
Wallfacing Intelligence hat eine neue Finanzierungsrunde in Höhe von Hunderten Millionen Yuan abgeschlossen und die zweite Version von MiniCPM herausgebracht, einer leistungsstarken kleinen Stahlkanone

Die inspirierende Geschichte, aus einer kleinen Sache einen großen Unterschied zu machen, findet sich nicht nur in der Geschichte des Unternehmertums, sondern auch in groß angelegten End-to-End-Modellen.
Im Februar dieses Jahres veröffentlichte Wall-facing Intelligence offiziell das 2B-Flaggschiff-Endseiten-Großmodell Wall-facing MiniCPM, das nicht nur den Leistungsbenchmark der „europäischen Version von OpenAI“ übertraf, sondern insgesamt auch vor dem von Google Gemma lag 2B-Niveau und übertraf sogar 7B und 13B bei Modellen mit Lautstärkeniveau, wie z. B. Llama2-13B usw.
Kürzlich hat Wall-Facing Intelligence auch eine neue Finanzierungsrunde in Höhe von mehreren hundert Millionen Yuan abgeschlossen, angeführt von Chunhua Venture Capital und Huawei Hubble, gefolgt vom Beijing Artificial Intelligence Industry Investment Fund und anderen als strategischem Aktionär zu investieren und zu unterstützen, und setzt sich dafür ein, die Förderung der effizienten Schulung großer Modelle und der schnellen Anwendungsimplementierung zu beschleunigen.

Heute jagt die seitliche große, an der Wand ausgerichtete kleine Stahlkanone MiniCPM den Sieg und leitet die zweite Vier-Schuss-Serie ein. Das Hauptthema lautet „Klein, aber stark, klein, aber vollständig“.
Unter anderem hat das multimodale Modell MiniCPM-V2.0 seine OCR-Fähigkeiten erheblich verbessert und die beste OCR-Leistung von Open-Source-Modellen aufgefrischt. Der allgemeine Szenentext ist mit Gemini-Pro vergleichbar und übertrifft die gesamte Serie der 13B-Modelle.
In der Object HalBench-Liste, die große Modellillusionen bewertet, schneiden MiniCPM-V2.0 und GPT-4V nahezu gleich ab.
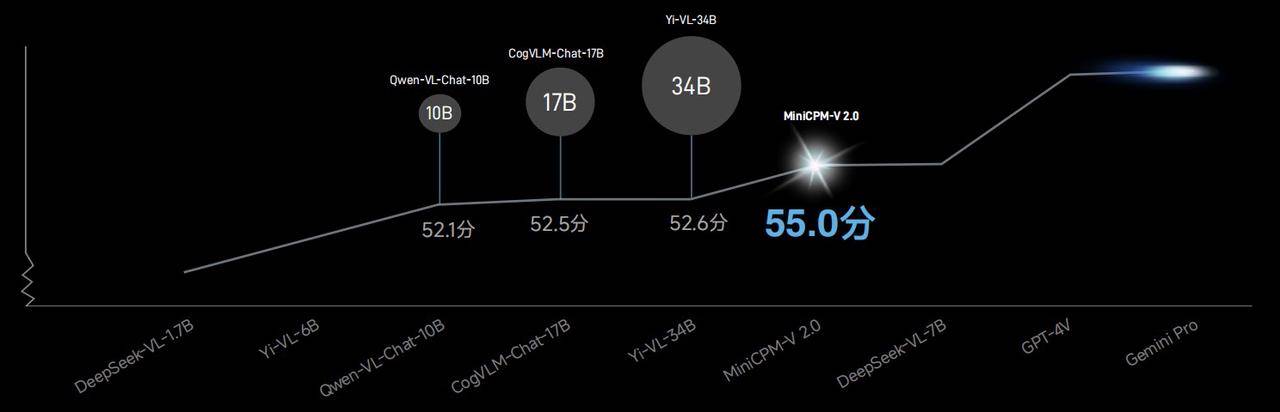
In der OpenCompass-Liste, die 11 gängige Bewertungsbenchmarks kombiniert, übertrifft die allgemeine Leistungsfähigkeit des multimodalen Modells MiniCPM-V2.0 Qwen-VL-Chat-10B, CogVLM-Chat-17B, Yi-VL-34B usw. mit einer Punktzahl von 55,0 Ein größeres Modell.
Im offiziellen Demonstrationsfall reagierte GPT-4V mit 6 Halluzinationen, als er gebeten wurde, die Szene desselben Bildes detailliert zu beschreiben, während MiniCPM-V2.0 nur 3 Halluzinationen hatte.

Darüber hinaus hat MiniCPM-V2.0 auch eine intensive Zusammenarbeit mit der Tsinghua-Universität gestartet, um gemeinsam den Schatz des Tsinghua-Universitätsmuseums – Tsinghua Slips – zu erkunden.
Dank seiner leistungsstarken multimodalen Erkennungs- und Argumentationsfunktionen kann MiniCPM-V2.0 problemlos damit umgehen, ob es sich um die Erkennung des einfachen Wortes „ke“ oder des komplexen Wortes „I“ handelt.
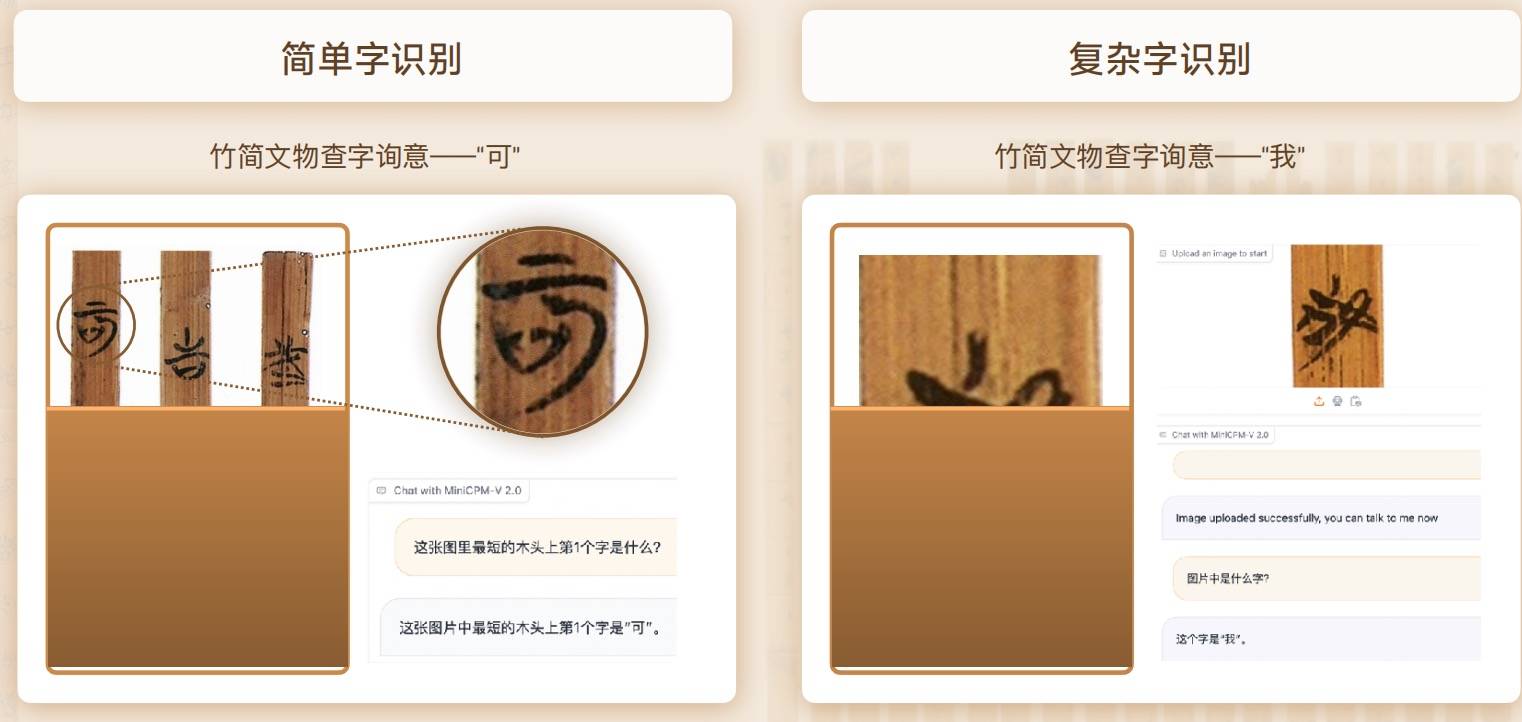
Im Wettbewerb mit ähnlichen chinesischen multimodalen Benchmark-Großmodellen liegt die Erkennungsgenauigkeit von MiniCPM-V2.0 weit vorne.
Die Erkennung präziser Details stellt höhere Anforderungen an die Klarheit von Bildern, und herkömmliche große Modelle können normalerweise nur kleine Bilder mit 448 x 448 Pixeln verarbeiten. Sobald die Informationen komprimiert sind, wird das Modell schwer zu lesen.
Für MiniCPM-V2.0 stellt dies jedoch kein Problem dar. Im offiziellen Demonstrationsfall kann MiniCPM-V2.0 wichtige Informationen auf einen Blick erfassen, ohne dass das bloße Auge sie erkennt. Auch „Family Mart“ lässt sich problemlos einfangen.

Lange Bilder enthalten Rich-Text-Informationen, und multimodale Modelle sind oft nicht in der Lage, lange Bilder zu erkennen, aber MiniCPM-V 2.0 kann die Schlüsselinformationen langer Bilder fest erfassen.

Von 448 x 448 Pixeln bis hin zu 1,8 Millionen hochauflösenden Großbildern und sogar dem ultimativen Seitenverhältnis von 1:9 (448 * 4032) kann MiniCPM-V 2.0 eine verlustfreie Erkennung erreichen.
Es versteht sich, dass die exklusive Technologie LLaVA-UHD tatsächlich hinter der effizienten Kodierung von hochauflösenden MiniCPM-V 2.0-Bildern verwendet wird.
- Modulare visuelle Kodierung: Das Bild mit Originalauflösung wird in Slices variabler Größe unterteilt, wodurch eine vollständige Anpassung an die Originalauflösung ohne Pixelauffüllung oder Bildverzerrung erreicht wird.
- Visuelles Komprimierungsmodul: Verwendet eine gemeinsame Perzeptron-Resampling-Schicht, um die visuellen Token von Bildausschnitten zu komprimieren. Die Anzahl der Token ist unabhängig von der Auflösung erschwinglich und die Rechenkomplexität ist geringer.
- Räumliche Modifikationsmethode: Verwenden Sie einfache Muster natürlicher Sprachsymbole, um die relativen Positionen von Bildausschnitten effektiv zu informieren.

Auch hinsichtlich der chinesischen OCR-Fähigkeiten übertrifft MiniCPM-V 2.0 GPT-4V deutlich. Verglichen mit der „Hilflosigkeit“ von GPT-4V ist seine Fähigkeit, Bilder genau zu identifizieren, noch wertvoller.
Hinter dieser Fähigkeit steht die Unterstützung modal- und sprachübergreifender Generalisierungstechnologie, die das Problem des Mangels an hochwertigen, groß angelegten multimodalen Daten im chinesischen Bereich lösen kann.
Die Fähigkeit, Langtexte zu verarbeiten, war schon immer ein wichtiges Kriterium für die Messung von Modellen.
Obwohl die Fähigkeit von 128K-Langtexten nichts Neues ist, ist dies für den MiniCPM-2B-128K, der nur 2B groß ist, auf jeden Fall etwas Lobenswertes.
Das kleinste 128K-Langtextmodell, MiniCPM-2B-128K-Langtextmodell, erweitert das ursprüngliche 4K-Kontextfenster auf 128K und übertrifft damit eine Reihe von 7B-Modellen wie Yarn-Mistral-7B-128K auf der InfiniteBench-Liste.

Durch die Einführung der MoE-Architektur hat sich die Leistung des neu veröffentlichten MiniCPM-MoE-8x2B MoE um durchschnittlich 4,5 % verbessert und übertrifft damit die gesamte Serie von 7B-Modellen und größeren Modellen wie LlaMA234B, während die Inferenzkosten nur 69,7 % von Gemma betragen. 7B.
MiniCPM-1.2B beweist, dass sich „klein“ und „leistungsstark“ nicht ausschließen.
Obwohl die direkten Parameter um die Hälfte reduziert wurden, behält MiniCPM-1.2B immer noch 87 % der Gesamtleistung des 2.4B-Modells der vorherigen Generation bei. In mehreren öffentlichen, maßgeblichen Testlisten ist das 1.2B-Modell sehr leistungsfähig und übertrifft die Gesamtleistung Qwen 1.8B und Qwen 1.8B. Hervorragende Ergebnisse mit Llama 2-7B und sogar Llama 2-13B.
Demonstration der Bildschirmaufzeichnung des MiniCPM-1.2B-Modells auf dem iPhone 15-Mobiltelefon, die Inferenzgeschwindigkeit wird um 38 % erhöht. Es hat 25 Token/s pro Sekunde erreicht, was 15 bis 25 Mal schneller ist als die menschliche Sprechgeschwindigkeit. Gleichzeitig wird der Speicher um 51,9 % reduziert, die Kosten werden um 60 % gesenkt und das Implementierungsmodell ist kleiner. aber die Nutzungsszenarien sind stark gestiegen.
Im Streben nach Modellen mit großen Parametern hat Face Wall Intelligence einen einzigartigen technischen Weg gewählt – so weit wie möglich Modelle mit kleinerer Größe und stärkerer Leistung zu entwickeln.
Die herausragende Leistung der zur Wand gerichteten kleinen Stahlkanone MiniCPM beweist voll und ganz, dass „klein“ und „stark“, „klein“ und „voll“ keine sich gegenseitig ausschließenden Attribute sind, sondern harmonisch nebeneinander existieren können. Wir freuen uns auch darauf, dass in Zukunft weitere solcher Modelle erscheinen.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo