
OpenAI gibt an, Beweise für DeepSeek-Verstöße zu haben, und der CEO von Anthropic veröffentlicht eine 10.000 Wörter lange Botschaft, in der er strengere Kontrollen in den Vereinigten Staaten fordert

DeepSeek war in letzter Zeit in Schwierigkeiten.
Nach Angaben der ausländischen Medien Financial Times sagte OpenAI, es gebe Beweise dafür, dass DeepSeek das Modell von OpenAI verwendet habe, um seine eigenen Open-Source-KI-Produkte zu entwickeln, was möglicherweise gegen die Nutzungsbedingungen von OpenAI verstoßen habe.
In der KI-Branche ist es üblich, neue Modelle mithilfe der „Destillations“-Technologie zu entwickeln. OpenAI ist jedoch der Ansicht, dass das Verhalten von DeepSeek den akzeptablen Bereich überschritten hat, da das Unternehmen die Technologie von OpenAI nutzt, um ein Konkurrenzprodukt zu entwickeln.
Zum Zeitpunkt der Drucklegung lehnte OpenAI es ab, näher auf die Einzelheiten dieser Anschuldigungen einzugehen.
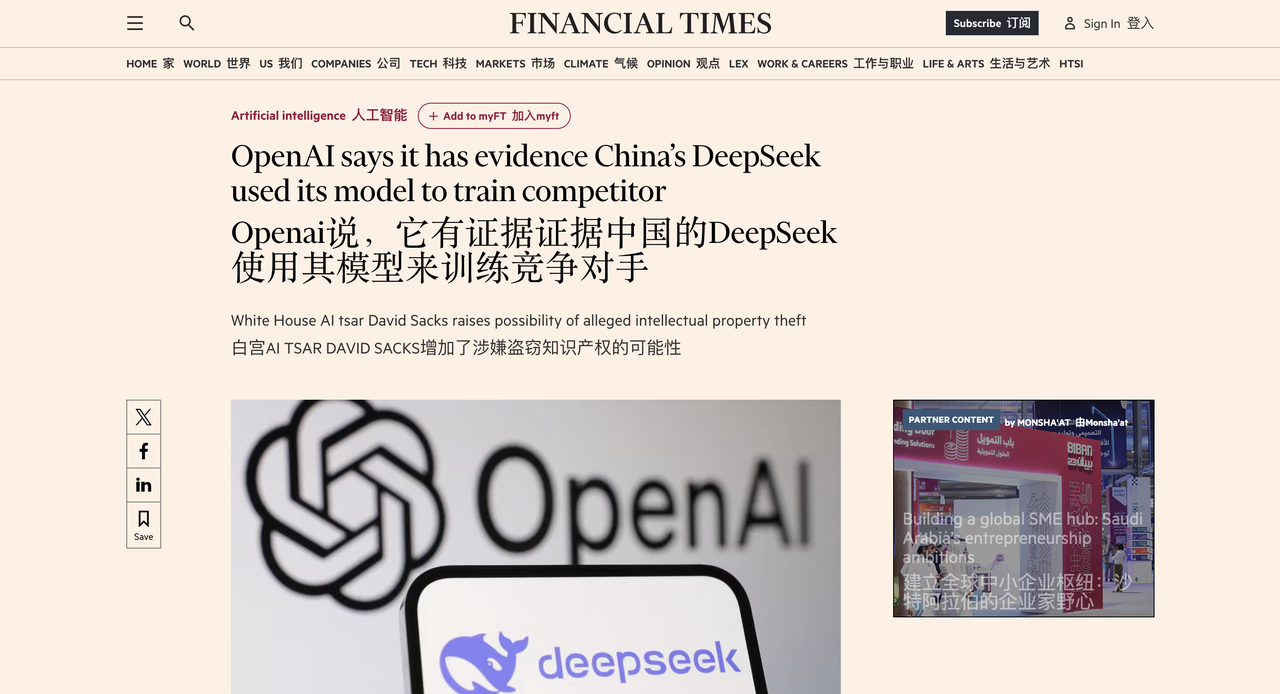
Gestern berichtete Bloomberg, dass OpenAI und sein Partner Microsoft im vergangenen Jahr eine Untersuchung mehrerer Konten eingeleitet haben, die die OpenAI-API verwendet haben, und den Zugriff auf Konten gesperrt haben, bei denen der Verdacht auf Modelldestillation besteht, mit der Begründung, dass diese Verhaltensweisen gegen die Nutzungsbedingungen verstoßen.
Eine Welle ist nicht abgeklungen und eine andere Welle ist entstanden.
Nach Angaben der ausländischen Medien Techcrunch reichte DeepSeek einen Markenantrag beim US-amerikanischen Patent- und Markenamt (USPTO) ein, in der Hoffnung, die Marke seiner KI-Chatbots, Produkte und Tools registrieren zu lassen. Der Antrag kam jedoch verspätet.
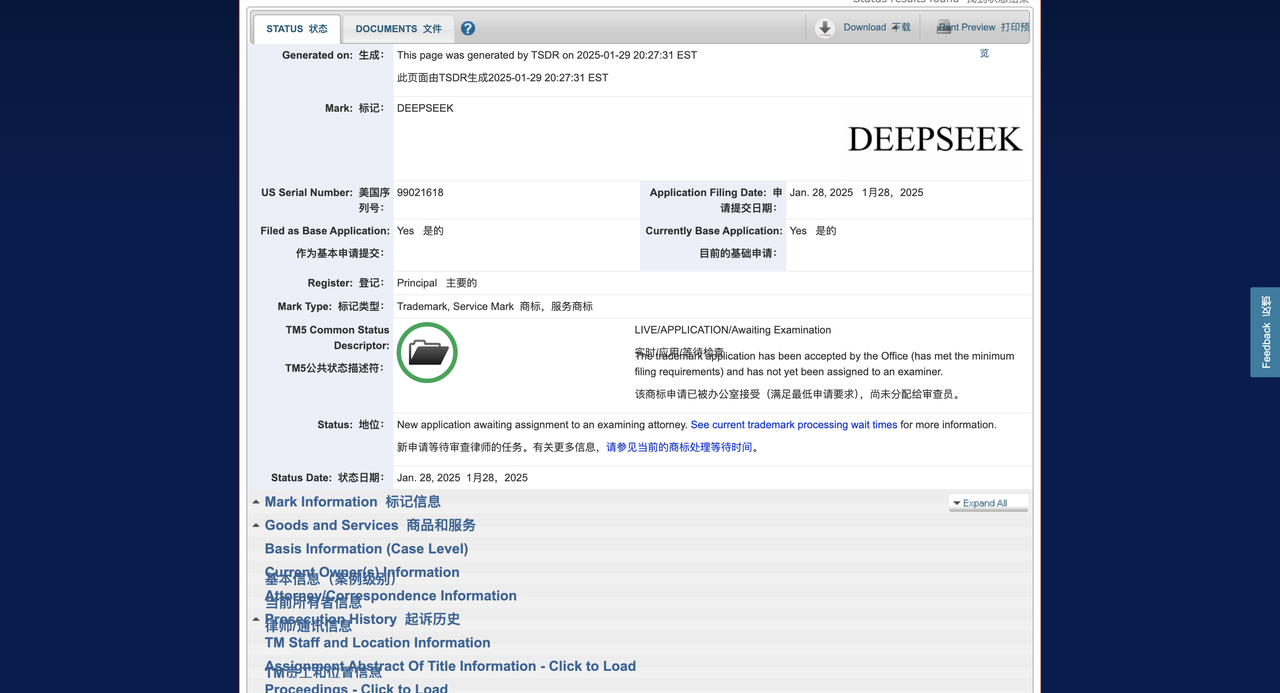
Erst vor 36 Stunden übernahm ein Unternehmen aus Delaware namens Delson Group Inc. die Führung bei der Einreichung einer Anmeldung für die Marke „DeepSeek“.
Die Delson Group behauptet, seit 2020 KI-Produkte der Marke „DeepSeek“ zu verkaufen. Die eingetragene Adresse des Unternehmens in der Markenanmeldung ist ein Haus in Cupertino, und sein Gründer und CEO ist Willie Lu.
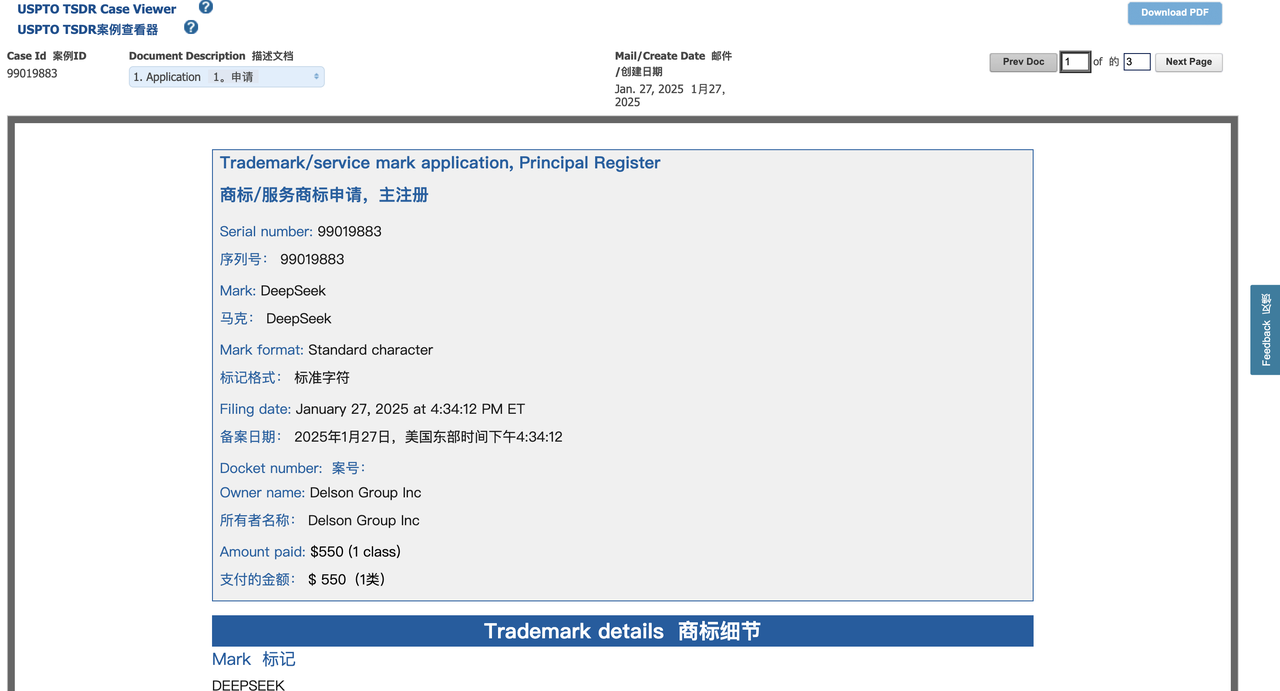
Interessanterweise sind Lu und DeepSeek-Gründer Liang Wenfeng beide Absolventen der Zhejiang-Universität. Lus LinkedIn-Profil zufolge ist er ein „halbpensionierter“ Beratungsprofessor an der Stanford University und fungiert auch als Berater der US-amerikanischen Federal Communications Commission (FCC). Sein beruflicher Schwerpunkt liegt im Bereich der drahtlosen Kommunikation.
Die Untersuchung von TechCrunch ergab, dass Lu in Las Vegas unter der Marke „DeepSeek“ auch einen Bildungskurs mit dem Titel „AI Super-Intelligence“ abhielt, dessen Tickets bei 800 US-Dollar begannen. Die Website des Kurses ist auch in der Markenanmeldung der Delson Group aufgeführt und behauptet, Lu verfüge über etwa 30 Jahre Erfahrung in den Bereichen Informations- und Kommunikationstechnologie (IKT) und künstliche Intelligenz (KI).
Als TechCrunch Lu über die in der Markenanmeldung enthaltene E-Mail kontaktierte, bot er an, sich in Palo Alto oder Saratoga, Kalifornien (der Reporter war in New York) zu treffen, um die Angelegenheit zu besprechen. Lu reagierte jedoch nicht auf weitere Anfragen nach Kommentaren.
Eine Suche in der Datenbank des Trademark Trial and Appeal Board (TTAB) des USPTO zeigt, dass die Delson Group zuvor mehr als 20 Markenstreitigkeiten mit vielen bekannten Unternehmen hatte, darunter GSMA, Tencent und TracFone Wireless. Das Unternehmen hat auf einige Markenanmeldungen freiwillig verzichtet oder diese zurückgezogen, hat aber auch einige Marken erfolgreich registriert.
Eine Suche in der breiteren USPTO-Markendatenbank zeigt, dass die Delson Group 28 Marken registriert hat, darunter auch Marken bekannter chinesischer Unternehmen. Beispielsweise ließ das Unternehmen die Marken „Geely“ und „China Mobile“ eintragen, Marken, die einem chinesischen Autohersteller bzw. einem Telekommunikationsgiganten aus Hongkong gehören.
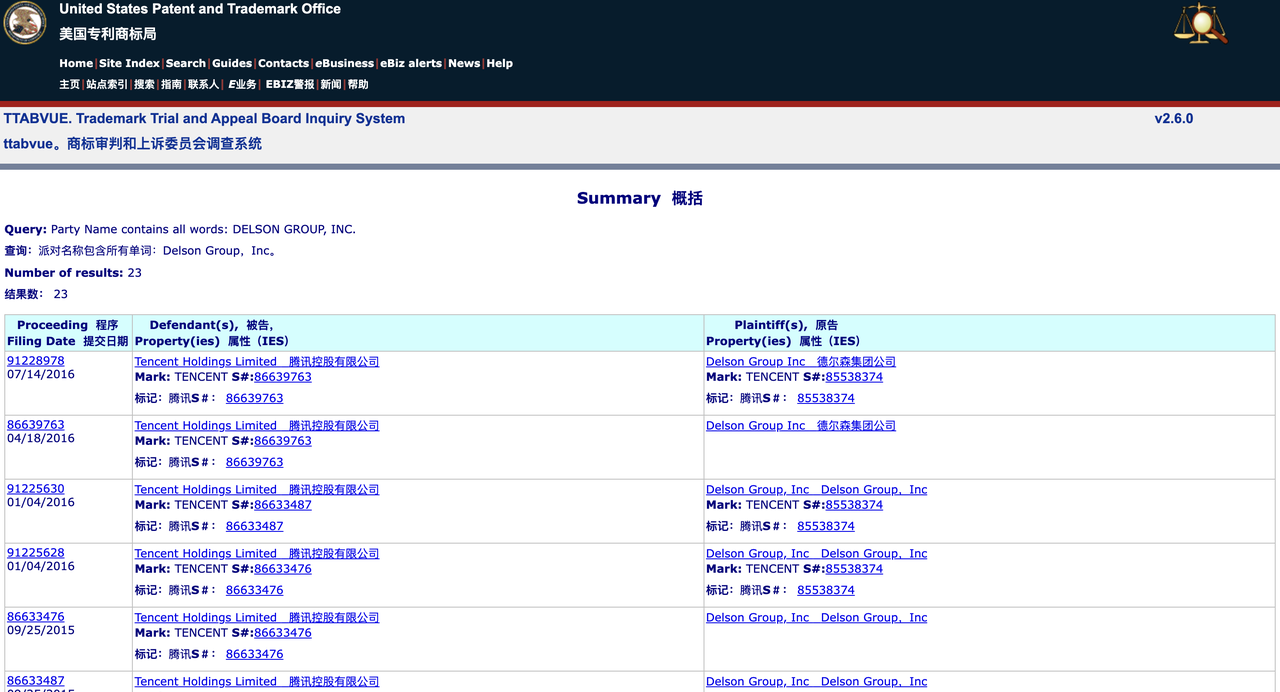
Dieses Muster deutet darauf hin, dass die Delson Group möglicherweise an einem „Trademark Squatting“-Verhalten beteiligt ist, das heißt, dass sie Marken im Voraus registriert, um sie später zu verkaufen oder von der Markenbekanntheit zu profitieren.
Derzeit sind die Markenrechte von DeepSeek in den USA benachteiligt. Nach US-Recht gilt im Allgemeinen das erste Unternehmen, das eine Marke nutzt, als rechtmäßiger Eigentümer der Marke, es sei denn, es kann nachgewiesen werden, dass die andere Partei sie in böser Absicht registriert hat.
Josh Gerben, Anwalt für geistiges Eigentum und Gründer der Gerben IP Firm, sagte in einem Interview mit TechCrunch, dass die Delson Group in vielerlei Hinsicht Vorteile habe:
- Die Bewerbungszeit ist früher (Einreichung 36 Stunden früher als bei DeepSeek);
- Behauptet, die Marke seit 2020 zu verwenden (DeepSeeks Markenanmeldung gibt an, dass es im Jahr 2023 gegründet wurde);
- Verfügen Sie über nachweisbare KI-bezogene Aktivitäten (einschließlich Schulungen und Website).
Gerben wies darauf hin, dass die Delson Group sogar eine Klage wegen „umgekehrter Verwechslung (Reverse Confusion)“ einreichen könnte, mit der Begründung, dass der schnelle Aufstieg von DeepSeek dazu führen würde, dass die Öffentlichkeit fälschlicherweise glaubt, DeepSeek sei der wahre Eigentümer der Marke. Darüber hinaus kann die Delson Group auch DeepSeek verklagen und verlangen, dass das Unternehmen die Nutzung der Marke „DeepSeek“ auf dem US-Markt einstellt.

„DeepSeek steht möglicherweise vor ernsthaften Markenproblemen“, sagte Gerben. „Die Delson Group als potenzieller „Inhaber früherer Rechte“ könnte gute Gründe für einen Rechtsstreit wegen Markenverletzung haben. "
Es ist erwähnenswert, dass DeepSeek nicht das einzige KI-Unternehmen ist, das Probleme mit Markenproblemen hatte. OpenAI versuchte beispielsweise, die Marke „GPT“ zu registrieren, wurde jedoch im Februar letzten Jahres vom USPTO mit der Begründung abgelehnt, der Begriff sei zu allgemein.
Wie wir bereits berichtet haben, befindet sich OpenAI immer noch in einem Rechtsstreit mit dem Technologieunternehmer Guy Ravine über die Marke „Open AI“. Ravine behauptete, er habe dieses Markenkonzept bereits 2015 (dem Gründungsjahr von OpenAI) vorgeschlagen und gehofft, eine „Open-Source“-KI-Plattform zu schaffen.
Darüber hinaus veröffentlichte Anthropic-CEO Dario Amodei heute früh einen 10.000 Wörter langen Artikel über die X-Plattform und reagierte damit auf die vielen jüngsten Unruhen rund um DeepSeek.
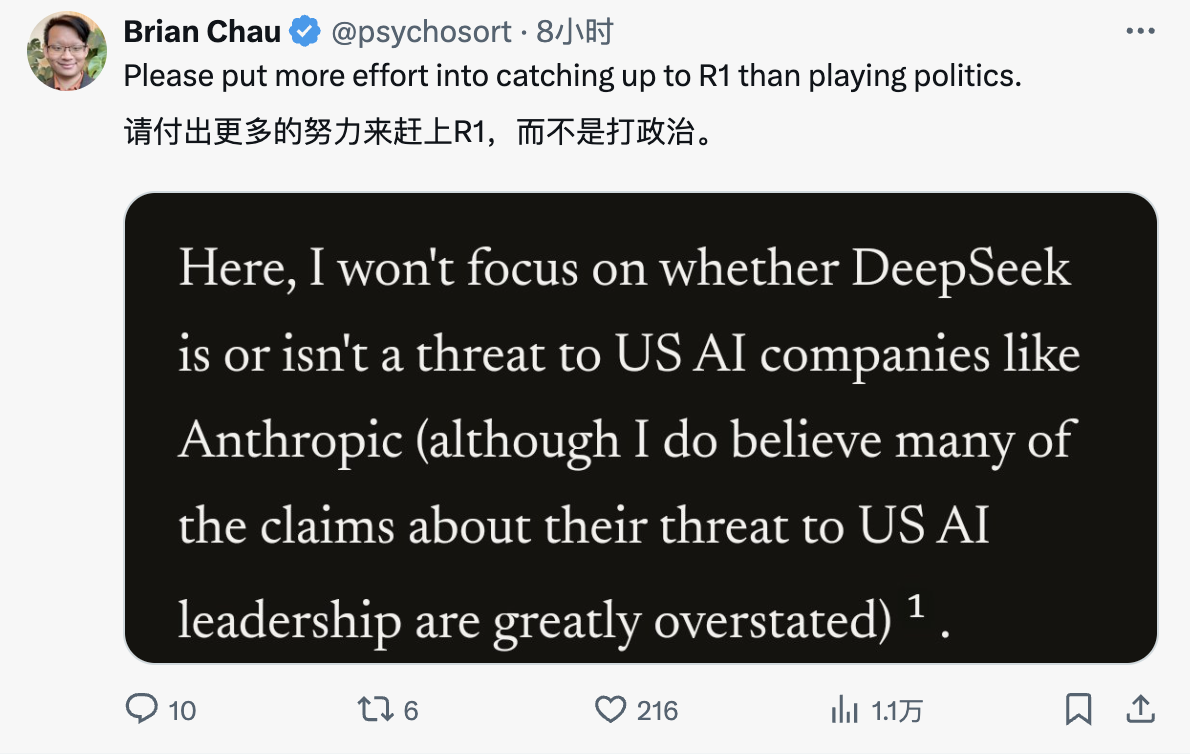
Angesichts des mutmaßlichen Verstoßes gegen Amodei schrieb Netizen X im Kommentarbereich:
Im Anhang finden Sie eine Zusammenstellung des Originaltextes (mit Streichungen) ~
Vor ein paar Wochen habe ich vorgeschlagen, die US-Chip-Exportkontrollen nach China zu verstärken. Heute nähert sich das chinesische KI-Unternehmen DeepSeek tatsächlich den modernsten KI-Modellen in den Vereinigten Staaten und ist in einigen Aspekten kostengünstiger.
In diesem Artikel werde ich nicht diskutieren, ob DeepSeek tatsächlich amerikanische KI-Unternehmen wie Anthropic bedroht (obwohl ich glaube, dass einige Behauptungen über die Übernahme der amerikanischen Führung durch chinesische KI übertrieben sind)¹. Stattdessen möchte ich einer Frage nachgehen: Untergräbt der technologische Durchbruch von DeepSeek die Notwendigkeit von Chip-Exportkontrollen? Meine Antwort ist nein. Tatsächlich denke ich, dass dies die Bedeutung der Exportkontrollen unterstreicht².
Das Hauptziel der Exportkontrollen besteht darin, sicherzustellen, dass Demokratien bei der KI-Entwicklung einen Schritt voraus bleiben. Es muss klar sein, dass die Regulierungspolitik nicht darauf abzielt, den chinesisch-amerikanischen KI-Wettbewerb zu verhindern. Wenn die Vereinigten Staaten und andere Demokratien letztendlich in der KI dominieren wollen, müssen sie über fortschrittlichere Modelle als China verfügen. Aber gleichzeitig sollten wir nicht zulassen, dass die chinesische Regierung einen technologischen Vorteil erlangt, wenn dieser vermieden werden kann.
Drei Kerndynamiken der KI-Entwicklung
Bevor ich auf politische Fragen eingehe, möchte ich drei wichtige Entwicklungen bei KI-Systemen vorstellen, die für das Verständnis der KI-Branche von entscheidender Bedeutung sind:
1. Skalierungsgesetze
Eine Grundregel im Bereich der KI ist, dass sich die Leistung des Modells mit zunehmendem Trainingsumfang stetig verbessert. Meine Mitbegründer und ich waren die ersten, die dieses Phänomen während unserer Arbeit bei OpenAI dokumentierten und validierten.
Einfach ausgedrückt: Wenn andere Bedingungen gleich sind, führt eine Erhöhung der Menge an Trainingsberechnungen (Computing) dazu, dass die KI bei verschiedenen kognitiven Aufgaben bessere Leistungen erbringt. Zum Beispiel:
- KI im Wert von 1 Mio. US-Dollar könnte möglicherweise 20 % der kritischen Programmieraufgaben lösen
- KI im Wert von 10 Millionen US-Dollar könnte 40 % der Probleme lösen
- KI im Wert von 100 Millionen US-Dollar kann möglicherweise 60 % der Probleme lösen
Diese Unterschiede werden enorme Auswirkungen auf die praktische Anwendung haben – eine Verzehnfachung der Berechnungen kann bedeuten, dass sich das KI-Niveau von Studenten bis hin zu Doktoranden verbessert. Infolgedessen investieren Unternehmen enorme Summen in die Ausbildung stärkerer Modelle.
2. Verbesserung der Recheneffizienz (Shifting the Curve)
Im Bereich der KI entstehen ständig verschiedene große und kleine Innovationen, die das KI-Training und die KI-Inferenz effizienter machen. Diese Innovationen können Verbesserungen der Modellarchitektur (z. B. Optimierung der Transformer-Struktur), effizientere Rechenmethoden (Verbesserung der Hardwareauslastung) und eine neue Generation von KI-Rechnerchips umfassen.
Diese Optimierungen werden die allgemeine Trainingseffizienz der KI verbessern, was als „Shifting the Curve“ bezeichnet wird:
Wenn eine bestimmte Technologie eine zweifache Rechenverbesserung mit sich bringt (Compute Multiplier, CM), dann kostet die Schulung der 40-prozentigen Code-Lösungsfähigkeit, deren Schulung ursprünglich 10 Millionen US-Dollar gekostet hat, nur noch 5 Millionen US-Dollar; die 60-prozentige Code-Lösungsfähigkeit, die ursprünglich 100 Millionen US-Dollar gekostet hat, kostet jetzt nur noch 50 Millionen US-Dollar.
Große KI-Unternehmen entdecken weiterhin solche CM-Verbesserungen:
- Kleine Optimierung (ca. 1,2-fach): Gemeinsame Feinabstimmungsoptimierung
- Mäßige Optimierung (ca. 2 Mal): Architekturverbesserungen oder Algorithmusoptimierungen
- Erhebliche Optimierung (ca. 10 Mal): großer technologischer Durchbruch
Da die Steigerung des KI-Intelligenzniveaus von äußerst hohem Wert ist, führt diese Effizienzsteigerung in der Regel nicht zu einer Reduzierung der gesamten Schulungskosten, sondern veranlasst Unternehmen vielmehr dazu, mehr Geld in die Schulung stärkerer Modelle zu investieren. Viele Menschen glauben fälschlicherweise, dass KI wie herkömmliche Produkte „zuerst teuer und dann billiger“ sein wird, aber KI ist kein Gut mit fester Qualität – wenn die Recheneffizienz verbessert wird, wird die Branche den Rechenverbrauch nicht reduzieren, sondern schneller eine stärkere KI anstreben.
Im Jahr 2020 veröffentlichte mein Team einen Artikel, in dem es heißt, dass die Verbesserungsrate der Recheneffizienz, die durch die Weiterentwicklung des Algorithmus erzielt wird, etwa 1,68-mal pro Jahr beträgt. Die aktuelle Rate könnte sich jedoch auf das Vierfache pro Jahr erhöht haben, und diese Schätzung berücksichtigt nicht die Auswirkungen von Hardware-Fortschritten.
3. Reduzierung der Inferenzkosten
Verbesserungen der Trainingseffizienz wirken sich auch auf die KI-Inferenz aus (d. h. auf den Rechenaufwand des Modells zur Laufzeit). In den letzten Jahren haben wir gesehen, dass die Kosten für Inferenz in der KI weiter gesunken sind, während sich die Leistung weiter verbessert hat. Beispielsweise übertrifft Claude 3.5 Sonnet (veröffentlicht 15 Monate nach GPT-4) GPT-4 in fast allen Benchmark-Tests, aber sein API-Preis beträgt nur 1/10 von GPT-4.

3. Paradigmenwechsel
Die Erweiterungsmethode des KI-Trainings ist nicht statisch. Manchmal ändern sich die Kernerweiterungsobjekte oder es werden während des Trainingsprozesses neue Erweiterungsmethoden eingeführt.
Zwischen 2020 und 2023 ist die Hauptausbaurichtung des KI-Trainings das Vortraining von Modellen. Diese Modelle werden hauptsächlich auf der Grundlage umfangreicher Internet-Textdaten trainiert, und auf dieser Grundlage wird ein kleiner Teil zusätzlicher Feinabstimmungstrainings durchgeführt, um bestimmte Fähigkeiten zu verbessern.
Mit Beginn des Jahres 2024 ist der Einsatz von Reinforcement Learning (RL)-Trainingsmodellen zur Generierung von Chain of Thought (CoT) zum neuen Schwerpunkt des KI-Trainings geworden.
Unternehmen wie Anthropic, DeepSeek und OpenAI (o1-Preview-Modell veröffentlicht im September 2024) haben herausgefunden, dass diese Trainingsmethode die Leistung des Modells bei bestimmten objektiv messbaren Aufgaben erheblich verbessern kann, insbesondere beim mathematischen Denken, bei Programmierwettbewerben und beim komplexen logischen Denken ähnlich wie Mathematik und Programmierung.
Das neue Trainingsparadigma verfolgt einen zweistufigen Ansatz, bei dem zunächst das traditionelle Vortrainingsmodell trainiert wird, um es mit grundlegenden Fähigkeiten auszustatten. Zweitens wird die Argumentationsfähigkeit des Modells durch Reinforcement Learning (RL) verbessert.
Da diese RL-Trainingsmethode noch neu ist, investieren derzeit alle Unternehmen weniger in die RL-Phase und befinden sich daher noch in der Anfangsphase der Skalierung. Eine Skalierung der Schulungsinvestitionen von nur 100.000 bis 1 Million US-Dollar kann zu enormen Leistungssteigerungen führen.
Unternehmen treiben den Ausbau der RL-Ausbildung zügig voran, die bald Hunderte Millionen oder sogar Milliarden Dollar erreichen soll. Derzeit befinden wir uns an einem einzigartigen „Kreuzungspunkt“, an dem das KI-Training einen wichtigen Paradigmenwechsel durchläuft, bei dem in kurzer Zeit schnelle Leistungsdurchbrüche erzielt werden können, da sich das RL-Training noch in einem frühen Expansionsstadium befindet.
Das Modell von DeepSeek
Die oben genannten drei großen KI-Entwicklungstrends können uns helfen, die kürzlich von DeepSeek veröffentlichten Modelle zu verstehen.
Vor etwa einem Monat hat DeepSeek „DeepSeek-V3“ auf den Markt gebracht, ein reines Pre-Training-Modell, das oben in Punkt 3 erwähnte Modell der ersten Stufe. Letzte Woche veröffentlichten sie dann „R1“, das eine zweite Trainingsstufe basierend auf V3 hinzufügte. Obwohl die internen Details dieser Modelle der Außenwelt nicht vollständig zugänglich sind, kann ich beide Markteinführungen am besten verstehen.
DeepSeek-V3 ist die eigentliche jüngste Innovation von DeepSeek und hat vor einem Monat Aufmerksamkeit verdient (und wir haben es damals auch bemerkt).
Als rein vorab trainiertes Modell liegt die Leistung von DeepSeek-V3 bei bestimmten Schlüsselaufgaben nahe an der Leistung der fortschrittlichsten KI-Modelle in den Vereinigten Staaten, aber die Trainingskosten sind viel geringer. (Wir haben jedoch festgestellt, dass das Claude 3.5 Sonnet bei einigen wichtigen Aufgaben, insbesondere bei der Programmierung in der realen Welt, immer noch deutlich besser war.)
Das DeepSeek-Team kann dies vor allem dadurch erreichen, dass es sich auf eine Reihe wirklich herausragender technischer Innovationen verlässt, insbesondere im Hinblick auf die Optimierung der Recheneffizienz, einschließlich der innovativen Optimierung des „Key-Value Cache“-Managements, das die Effizienz des Modells im Inferenzprozess verbessert, und der bahnbrechenden Anwendung der „Mixture of Experts (MoE)“-Technologie, die es ihm ermöglicht, in groß angelegten KI-Modellen eine bessere Leistung als je zuvor zu erzielen.
Wir müssen jedoch genauer analysieren:
DeepSeek hat „mit 6 Millionen US-Dollar nicht das erreicht, wofür amerikanische KI-Unternehmen Milliarden von Dollar ausgegeben haben“. Soweit ich für Anthropic sprechen kann, handelt es sich beim Claude 3.5 Sonnet um ein mittelgroßes Modell, dessen Ausbildung mehrere zehn Millionen Dollar kostet (die genaue Zahl verrate ich nicht). Darüber hinaus sind Gerüchte, dass beim 3.5 Sonnet-Training größere, teurere Modelle verwendet wurden, nicht wahr. Das Training von Sonnet wurde vor 9 bis 12 Monaten durchgeführt, während das Modell von DeepSeek zwischen November und Dezember letzten Jahres trainiert wurde.
Dennoch bleibt Sonnet in vielen internen und externen Bewertungen klarer Spitzenreiter. Daher sollte eine genauere Aussage lauten: „DeepSeek hat ein Modell zu relativ geringen Kosten trainiert, das nahe an der Leistung des US-Modells vor 7 bis 10 Monaten liegt, aber die Kosten sind bei weitem nicht so niedrig, wie die Leute sagen.“
Wenn den Trends der Vergangenheit zufolge die KI-Schulungskosten um etwa das Vierfache pro Jahr gesunken sind, können wir unter normalen Umständen – wie dem Kostenrückgangstrend in den Jahren 2023 und 2024 – davon ausgehen, dass die aktuellen Modellschulungskosten drei- bis viermal niedriger sein sollten als bei 3,5 Sonnet oder GPT-4o. Die Leistung von DeepSeek-V3 ist diesen hochmodernen amerikanischen Modellen immer noch unterlegen – etwa doppelt so schlecht (diese Schätzung ist für DeepSeek-V3 recht großzügig). Das heißt, wenn die Schulungskosten von DeepSeek-V3 achtmal niedriger sind als die des amerikanischen Spitzenmodells vor einem Jahr, ist das normal und entspricht dem Trend und ist kein unerwarteter Durchbruch.
Tatsächlich ist die Kostensenkung von DeepSeek-V3 sogar noch geringer als die Inferenzpreissenkung (10-fach) von GPT-4 auf Claude 3.5 Sonnet, die selbst sogar noch stärker ist als GPT-4. All dies zeigt, dass DeepSeek-V3 weder ein revolutionärer Durchbruch in der Technologie noch eine Änderung des Wirtschaftsmodells großer Sprachmodelle (LLM) ist, sondern nur ein normaler Fall im Einklang mit dem bestehenden Kostensenkungstrend.
Der Unterschied besteht darin, dass es dieses Mal ein chinesisches Unternehmen war, das die Führung bei der Realisierung der erwarteten Kostensenkung übernahm. Dies ist das erste Mal in der Geschichte und daher von großer geopolitischer Bedeutung. Allerdings werden amerikanische KI-Unternehmen diesem Trend bald folgen, und zwar nicht durch das Kopieren von DeepSeek, sondern weil sie selbst sich ebenfalls auf der etablierten Kostensenkungskurve bewegen.
Sowohl DeepSeek als auch amerikanische KI-Unternehmen verfügen jetzt über mehr Mittel und Chips als beim Training ihrer bestehenden Hauptmodelle. Diese zusätzlichen Chips werden zur Entwicklung neuer Modelltechnologien verwendet und werden manchmal zum Trainieren großer Modelle verwendet, die noch nicht veröffentlicht wurden oder mehrere Versuche zur Perfektionierung erfordern.
Es wurde berichtet (obwohl wir die Echtheit nicht bestätigen können), dass DeepSeek tatsächlich über 50.000 GPUs der Hopper-Generation⁶ verfügt, und ich schätze, dass dies etwa 1/2 bis 1/3 der Größe der GPUs großer US-amerikanischer KI-Unternehmen ist (diese Zahl ist beispielsweise zwei- bis dreimal kleiner als der „Colossus“-Cluster von xAI)⁷. Die Kosten für diese 50.000 Hopper-GPUs belaufen sich auf etwa 1 Milliarde US-Dollar.
Daher weist die Gesamtinvestition von DeepSeek als Unternehmen (nicht nur die Schulungskosten eines einzelnen Modells) keine große Lücke zu der der amerikanischen KI-Forschungslabore auf.
Es ist erwähnenswert, dass die Analyse der „Skalierungskurve“ tatsächlich etwas zu stark vereinfacht ist. Verschiedene Modelle haben ihre eigenen Eigenschaften und sind auf unterschiedliche Bereiche spezialisiert. Der Wert der Expansionskurve ist nur ein grober Durchschnitt und lässt viele Details außer Acht.
Soweit ich das Modell von Anthropic verstehe, ist Claude, wie ich bereits erwähnt habe, hervorragend in der Codegenerierung und der qualitativ hochwertigen Interaktion mit Benutzern, wobei viele es sogar für persönliche Beratung oder Unterstützung nutzen. In dieser Hinsicht und bei einigen anderen spezifischen Aufgaben kann DeepSeek einfach nicht vergleichen, und diese Lücken spiegeln sich nicht direkt in den Skalierungskurvendaten wider.
Die Veröffentlichung von R1 letzte Woche erregte große öffentliche Aufmerksamkeit und ließ den Aktienkurs von Nvidia um etwa 17 % fallen. Aber aus innovativer oder technischer Sicht ist der R1 bei weitem nicht so aufregend wie der V3.
R1 fügt lediglich eine zweite Trainingsstufe hinzu – Reinforcement Learning (dies wurde in Nr. 3 des vorherigen Abschnitts erwähnt), das im Wesentlichen eine Nachbildung der OpenAI-Methode in der o1-Version ist (der Umfang und die Wirkung der beiden scheinen ähnlich zu sein)⁸. Da wir uns jedoch noch in einem frühen Stadium der Skalierungskurve befinden, ist es möglich, dass mehrere Unternehmen ähnliche Modelle trainieren können, vorausgesetzt, sie verfügen über ein starkes vorab trainiertes Basismodell.
Die Kosten für das Training von R1 auf Basis der vorhandenen V3 können sehr gering sein. Daher befinden wir uns an einem interessanten „Schnittpunkt“, an dem mehrere Unternehmen Modelle mit hervorragenden Inferenzfähigkeiten trainieren können. Diese Situation wird jedoch nicht lange anhalten, da sich das Modell entlang der Expansionskurve weiter nach oben entwickelt, wird dieses Fenster der „unteren Schwelle“ bald enden.
Kontrollen bei Chip-Exporten nach China
Die obige Analyse ist eigentlich nur eine Vorbereitung auf das Thema, das mir wirklich am Herzen liegt – die Chip-Exportkontrolle nach China. In Kombination mit den vorherigen Fakten denke ich, dass die aktuelle Situation wie folgt aussieht:
Der Trend beim KI-Training geht dahin, dass Unternehmen immer mehr Geld investieren, um leistungsfähigere Modelle zu trainieren. Obwohl die Kosten für das Training von Modellen mit demselben Intelligenzniveau weiter sinken, ist der wirtschaftliche Wert von KI-Modellen so hoch, dass die Kosteneinsparungen fast sofort in das Training leistungsfähigerer Modelle reinvestiert werden, während die Gesamtausgaben auf dem gleichen hohen Niveau bleiben.
Wenn die von DeepSeek entwickelte Effizienzoptimierungsmethode nicht von amerikanischen Labors beherrscht wird, wird sie bald von Labors in den USA und China verwendet, um KI-Modelle im Wert von Milliarden Dollar zu trainieren. Diese neuen Modelle werden eine bessere Leistung erbringen als die Multimilliarden-Dollar-Modelle, deren Training ursprünglich geplant war, aber die Investition wird immer noch Milliarden von Dollar betragen, und diese Zahl wird weiter steigen, bis das Niveau der KI-Intelligenz die Fähigkeiten fast aller Menschen in fast allen Bereichen übersteigt.
Um eine solche KI zu bauen, die intelligenter ist als fast alle anderen, sind Millionen von Chips und mindestens mehrere zehn Milliarden Dollar an Finanzmitteln erforderlich. Die Realisierung wird höchstwahrscheinlich zwischen 2026 und 2027 erfolgen. Die jüngste Ankündigung von DeepSeek wird diesen Trend nicht ändern, da ihre Kostensenkungen immer noch im erwarteten Bereich liegen, der in den langfristigen Berechnungen der Branche seit langem berücksichtigt wurde.
Das bedeutet, dass sich die Welt zwischen 2026 und 2027 möglicherweise in zwei sehr unterschiedlichen Situationen befindet. In den Vereinigten Staaten werden mehrere Unternehmen definitiv über die benötigten Millionen Chips verfügen (zu einem Preis von mehreren zehn Milliarden Dollar). Die Frage ist, ob China auch Zugang zu Millionen von Chips haben wird⁹.
Wenn China Millionen von Chips erwerben kann, betreten wir eine bipolare Welt, in der sowohl die Vereinigten Staaten als auch China über leistungsstarke KI-Modelle verfügen, die die Entwicklung von Wissenschaft und Technologie in beispiellosem Tempo vorantreiben – was ich „Länder der Genies in einem Rechenzentrum“ nenne.

Aber eine bipolare Welt bleibt möglicherweise nicht lange im Gleichgewicht. Selbst wenn China und die Vereinigten Staaten in der KI-Technologie vorübergehend gleichwertig sind, investiert China möglicherweise mehr Talente, Gelder und Energie in die Anwendung der KI-Technologie im militärischen Bereich. In Verbindung mit Chinas riesiger industrieller Basis und militärisch-strategischen Vorteilen könnte dies es China ermöglichen, nicht nur die Vorherrschaft im Bereich der KI zu erlangen, sondern sogar in verschiedenen Bereichen auf der ganzen Welt die Führung zu übernehmen.
Wenn China nicht in der Lage ist, Millionen von Chips zu erwerben, werden wir zumindest vorübergehend in eine unipolare Welt eintreten, in der nur die Vereinigten Staaten und ihre Verbündeten über die fortschrittlichsten KI-Modelle verfügen. Ob diese unipolare Situation anhalten wird, ist ungewiss, aber es ist zumindest möglich, dass sich ein kurzer Vorsprung in einen langfristigen Vorteil verwandelt, da KI-Systeme zum Aufbau einer stärkeren KI beitragen¹⁰. In diesem Szenario könnten die Vereinigten Staaten und ihre Verbündeten eine entscheidende und langfristige Dominanz auf der Weltbühne erlangen.
Daher sind streng durchgesetzte Exportkontrollen¹¹ das einzig wirksame Mittel, um zu verhindern, dass China Millionen von Chips erhält, und sie sind auch der wichtigste Faktor dafür, ob die Welt letztendlich unipolar oder bipolar sein wird.

Der Erfolg von DeepSeek bedeutet nicht, dass die Exportkontrollen gescheitert sind. Wie ich bereits sagte, verfügt DeepSeek tatsächlich über beträchtliche Chipressourcen, daher ist es nicht verwunderlich, dass sie in der Lage waren, ein leistungsstarkes Modell zu entwickeln und zu trainieren. Ihre Ressourcen sind nicht stärker eingeschränkt als amerikanische KI-Unternehmen, und Exportkontrollen sind nicht der Hauptgrund für ihre „Innovation“. Sie sind einfach sehr gute Ingenieure, und das zeigt nur, dass China im Bereich der KI ein ernstzunehmender Konkurrent der USA ist.
Der Erfolg von DeepSeek bedeutet nicht, dass China jederzeit durch Schmuggel an die benötigten Chips kommen kann oder dass es Lücken in der Exportkontrolle gibt, die nicht geschlossen werden können. Ich glaube, dass Exportkontrollen nie dazu gedacht waren, China daran zu hindern, Zehntausende Chips zu beschaffen. Eine wirtschaftliche Aktivität im Wert von einer Milliarde US-Dollar lässt sich verbergen, aber eine Aktivität im Wert von 10 Milliarden US-Dollar oder gar einer Milliarde US-Dollar ist viel schwerer zu verbergen, und der heimliche Versand von Millionen von Chips kann körperlich äußerst schwierig sein.
Wir können uns auch die Arten von Chips ansehen, über die DeepSeek derzeit Berichten zufolge verfügt. Laut SemiAnalysis-Analyse sind die vorhandenen 50.000 KI-Chips von DeepSeek eine Mischung aus H100, H800 und H20.
- H100s unterliegen seit ihrer Einführung Exportkontrollen. Wenn DeepSeek also über H100s verfügt, müssen diese durch Schmuggel beschafft worden sein. (Es ist jedoch erwähnenswert, dass Nvidia erklärt hat, dass die KI-Fortschritte von DeepSeek „vollständig mit den Exportkontrollbestimmungen vereinbar sind“).
- Der H800 konnte im Rahmen der ursprünglichen Exportkontrollrichtlinie im Jahr 2022 noch exportiert werden, wurde jedoch nach der Aktualisierung der Richtlinie im Oktober 2023 verboten, sodass diese Chips möglicherweise vor Inkrafttreten des Verbots ausgeliefert wurden.
- H20, das weniger effizient beim Training, aber effizienter bei der Schlussfolgerung (Probenahme) ist, darf immer noch exportiert werden, aber ich denke, es sollte auch verboten werden.
Zusammenfassend lässt sich sagen, dass es sich bei den KI-Chips im Besitz von DeepSeek hauptsächlich um Chips handelt, die derzeit nicht verboten sind (aber verboten werden sollten), Chips, die vor dem Verbot erworben wurden, und eine kleine Anzahl von Chips, die durch Schmuggel erworben werden können.
Dies zeigt tatsächlich, dass die Exportkontrollen funktionieren und optimiert werden: Wenn die Exportkontrollen völlig wirkungslos wären, hätte DeepSeek wahrscheinlich inzwischen eine ganze Charge erstklassiger H100-Chips. Dies ist jedoch nicht der Fall, was zeigt, dass die Politik die Lücken nach und nach schließt. Wenn wir die Kontrollen schnell genug verschärfen, könnten wir verhindern, dass China Zugang zu Millionen von Chips erhält, was die Wahrscheinlichkeit erhöht, dass die Vereinigten Staaten ihre Führungsrolle in der KI behalten und eine unipolare Welt schaffen.
Was Exportkontrollen und die nationale Sicherheit der USA betrifft, möchte ich Folgendes klarstellen:
Ich betrachte DeepSeek selbst nicht als Rivalen und ziele auch nicht speziell auf dieses Unternehmen ab. In ihren Interviews wirken DeepSeek-Forscher wie kluge, neugierige Ingenieure, die einfach nur nützliche Technologien entwickeln wollen.
Exportkontrollen sind eines der wirksamsten Instrumente, die uns zur Verfügung stehen, um dies zu verhindern. Manche meinen, die Tatsache, dass die KI-Technologie immer leistungsfähiger und kostengünstiger werde, sei ein Grund, die Exportkontrollen zu lockern – doch das ist völlig unvernünftig.
Fußnote
- 1 Zur Modelldestillation: In diesem Artikel werde ich nicht auf Berichte darüber eingehen, ob DeepSeek westliche Modelle destilliert. Ich gehe allein aufgrund der Informationen im DeepSeek-Artikel davon aus, dass sie das Modell tatsächlich so trainiert haben, wie sie es angegeben haben.
- 2 Die Veröffentlichung von DeepSeek hat keine Auswirkungen auf Nvidia: Tatsächlich denke ich, dass die Veröffentlichung des DeepSeek-Modells offensichtlich keine negativen Auswirkungen auf Nvidia hat, und der daraus resultierende Rückgang des Nvidia-Aktienkurses um ca. 17 % verwirrt mich. Logischerweise wird die Veröffentlichung von DeepSeek auf Nvidia noch weniger Auswirkungen haben als auf andere KI-Unternehmen. Aber auf jeden Fall besteht der Hauptzweck meines Artikels darin, die Exportkontrollpolitik zu verteidigen.
- 3 Details zum Training von R1: Genauer gesagt handelt es sich bei R1 um ein vorab trainiertes Modell, das nur einen kleinen Teil des Reinforcement Learning (RL)-Trainings durchläuft, was bei Modellen vor dem Inferenzparadigmenwechsel üblich ist.
- 4 DeepSeek ist bei einigen spezifischen Aufgaben stark: Der Umfang dieser Aufgaben ist jedoch sehr begrenzt.
- 5 Zu den im DeepSeek-Papier erwähnten „Trainingskosten in Höhe von 6 Millionen US-Dollar“: Diese Daten werden im DeepSeek-Papier zitiert. Ich akzeptiere sie hier vorerst und bezweifle ihre Authentizität. Allerdings bezweifle ich die Legitimität dieses direkten Vergleichs mit den Schulungskosten US-amerikanischer KI-Unternehmen. 6 Millionen US-Dollar beziehen sich nur auf die Kosten für die Schulung eines bestimmten Modells, aber die Gesamtkosten für KI-Forschung und -Entwicklung sind viel höher als dieser Betrag. Darüber hinaus können wir uns der Echtheit der 6 Millionen US-Dollar nicht ganz sicher sein – obwohl der Maßstab des Modells überprüft werden kann, sind Faktoren wie die Anzahl der im Training verwendeten Token schwer zu überprüfen.
- 6 Korrektur zu den vorhandenen Chips von DeepSeek: In einigen Interviews habe ich einmal gesagt, dass DeepSeek „50.000 Stück H100“ hat, aber das ist eigentlich eine ungenaue Zusammenfassung relevanter Berichte, und ich möchte es hier korrigieren. H100 ist derzeit der bekannteste Hopper-Architektur-Chip, daher ging ich davon aus, dass sich der Bericht auf H100 bezog. Tatsächlich umfasst die Hopper-Serie aber auch H800 und H20, und DeepSeek verfügt über eine Mischung dieser drei Chips mit insgesamt 50.000 Chips. Auch wenn dieser Umstand nichts an der Gesamtsituation ändert, ist er dennoch einer Klarstellung wert. Ich werde die Probleme mit dem H800 und H20 detaillierter analysieren, wenn ich über Exportkontrollen diskutiere.
- 7 Es wird erwartet, dass sich die Chip-Kluft zwischen den USA und China in Computing-Clustern der nächsten Generation weiter vergrößern wird, vor allem aufgrund der Auswirkungen der Exportkontrollen.
8 Einer der Hauptgründe, warum R1 große Aufmerksamkeit erregt hat: Ich denke, ein Grund dafür, dass R1 große Aufmerksamkeit erregt hat, liegt darin, dass es das erste Modell ist, das dem Benutzer den Prozess der „Gedankenkette“ zeigt, während o1 von OpenAI nur die endgültige Antwort zeigt. DeepSeek zeigt, dass Benutzer an transparenten Argumentationsprozessen für KI interessiert sind. Um es klar auszudrücken: Dies ist lediglich eine Designentscheidung für die Benutzeroberfläche (UI) und hat nichts mit dem Modell selbst zu tun. - 10 Das Ziel der Exportkontrolle: Hier muss klar sein, dass das Ziel nicht darin besteht, China die Möglichkeit zu nehmen, vom technologischen Fortschritt der KI zu profitieren – KI-Durchbrüche in Wissenschaft, medizinischer Versorgung, Lebensqualität und anderen Bereichen sollten allen zugute kommen. Das eigentliche Ziel besteht darin, zu verhindern, dass diese Länder eine militärische Dominanz erlangen.
Im Anhang finden Sie die relevanten Links zum Bericht:
https://x.com/DarioAmodei/status/1884636410839535967
https://darioamodei.com/on-deepseek-and-export-controls
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo