallelisierung und Pipeline-Parallelisierung.
Beim gleichzeitigen Training auf 16K-GPUs können pro GPU eine Rechenauslastung von über 400 TFLOPS erreicht werden. Das Forschungsteam führte Trainingsläufe auf zwei speziell angefertigten 24K-GPU-Clustern durch.

Um die GPU-Verfügbarkeit zu maximieren, entwickelte das Forschungsteam einen fortschrittlichen neuen Trainingsstapel, der die Fehlererkennung, -behandlung und -wartung automatisiert. Darüber hinaus hat Meta die Hardware-Zuverlässigkeit und die Mechanismen zur Erkennung stiller Datenbeschädigungen erheblich verbessert und ein neues skalierbares Speichersystem entwickelt, um den Overhead von Prüfpunkten und Rollbacks zu reduzieren.
Durch diese Verbesserungen beträgt die effektive Gesamttrainingszeit mehr als 95 % und die Trainingseffizienz von Llama 3 ist etwa dreimal höher als die der vorherigen Generation.
Weitere technische Details finden Sie im offiziellen Blog von Meta: https://ai.meta.com/blog/meta-llama-3/
Open Source vs. Closed Source
Als „Sohn“ von Meta ist Llama 3 natürlich in den KI-Chatbot Meta AI integriert.
Zurückgehend auf die Meta Connect 2023-Konferenz im letzten Jahr kündigte Zuckerberg auf dem Treffen offiziell die Einführung von Meta AI an und bewarb es dann schnell in den Vereinigten Staaten, Australien, Kanada, Singapur, Südafrika und anderen Regionen.
In früheren Interviews zeigte sich Zuckerberg noch zuversichtlicher, dass Meta AI mit Llama 3 ausgestattet ist, und sagte, es sei der intelligenteste KI-Assistent, den Menschen kostenlos nutzen können.
Ich denke, dass dies von einem Chatbot-ähnlichen Format zu einem Format übergehen wird, bei dem man einfach eine Frage stellen kann und eine Antwort erhält, und man ihm komplexere Aufgaben geben kann und diese Aufgaben erledigt.
Im Anhang finden Sie die Web-Experience-Adresse von Meta AI: https://www.meta.ai/

Wenn Meta AI „in Ihrem Land/Ihrer Region noch nicht verfügbar“ ist, können Sie natürlich den einfachsten Kanal für die Nutzung des Open-Source-Modells nutzen – Hugging Face, die weltweit größte KI-Open-Source-Community-Website.
Im Anhang finden Sie die Erlebnisadresse: https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
Perplexity, Poe und andere Plattformen kündigten ebenfalls schnell die Integration von Llama 3 in Plattformdienste an.

Sie können Llama 3 auch erleben, indem Sie die Replicate-API-Schnittstelle der Open-Source-Modellplattform aufrufen. Der Preis für die Nutzung wurde ebenfalls offengelegt, sodass Sie es möglicherweise bei Bedarf verwenden möchten.
Interessanterweise entdeckten aufmerksame Internetnutzer, bevor Meta Llama 3 offiziell ankündigte, dass Microsofts Azure-Markt die 8B-Instruct-Version von Llama 3 gestohlen hatte die Seite „404“.
Derzeit wiederhergestellt: https://azuremarketplace.microsoft.com/en-us/marketplace/apps/metagenai.meta-llama-3-8b-chat-offer?tab=overview
Die Ankunft von Llama 3 löst einen neuen Diskussionssturm auf der sozialen Plattform X aus.
Meta AI-Chefwissenschaftler und Turing-Award-Gewinner Yann LeCun jubelte nicht nur über die Veröffentlichung von Llama 3, sondern sagte auch erneut voraus, dass in den nächsten Monaten weitere Versionen auf den Markt kommen werden. Sogar Musk erschien im Kommentarbereich und drückte seine Anerkennung und Erwartungen an Llama 3 mit einem prägnanten und impliziten „Nicht schlecht“ aus.
JIm Fan, ein leitender Wissenschaftler bei NVIDIA, hat seine Aufmerksamkeit auf das kommende Llama 3 400B+ gerichtet. Seiner Ansicht nach hat sich die Einführung von Llama 3 vom technologischen Fortschritt gelöst und ist ein Symbol für das Open-Source-Modell und das Top-Closed-Source-Modell .
Aus dem geteilten Benchmark-Test geht hervor, dass die Stärke des Llama 3 400B+ fast mit der des Claude Extra Large Cup und der neuen Version des GPT-4 Turbo vergleichbar ist. Obwohl es immer noch einen gewissen Abstand gibt, reicht es aus, dies zu beweisen dass es einen Platz unter den Top-Großmodellen einnimmt.

Der heutige Tag fällt mit dem Geburtstag von Andrew Ng zusammen, einem Professor an der Stanford University und einem Top-Experten für KI. Die Ankunft von Lama 3 ist zweifellos die besondere Art, seinen Geburtstag zu feiern.
Man muss sagen, dass das heutige Open-Source-Modell wirklich hundert Blumen zum Blühen bringt und hundert Denkschulen miteinander konkurrieren lässt.
Zu Beginn dieses Jahres beschrieb Zuckerberg, der 350.000 GPUs in der Hand hat, in einem Interview mit The Verge mit festem Ton Metas Vision – engagiert für den Aufbau von AGI (künstliche allgemeine Intelligenz).
Im krassen Gegensatz zu OpenAI, das nicht offen ist, hat Meta auf dem Open-Source-Weg einen Angriff auf den Heiligen Gral von AGI gestartet.
Wie Zuckerberg sagte, hat Meta, das eindeutig Open Source ist, auf dieser herausfordernden Reise nichts gewonnen:
Generell bin ich sehr geneigt zu glauben, dass Open Source gut für die Community und gut für uns ist, weil wir von Innovationen profitieren.
Im vergangenen Jahr wurde im gesamten KI-Kreis endlos über den Open-Source- oder Closed-Source-Weg debattiert. Diese Debatte ging über den Vergleich von Vor- und Nachteilen auf technischer Ebene hinaus und berührte die Kernrichtung der zukünftigen Entwicklung der KI. Sogar Musk, der persönlich vor Ort war, hat durch Open Source Grok 1.0 einen Unterschied in der Welt gemacht.
Vor nicht allzu langer Zeit hieß es noch, dass das Open-Source-Modell immer rückständiger werden werde. Nun hat die Einführung von Llama 3 dieser pessimistischen Sichtweise auch einen schallenden Schlag ins Gesicht gegeben.
Doch obwohl Llama 3 eine gewisse Erleichterung für das Open-Source-Modell bringt, ist diese Debatte über Open Source versus Closed Source noch lange nicht vorbei.
Schließlich könnte GPT-4.5/5, das sich heimlich auf den Start vorbereitet, dieser langwierigen Debatte mit einer konkurrenzlosen Leistung in diesem Sommer ein Ende bereiten.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo