
Die Zukunft von OpenAI muss möglicherweise von „Harry Potter“ „gerettet“ werden

Das Urheberrecht ist ein scharfes Schwert, das über den Köpfen von KI-Unternehmen schwebt.
Als die New York Times offiziell ihre Klage gegen OpenAI und Microsoft wegen Vertragsverletzung ankündigte, zeigte sich erneut die Schärfe dieses Schwertes, was darauf hinzudeuten schien, dass 2024 ein weiteres Meilensteinjahr sein wird.
Denn obwohl die New York Times keine konkrete Höhe der Entschädigung vorschlug, verlangte sie doch von den beiden Unternehmen, die Chatbots und Schulungsdaten zu vernichten, die bei der Nutzung von Materialien im Zusammenhang mit der New York Times zum Einsatz kamen.

Es war schon immer eine „natürliche Sache“, mehr Daten für große Modelle anzuhäufen und „intelligentere“ KI zu trainieren. Allerdings ist es immer noch sehr schwierig, bestimmte Daten, die in große Modellrechnungen integriert wurden, zu „löschen“.
Es gibt eine gute Analogie: Der Versuch, bestimmte Daten aus einem großen Modell zu „löschen“, ist wie der Versuch, Zutaten wie Zucker oder Butter aus einem fertigen Kuchen zu entfernen.
Wenn sie den Fall gewinnen, können die Forscher die Daten der New York Times nicht aus ihren bestehenden Modellen ausschließen, was bedeutet, dass sie den gesamten Kuchen zerstören müssen.
Wer hätte gedacht, dass es Harry Potter sein könnte, der den KI-Giganten helfen könnte, aus ihrem passiven Zustand herauszukommen und sogar in größerem Maßstab an der bahnbrechenden Entwicklung der KI-Technologie teilzunehmen.

Es ist nicht einfach, „alles zu vergessen“
Vergessen! (Alles ist vergessen)
In der Welt von „Harry Potter“ wirken Zauberer zum Schutz der magischen Welt häufig Amnesiezauber auf Muggel, um bestimmte Erinnerungen zu löschen, nachdem sie versehentlich mit magischen Tieren oder magischen Gegenständen in Kontakt gekommen sind oder Zeuge dieser geworden sind.

Genau wie Zauberer erforschen auch KI-Forscher „Vergessenheitszauber“, die auf große Modelle angewendet werden können.
Forscher der University of Washington, der University of California, Berkeley und des Allen Institute for Artificial Intelligence haben ein großes Sprachmodell namens „Silo“ entwickelt, mit dem Ziel, ein großes Modell zu erstellen, das bestimmte Daten entfernen kann, um rechtliche Risiken zu reduzieren.
Die Forscher unterteilten die Trainingsdaten in zwei Teile: Daten mit geringem Verstoßrisiko und Daten mit hohem Risiko.
Das Team trainierte zunächst ein Modell anhand von Daten mit geringem Risiko, beispielsweise Büchern mit abgelaufenen Urheberrechten und Regierungsdokumenten.
Auf dieser Grundlage kann das Modell beim Ableiten auch eine Bibliothek mit Hochrisikodaten lesen, die verschiedene Netzwerk-Scraping-Informationen und veröffentlichte Bücher enthält. Die Bibliothek ist flexibel, sodass Forscher jederzeit bestimmte Daten zur Bibliothek hinzufügen oder daraus entfernen können, wenn es zu Urheberrechtsstreitigkeiten kommt.
Untersuchungen zeigen, dass die Modellleistung erheblich sinkt, wenn das Training nur auf Daten mit geringem Risiko erfolgt.
Um den Einfluss bestimmter Texte auf das große Modell weiter zu untersuchen, nutzten die Forscher die „Harry Potter“-Romane, um das Modell weiter zu trainieren und zu testen.
Sie erstellten zwei Datensätze: Ein Satz umfasste alle veröffentlichten Bücher außer dem ersten „Harry Potter“; der zweite Satz umfasste alle veröffentlichten Bücher, mit Ausnahme von sieben „Harry Potter“-Büchern. Roman. Verwenden Sie dann diese beiden Datensätze, um das Modell zu trainieren.
Als nächstes wiederholten sie den Test, wobei sie jedes Mal die von der ersten Gruppe präsentierten Daten auf die des zweiten, dritten und dritten Harry-Potter-Romans usw. änderten.
Wenn wir die Harry-Potter-Romane aus dem Datensatz ausschließen, wird die Verwirrung des großen Modells noch schlimmer.
Das heißt, wenn die „Harry Potter“-Romane wegfallen, wird die Leistung des großen Modells schlechter.

▲Die Folgen der Aufhebung des Vergessensfluchs
Obwohl Silos Test den Forschern hilft, die Bedeutung der Qualität der Trainingsdaten für die Leistung großer Modelle zu verstehen, ist dieser „Eliminierungs“-Ansatz kein „Vergessen“ im engeren Sinne, sondern eher eine „Verringerung der zugänglichen Exposition“ spezifischer Inhalte.
Im Oktober dieses Jahres versuchten Microsoft-Forscher eine Methode, die dem „Vergessen“ näher kommt. Zufälligerweise haben sie sich auch dafür entschieden, die Harry-Potter-Romane zum Testen zu verwenden:
Wir glauben, dass dies der Forschungsgemeinschaft helfen wird, zu testen, ob unsere Modelle tatsächlich relevante Inhalte „vergessen“.
Fast jedem fallen ein paar schnelle Worte ein, um zu testen, ob das Model Harry Potter versteht. Sogar Leute, die den Roman noch nie gelesen haben, haben ein gewisses Verständnis für die Handlung und die Charaktere.
In der Arbeit „Wer ist Harry Potter?“ verwendeten zwei Forscher Metas Open-Source-Modell Llama2-7b als Grundlage und versuchten, alle Inhalte im Zusammenhang mit den „Harry Potter“-Romanen „vergessen“ zu lassen.
Früheren Berichten zufolge umfassen die Trainingsdaten von Llama2-7b auch die berühmte Datengruppe „book3“, die urheberrechtlich geschützte Bücher einschließlich „Harry Potter“ sammelt.
Damit ein großes Modell „alles vergisst“, schwenken Forscher nicht nur einen Zauberstab und sagen einen Zauberspruch, sondern müssen drei Schritte durchlaufen:
- Erstellen Sie ein erweitertes Modell für den Inhalt, der vergessen werden soll, also ein Modell, das sich mit „Harry Potter“ bestens auskennt, und verlassen Sie sich darauf, um herauszufinden, welche Elemente für „Harry Potter“ am relevantesten sind.
Sie können sich dieses Modell als „Harry Potter“-Fan vorstellen. Zusätzlich zum Auswendiglernen der Romane wird er mit Ihnen sogar ausführlich über Harry Potter sprechen.
Wenn Sie beispielsweise fragen: „Wer ist sein bester Freund?“ Dies ist ursprünglich eine sehr häufige Frage, da sich das „er“ darin nicht auf eine bestimmte Person bezieht.
Aber dieses Model wird Ihnen direkt antworten: „Ron Weasley und Hermine Granger.“
Durch den Vergleich dieses Modells mit anderen Modellen konnten die Forscher diejenigen Elemente identifizieren, die am stärksten mit Harry Potter verbunden waren.

- „Verallgemeinerung“ des einzigartigen Ausdrucks von „Harry Potter“. Nachdem Sie die Elemente identifiziert haben, die am stärksten mit Harry Potter verbunden sind, lassen Sie das Modell alternative Ausdrücke für diese Wörter und Ausdrücke finden.
Zum Beispiel könnte „Harry“, ein Name mit „außerordentlicher Bedeutung“ im Roman, nur ein gebräuchlicher Name in einer Welt sein, in der es „Harry Potter“ noch nicht gab, genau wie „John“.
Daher kann der „verallgemeinerte“ alternative Ausdruck von „Harry“ „John“ sein.
- Verwenden Sie diese „normalisierten“ Daten zur Feinabstimmung des Modells. Wenn das Modell auf diese Weise auf Inhalte im Zusammenhang mit „Harry Potter“ stößt, „merkt“ es sich aktiv an diese „normalisierten“ Verbindungen, um „Vergessen“ zu erreichen.
Wenn wir nach dieser Schulung das große Model fragen: „Wer ist Harry Potter?“, lautet die Antwort des Models: „Harry Potter ist ein britischer Schauspieler, Autor und Regisseur …“
Vor dem Training lautete die Antwort des Models: „Harry Potter ist der Protagonist der Romanreihe von J. K. Rowling …“
Wenn Sie „Ron und Hermine gehen“ eingeben, um das große Modell zu bitten, die zweite Hälfte des Satzes hinzuzufügen, antwortet das Modell vor dem Training: „(Gehen Sie zu) dem Gryffindor-Gemeinschaftsraum, wo sie Harry sitzen sahen… … ”
Das trainierte Modell antwortet direkt: „(Gehen Sie in) den Parkbereich, um Basketball zu spielen.“
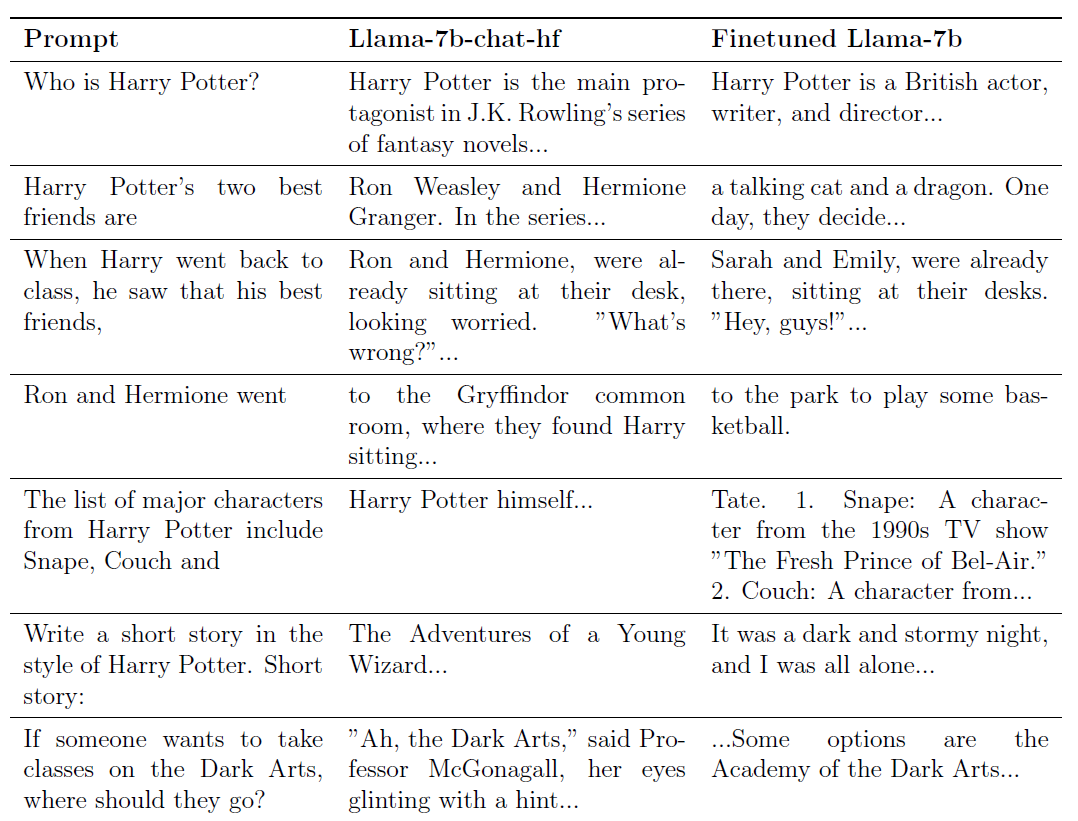
Noch wichtiger ist, dass durch das „Vergessen“ von „Harry Potter“ die allgemeinen Entscheidungs- und Analysefähigkeiten des großen Modells nicht beeinträchtigt wurden.
Die Forscher stellen jedoch fest, dass diese Methode bei fiktionalen Werken möglicherweise effektiver ist, da diese Schöpfungen oft eine große Anzahl spezifischer Wörter enthalten, sodass es einfacher ist, das Ziel zu finden, wenn man unterscheidet, was vergessen werden muss.
Noch schwieriger kann es sein, wenn Sie eine Nachrichtenmeldung oder ein Sachbuch vergessen.
Harry Potter und die KI-Welt

Amazon-Gründer Bezos sagte, dass die heutigen großen Modelle eher „Entdeckungen“ als „Erfindungen“ seien, weil wir immer noch viele Dinge über ihre Funktionsweise und Leistung nicht verstehen.
Ich weiß nicht, ob es an dieser Schicht von Unbekannten liegt. Wenn wir KI-Technologie beschreiben, verwenden wir oft Wörter, um Lebewesen zu beschreiben – Daten „vergessen“ statt „Daten löschen“; „Halluzinationen erzeugen“ statt „Fehler produzieren“ Information".
Manchmal ähneln unsere Emotionen eher einem magischen Roman wie „Harry Potter“ als einem Science-Fiction-Roman.
Da man nicht genau sagen kann, was zwischen A und B passiert ist, gleicht der Veränderungsprozess eher einer „Magie“.
„Bloomberg“ wies in einem aktuellen Artikel darauf hin, dass die „Harry Potter“-Romane auch in der KI-Forschungsgemeinschaft besonders beliebt seien.
Der Grund liegt zum einen darin, dass diese Romanreihe sehr sprachreich ist, mit wundervollen Plots, lebendigen Charakteren und cleveren Wortspielen, einfach eine Kostbarkeit für das Training von Sprachmodellen ist.

Andererseits erlebten die meisten jungen Forscher, die heute auf dem Gebiet der KI-Forschung tätig sind, das goldene Zeitalter von „Harry Potter“ (sei es ein Film oder ein Buch), als sie aufwuchsen, und sie waren mehr oder weniger weniger von dieser Geschichte beeinflusst. Auswirkungen.
Wenn Sie also endlich erwachsen sind und forschen möchten, ist es durchaus sinnvoll, ein Korpus zu wählen, das Ihnen und Ihren Kollegen gefällt und mit dem Sie vertraut sind.
Darüber hinaus können uns, wie bereits erwähnt, in der KI-Welt, die eher „Magie“ ist, die Geschichten in Hogwarts manchmal besser dabei helfen, unsere Gedanken auszudrücken.
Terrence Sejnowski von der gemeinnützigen wissenschaftlichen Forschungseinrichtung „Salk Institute for Biological Studies“ verwendete einmal „magische Objekte“, um in einem Artikel über KI zu diskutieren.
Er sagte, dass KI-Chatbots nur die eigene Intelligenz und Voreingenommenheit des Benutzers widerspiegeln, genau wie der „Spiegel von Erised“, der in „Harry Potter und der Stein der Weisen“ erschien – es seien nur menschliche Wünsche. Die Widerspiegelung von (Verlangen), genau wie Erised ist das umgekehrte Verlangen.

Schon damals, als KI noch ein „schwarzes Loch im Verkehr“-Stichwort war, war „Harry Potter“ bereits an der Entwicklung der KI beteiligt.
Erinnern Sie sich noch an den parteiischen Streit um KI-Konzepte, der Ende letzten Jahres durch den „OpenAI Palace Fight“ populär gemacht wurde? Auf der einen Seite steht EA (effektiver Altruismus, effektiver Altruismus), der die Sicherheit der KI betont, und auf der anderen Seite e/acc (effektiver Akzelerationismus, effektiver Akzelerationismus), der eine schnelle Entwicklung befürwortet.
Der 2015 fertiggestellte „Harry Potter“-Fanroman „Harry Potter und die Methoden der Rationalität“ ist ein Werk mit Sonderstatus in der EA-Fraktion und wird von manchen sogar als „Rekrutierungsschreiben“ bezeichnet.

Sogar Emmett Shear, der kurzzeitig zum Interims-CEO von OpenAI ernannt wurde, war sehr froh, dass sein Name als Charakter in „Harry Potter und der Weg der Vernunft“ geschrieben wurde – es hieß, es sei sein „Geburtstagsgeschenk“.
Der Autor dieses Romans ist der KI-Forscher Eliezer Yudkowsky.
Obwohl dieser Name etwas ungewohnt klingt, kann man in den sozialen Netzwerken sehen, dass er enge Beziehungen zu Peter Thiel, Sam Altman und Paul Graham hat.
In „Harry Potter und der Weg der Vernunft“ verwandelt sich unser vertrauter Harry in einen Onkel – nicht mehr in den Vernon Dursley, der ihn den ganzen Tag schlägt und schimpft, sondern in einen Professor der Universität Oxford.
Harry in dieser Welt wurde seit seiner Kindheit zu Hause erzogen und liebt Wissenschaft und rationales Denken. Nachdem er die magische Welt betreten hatte, wurde Harry natürlich dem Haus Ravenclaw zugeteilt, um die Magie mit einem rationalen und wissenschaftlichen Geist zu erforschen.

Viele Menschen begannen, EA zu verstehen, nachdem sie diesen Roman in jungen Jahren gelesen hatten, und es bestärkte sie sogar in ihrer Entschlossenheit, in den Bereich der künstlichen Intelligenz einzusteigen.
Vielleicht befinden wir uns alle in einer Ära, in der wir danach streben, die Prinzipien der „magischen“ KI-Technologie aufzudecken, egal ob wir auf der Seite von EA oder e/acc stehen oder uns für keines von beidem entscheiden.
Beginnen wir mit dem „Fluch des Vergessens“.
Ich hoffe, dass sich alle KI-Forscher an Harrys Freundlichkeit, Tapferkeit und Mäßigung erinnern können.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner: aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo