
Gerade hat Huang Renxun den Atombomben-KI-Chip der dritten Generation vorgestellt! Der persönliche Supercomputer führt 1000 Billionen Operationen pro Sekunde durch, DeepSeek wird der größte Gewinner

Die Nvidia GTC-Konferenz ist zum Super Bowl der KI-Branche geworden. Es gibt kein Drehbuch und keinen Teleprompter, und Huang Renxun ist im Gegenteil der humanste Teil dieser hochkonzentrierten KI-Konferenz, der im Grunde schon im Voraus geprobt oder aufgezeichnet wird.

Gerade hat Huang Renxun erneut eine neue Generation von KI-Chips auf Atombombenniveau herausgebracht, aber es gibt auch einen versteckten Protagonisten in dieser Konferenz – DeepSeek.
Aufgrund von Verbesserungen bei der Agenten-KI (Agentic AI) und den Argumentationsfähigkeiten ist der Rechenaufwand jetzt mindestens 100-mal höher als zu diesem Zeitpunkt im letzten Jahr geschätzt.
Die Auswirkungen der Argumentation zur Kosteneffizienz auf die KI-Branche, statt nur die Anhäufung von Rechenleistung, wurden zum Hauptthema dieser Konferenz. NVIDIA möchte eine KI-Fabrik werden, die es der KI ermöglicht, mit einer Geschwindigkeit zu lernen und zu denken, die über der des Menschen liegt.
Der Grund dafür ist im Wesentlichen, dass eine Fabrik Token produziert und der Wert der Fabrik davon abhängt, ob sie Einnahmen und Gewinne generieren kann. Daher musste die Fabrik mit äußerster Effizienz gebaut werden.
Die neue „Atombombe“ von NVIDIA, die Jen-Hsun Huang gezündet hat, zeigt uns auch, dass der zukünftige Wettbewerb in der künstlichen Intelligenz nicht darin liegt, welches Modell größer ist, sondern darin, welches Modell die niedrigsten Argumentationskosten und eine höhere Argumentationseffizienz aufweist.
Neben dem neuen Blackwell-Chip gibt es auch zwei „True AI PCs“
Der neue Blackwell-Chip trägt den Codenamen „Ultra“ und ist der GB300-KI-Chip. Er tritt die Nachfolge des „weltweit leistungsstärksten KI-Chips“ B200 an und schafft erneut einen Durchbruch in Sachen Leistung.
Blackwell Ultra wird die Rack-Scale-Lösung NVIDIA GB300 NVL72 sowie das NVIDIA HGX B300 NVL16-System umfassen.

Blackwell Ultra GB300 NVL72 wird in der zweiten Hälfte dieses Jahres veröffentlicht. Die Parameterdetails sind wie folgt:
- 1.1 EF FP4-Inferenz: Bei der Ausführung von FP4-Präzisionsinferenzaufgaben können 1,1 ExaFLOPS (exaFLOPS) erreicht werden.
- 0,36 EF FP8-Training: Die Leistung beträgt 1,2 ExaFLOPS bei der Ausführung von Trainingsaufgaben mit FP8-Genauigkeit.
- 1,5-fache GB300 NVL72: Im Vergleich zu GB200 NVL72 beträgt die Leistung das 1,5-fache.
- 20 TB HBM3: Ausgestattet mit 20 TB HBM-Speicher, 1,5-mal so viel wie die vorherige Generation
- 40 TB schneller Speicher: Es verfügt über 40 TB schnellen Speicher, was dem 1,5-fachen der vorherigen Generation entspricht.
- 14,4 TB/s CX8: Unterstützt CX8 mit einer Bandbreite von 14,4 TB/s, was dem Doppelten der vorherigen Generation entspricht.
Ein einzelner Blackwell Ultra-Chip liefert die gleiche KI-Leistung von 20 Petaflops (Petaflops) wie sein Vorgänger, jedoch mit mehr 288 GB HBM3e-Speicher.
Wenn H100 besser für das Training großer Modelle geeignet ist und B200 bei Inferenzaufgaben eine gute Leistung erbringt, dann ist B300 eine multifunktionale Plattform, die Pre-Training, Post-Training und KI-Inferenz bewältigen kann.

NVIDIA wies außerdem ausdrücklich darauf hin, dass sich Blackwell Ultra auch für KI-Agenten und „physische KI“ eignet, die zum Trainieren von Robotern und autonomen Fahrzeugen eingesetzt werden.
Um die Systemleistung weiter zu verbessern, wird Blackwell Ultra auch in die Plattformen Spectrum-X Ethernet und NVIDIA Quantum-X800 InfiniBand von NVIDIA integriert, um einen quantitativen Durchsatz von 800 Gbit/s für jede GPU im System bereitzustellen und KI-Fabriken und Cloud-Rechenzentren dabei zu helfen, KI-Inferenzmodelle schneller zu verarbeiten.
Zusätzlich zum NVL72-Rack brachte Nvidia auch die DGX Station auf den Markt, einen Desktop-Computer mit einem einzelnen GB300-Blackwell-Ultra-Chip. Zusätzlich zum Blackwell Ultra wird dieser Host auch mit 784 GB desselben Systemspeichers, einem integrierten 800 Gbit/s NVIDIA ConnectX-8 SuperNIC-Netzwerk ausgestattet sein und 20 Petaflops KI-Leistung unterstützen.

Das zuvor auf der CES 2025 vorgestellte „Mini-Host“-Projekt DIGITS trägt offiziell den Namen DGX Spark. Es ist mit dem speziell für Desktops optimierten GB10-Grace-Blackwell-Superchip ausgestattet. Es kann bis zu 1000 Billionen KI-Rechenoperationen pro Sekunde bereitstellen und wird für die Feinabstimmung und Argumentation der neuesten KI-Grundmodelle verwendet, darunter das Weltbasismodell NVIDIA Cosmos Reason und das Roboterbasismodell NVIDIA GR00T N1.
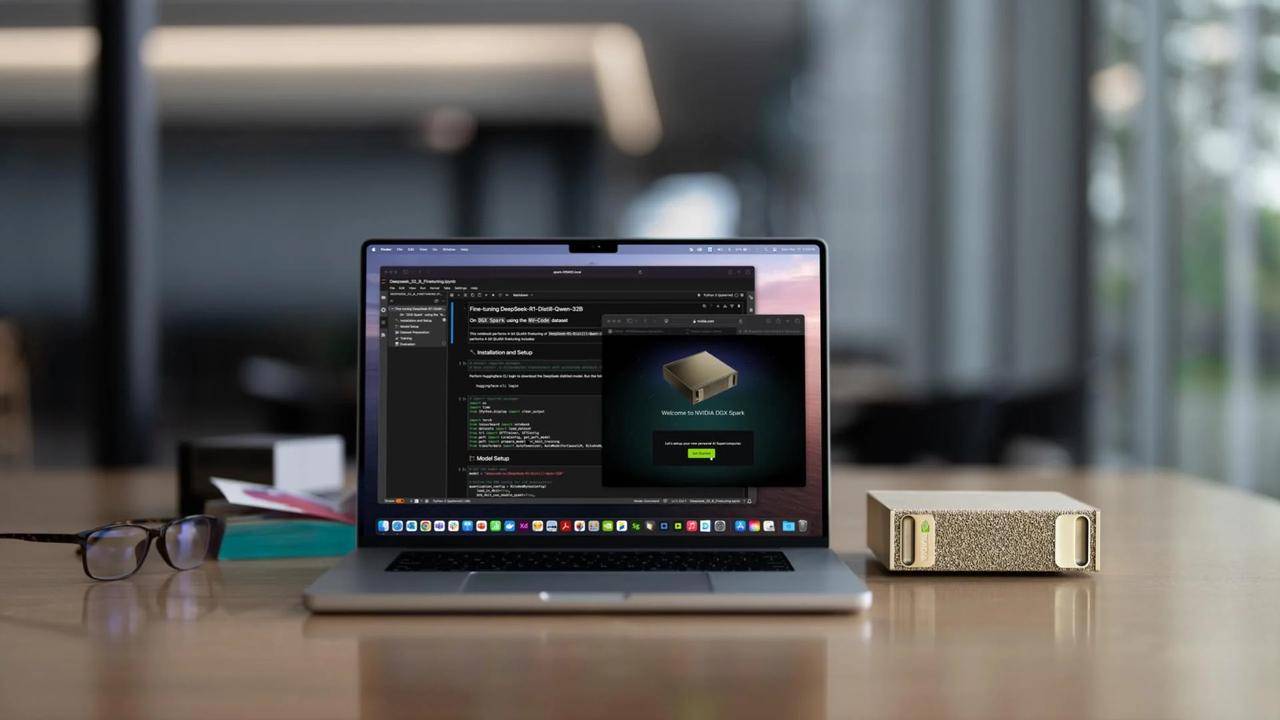
Huang Renxun sagte, dass Benutzer mit DGX Station und DGX Spark große Modelle lokal ausführen oder sie in anderen beschleunigten Clouds oder Rechenzentrumsinfrastrukturen wie NVIDIA DGX Cloud bereitstellen können.
Dies ist der Computer der KI-Ära.
Das DGX Spark-System kann ab sofort vorbestellt werden, während die DGX Station voraussichtlich noch in diesem Jahr von Partnern wie ASUS, Dell, HP und anderen auf den Markt kommen wird.
Der KI-Chip der nächsten Generation, Rubin, wurde offiziell angekündigt und soll in der zweiten Hälfte des Jahres 2026 auf den Markt kommen
NVIDIA hat seine Architektur schon immer nach Wissenschaftlern benannt, und diese Benennungsmethode ist Teil der NVIDIA-Kultur geworden. Dieses Mal hat NVIDIA diese Praxis fortgesetzt und seine KI-Chipplattform der nächsten Generation „Vera Rubin“ getauft, um an die berühmte amerikanische Astronomin Vera Rubin zu erinnern.
Huang Renxun sagte, dass Rubins Leistung 900-mal höher sein wird als die von Hopper, während Blackwell im Vergleich zu Hopper eine 68-fache Verbesserung erzielt hat.
Unter ihnen wird Vera Rubin NVL144 voraussichtlich in der zweiten Hälfte des Jahres 2026 auf den Markt kommen. Parameterinformationen sparen Fluss und lesen nicht die Version:
- 3,6 EF FP4-Inferenz: Bei der Ausführung von FP4-Präzisionsinferenzaufgaben können 3,6 ExaFLOPS (exaFLOPS) erreicht werden.
- 1,2 EF FP8 Training: Bei der Durchführung von Trainingsaufgaben mit FP8-Genauigkeit beträgt die Leistung 1,2 ExaFLOPS.
- 3,3-faches GB300 NVL72: Im Vergleich zum GB300 NVL72 ist die Leistung um das 3,3-fache verbessert.
- 13 TB/s HBM4: Ausgestattet mit HBM4 beträgt die Bandbreite 13 TB/s.
- 75 TB schneller Speicher: Es verfügt über 75 TB schnellen Speicher, was 1,6-mal so viel ist wie die vorherige Generation.
- 260 TB/s NVLink6: Unterstützt NVLink 6 mit einer Bandbreite von 260 TB/s, was dem Doppelten der vorherigen Generation entspricht.
- 28,8 TB/s CX9: Unterstützt CX9 mit einer Bandbreite von 28,8 TB/s, was dem Doppelten der vorherigen Generation entspricht.

Die Standardversion von Rubin wird mit HBM4 ausgestattet sein, was die Leistung gegenüber dem aktuellen Hopper H100-Chip deutlich verbessert hat.
Rubin stellte einen Nachfolger namens Grace CPU – Veru vor, der 88 angepasste Arm-Kerne enthält, jeder Kern unterstützt 176 Threads und erreicht über NVLink-C2C eine Verbindung mit hoher Bandbreite von 1,8 TB/s.
Nvidia sagt, dass das benutzerdefinierte Vera-Design doppelt so schnell sein wird wie die CPU, die im letztjährigen Grace Blackwell-Chip verwendet wurde.
In Kombination mit einer Vera-CPU kann Rubins Rechenleistung bei Inferenzaufgaben 50 Petaflops erreichen, mehr als das Doppelte der 20 Petaflops von Blackwell. Darüber hinaus unterstützt Rubin auch HBM4-Speicher mit bis zu 288 GB, was ebenfalls eine der Kernspezifikationen ist, auf die KI-Entwickler achten.

Tatsächlich besteht Rubin aus zwei GPUs, und dieses Designkonzept ähnelt der derzeit auf dem Markt erhältlichen Blackwell-GPU – letztere funktioniert ebenfalls, indem sie zwei unabhängige Chips zu einem Ganzen zusammenfügt.
Beginnend mit Rubin wird Nvidia Multi-GPU-Komponenten nicht mehr wie bei Blackwell als eine einzelne GPU bezeichnen, sondern sie anhand der tatsächlichen Anzahl der GPU-Chipchips genauer zählen.
Auch die Verbindungstechnologie wurde aktualisiert. Rubin ist mit NVLink der sechsten Generation und einer CX9-Netzwerkkarte ausgestattet, die 1600 Gbit/s unterstützt, was die Datenübertragung beschleunigen und die Konnektivität verbessern kann.
Zusätzlich zur Standardversion von Rubin plant Nvidia auch die Einführung einer Ultra-Version von Rubin.

Rubin Ultra NVL576 wird in der zweiten Hälfte des Jahres 2027 auf den Markt kommen. Parameterdetails sind wie folgt:
- 15 EF FP4-Inferenz: Die Leistung erreicht 15 ExaFLOPS, wenn Inferenzaufgaben mit FP4-Präzision ausgeführt werden.
- 5 EF FP8 Training: Leistung von 5 ExaFLOPS bei der Durchführung von Trainingsaufgaben mit FP8-Genauigkeit.
- 14X GB300 NVL72: Im Vergleich zu GB300 NVL72 ist die Leistung um das 14-fache verbessert.
- 4,6 PB/s HBM4e: Ausgestattet mit HBM4e-Speicher beträgt die Bandbreite 4,6 PB/s.
- 365 TB schneller Speicher: Das System verfügt über 365 TB schnellen Speicher, was achtmal so viel ist wie die vorherige Generation.
- 1,5 PB/s NVLink7: Unterstützt NVLink 7 mit einer Bandbreite von 1,5 PB/s, 12-mal so viel wie die der vorherigen Generation.
- 115,2 TB/s CX9: Unterstützt CX9 mit einer Bandbreite von 115,2 TB/s, was dem Achtfachen der Bandbreite der vorherigen Generation entspricht.
In Bezug auf die Hardwarekonfiguration setzt das Veras-System von Rubin Ultra das Design von 88 maßgeschneiderten Arm-Kernen fort, jeder Kern unterstützt 176 Threads und bietet über NVLink-C2C eine Bandbreite von 1,8 TB/s.
In Bezug auf die GPU integriert Rubin Ultra vier GPUs in Reticle-Größe. Jede GPU bietet 100 Petaflops FP4-Rechenleistung und ist mit 1 TB HBM4e-Speicher ausgestattet, wodurch neue Höhen in Bezug auf Leistung und Speicherkapazität erreicht werden.
Um im sich schnell ändernden Wettbewerb auf dem Markt gut bestehen zu können, wurde der Produktveröffentlichungsrhythmus von NVIDIA auf einmal pro Jahr verkürzt. Auf der Pressekonferenz gab Huang auch offiziell den Namen des KI-Chips der nächsten Generation bekannt – Physiker Feynman.
Da die Größe der KI-Fabriken immer weiter zunimmt, rückt die Bedeutung der Netzwerkinfrastruktur immer stärker in den Vordergrund.
Zu diesem Zweck hat NVIDIA Spectrum-X eingeführt  und optische Quantum-X-Silizium-Netzwerk-Switches, die KI-Fabriken dabei helfen sollen, Millionen von GPUs standortübergreifend zu verbinden und gleichzeitig den Energieverbrauch und die Betriebskosten deutlich zu senken.
und optische Quantum-X-Silizium-Netzwerk-Switches, die KI-Fabriken dabei helfen sollen, Millionen von GPUs standortübergreifend zu verbinden und gleichzeitig den Energieverbrauch und die Betriebskosten deutlich zu senken.

Spectrum-X Photonics-Schalter sind in verschiedenen Konfigurationen erhältlich, darunter:
- 128-Port-800-Gbit/s- oder 512-Port-200-Gbit/s-Konfiguration mit einer Gesamtbandbreite von 100 Tbit/s
- Konfiguration mit 512 Ports 800 Gbit/s oder 2048 Ports 200 Gbit/s, Gesamtdurchsatz erreicht 400 Tbit/s
Der zugehörige Quantum-X Photonics-Switch basiert auf der 200-Gbit/s-SerDes-Technologie, bietet 144-Port-800-Gbit/s-InfiniBand-Verbindungen und nutzt ein Flüssigkeitskühlungsdesign, um integrierte Silizium-Photonikkomponenten effizient zu kühlen.
Quantum-X Photonics-Switches bieten im Vergleich zu Produkten der vorherigen Generation eine doppelte Geschwindigkeit und eine fünffache Skalierbarkeit für die KI-Computing-Architektur.
Quantum-X Photonics InfiniBand-Switches werden voraussichtlich noch in diesem Jahr verfügbar sein, während Spectrum-X Photonics Ethernet-Switches voraussichtlich im Jahr 2026 auf den Markt kommen.
Mit der rasanten Entwicklung der KI ist auch der Bedarf an Bandbreite, geringer Latenz und hoher Energieeffizienz in Rechenzentren dramatisch gestiegen.
NVIDIA Spectrum-X Photonics-Switches verwenden eine Photonik-Integrationstechnologie namens CPO. Sein Kern besteht darin, die optische Engine (also einen Chip, der optische Signale verarbeiten kann) und gewöhnliche elektronische Chips (wie Schaltchips oder ASIC-Chips) in einem Gehäuse unterzubringen.
Die Vorteile dieser Technik sind vielfältig:
- Höhere Übertragungseffizienz: Durch die Verkürzung der Distanz wird das Signal schneller übertragen.
- Geringerer Stromverbrauch: Die Entfernung ist kürzer und es wird weniger Energie zur Signalübertragung benötigt.
- Kleinere Größe: Durch die Integration optischer und elektrischer Komponenten wird die Gesamtgröße kleiner und die Raumausnutzung höher.
Dynamo, das „Betriebssystem“ der KI-Fabrik
In Zukunft wird es keine Rechenzentren mehr geben, sondern nur noch KI-Fabriken.
Huang Renxun sagte, dass es in Zukunft, wenn jede Branche und jedes Unternehmen eine Fabrik hat, zwei Fabriken geben wird: eine ist die Fabrik, in der tatsächlich produziert wird, und die andere ist die KI-Fabrik, und Dynamo ist ein Betriebssystem, das speziell für die „KI-Fabrik“ entwickelt wurde.
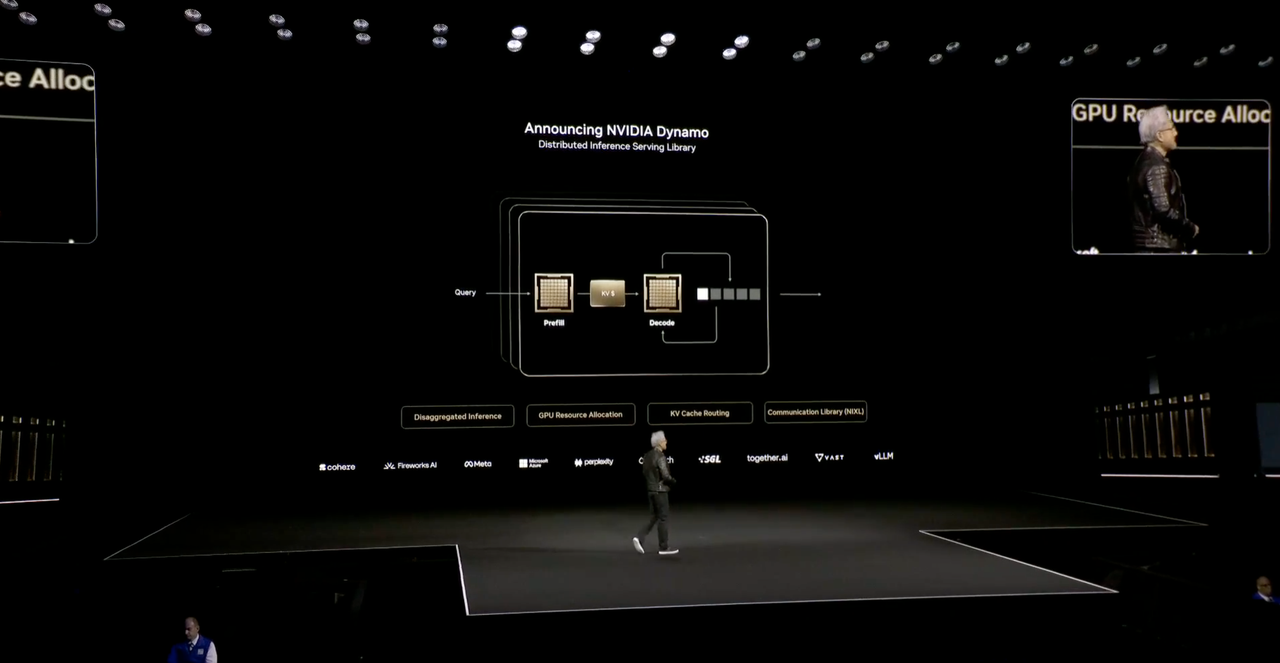
Dynamo ist eine verteilte Reasoning-Dienstbibliothek, die Open-Source-Lösungen für Probleme bereitstellt, die Token erfordern, aber nicht genügend Token erhalten können.
Einfach ausgedrückt bietet Dynamo vier Vorteile:
- Die GPU-Planungs-Engine plant GPU-Ressourcen dynamisch, um sie an die Benutzeranforderungen anzupassen
- Der intelligente Router reduziert die GPU-Neuberechnung wiederholter und überlappender Anfragen und setzt so mehr Rechenleistung für die Bearbeitung neuer eingehender Anfragen frei.
- Kommunikationsbibliothek mit geringer Latenz zur Beschleunigung der Datenübertragung
- Speichermanager, Intelligenz für Inferenzdaten in kostengünstigen Speicher- und Speichergeräten
Humanoide Roboter werden in ihrem Erscheinungsbild nie fehlen
Humanoide Roboter bildeten erneut das Finale der GTC-Konferenz. Dieses Mal brachte NVIDIA Isaac GR00T N1, das weltweit erste Open-Source-Funktionsmodell eines humanoiden Roboters.

Huang Renxun sagte, dass die Ära der allgemeinen Robotik mit Hilfe des Datengenerierungs- und Roboterlern-Frameworks des Isaac GR00T N1-Kerns angebrochen sei, Roboterentwickler auf der ganzen Welt würden die nächste Grenze der KI-Ära betreten.
Dieses Modell verwendet eine „Dual-System“-Architektur, um menschliche kognitive Prinzipien zu imitieren:
- System 1: Ein schnell denkendes Aktionsmodell, das menschliche Reaktionen oder Intuition nachahmt
- System 2: Ein Modell des langsamen Denkens für eine durchdachte Entscheidungsfindung.
Mithilfe des visuellen Sprachmodells ermittelt System 2 die Umgebung und Anweisungen und plant dann Aktionen. System 1 setzt diese Pläne in Roboteraktionen um.
Das Basismodell des GR00T N1 wird vorab mithilfe allgemeiner, menschenähnlicher Überlegungen und Fähigkeiten trainiert, und Entwickler können das Training mit realen oder synthetischen Daten nachbearbeiten, um spezifische Anforderungen zu erfüllen: ob es bestimmte Aufgaben in der Fabrik erledigen oder Hausarbeiten zu Hause autonom erledigen kann.
Huang kündigte außerdem Newton an, eine Open-Source-Physik-Engine, die in Zusammenarbeit mit Google DeepMind und Disney Research entwickelt wurde.

Ein mit der Newton-Plattform ausgestatteter Roboter erschien ebenfalls auf der Bühne und nannte ihn „Blue“. Er sah aus wie der BDX-Roboter in „Star Wars“ und konnte mit Huang über Stimme und Bewegung interagieren.
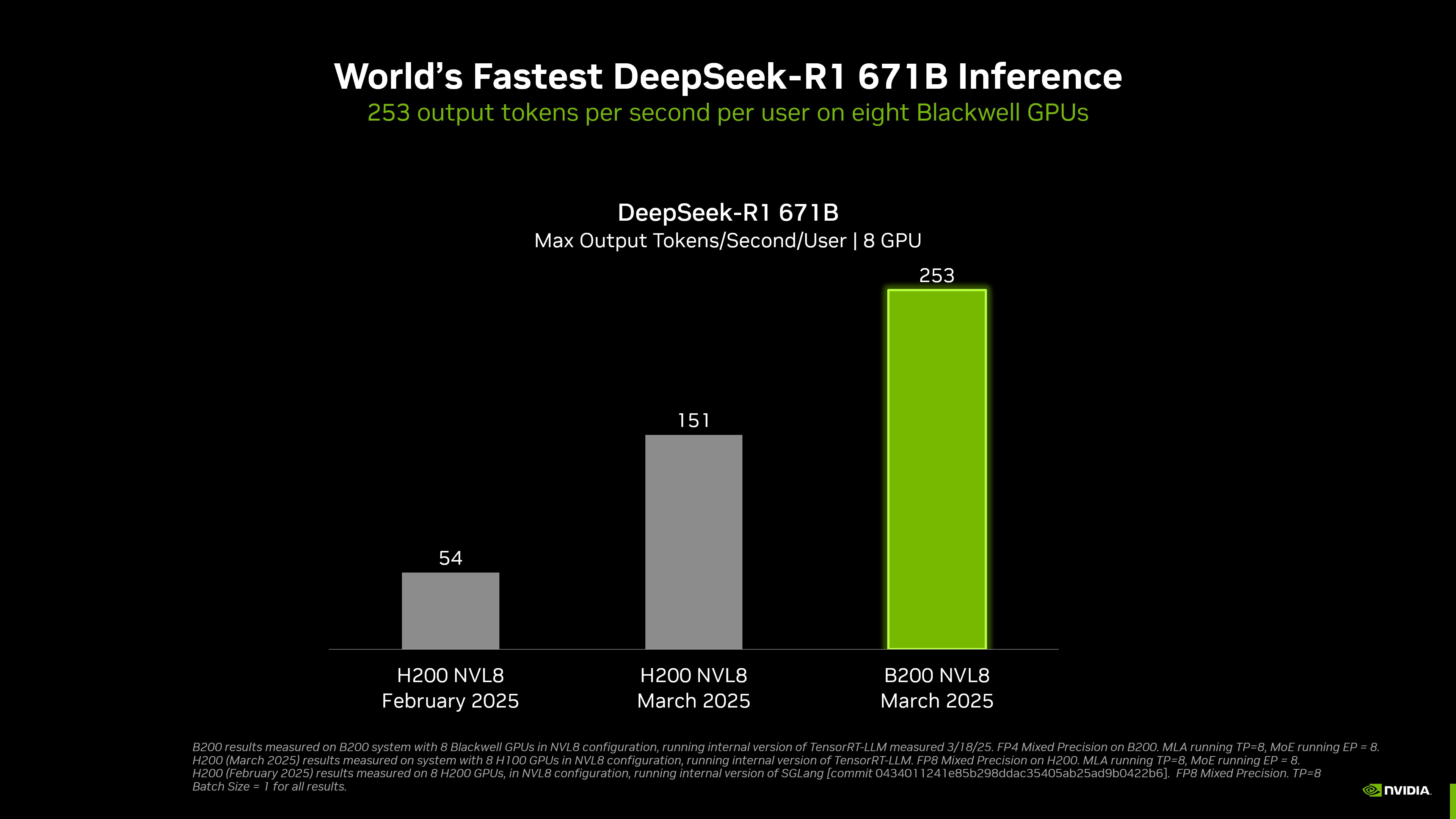
Mit 8 GPUs ist die Inferenzgeschwindigkeit von DeepSeek-R1 die schnellste der Welt
NVIDIA hat die weltweit schnellste DeepSeek-R1-Inferenz erreicht.
Laut der offiziellen Website kann ein mit 8 Blackwell-GPUs ausgestattetes DGX-System beim Ausführen des DeepSeek-R1-Modells mit 671 Milliarden Parametern eine Geschwindigkeit von mehr als 250 Token pro Sekunde und Benutzer erreichen oder einen maximalen Durchsatz von mehr als 30.000 Token pro Sekunde erreichen.
Durch die Kombination von Hardware und Software hat sich der Durchsatz von NVIDIA beim Modell DeepSeek-R1 671B seit Januar dieses Jahres um etwa das 36-fache erhöht, und die Kosteneffizienz pro Token hat sich um etwa das 32-fache erhöht.
Um diesen Erfolg zu erreichen, wurde das gesamte Inferenz-Ökosystem von NVIDIA umfassend für die Blackwell-Architektur optimiert. Es integriert nicht nur fortschrittliche Tools wie TensorRT-LLM und TensorRT Model Optimizer, sondern unterstützt auch nahtlos gängige Frameworks wie PyTorch, JAX und TensorFlow.
Bei Modellen wie DeepSeek-R1, Llama 3.1 405B und Llama 3.3 70B verbessert die DGX B200-Plattform mit FP4-Genauigkeit den Inferenzdurchsatz im Vergleich zur DGX H200-Plattform um mehr als das Dreifache.
Es ist erwähnenswert, dass Quantencomputing in der Grundsatzrede dieser Konferenz nicht erwähnt wurde, NVIDIA jedoch speziell einen Quantentag auf dieser GTC-Konferenz veranstaltete und die CEOs vieler bekannter Quantencomputing-Unternehmen zur Teilnahme einlud.
Sie müssen wissen, dass Huang Renxuns Behauptung zu Beginn des Jahres, dass „Quantencomputing 20 Jahre dauern wird, bis es praktikabel ist“, mir immer noch in den Ohren ist.
Hinter der Tonänderung steht es untrennbar mit dem topologischen Quantenchip Majorana 1 von Microsoft, der 17 Jahre für die Entwicklung und Realisierung der Integration von 8 topologischen Qubits benötigte. Er ist auch untrennbar mit dem Google Willow-Chip verbunden, der behauptet, eine Aufgabe zu erledigen, die ein klassischer Computer in 10^25 Jahren in 5 Minuten verarbeiten muss, was den Hype um das Quantencomputing fördert.

Der Chip ist zweifellos das Highlight, aber auch das Debüt einiger Software verdient Aufmerksamkeit.
Marc Andreessen, ein berühmter Investor aus dem Silicon Valley, argumentierte einmal, dass Software die Welt verschlingt. Die Kernlogik besteht darin, dass Software durch Virtualisierung, Abstraktion und Standardisierung zur Infrastruktur wird, die die physische Welt kontrolliert.
NVIDIA gibt sich nicht damit zufrieden, ein „Schaufelverkäufer“ zu sein, sondern hat den Ehrgeiz, ein „Produktivitätsbetriebssystem“ im KI-Zeitalter zu schaffen. Vom intelligenten Fahren von Autos bis hin zu digitalen Zwillingsfabriken in der Fertigungsindustrie sind diese Fälle auf der Konferenz konkrete Ausdrucksformen der Umwandlung von GPU-Rechenleistung in Branchenproduktivität.
Unabhängig davon, ob es sich um den neuesten Atombombenchip handelt, der auf der Pressekonferenz vorgestellt wurde, oder um Quantencomputing-Wetten auf die Zukunft, sind Huang Renxuns Erkenntnisse und Pläne zur zukünftigen Entwicklung der KI auf dieser Pressekonferenz interessanter als die aktuellen technischen Parameter und Leistungsindikatoren.

Bei der Einführung des Vergleichs zwischen Blackwell- und Hopper-Architektur vergaß Huang Renxun auch nicht, Humor einzusetzen.
Als Beispiel verwendete er die Vergleichsdaten einer 100-MW-Fabrik und wies darauf hin, dass die Hopper-Architektur 45.000 Chips und 400 Racks benötige, während die Blackwell-Architektur den Hardwarebedarf aufgrund der höheren Effizienz deutlich reduziert.
Daher wurde Huang Renxuns klassische Zusammenfassung wieder verworfen: „Je mehr Sie kaufen, desto mehr sparen Sie“ (je mehr Sie kaufen, desto mehr sparen Sie). „Dann änderte sich das Thema und er fügte hinzu: „Je mehr Sie kaufen, desto mehr verdienen Sie“ (je mehr Sie kaufen, desto mehr verdienen Sie).
Da sich der Schwerpunkt des KI-Bereichs vom Training auf das Denken verlagert, muss NVIDIA beweisen, dass sein Software- und Hardware-Ökosystem in Denkszenarien unersetzlich ist.
Einerseits entwickeln Giganten wie Meta und Google selbst entwickelte KI-Chips, die möglicherweise die Nachfrage vom GPU-Markt ablenken.
Andererseits reagiert das rechtzeitige Debüt der neuesten KI-Chips von NVIDIA auf die Auswirkungen von Open-Source-Modellen wie DeepSeek auf die GPU-Nachfrage und demonstriert technologische Vorteile im Bereich der Argumentation. Es dient auch der Absicherung gegen Marktbedenken hinsichtlich der Spitzennachfrage nach Schulungen.
Nvidia, dessen Bewertung kürzlich auf ein 10-Jahres-Tief gefallen ist, braucht mehr denn je einen kräftigen Sieg.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo