
Eine Einführung in die Verwendung von NLTK mit Python
Die Verarbeitung natürlicher Sprache ist ein Aspekt des maschinellen Lernens, mit dem Sie geschriebene Wörter in eine maschinenfreundliche Sprache verarbeiten können. Solche Texte können dann angepasst werden, und Sie können nach Belieben Rechenalgorithmen darauf ausführen.
Die Logik hinter dieser faszinierenden Technologie scheint komplex zu sein, ist es aber nicht. Und selbst jetzt können Sie mit soliden Kenntnissen der grundlegenden Python-Programmierung mit dem Natural Language Toolkit (NLTK) eine neuartige DIY-Textverarbeitung erstellen.
Hier erfahren Sie, wie Sie mit Pythons NLTK beginnen.
Was ist NLTK und wie funktioniert es?
NLTK wurde mit Python geschrieben und bietet eine Vielzahl von Funktionen zur Manipulation von Zeichenfolgen. Es ist eine vielseitige Bibliothek natürlicher Sprache mit einem umfangreichen Modell-Repository für verschiedene Anwendungen in natürlicher Sprache.
Mit NLTK können Sie Rohtexte verarbeiten und daraus sinnvolle Merkmale extrahieren. Es bietet auch Textanalysemodelle, funktionsbasierte Grammatiken und umfangreiche lexikalische Ressourcen zum Erstellen eines vollständigen Sprachmodells.
So richten Sie NLTK . ein
Erstellen Sie zunächst einen Projektstammordner an einer beliebigen Stelle auf Ihrem PC. Um die NLTK-Bibliothek zu verwenden, öffnen Sie Ihr Terminal im zuvor erstellten Stammordner und erstellen Sie eine virtuelle Umgebung .
Installieren Sie dann das Natural Language Toolkit mit pip in dieser Umgebung:
pip install nltkNLTK bietet jedoch eine Vielzahl von Datensätzen, die als Grundlage für neuartige natürliche Sprachmodelle dienen. Um darauf zuzugreifen, müssen Sie den integrierten NLTK-Daten-Downloader starten.
Nachdem Sie NLTK erfolgreich installiert haben, öffnen Sie Ihre Python-Datei mit einem beliebigen Code-Editor.
Importieren Sie dann das nltk- Modul und instanziieren Sie den Daten-Downloader mit dem folgenden Code:
pip install nltk
nltk.download()Wenn Sie den obigen Code über das Terminal ausführen, wird eine grafische Benutzeroberfläche zum Auswählen und Herunterladen von Datenpaketen angezeigt. Hier müssen Sie ein Paket auswählen und auf die Schaltfläche Download klicken, um es zu erhalten.
Jedes heruntergeladene Datenpaket wird in das angegebene Verzeichnis im Feld Download-Verzeichnis gespeichert. Sie können dies ändern, wenn Sie möchten. Versuchen Sie jedoch, den Standardspeicherort auf dieser Ebene beizubehalten.
Hinweis: Die Datenpakete werden standardmäßig an die Systemvariablen angehängt. Sie können sie also unabhängig von der verwendeten Python-Umgebung für nachfolgende Projekte weiter verwenden.
So verwenden Sie NLTK-Tokenizer
Letztlich bietet NLTK trainierte Tokenisierungsmodelle für Wörter und Sätze. Mit diesen Tools können Sie aus einem Satz eine Liste von Wörtern erstellen. Oder verwandeln Sie einen Absatz in ein sinnvolles Satzarray.
Hier ist ein Beispiel für die Verwendung des NLTK word_tokenizer :
import nltk
from nltk.tokenize import word_tokenize
word = "This is an example text"
tokenWord = word_tokenizer(word)
print(tokenWord)
Output:
['This', 'is', 'an', 'example', 'text']NLTK verwendet auch einen vortrainierten Satz-Tokenizer namens PunktSentenceTokenizer . Es funktioniert, indem ein Absatz in eine Liste von Sätzen unterteilt wird.
Sehen wir uns an, wie das mit einem Absatz mit zwei Sätzen funktioniert:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
sentence = "This is an example text. This is a tutorial for NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(sentence)
print(tokenized_sentence)
Output:
['This is an example text.', 'This is a tutorial for NLTK']
Sie können jeden Satz in dem aus dem obigen Code generierten Array mit word_tokenizer und Python for loop weiter tokenisieren.
Beispiele für die Verwendung von NLTK
Auch wenn wir nicht alle möglichen Anwendungsfälle von NLTK demonstrieren können, finden Sie hier einige Beispiele dafür, wie Sie damit beginnen können, reale Probleme zu lösen.
Holen Sie sich Wortdefinitionen und ihre Wortarten
NLTK bietet Modelle zur Bestimmung von Wortarten, zum Erhalt einer detaillierten Semantik und zur möglichen kontextbezogenen Verwendung verschiedener Wörter.
Sie können das Wordnet- Modell verwenden, um Variablen für einen Text zu generieren. Bestimmen Sie dann seine Bedeutung und Wortart.
Lassen Sie uns zum Beispiel die möglichen Variablen für "Monkey:" überprüfen.
import nltk
from nltk.corpus import wordnet as wn
print(wn.synsets('monkey'))
Output:
[Synset('monkey.n.01'), Synset('imp.n.02'), Synset('tamper.v.01'), Synset('putter.v.02')]
Der obige Code gibt mögliche Wortalternativen oder Syntaxen und Wortarten für "Affe" aus.
Überprüfen Sie nun die Bedeutung von "Affe" mit der Definitionsmethode :
Monkey = wn.synset('monkey.n.01').definition()
Output:
any of various long-tailed primates (excluding the prosimians)Sie können die Zeichenfolge in Klammern durch andere generierte Alternativen ersetzen, um zu sehen, was NLTK ausgibt.
Das pos_tag- Modell bestimmt jedoch die Wortarten eines Wortes. Sie können dies mit dem word_tokenizer oder PunktSentenceTokenizer() verwenden, wenn Sie es mit längeren Absätzen zu tun haben.
So funktioniert das:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
word = "This is an example text. This is a tutorial on NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(word)
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i)
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN'), ('.', '.')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Der obige Code paart jedes tokenisierte Wort mit seinem Sprach-Tag in einem Tupel. Sie können die Bedeutung dieser Tags auf der Penn Treebank überprüfen.
Für ein saubereres Ergebnis können Sie die Punkte in der Ausgabe mit der Methode replace() entfernen:
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i.replace('.', ''))
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Cleaner output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Visualisieren von Feature-Trends mit NLTK-Plot
Das Extrahieren von Merkmalen aus Rohtexten ist oft mühsam und zeitaufwendig. Sie können jedoch die stärksten Merkmalsbestimmer in einem Text anzeigen, indem Sie das Trenddiagramm der NLTK-Häufigkeitsverteilung verwenden.
NLTK synchronisiert sich jedoch mit matplotlib. Sie können dies nutzen, um einen bestimmten Trend in Ihren Daten anzuzeigen.
Der folgende Code vergleicht beispielsweise eine Reihe positiver und negativer Wörter in einem Verteilungsdiagramm unter Verwendung ihrer letzten beiden Alphabete:
import nltk
from nltk import ConditionalFreqDist
Lists of negative and positive words:
negatives = [
'abnormal', 'abolish', 'abominable',
'abominably', 'abominate','abomination'
]
positives = [
'abound', 'abounds', 'abundance',
'abundant', 'accessable', 'accessible'
]
# Divide the items in each array into labeled tupple pairs
# and combine both arrays:
pos_negData = ([("negative", neg) for neg in negatives]+[("positive", pos) for pos in positives])
# Extract the last two alphabets from from the resulting array:
f = ((pos, i[-2:],) for (pos, i) in pos_negData)
# Create a distribution plot of these alphabets
cfd = ConditionalFreqDist(f)
cfd.plot()Das Diagramm der Alphabetverteilung sieht wie folgt aus:
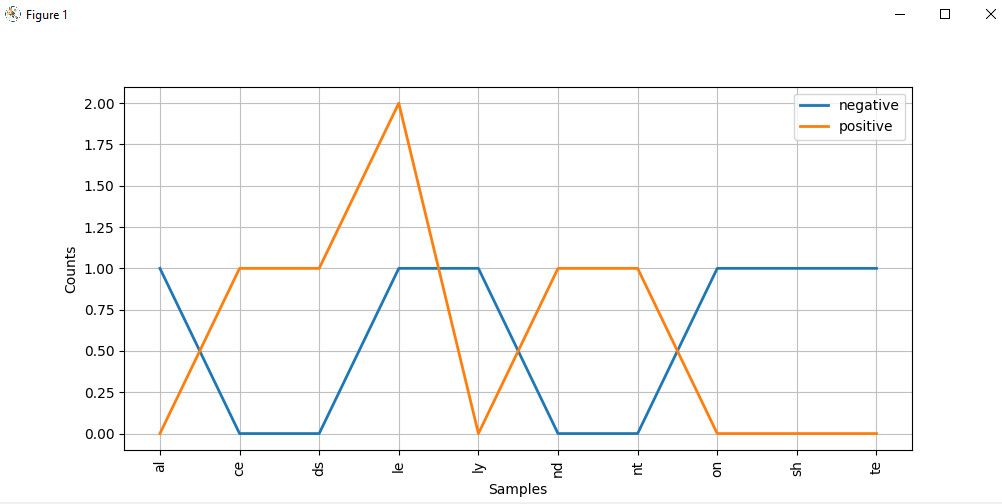
Bei genauer Betrachtung des Graphen ist die Wahrscheinlichkeit, dass es sich bei Wörtern, die mit ce , ds , le , nd und nt enden, mit höherer Wahrscheinlichkeit positive Texte handelt. Aber diejenigen, die mit al , ly , on und te enden, sind eher negative Wörter.
Hinweis : Obwohl wir hier selbst generierte Daten verwendet haben, können Sie mit dem Corpus-Reader auf einige der integrierten Datensätze des NLTK zugreifen, indem Sie sie aus der Corpus- Klasse von nltk aufrufen . Sehen Sie sich die Dokumentation des Korpuspakets an, um zu sehen, wie Sie es verwenden können.
Erkunden Sie weiterhin das Natural Language Processing Toolkit
Mit dem Aufkommen von Technologien wie Alexa, Spam-Erkennung, Chatbots, Sentiment-Analyse und mehr scheint sich die Verarbeitung natürlicher Sprache in ihre untermenschliche Phase zu entwickeln. Obwohl wir in diesem Artikel nur einige Beispiele für das Angebot von NLTK betrachtet haben, bietet das Tool fortgeschrittenere Anwendungen, die über den Umfang dieses Tutorials hinausgehen.
Nachdem Sie diesen Artikel gelesen haben, sollten Sie eine gute Vorstellung davon haben, wie NLTK auf Basisebene verwendet wird. Jetzt müssen Sie nur noch dieses Wissen selbst in die Tat umsetzen!