
„Vorsprung verschaffen“ mit GPT-5! Google veröffentlicht das leistungsstärkste KI-Paket mit der teuersten KI-Mitgliedschaft aller Zeiten für 1.800 Yuan pro Monat

Am Tag vor der letztjährigen Google I/O hat OpenAI GPT-4o eingeführt.
Die Offensiv- und Defensivsituationen sind in diesem Jahr anders.
Vor einigen Tagen gab OpenAI bekannt, dass GPT-5 ein All-in-One-Produkt sein wird, das verschiedene Produkte integriert. Gerade eben hat Google diese Idee auf der I/O-Konferenz umgesetzt und direkt seinen leistungsstärksten KI-Familien-Bucket aller Zeiten hervorgeholt.
Von der Veröffentlichung der Modelle Gemini 2.5 Pro und Flash über den AI-Modus bis hin zu Veo 3, Imagen 4 und KI-Kits für Entwickler und Kreative hat Google den Weg vom Modell zum Produkt praktisch in einer Pressekonferenz zusammengefasst.
Genauer gesagt hat Google die derzeit heißesten KI-Anwendungsszenarien bereits in seinen Produktschnittstellen „vergraben“, sodass den Leuten klar wird, dass das Unternehmen immer noch einer der KI-Giganten der Welt mit der stärksten technischen Stärke und den stärksten Fähigkeiten zur ökologischen Integration ist.
Kein Wunder also, dass viele Internetnutzer nach der fast zweistündigen Pressekonferenz scherzten, dass eine große Zahl von Start-ups durch Google zugrunde gehen würden.
Es ist jedoch nicht schwer zu erkennen, dass sich einige Funktionen auf der Pressekonferenz noch im „Trailer“- und Teststadium im kleinen Maßstab befinden und möglicherweise noch weit von einer echten Implementierung entfernt sind.

Helfen Sie mir, in einem Rutsch „Tickets kaufen + Sitzplätze finden + Formulare ausfüllen“ zu können. Das neue KI-Suchvolumen von Google spielt verrückt.
KI schreibt die zugrunde liegende Logik der Suche neu.
Auf der letztjährigen I/O-Konferenz hat Google die Funktion „AI Overviews“ vorgestellt, die mittlerweile mehr als 1,5 Milliarden aktive Nutzer pro Monat hat.
Generative KI hat die Art und Weise, wie Menschen suchen, schrittweise verändert. Dies hat jedoch zur Folge, dass wir uns nicht mehr damit zufrieden geben, einfache Fragen in das Suchfeld einzugeben, sondern stattdessen komplexere, längere und multimodalere Fragen stellen.
Heute hat Google seine Bemühungen zur Integration von Suche und KI erneut verstärkt und mit dem AI Mode ein durchgängiges KI-Sucherlebnis eingeführt.
Wie Google-CEO Sundar Pichai erklärte, ist dies das leistungsstärkste KI-Suchformular, das Google je entwickelt hat. Es verfügt nicht nur über fortgeschrittenere Denk- und multimodale Verständnisfähigkeiten, sondern unterstützt auch eine eingehende Erkundung durch kontextbezogene Fragen und Weblinks.

Wenn ein Benutzer beispielsweise mit einer Suchanfrage konfrontiert wird, die eine komplexe Interpretation erfordert, kann der KI-Modus den Mechanismus der „Deep Search“ aktivieren, zwischen verschiedenen Informationen unterscheiden und in wenigen Minuten einen Zitationsbericht auf Expertenniveau erstellen, wodurch Sie Stunden an Recherchezeit sparen.
Gleichzeitig hat Google auch die multimodalen Funktionen von Project Astra in die Suche integriert, um die Echtzeit-Interaktivität der Suche weiter zu verbessern. Mit der Funktion „Live suchen“ können Benutzer einfach ihre Kamera einschalten, um Fragen zu stellen und in Echtzeit Feedback zu erhalten.
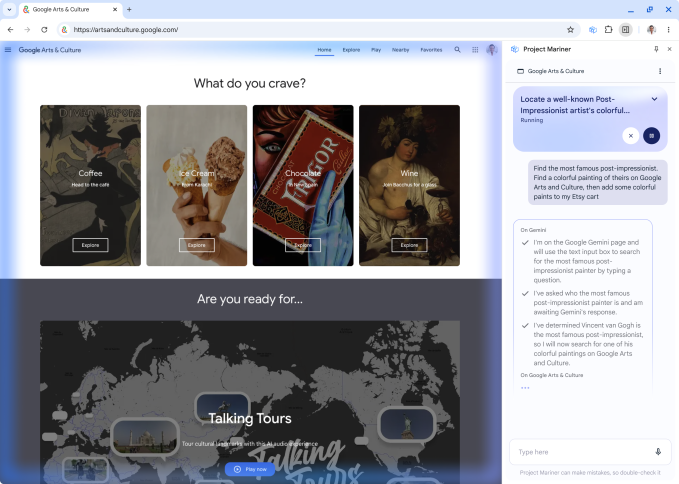
Dieses Jahr ist das erste Jahr von Agent und Google hat außerdem mit Bedacht die Funktion Project Mariner Agent eingeführt, um Benutzern dabei zu helfen, Aufgaben effizienter zu erledigen.
Mit nur einem Satz wie „Helfen Sie mir, zwei günstige Tickets für das Spiel an diesem Samstag im Untergeschoss zu finden“ kann der KI-Modus beispielsweise automatisch auf mehreren Ticketplattformen nach Optionen suchen, Preise und Lagerbestände in Echtzeit vergleichen und mühsame Vorgänge wie das Ausfüllen von Formularen übernehmen, wodurch die Effizienz erheblich gesteigert wird.
Der Google AI-Modus basiert auf dem Gemini-Modell und dem Google Shopping Graph und kann Ihnen dabei helfen, Ihre Produkte einzugrenzen und Inspiration zu bieten. Wenn Sie sehen möchten, wie Ihnen die Kleidung steht, laden Sie einfach ein Foto von sich hoch, um die Kleidung virtuell anzuprobieren.
Darüber hinaus verfügt der KI-Modus auch über leistungsstarke Personalisierungsfunktionen. Es kann auf der Grundlage kontextbezogener Benutzerpräferenzen individuelle Vorschläge bereitstellen und Diagramme und Visualisierungsergebnisse generieren, insbesondere bei der Suche im Sport- und Finanzbereich.
Diese Funktion ist jetzt in den USA vollständig eingeführt und wird in Zukunft auf weitere Regionen ausgeweitet.
Durch die Möglichkeit, Code zu schreiben und Token zu speichern, erhält Gemini 2.5 die Rolle des „Student Master“
In Bezug auf die Modellfunktionen veröffentlichte Google die I/O-Version von Gemini 2.5 Pro, die die Charts anführte.
Jetzt führt Gemini 2.5 Pro einen Inferenzverbesserungsmodus namens „Deep Think“ ein. Diese Funktion berücksichtigt mehrere Annahmen, bevor eine Antwort generiert wird, und ermöglicht so ein tieferes Verständnis des Kontexts der Frage.

2.5 Pro Deep Think belegte bei der United States Mathematical Olympiad (USAMO) 2025 und LiveCodeBench (Programmier-Benchmark) den ersten Platz und erreichte 84,0 % bei MMMU (Test des multimodalen Denkens).
Google teilte jedoch mit, dass man mehr Zeit in die Durchführung hochmoderner Sicherheitsbewertungen investieren und weiteren Rat von Sicherheitsexperten einholen werde. Als erster Schritt wird die Deep Think-Funktion derzeit über die Gemini-API einer kleinen Anzahl von Testern zugänglich gemacht.
Ebenfalls verbessert wurde der auf Effizienz ausgerichtete Gemini 2.5 Flash.
Die neue Version 2.5 Flash weist Verbesserungen bei wichtigen Benchmarks auf, beispielsweise bei Argumentation, Multimodalität, Code und langem Kontext. Gleichzeitig ist sie effizienter, da bei der Auswertung 20 bis 30 % weniger Token verwendet werden.
2.5 Flash ist jetzt für alle in der Gemini-App verfügbar und wird Anfang Juni allgemein für Entwickler über Google AI Studio und für Unternehmen über Vertex AI veröffentlicht.
In Bezug auf die Entwicklererfahrung werden 2.5 Pro und 2.5 Flash die Funktion „Gedankenzusammenfassung“ in Gemini API und Vertex AI einführen, die den Argumentationspfad des Modells strukturiert mit Titeln, Schlüsselinformationen und aufrufenden Tools darstellen kann.
Auch Entwickler profitieren davon. Google gab bekannt, dass es MCP-Tools in der Gemini-API und im SDK offiziell unterstützen wird, sodass Entwickler problemlos auf weitere Open-Source-Tools und Plug-in-Ökosysteme zugreifen können.
Musik, Filme und Bilder sind alle online verfügbar. Google hat KI zum Hit gemacht
Auf dieser Konferenz stellte Google eine neue Generation von Bild- und Videomodellen vor – Veo 3 und Imagen 4.
Im Gegensatz zur herkömmlichen Videogenerierung ist Veo 3 ein Videogenerierungsmodell, das Audio unterstützt. Es kann Verkehr, Vogelgesang und sogar Gespräche von Figuren in städtischen Straßenszenen simulieren und so das Gefühl des Eintauchens deutlich verstärken.
Das Modell generiert nicht nur Videos basierend auf Text- und Bildaufforderungen, sondern synchronisiert auch die physische Umgebung präzise mit der Lippensynchronisation, wodurch der Realismus der Videoerstellung erheblich verbessert wird.
Veo 3 ist derzeit für Ultra-Abonnenten auf der Gemini-App und der Flow-Plattform verfügbar und wird für Unternehmensbenutzer auf der Vertex AI-Plattform unterstützt.

Der oben erwähnte Flow ist ein von Google für Kreative entwickeltes KI-Filmtool.
Benutzer beschreiben Filmszenen einfach in natürlicher Sprache, um Schauspieler, Drehorte, Requisiten und Stil zu verwalten und automatisch Erzählsegmente zu generieren. Flow ist jetzt für Benutzer von Gemini Pro und Ultra in den USA verfügbar, die weltweite Einführung ist in Arbeit.
In Bezug auf die Bilderzeugung weist die neue Version von Imagen 4 eine verbesserte Genauigkeit und Geschwindigkeit auf und kann Stoffe, Wassertropfen und Tierhaare detailliert und realistisch darstellen, während gleichzeitig abstraktere Stile erzeugt werden können.
Es unterstützt 2K-Auflösung und mehrere Seitenverhältnisse und ist hinsichtlich Satz und Rechtschreibung deutlich optimiert, sodass es sich für die Erstellung von Grußkarten, Postern und sogar Comics eignet.
Imagen 4 ist heute in den Folien, Videos und Dokumenten von Gemini, Whisk, Vertex AI und Workspace verfügbar. Berichten zufolge soll künftig eine zehnmal schnellere Version auf den Markt kommen.

Im Bereich der Musikproduktion hat Google den Zugriff auf die Music AI Sandbox mit Lyria 2 erweitert und das interaktive Musikgenerierungsmodell Lyria RealTime eingeführt. Das Modell steht Entwicklern jetzt über API und AI Studio zur Verfügung.
Unter Berücksichtigung der Tatsache, dass von Veo 3, Imagen 4 und Lyria 2 generierte Inhalte weiterhin das SynthID-Wasserzeichen tragen, hat Google einen neuen SynthID-Detektor veröffentlicht.
Benutzer müssen Dateien nur hochladen, um festzustellen, ob sie SynthID-Wasserzeichen enthalten, die zum Schutz vor Fälschungen und zur Rückverfolgung der Quelle von KI-Inhalten verwendet werden.
Google möchte ein „Weltmodell“ erstellen, das Ihnen sogar bei der Erledigung von Aufgaben helfen kann?
Google hofft, Gemini zu einem „Weltmodell“ auszubauen, das alle Aspekte der realen Welt planen, verstehen und simulieren kann.
Demis Hassabis, CEO von Google DeepMind, sagte, diese Richtung sei eines der Kernkonzepte von Project Astra.

Im Laufe des letzten Jahres hat Google nach und nach Videoverständnis, Bildschirmfreigabe, Speicherfunktionen usw. in Gemini Live integriert. Jetzt wurde die neue Sprachausgabe von Gemini mit nativem Audio hinzugefügt, das natürlicher ist; Gleichzeitig werden auch die Gedächtnis- und Computernutzungsfähigkeiten verbessert.
Darüber hinaus untersucht Google auch, wie Agentenfunktionen genutzt werden können, um Menschen beim Multitasking zu unterstützen.
Dazu gehört beispielsweise das Projekt Mariner, das bis zu zehn Aufgaben gleichzeitig erledigen kann, etwa Informationsabfrage, Reservierung, Einkauf und Recherche. Es ist jetzt für Ultra-Benutzer in den USA verfügbar und wird bald in die Gemini-API und andere Kernprodukte integriert.
Eine große Anzahl neuer KI-Funktionen wird veröffentlicht. Wird ein echtes Killer-Feature entstehen?
NotebookLM gab gestern offiziell bekannt, dass es innerhalb von 24 Stunden nach seiner Einführung die Produktivitäts-App Nr. 2 und die App Nr. 9 insgesamt im App Store geworden sei.
Als wichtige Erkundung von Google im Bereich der KI-Notiztools bietet NotebookLM Funktionen wie Audioübersicht und Mindmapping.
Unter anderem unterstützen Audioübersichten derzeit über 80 Sprachen und diese Woche kündigte Google außerdem an, dass diese Funktion künftig noch individueller anpassbar sein wird. Die Länge der Zusammenfassung können die Benutzer nach Bedarf wählen, egal ob sie nur schnell überfliegen oder ausführlich lesen möchten.
Diese Funktion wird zunächst auf Englisch verfügbar sein und später auf weitere Sprachen erweitert werden.
Gleichzeitig reagiert Google auch auf die Wünsche der Nutzer nach visueller Darstellung und wird NotebookLM in Kürze um eine Videoübersichtsfunktion erweitern. Benutzer können Notizinhalte mit nur einem Klick in Lehrvideos umwandeln und so Informationen intuitiver vermitteln.

Auch im Bereich der KI-Programmierung brachte Google die neuesten Fortschritte von Jules mit.
Dieser autonome Codierassistent, der ursprünglich in Google Labs erschien, kann Code verstehen und Entwicklungsaufgaben wie das Schreiben von Tests, das Erstellen von Funktionen und das Beheben von Fehlern autonom erledigen. Es ist jetzt offiziell in die öffentliche Betatestphase eingetreten.

Darüber hinaus hat Google einen neuen Abonnementdienst eingeführt: Google AI Ultra.
Der Plan bietet professionellen Benutzern unbegrenzten Zugriff auf die leistungsstärksten Modelle und erweiterten Funktionen von Google. Es eignet sich für Profis wie Filmemacher, Entwickler, Kreativarbeiter usw. und kostet monatlich 249,99 US-Dollar.
Das Programm ist derzeit in den USA verfügbar und wird bald auf andere Länder ausgeweitet.

Tatsächlich mangelt es der KI heute nicht an Modellen oder Funktionen. Was wirklich selten ist, ist ein „Killerprodukt“, das in den Alltag integriert werden kann und wirklich in die Köpfe der Mainstream-Benutzer eindringt.
Google ist sich dessen durchaus bewusst und arbeitet hart daran, die Antwort zu finden.
Daher können wir sehen, dass Google auf dieser Pressekonferenz fast alles getan und alles erwähnt hat: von Text, Bildern, Videos, Musik bis hin zu Suche, Agenten und Kreativtools.
Die Karten wurden aufgedeckt und die Technologie ist vorhanden. Jetzt muss Google nur noch einen Schritt machen, der die wirklichen Schwachstellen des Benutzers trifft.
#Willkommen beim offiziellen öffentlichen WeChat-Konto von iFanr: iFanr (WeChat-ID: ifanr), wo Ihnen so bald wie möglich weitere spannende Inhalte präsentiert werden.