
170.000 Raubkopien von Büchern sind das Geheimnis, wie „ChatGPTs“ intelligent werden

Der „echte Hammer“ ist endlich da.
Im Juli dieses Jahres wurden OpenAI und Meta von den drei amerikanischen Autoren Sarah Silverman, Christopher Golden und Richard Kadrey verklagt, mit der Begründung, dass die beiden Unternehmen ihre Bücher ohne Zustimmung des Autors als Materialien zum Trainieren großer Modelle verwendet hätten.

▲ Schauspielerin, Autorin Sarah Silverman und ihre Autobiografie, Bild aus Vulture
Beweis?
Im OpenAI-Fall konnte ChatGPT den Inhalt ihrer Bücher zusammenfassen, nachdem die Kläger kurze Worte eingegeben hatten.
Im Fall von Meta steht im Papier des Meta-Großmodells LLaMA, dass seine Trainingsdaten ein von EleutherAI organisiertes Material namens „ThePile“ enthalten.
„ThePile“ enthält auch einen Datensatz namens „Books3“, dessen Inhalt genau die Daten von Bibliotik sind, einer Online-Bibliothek für Raubkopien von Büchern.
Es ist ersichtlich, dass die damals vom Kläger vorgelegten Beweise relativ „indirekt“ waren.
Bisher hat Autor und Programmierer Alex Reisner offiziell verraten, welche Autorenbücher hinter Metas großem Vorbild gestohlen wurden.
Überraschend ist, dass diese „Beweise“ ständig an die Oberfläche gebracht, aber nicht aufgedeckt wurden. Warum?
Sogar die Ersteller der rechtsverletzenden Materialien haben immer darauf bestanden, dass dies eine „gerechte“ Sache sei.
170.000 Raubkopien von Büchern

▲ Bild von Interesting Engineering
Alex Reisners „großes Projekt“ entstand aus Neugier:
Als Autor und Computerprogrammierer war ich schon immer neugierig, auf welchen Büchern generative KI-Systeme trainiert werden.
Diesen Sommer begann Reisner, in Communities wie GitHub und Hugging Face nach Antworten zu suchen, und fand schließlich den oben erwähnten Open-Source-Datensatz „ThePile“.
Das Herunterladen auf „ThePile“ bedeutet jedoch nicht, dass Sie wissen, welche Bücher sich in „Books3“ befinden.
Da „ThePile“ über 800 GB verfügt, ist es zu groß, als dass normale Texteditoren es überhaupt lesen könnten. Reisner hat eine Reihe von Programmen geschrieben, um die Informationen aus „Books3“ extrahieren zu können.

▲ Bild von Unsplash
Unerwarteterweise gibt es in den extrahierten Informationen keine Daten mit Tags wie „Buchtitel“ und „Name des Autors“ und alles ist nur „Text“.
Also schrieb Reisner ein weiteres Programm, um die ISBN-Nummer (International Standard Book Number) aus den Daten zu extrahieren und verglich die Daten mit anderen Online-Buchdatenbanken, um die spezifischen Bücher zu identifizieren, die in „Books3“ enthalten sind.
Am Ende wurden in diesem Schritt 190.000 ISBN-Codes gefunden, 170.000 entsprechende Buchtitel identifiziert (die tatsächliche Anzahl der Bücher kann etwas geringer sein, da es verschiedene Ausgaben desselben Buches gibt) und weitere 20.000 Codes konnten nicht gefunden werden entsprechenden Buchtitel.
Etwa ein Drittel dieser Bücher sind Belletristik und zwei Drittel Sachbücher von großen und kleinen Verlagen.
Ja, zu diesen identifizierten Büchern gehören auch die Bücher der drei Autoren, die OpenAI und Meta zu Beginn des Artikels verklagt haben. Man kann also sagen, dass Metas LLaMA Raubkopien von Büchern als Schulungsmaterial verwendet hat, was einen sehr direkten Beweis erbracht hat.
Darüber hinaus können wir auch Elena Ferrante, Autorin von „My Brilliant Girlfriend“, Margaret Atwood, Autorin von „The Handmaid's Tale“, Stephen King, Haruki Murakami, berühmte Speisen und Getränke, zahlreiche Werke des Autors Michael Pollan und den Thrillerautor James Patterson sehen , und andere.

▲ Margaret Atwood und mehr als 8.000 Autoren haben außerdem einen gemeinsamen Brief geschrieben, in dem sie KI-Unternehmen dazu auffordern, die Genehmigung von Autoren einzuholen, bevor sie Bücher als Schulungsmaterialien verwenden dürfen. Das Bild stammt von „The Independent“
Neben Büchern berühmter Autoren fand Reisner auch 102 Pulp-Romane von Ron Hubbard, dem Gründer von Scientology, und 90 Bücher von John F. Arthurs Buch sowie mehrere Werke von Erich von Däniken, einem Befürworter der „Alien-Creation-Theorie“. ".
Reisner wies im „Atlantic Monthly“-Artikel darauf hin, dass der „Books3“-Datensatz zwar außerhalb der KI-Community nicht sehr bekannt, in der Community aber recht beliebt sei. „Er kann heruntergeladen werden, ist aber etwas schwer zu finden.“ . Wenn Sie durchsuchen und analysieren möchten, ist dies gleichermaßen eine Herausforderung.“
Es ist das erste Mal, dass Reisner so viel Zeit damit verbracht hat, ein Programm zur Analyse des Vergleichs zu schreiben, außerdem sorgfältig einen Artikel verfasst und ihn in den Massenmedien veröffentlicht hat.
Gleichzeitig unterstützt der KI-Kreis stillschweigend „Books3“, denn nach den Worten des Schöpfers von „Books3“ handelt es sich um eine wichtige Ressource, um sicherzustellen, dass die Entwicklung generativer KI nicht monopolisiert wird von großen Unternehmen.
„Feuerdieb“ oder „Dieb“?

▲Das Bild stammt aus „The Atlantic Monthly“
Es wäre in der Tat besser, wenn wir so etwas wie Books3 nicht bräuchten.
Aber ohne Books3 kann nur OpenAI das tun, was sie tun.
Der Indie-Entwickler Shawn Presser, der Schöpfer von „Books3“, sagte zu Reisner.
Presser begann mit der Erstellung von Books3, um allen Entwicklern „Trainingsdaten auf OpenAI-Ebene“ bereitzustellen.
Im Jahr 2020 lud Presser eine Kopie von Bibliotik herunter und schrieb ein Programm um, das der Hacker Aaron Swartz vor mehr als einem Jahrzehnt geschrieben hatte, um alle Bücher im ePub-Format in einfachen Text umzuwandeln – ein Format, das besser für große Modelle geeignet ist.
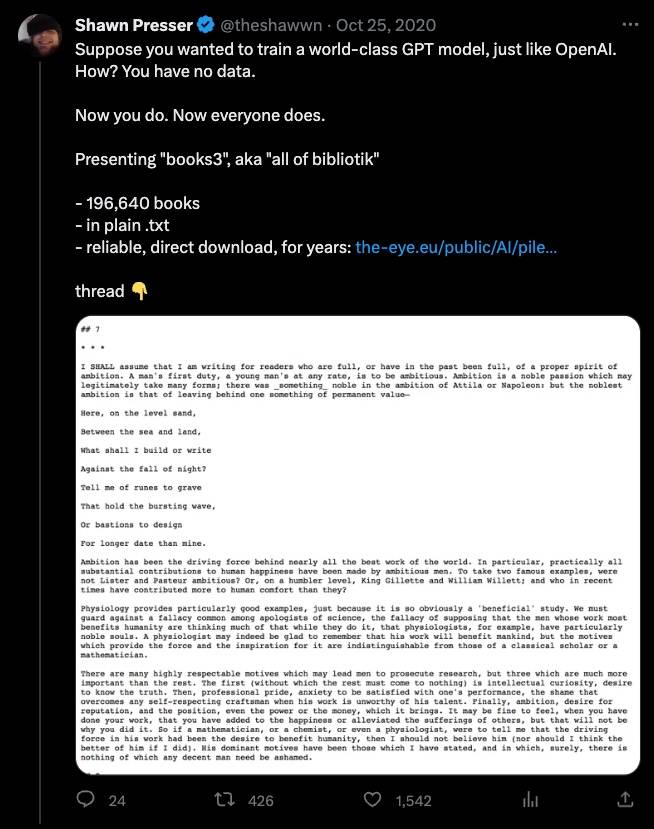
Was das Fehlen von Copyright-Informationen für einige Bücher im Datensatz betrifft, sagte Presser, dass dies ein unerwartetes Ergebnis der Konvertierung und keine Absicht sei.
Der Name „Books3“ spiegelt auch die von OpenAI erwähnten „Books1“ und „Books2“ wider.
Im Jahr 2020 wurde in einem Artikel von OpenAI darauf hingewiesen, dass die Trainingsdaten von GPT-3 zwei Sammlungen internetbasierter Buchdaten umfassen.
Aufgrund seiner Größe wird vermutet, dass die „Books1“-Daten von OpenAI vom „Project Gutenberg“ stammen – einem Projekt, das sich auf das Sammeln von Buchressourcen spezialisiert hat, deren Urheberrecht abgelaufen ist.
Der Inhalt von „Books2“ ist unbekannt, und einige Leute haben aufgrund der Größe vermutet, dass es den Daten von Bibliotik oder der Online-Raubkopienbibliothek von Libgen ähnelt.
Natürlich nutzte GPT-3 damals neben den Buchdaten auch andere Daten wie Wikipedia und andere Textinformationen aus dem Internet.
Deshalb enthält „ThePile“, das von EleutherAI integriert wurde, auch viele andere Daten, wie Wikipedia, Untertitel von YouTube-Videos, Dokumente und Stenografien des Europäischen Parlaments und so weiter.
Dennoch erscheint der qualitativ hochwertige Text von Büchern im Vergleich immer noch wichtig.
Meta sagte , dass das ursprüngliche Großmodell LlaMA-65B keine gute Leistung erbrachte, hauptsächlich weil es „eine begrenzte Anzahl von Büchern und wissenschaftlichen Arbeiten verwendete“.
Das MIT-Cornell-Papier weist außerdem darauf hin, dass Bücher bei großen Modelltrainingsdaten „den stärksten positiven Effekt auf die nachgelagerte Leistung haben“.
Daher werden wir „ThePile“ und „Books3“ in den LlaMA 2-Trainingsdaten sehen, die später von Meta veröffentlicht werden.

▲ Bild von CNN
Aus diesem Grund war Presser empört, als Books3 kürzlich nach einer Beschwerde der dänischen Anti-Piraterie-Gruppe Rights Alliance geschlossen wurde .
Seiner Ansicht nach nutzen alle großen, gewinnbringenden Unternehmen die rechtsverletzenden Inhalte, um ihre eigenen großen Modelle privat zu trainieren. Da sie ihre Trainingsdaten jedoch nicht offenlegen, kann niemand sie verklagen.
Allerdings wurde Books3 gerade deshalb aus dem Regal genommen, weil er das große Modell offener und transparenter machen wollte und die Datenquelle aktiv offenlegte.
Presser betonte, dass wir nicht zulassen dürfen, dass große Unternehmen mit großen finanziellen Mitteln diese wichtige Technologie, die unsere Kultur umgestaltet, monopolisieren, sondern dass jeder über die Ressourcen verfügt, seine eigenen großen Modelle zu entwickeln :
Mein Ziel ist es, diese großen Modelle für jedermann zugänglich zu machen (zu bauen).
Sofern der Autor des Buches keine Möglichkeit hat, ChatGPT offline zu schalten oder ihn zur Schließung zu verklagen, ist es sehr wichtig, dass Sie und ich unser eigenes ChatGPT erstellen können.
Genau wie in den 90er Jahren gilt es sicherzustellen, dass jeder seine eigene Website einrichten kann.
Es ist nicht unmöglich, ChatGPT offline zu verklagen.
Jeder verklagt die KI-Giganten

▲ OpenAI ist nicht mehr „offen“ und nicht transparent. Das Bild stammt von Politico
Die vom Star-Autor eingeleitete Klage mag mehr Aufmerksamkeit erregen, aber es sind die traditionellen Nachrichtenmedien, die das Potenzial haben, ChatGPT wegen „Neugestaltung“ zu verklagen.
Letzte Woche berichtete NPR unter Berufung auf mit der Angelegenheit vertraute Personen, dass die New York Times erwäge, OpenAI zu verklagen.
In den letzten Wochen hat die New York Times eine Lizenzvereinbarung mit OpenAI ausgehandelt. Die Verhandlungen schienen jedoch nicht gut zu laufen, sodass die New York Times darüber nachdachte, OpenAI wegen Urheberrechtsverletzung zu verklagen.
Dem Bericht zufolge sieht das Urheberrechtsgesetz des Bundes vor, dass Täter für jeden „vorsätzlichen“ Verstoß mit einer Geldstrafe von bis zu 150.000 US-Dollar belegt werden können. In Kombination mit der Anzahl der Artikel in der New York Times kann diese Summe „für ein Unternehmen fatal sein“.
Wenn der Richter außerdem entscheidet, dass OpenAI den Artikel der New York Times illegal zum Trainieren eines großen Modells verwendet hat, kann das Gericht OpenAI auch anweisen, den ChatGPT-Datensatz zu zerstören, wodurch es gezwungen wird, ChatGPT nur mit autorisierten Werken neu zu trainieren und zu erstellen.

▲ Bild von BrookField
Unabhängig davon, ob der Kläger die New York Times oder ein Buchautor ist, wird der Erfolg dieser Klagen (oder potenzieller Klagen) davon abhängen, ob die KI-Giganten die Verwendung dieser Informationen als „faire Verwendung“ bezeichnen können – also unter bestimmten Voraussetzungen Unter bestimmten Umständen kann die unbefugte Nutzung bestimmter Werke gestattet sein, beispielsweise für Lehr-, Kommentar-, Forschungs- und Berichterstattungszwecke.
Es gibt zwei Argumente für „Fair Use“:
- Generative KIs reproduzieren nicht die Bücher selbst, an denen sie trainiert wurden, sondern erstellen neue Inhalte;
- Diese neuen Inhalte werden dem Markt des Originalwerks keinen Schaden zufügen.
Jason Schultz, Direktor der Technology Law and Policy Clinic der New York University, sagt, das Argument sei stichhaltig, wenn es um Buchdiebstahl geht.
Die Anwälte der New York Times bestanden jedoch darauf, dass die Nutzung des Zeitungsartikels durch OpenAI nicht als „faire Nutzung“ einzustufen sei.
Wenn Benutzer über KI-Chatbots Beschreibungen von Nachrichtenereignissen erhalten können, die in Artikeln erwähnt werden, können Benutzer Artikel möglicherweise nicht erneut lesen, sodass sie möglicherweise zu einem Ersatz für Nachrichtenartikel werden und sich auf den ursprünglichen Markt auswirken.
Der Rechtsblogger Fan Baile wies darauf hin, dass das Gesetz zum Schutz des geistigen Eigentums nicht statisch sei, sondern dass sein Kern fest sei – um den Kreativmarkt zu gedeihen.
Wenn sogar ein KI-Unternehmen mit einem Wert von mehreren zehn Milliarden Dollar die Werke, die Autoren jahrelang geschaffen haben, kostenlos nutzen könnte, ohne Urheberrechtsgebühren zu zahlen, und diese Bücher sogar stehlen könnte, um Werkzeuge zu trainieren, die Autoren ersetzen sollen, wäre das ein großes Problem . Es ist zweifellos ein fataler Schlag für die Schöpfer.
Das von Presser angesprochene Problem der „Datenungerechtigkeit“ sollte keine Entschuldigung für die Verletzung der Rechte von Urhebern sein.
Urheberrechtsfragen werden letztendlich einer der Schlüsselfaktoren dafür sein, wie weit KI gehen kann.
Laut Daniel Gervais, Co-Direktor des Intellectual Property Program an der Vanderbilt University:
Das Urheberrecht ist ein Schwert, das über KI-Unternehmen schwebt, und wenn sie nicht herausfinden, wie sie eine Lösung aushandeln können, wird dieses Schwert noch viele Jahre über ihnen hängen.
All dies ist nur der Anfang einer neuen Phase.

Schließlich haben wir einige der laufenden Klagen wegen Verstößen gegen KI-Unternehmen als Referenz geklärt 

#Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich präsentiert.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo