
Sie können ChatGPT mit 2 GB Speicher ausführen! Diese im Inland hergestellte „kleine Stahlkanone“ wird es Huawei-OVs ermöglichen, den Engpass in ihrer KI-Erfahrung zu überwinden.

In dieser KI-Welle ist Wall-Facing Intelligence einer der wenigen großen Kopfmodellhersteller in China, der sich für das All-In-End-to-Side-Modell entscheidet.
Seit Wallface Intelligence im Februar die leistungsstarke kleine Stahlkanone 1.0 herausgebracht hat, wurde sie in den folgenden Monaten schrittweise aktualisiert. Unter anderem wurde das später veröffentlichte Open-Source-Modell MiniCPM-Llama3-V 2.5 vom Stanford AI-Team aufgrund seiner Stärke plagiiert Stärke.
Im April prognostizierte Zeng Guoyang, CTO von Wallface Intelligence, außerdem, dass Modelle auf GPT-3.5-Niveau innerhalb von ein oder zwei Jahren auf Mobilgeräten laufen können.
Die gute Nachricht ist, dass Sie nicht noch ein bis zwei Jahre warten müssen, denn das heute veröffentlichte MiniCPM 3.0 hat das Ziel erreicht, das bei der Veröffentlichung der ersten Generation kleiner Stahlkanonen gesetzt wurde: um den Betrieb von GPT-3.5-Level-Modellen zu ermöglichen das Gerät innerhalb dieses Jahres.

Mit nur 4B-Parametern übertrifft die Leistung von MiniCPM 3.0 die von GPT-3.5. MiniCPM 3.0 markiert auch die Ankunft des „geräteseitigen ChatGPT“-Moments.
Einfach ausgedrückt bedeutet die Einführung von MiniCPM 3.0, dass Benutzer in Zukunft schnelle, sichere und funktionsreiche lokale KI-Dienste nutzen können, ohne auf Cloud-Verarbeitung angewiesen zu sein, und ein reibungsloseres und privateres intelligentes Interaktionserlebnis erhalten.
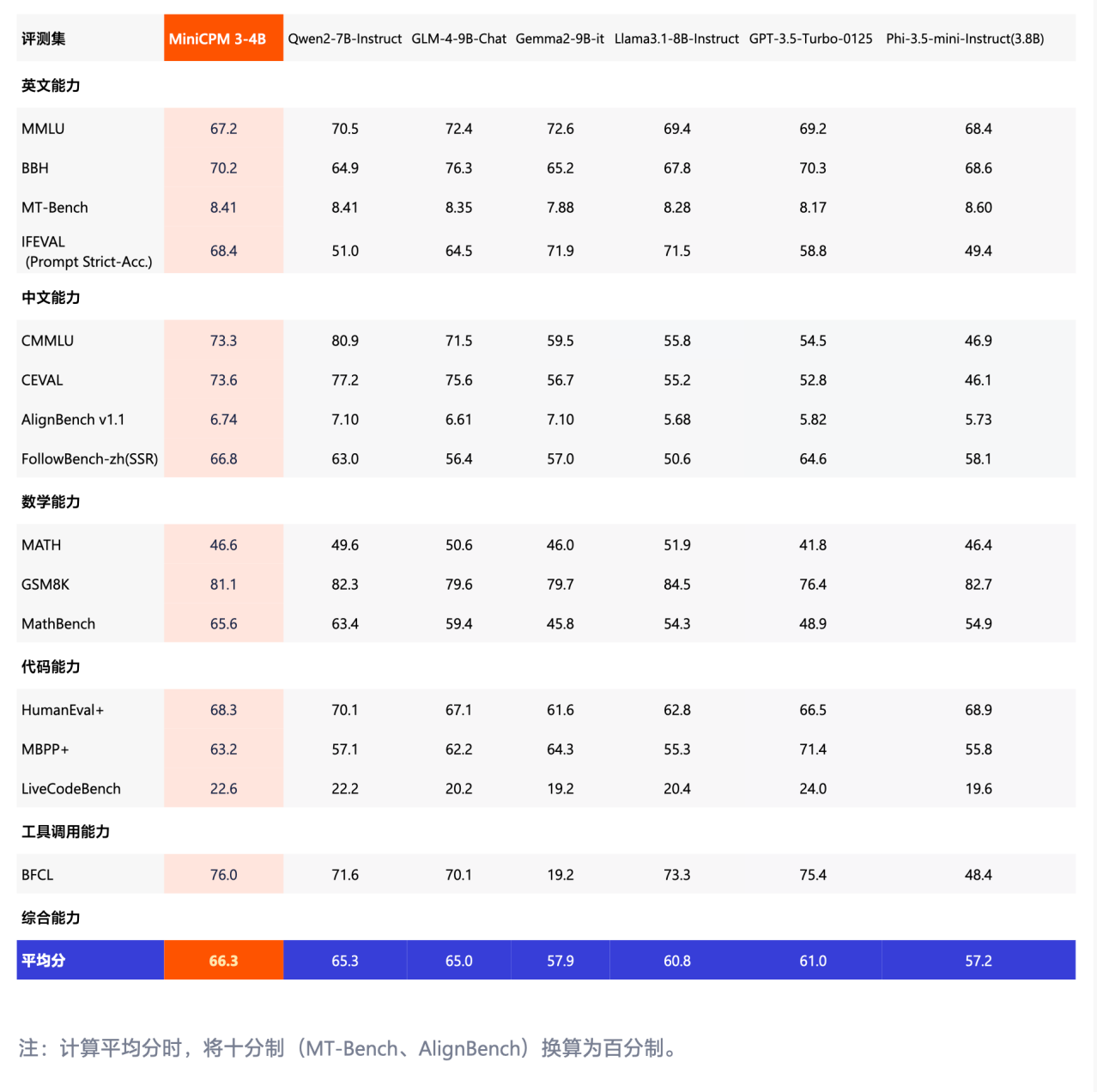
Nach den vom Beamten geteilten Benchmark-Tests zu urteilen, ist MiniCPM 3.0 der beste Benchmark-Test, der sich auf Chinesischkenntnisse konzentriert, wie CMMLU und CEVAL, und übertrifft Modelle wie Phi-3.5 und GPT-3.5 mit Leichtigkeit.
Selbst im Vergleich zu herausragenden inländischen Großmodellen wie 8B und 9B ist die Leistung von MiniCPM 3.0 immer noch hervorragend.
Fassen wir die Funktionen von MiniCPM 3.0 kurz zusammen:
- Unbegrenzter Text, Listenleistung übertrifft Kimi
- Der stärkste Funktionsaufruf auf der Endseite, mit einer Leistung, die mit GPT-4o vergleichbar ist
- Super leistungsstarkes dreiteiliges RAG-Plug-In-Set, chinesische Suche, zuerst Chinesisch und Englisch sprachübergreifend
Unbegrenzter Text, Leistung jenseits von Kimi
Klein, aber leistungsstark, klein, aber umfassend, das sind vielleicht die passendsten Adjektive für MiniCPM 3.0.
Die Kontextlänge ist ein wichtiges Merkmal, das die grundlegenden Fähigkeiten großer Modelle misst. Eine längere Kontextlänge bedeutet, dass das Modell mehr Informationen speichern und abrufen kann, was dem Modell hilft, Sprache genauer zu verstehen und zu generieren.
Eine längere Kontextlänge könnte es einem KI-Schreibtool beispielsweise ermöglichen, relevantere Vorschläge basierend auf dem, was der Benutzer zuvor geschrieben hat, bereitzustellen oder komplexere und ansprechendere Geschichten basierend auf kontextbezogeneren Informationen zu erstellen.
Zu diesem Zweck schlug Face Wall die LLMxMapReduce-Technologie zur Verarbeitung langer Artikelrahmen vor.
Dies ist eine Möglichkeit, einen unendlich langen Text zu erhalten, indem langer Kontext in mehrere Fragmente zerlegt wird, sodass das Modell ihn parallel verarbeiten, Schlüsselinformationen aus verschiedenen Fragmenten extrahieren und die endgültige Antwort zusammenfassen kann.

Es wird berichtet, dass diese Technologie im Allgemeinen die Fähigkeit des Modells verbessert, lange Texte zu verarbeiten. Auch wenn der Text länger wird, bleibt die Leistung stabil und der Punkteverlust bei langem Text wird verringert, wenn er länger wird.
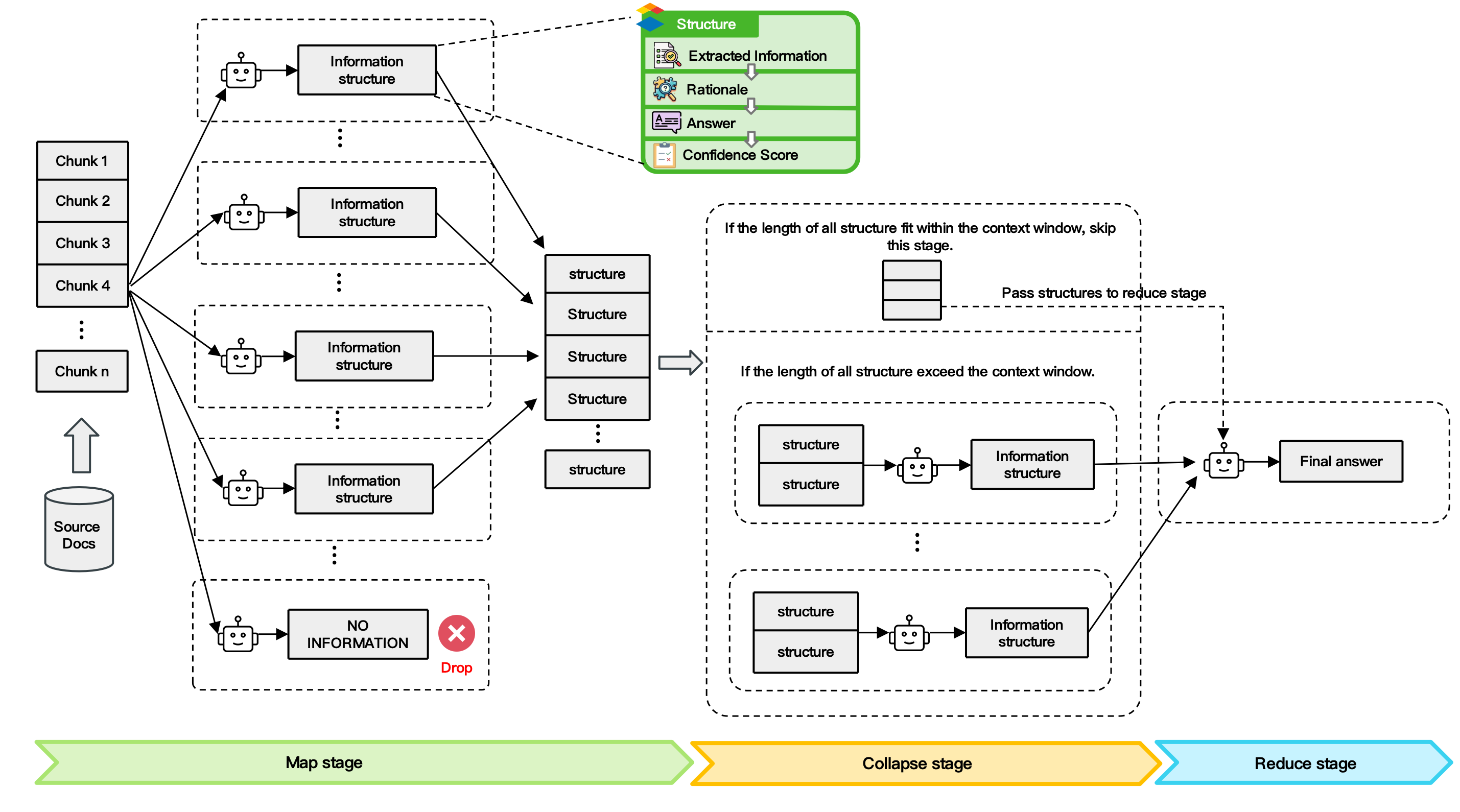
▲ Technisches Rahmendiagramm von LLMxMapReduce
Von 32 KB bis 512 KB kann MiniCPM 3.0 die Einschränkungen des großen Modellspeichers durchbrechen und die Kontextlänge unendlich und stabil erweitern. Mit den Worten der offiziellen Website ist es „so lang, wie Sie wollen“.
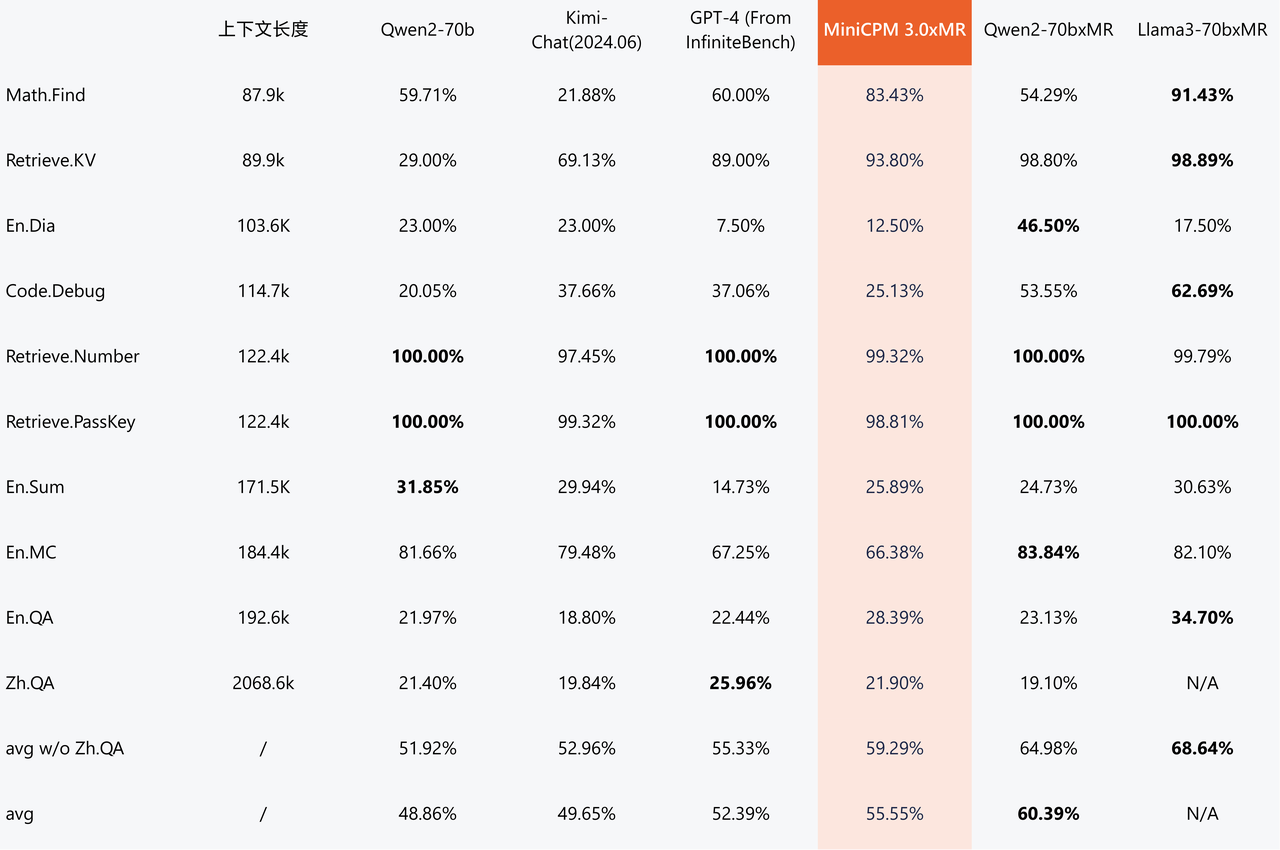
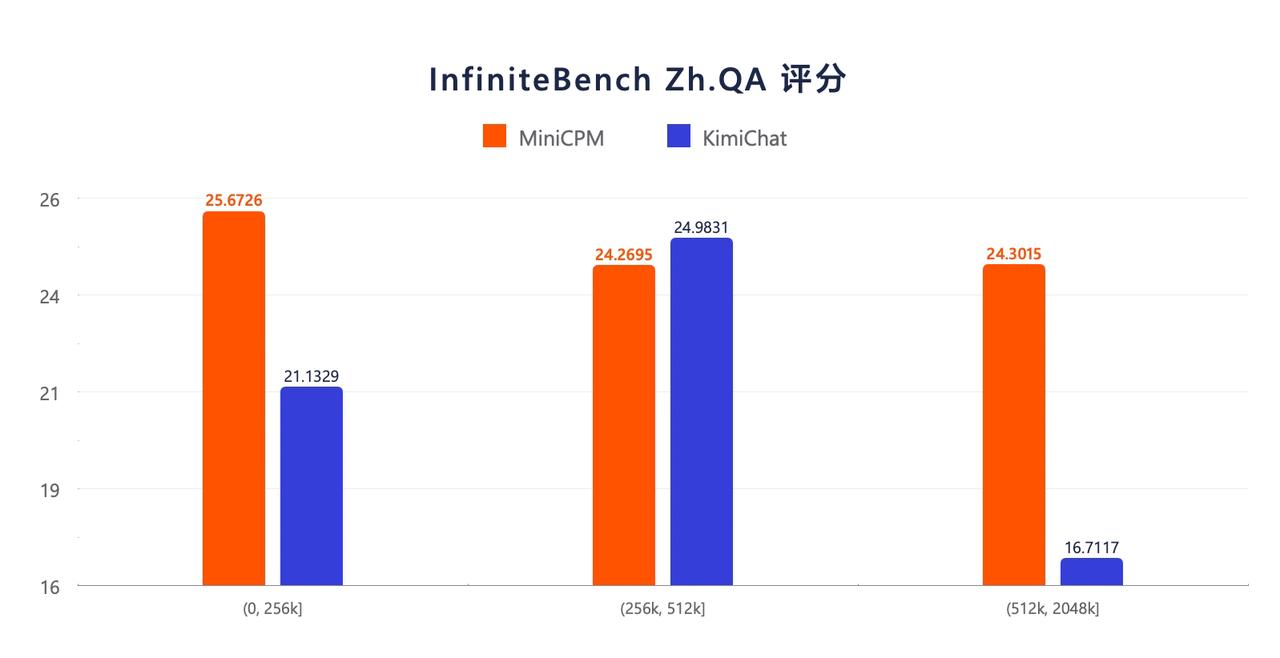
Den InfiniteBench-Benchmark-Testergebnissen großer Modelllangtexte zufolge wird der Leistungsvorteil von MiniCPM 3.0 mit 4B-Parametern mit zunehmender Textlänge immer offensichtlicher.
Die Bewertungsergebnisse von InfiniteBench Zh.QA zeigen, dass die Gesamtleistung von MiniCPM 3.0 mit 4B-Parametern besser ist als die von Kimi und eine relativ stärkere Stabilität bei längeren Texten aufweist.
Der stärkste Funktionsaufruf auf der Endseite, mit einer Leistung, die mit GPT-4o vergleichbar ist
In Interviews mit APPSO und anderen Medien sagte Zeng Guoyang auch, dass MiniCPM 3.0 einige Funktionen verbessert hat, die den Benutzern Sorgen bereiten, wie zum Beispiel das Hinzufügen vollständiger Systemaufforderungsfunktionsaufrufe und Code-Interpreterfunktionen.
Unter anderem kann Funktionsaufruf die Fuzzy-Eingabesemantik des Benutzers in strukturierte Anweisungen umwandeln, die die Maschine genau verstehen und ausführen kann, und ermöglicht die Verbindung großer Modelle mit externen Tools und Systemen.
Insbesondere das Aufrufen von Apps wie Kalender, Wetter, E-Mail, Browser usw. oder lokalen Datenbanken wie Fotoalben und Dateien auf dem Mobiltelefon per Sprache eröffnet unbegrenzte Möglichkeiten für Agentenanwendungen auf Endgeräten und macht die Mensch-Computer-Interaktion natürlicher und komfortabler .
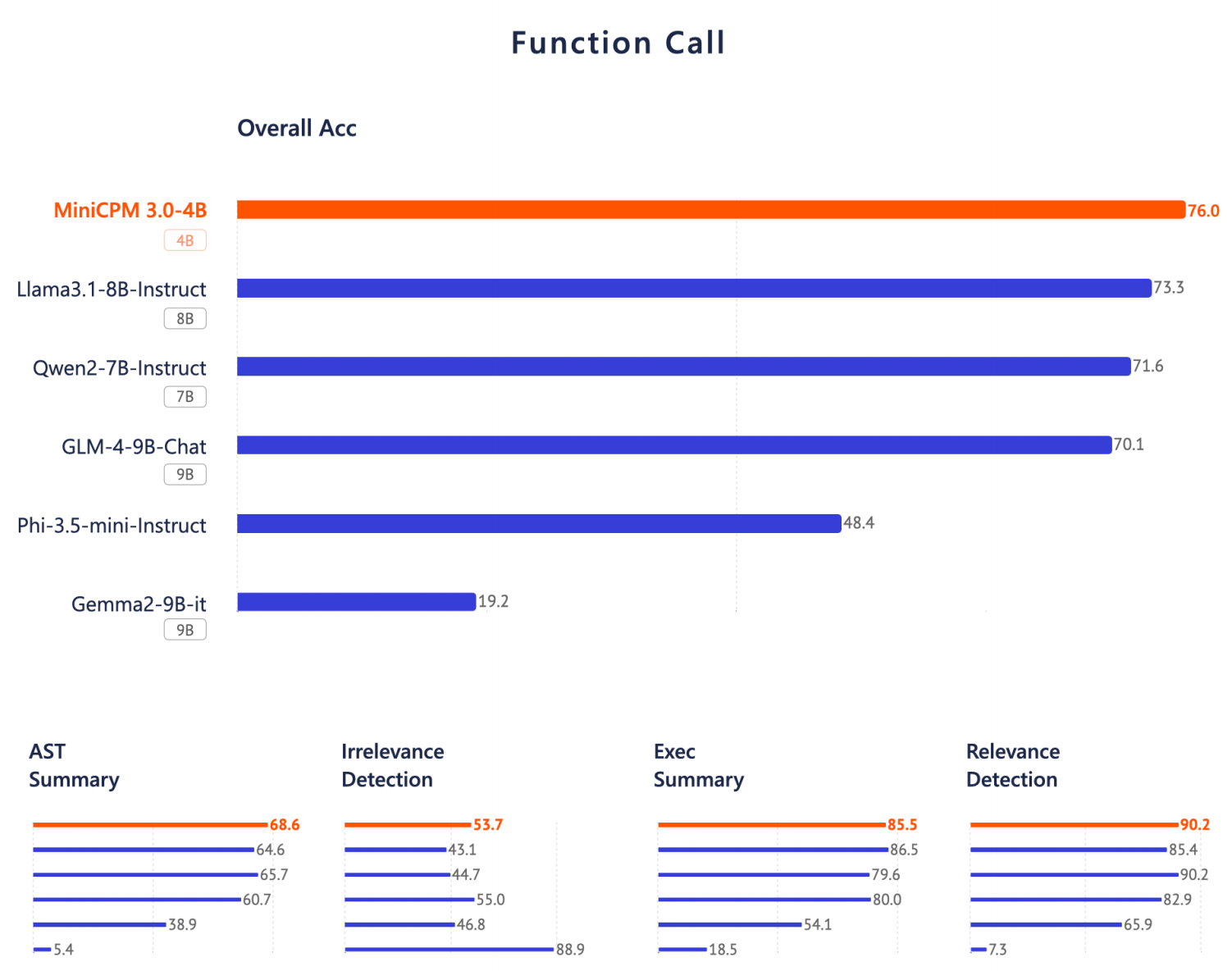
Berichten zufolge soll MiniCPM 3.0 die stärkste Funktionsaufrufleistung auf der Geräteseite haben. Auf der Berkeley Function-Calling Leaderboard-Liste liegt seine Leistung nahe bei GPT-4o und übertrifft Llama 3.1-8B, Qwen-2-7B und GLM-4-9B und viele andere Modelle.
Zeng Guoyang sagte, dass die vorhandenen Open-Source-Modelle diese Funktionen nicht vollständig abdecken. Normalerweise können nur einige große Cloud-Modelle diese Funktionen vollständig abdecken. Nun implementiert MiniCPM 3.0 auch einige entsprechende Funktionen.
Nehmen wir zum Beispiel RAG (Retrieval Augmented Generation), eine Technologie, die Information Retrieval (IR) und Natural Language Generation (NLG) kombiniert.
Es leitet den Textgenerierungsprozess durch den Abruf relevanter Informationen aus großen Dokumentbibliotheken, was die Genauigkeit und Zuverlässigkeit des Modells bei Aufgaben wie der Beantwortung von Fragen und der Textgenerierung verbessern und das Halluzinationsproblem großer Modelle verringern kann.
Für vertikale Branchen wie Recht und Medizin, die auf professionelle Wissensbasen angewiesen sind und eine äußerst geringe Toleranz gegenüber großen Modellillusionen haben, ist großes Modell + RAG in der Branche besonders praktisch.
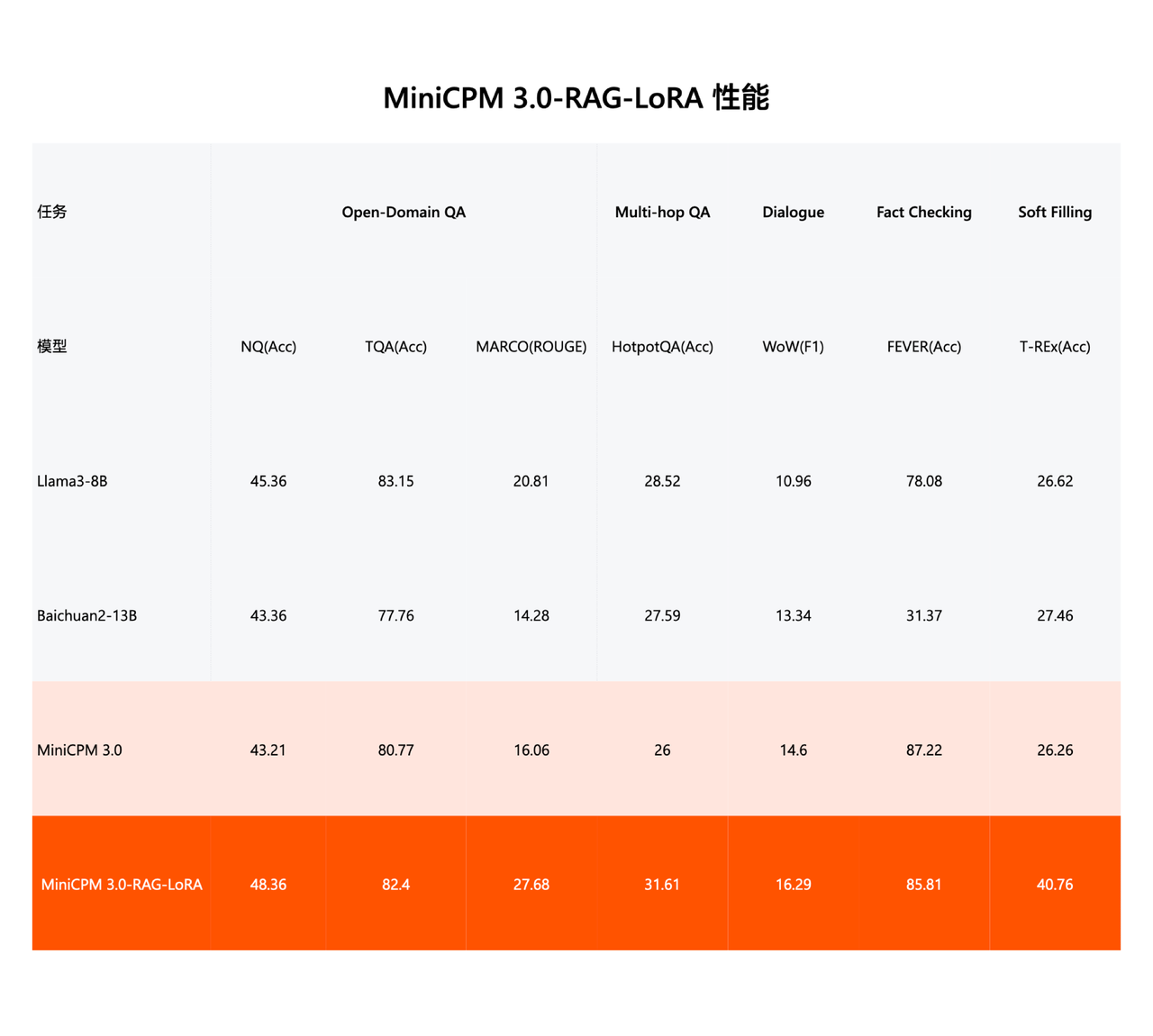
Mit MiniCPM 3.0 wurde das dreiteilige RAG-Set in einem Rutsch eingeführt: Retrieval-Modell, Reordering-Modell und LoRA-Plug-in für RAG-Szenarien.
MiniCPM-Embedding (Abrufmodell) hat beim sprachübergreifenden Abruf in Chinesisch und Englisch die SOTA-Leistung erreicht und belegt in der MTEB-Abrufliste, die die Texteinbettungsfunktionen des Modells bewertet, den ersten Platz in Chinesisch und den dreizehnten Platz in Englisch.
MiniCPM-Reranker (Reranking-Modell) erreichte SOTA-Leistung in den sprachübergreifenden Tests Chinesisch, Englisch und Chinesisch-Englisch.
Nach dem LoRA-Training für RAG-Szenarien schneidet MiniCPM 3.0-RAG-LoRA gut bei der Beantwortung offener Domänenfragen (NQ, TQA, MARCO), der Beantwortung von Multi-Hop-Fragen (HotpotQA), dem Dialog (WoW), der Faktenprüfung (FEVER) und dem Ausfüllen von Informationen ab (T-REx) und andere Leistungsaufgaben und übertrifft branchenführende Modelle wie Llama3-8B und Baichuan2-13B.
Die Modellanwendung wird implementiert. Führen Sie sie zunächst aus und sprechen Sie dann darüber
In einem Interview mit APPSO und anderen Medien erwähnte Li Dahai, CEO von Wall-Facing Intelligence, dass die Fähigkeit, Anwendungen auszuführen und wirklich reibungslos zu erstellen, zwei verschiedene Konzepte seien.
Das optimierte MiniCPM 3.0 hat einen sehr geringen Ressourcenbedarf für Endgeräte. Nach der Quantifizierung sind nur 2,2 G Speicher für das iPad erforderlich. Die endseitige Inferenz kann auch 18–20 Token/s erreichen.
Für mobile Geräte wie das iPad bedeutet die Verarbeitung von 18 bis 20 Token pro Sekunde bereits, dass das Modell Eingaben in natürlicher Sprache in Echtzeit verarbeiten kann.
Beispielsweise werden Benutzer bei Spracherkennungs- oder Echtzeitübersetzungsanwendungen grundsätzlich keine offensichtlichen Verzögerungen erleben und ein relativ reibungsloses interaktives Erlebnis genießen.
Darüber hinaus bieten die Modelle der MiniCPM-Serie als End-Side-Modelle im Vergleich zu Cloud-Modellen natürlich auch lokale Vorteile wie schwaches Netzwerk, Benutzerfreundlichkeit bei getrennter Verbindung, extrem niedrige Latenz sowie Datenschutz und Sicherheit.

Wenn Sie in der Nähe des Gongga-Schneebergs reisen und wissen möchten, wo Sie den „Rizhao-Jinshan-Berg“ am besten genießen können, und Ihr Netzwerk nicht gut ist, können Sie nach MiniCPM 3.0 fragen.
Oder wenn Sie ein Neuling im „Seegang“ sind, an der rauen Küste stehen, aber mit voller Ladung nach Hause zurückkehren möchten, können Sie genauso gut den Vorschlägen von MiniCPM 3.0 folgen. Wenn Sie in den Nachthimmel schauen und die Idee haben, Sternspuren einzufangen, kann Ihnen MiniCPM 3.0 auch die Details der Aufnahme mitteilen.
Hinter dem rasanten Fortschritt der MiniCPM-Kleinstahlkanonenserie steht das konsequente Grundprinzip effizienter Großmodelle.
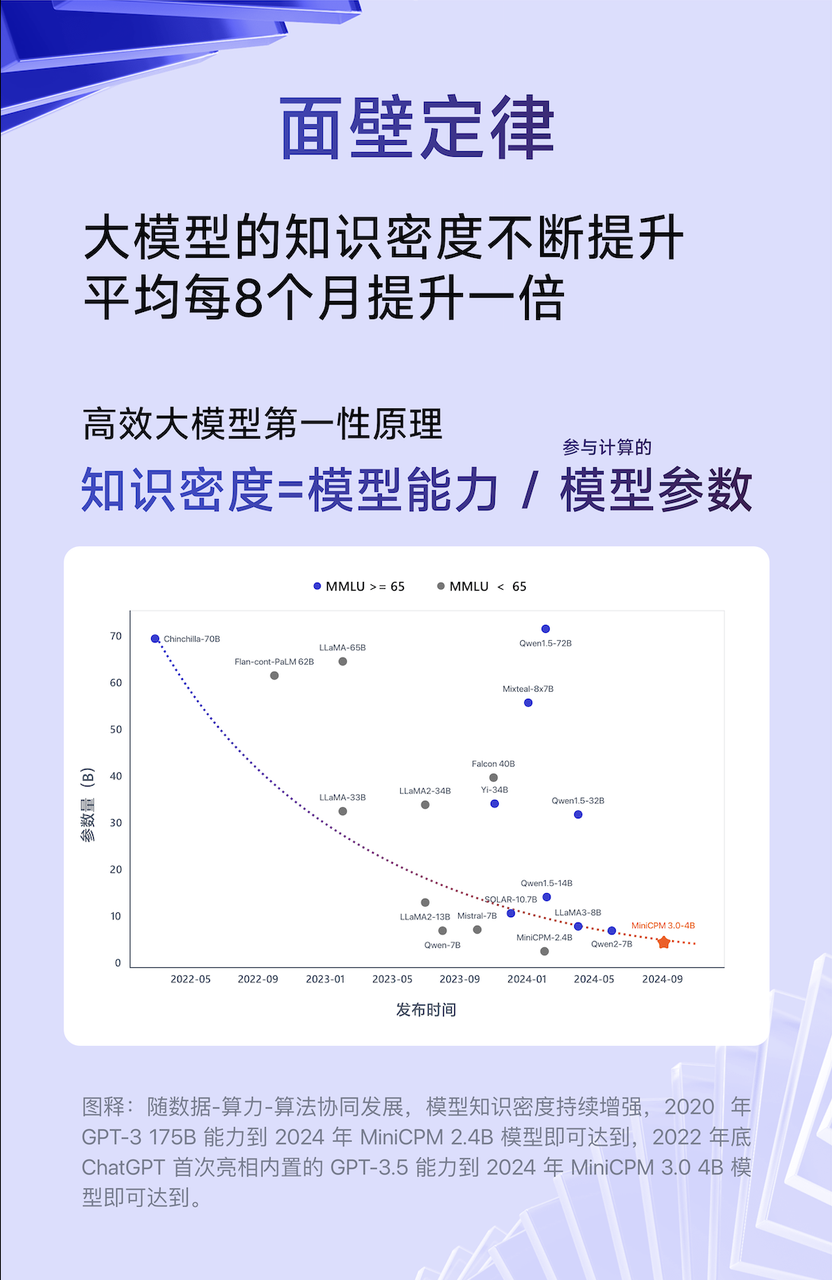
Liu Zhiyuan, Chefwissenschaftler von Wall-Facing Intelligence, schlug im Zeitalter großer Modelle einmal ein „Mooresches Gesetz“ vor, das besagt, dass sich die Wissensdichte großer Modelle durchschnittlich alle acht Monate verdoppelt.
Wissensdichte = Modellfähigkeit/Modellparameter, die an der Berechnung beteiligt sind
Da die Wissensdichte des Modells weiter zunimmt, wird die 175B-Fähigkeit von GPT-3 im Jahr 2020 durch das MiniCPM 2.4B-Modell im Jahr 2024 erreicht, und das integrierte GPT-3.5 von ChatGPT wird Ende 2020 auf den Markt kommen 2022, was durch das Modell MiniCPM 3.0 im Jahr 2024 erreicht wird.

Wenn MiniCPM auf dieser Grundlage die ultimative endseitige Leistung anstrebt, dann strebt MiniCPM-V die ultimative multimodale Innovationsleistung an. Der Fortschritt der wandorientierten kleinen Stahlkanone ist kein einseitiger Fortschritt, sondern die gleichzeitige Weiterentwicklung des Endes -seitige Dual-Flaggschiffe.
Nach ein oder zwei Jahren technischer Erkundung dringen große KI-Modelle allmählich in den Tiefwasserbereich der praktischen Anwendung vor.
Li Dahai glaubt, dass große Modelle zwei allgemeine Werte haben: Der Wert in einer Richtung besteht darin, die alte Welt aufzuwerten, und der Wert in der zweiten Richtung besteht darin, die neue Welt zu entdecken.
Ein typisches Beispiel ist beispielsweise die Integration des ChatGPT-Dienstes von Apple in Apple Intelligence.
Das Gleiche gilt für das geräteseitige Modell. In Szenarien wie Mobiltelefonen, Autos und PCs ist es besser, die Terminalhersteller gut zu bedienen und die Terminalhersteller dann das geräteseitige Modell verwenden zu lassen Ändern Sie das gesamte Erlebnis auf Systemebene.
Allerdings müssen Hersteller beim spannenden Sprung von der Technologie zum Produkt auch viel Zeit in die Integration von Nutzerbedürfnissen und Technologie investieren.
Wie Li Dahai sagte, gibt es das mobile Internet zwar schon seit der Einführung des iPhones, doch das wirkliche Wachstum und bewährte Anwendungen im großen Stil zeichneten sich erst einige Jahre später ab.

Tatsächlich hat die wandorientierte Intelligenz praktische Anwendungsszenarien untersucht.
Zuvor wurde das wandseitige MiniCPM-Endseitenmodell tatsächlich auf PCs, Tablets, Mobiltelefonen und anderen Bereichen ausgeführt.
Vor nicht allzu langer Zeit hat sich Wall-Facing Intelligence auch bei WAIC zusammengeschlossen, um die Entwicklung von Robotern zu beschleunigen und eine bahnbrechende Lösung für vollständige „verkörperte Intelligenz“ zu schaffen. Dies ist auch die branchenweit erste Demonstration eines effizienten End-Side-Modells, das auf einem humanoiden Roboter läuft um die physische Welt zu verstehen, zu argumentieren und mit ihr zu interagieren.
Li Dahai gab gegenüber APPSO und anderen Medien außerdem bekannt, dass Produkte, die mit intelligenten End-to-Side-Modellen für die Wandmontage ausgestattet sind, voraussichtlich noch vor Jahresende auf den Markt kommen werden.
Kurz gesagt: Durch wandorientierte Intelligenz werden hocheffiziente und leistungsstarke Großmodelle weiterhin in der Nähe der Benutzer platziert, sodass die Funktionen großer Modelle wie Elektrizität, allgegenwärtig, allgegenwärtig und sicher nach Belieben genutzt werden können.
Auf diese Weise können möglichst schnell mehr Menschen den Wert und die Funktion großer Modelle genießen.
MiniCPM 3.0 Open-Source-Adresse:
GitHub:  https://github.com/OpenBMB/MiniCPM
https://github.com/OpenBMB/MiniCPM
HuggingFace: https://huggingface.co/openbmb/MiniCPM3-4B
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo