
Wie erreicht OpenAI bei der Enthüllung des leistungsstärksten Videogenerierungsmodells Sora eine Aufnahme in einer Minute?

Heute früh hat OpenAI das KI-Videogenerierungstool Sora aus seinem „Munitionsarsenal“ genommen und damit sofort große Schlagzeilen gemacht.
Sogar Musk, der schon immer im Widerspruch zu OpenAI stand, ist bereit, die Macht von Sora anzuerkennen und sie zu loben: „In den nächsten Jahren werden Menschen mit Hilfe der Macht der KI herausragende Werke schaffen.“
Die Stärke von Sora liegt in seiner Fähigkeit, auf der Grundlage von Textbeschreibungen kohärente und flüssige Videos von bis zu 60 Sekunden zu erstellen, die heikle und komplexe Szenen, lebendige Charakterausdrücke und komplexe Kamerabewegungen enthalten.
Verglichen mit anderen Videos, die nur Videos mit einstelligen Ziffern erzeugen können, hat Soras Dauer von einer Minute zweifellos den Effekt, den Spieß umzudrehen.
Noch wichtiger ist, dass Sora das beste Niveau in Bezug auf Videoauthentizität, Länge, Stabilität, Konsistenz, Auflösung oder Textverständnis gezeigt hat. Lassen Sie uns zunächst die offiziell veröffentlichten Demonstrationsvideoclips genießen.
Hinweis: In der wunderschönen, verschneiten Stadt Tokio herrscht geschäftiges Treiben. Die Kamera bewegt sich durch die geschäftige Stadtstraße und folgt mehreren Menschen, die das schöne Schneewetter genießen und an nahegelegenen Ständen einkaufen. Wunderschöne Sakura-Blütenblätter fliegen zusammen mit Schneeflocken durch den Wind.
In diesem Video ist ein Paar aus der Perspektive einer Drohne zu sehen, wie es durch eine belebte Stadtstraße läuft, während wunderschöne Kirschblütenblätter in der Luft tanzen, begleitet von Schneeflocken.
Während andere Tools immer noch Schwierigkeiten haben, ein einzelnes Objektiv stabil zu halten, hat Sora einen reibungslosen nahtlosen Wechsel mehrerer Objektive erreicht, und die Kohärenz des Objektivwechsels und die Konsistenz von Objekten liegen weit vorn, was ein echter Schlag zur Dimensionsreduzierung ist. 

▲Von @gabor
In der Vergangenheit erforderte die Aufnahme eines solchen Videos möglicherweise viel Zeit und Energie für eine Reihe mühsamer Aufgaben wie Drehbucherstellung und Szenenbild. Jetzt kann Sora mit nur einer einfachen Textbeschreibung eine so große Szene erzeugen, und die entsprechenden Praktizierenden könnten zu zittern begonnen haben.
Netizen @debarghya_das hat diesen über 20 Sekunden langen Trailer in 15 Minuten mit OpenAI Sora-Schnitt, David Attenboroughs Stimme bei Eleven Labs und einigen natürlichen Musikbeispielen von Youtube auf iMovie erstellt.

Wie erzielt Sora seine kraftvolle Wirkung?
OpenAI veröffentlichte außerdem einen detaillierten technischen Bericht zu Sora, in dem die technischen Prinzipien und Anwendungen dahinter vorgestellt werden.
Wie gelang Sora dieser Durchbruch? Inspiriert durch die erfolgreichen praktischen Erfahrungen von LLM führt OpenAI visuelle Patch-Einbettungscodes (Patches) ein, eine hoch skalierbare und effektive visuelle Datendarstellung, die die Fähigkeit generativer Modelle, verschiedene Video- und Bilddaten zu verarbeiten, erheblich verbessern kann.

In einem hochdimensionalen Raum komprimiert OpenAI zunächst die Videodaten in einen niedrigdimensionalen latenten Raum und zerlegt sie dann in räumlich-zeitliche Einbettungen, wodurch das Video in eine Reihe von Codierungsblöcken umgewandelt wird.
Als nächstes trainierte OpenAI ein Netzwerk, das speziell darauf ausgelegt war, die Dimensionalität visueller Daten zu reduzieren. Das Netzwerk verwendet ein Rohvideo als Eingabe und gibt eine latente Darstellung aus, die sowohl zeitlich als auch räumlich komprimiert ist. In diesem komprimierten latenten Raum wird Sora trainiert und generiert in diesem Raum Videos.
Darüber hinaus hat OpenAI ein Decodermodell trainiert, das diese latenten Darstellungen in Videobildern auf Pixelebene wiederherstellen kann.
Durch die Verarbeitung der komprimierten Videoeingabe konnten die Forscher eine Reihe räumlich-zeitlicher Patches extrahieren, die im Modell eine ähnliche Rolle wie Transformer-Tokens spielen.
Mithilfe einer Patch-basierten Darstellung kann sich Sora an Videos und Bilder mit unterschiedlichen Auflösungen, Dauern und Seitenverhältnissen anpassen. Bei der Generierung neuer Videoinhalte können diese zufällig initialisierten Patches entsprechend der erforderlichen Größe in einem Raster angeordnet werden. Kontrollieren Sie die Größe und Form Ihres endgültigen Videos.

Obwohl das obige Prinzip ziemlich kompliziert klingt, ist die neue Technologie von OpenAI – visueller Block-Einbettungscode (als visueller Block bezeichnet) – in Wirklichkeit so, als würde man einen Haufen unorganisierter Bausteine in einer kleinen Box organisieren. Auf diese Weise können Sie, selbst wenn viele Bausteine vorhanden sind, die benötigten Bausteine leicht finden, solange Sie diese kleine Kiste finden.
Da Videodaten in kleine Quadrate umgewandelt werden, extrahieren sie, wenn OpenAI Sora eine neue Videoaufgabe stellt, zunächst einige kleine Quadrate mit zeitlichen und räumlichen Informationen aus dem Video. Diese kleinen Quadrate werden dann an Sora übergeben, um auf Grundlage dieser Informationen neue Videos zu generieren.
So lässt sich das Video wie ein Puzzle wieder zusammensetzen. Dies hat den Vorteil, dass der Computer schneller verschiedene Arten von Bildern und Videos erlernen und verarbeiten kann.
Als Sora intensiver trainiert wurde, stellten OpenAI-Forscher auch fest, dass sich die Probenqualität mit zunehmendem Trainingsaufwand erheblich verbesserte. OpenAI hat herausgefunden, dass das Training direkt auf der Originalgröße der Daten mehrere Vorteile hat:
- Sora schneidet das Material beim Training nicht zu, sodass Sora Inhalte direkt entsprechend dem nativen Seitenverhältnis verschiedener Geräte erstellen kann.
- Das Training des nativen Seitenverhältnisses des Videos kann die Kompositions- und Layoutqualität des Videos erheblich verbessern.

Darüber hinaus verfügt Sora über folgende Funktionen:
Für das Training eines Systems zur Text-zu-Video-Generierung ist eine große Anzahl von Videos mit Textuntertiteln erforderlich. OpenAI wendet die in DALL·E 3 eingeführte Re-Annotation-Technologie auf Videos an.
Ähnlich wie DALL·E 3 verwendet OpenAI GPT, um die kurzen Eingabeaufforderungen des Benutzers in längere detaillierte Anweisungen umzuwandeln und sie dann an das Videomodell zu senden, sodass Sora qualitativ hochwertige Videos generieren kann.
Neben der Konvertierung von Text kann Sora auch Eingaben von Bildern oder vorhandenen Videos akzeptieren. Mit dieser Funktion kann Sora eine Vielzahl von Bild- und Videobearbeitungsaufgaben erledigen, z. B. das Erstellen nahtloser Loop-Videos, das Hinzufügen von Animationseffekten zu statischen Bildern, das Verlängern der Wiedergabezeit von Videos usw.
Ein realistisches Bild von Wolken, die das Wort „SORA“ bilden.


In einem reich verzierten historischen Saal droht eine riesige Welle. Die beiden Surfer nutzten die Gelegenheit und ritten gekonnt auf den Wellen.


Sora kann den Stil und die Umgebung in einem Video ohne vorherige Beispiele ändern. Selbst zwei Videos mit völlig unterschiedlichen Stilrichtungen lassen sich problemlos verbinden.

Sora kann auch Bilder erzeugen. Das Forschungsteam erstellt Bilder unterschiedlicher Größe, indem es Gaußsche Rauschblöcke in einem räumlichen Raster mit einem Zeitbereich von nur einem Bild anordnet. Die maximale Auflösung erreicht 2048×2048.

Die echte OpenAI gab auch offen die aktuellen Einschränkungen von Sora zu, wie etwa seine Unfähigkeit, die physikalischen Effekte komplexer Szenen zu simulieren und einige spezifische kausale Zusammenhänge zu verstehen. Es kann beispielsweise grundlegende physikalische Wechselwirkungen wie Glasbruch nicht genau simulieren.

▲Laufen in die entgegengesetzte Richtung
Aber OpenAI ist fest davon überzeugt, dass die aktuellen Fähigkeiten von Sora zeigen, dass die weitere Erweiterung von Videomodellen ein vielversprechender Weg zur Entwicklung leistungsfähiger Simulatoren ist, die die physische und digitale Welt sowie die darin enthaltenen Objekte, Tiere und Menschen simulieren können.
Weltmodelle, die nächste Richtung der KI?
OpenAI hat herausgefunden, dass Sora, wenn es in großem Maßstab trainiert wird, einen überzeugenden Satz neuer Fähigkeiten aufweist, die bis zu einem gewissen Grad reale Menschen, Tiere und Umgebungen simulieren können.
Diese Fähigkeiten basieren nicht auf spezifischen Voreinstellungen dreidimensionaler Räume oder Objekte, sondern werden durch umfangreiche Daten gesteuert.
- Kohärenz im dreidimensionalen Raum
Sora kann Videos mit dynamischen Perspektivwechseln generieren. Wenn sich Kameraposition und -winkel ändern, können sich die Charaktere und Szenenelemente im Video kohärent im dreidimensionalen Raum bewegen. - Kontinuität über große Entfernungen und Objektpersistenz Sora gewährleistet die Videokontinuität über lange Zeiträume hinweg, selbst wenn Personen, Tiere oder Objekte verdeckt sind oder sich aus dem Bild bewegen. Ebenso kann derselbe Charakter im selben Videobeispiel mehrmals gezeigt werden und ein einheitliches Erscheinungsbild gewährleistet werden.
- Simulation der digitalen Welt
Sora kann auch digitale Prozesse wie Videospiele simulieren, indem es einfach die Worte „Minecraft“ erwähnt, um die damit verbundenen Fähigkeiten zu aktivieren.
OpenAI betrachtet Sora als „die Grundlage von Modellen, die die reale Welt verstehen und simulieren können“ und glaubt, dass seine Fähigkeiten „ein wichtiger Meilenstein bei der Verwirklichung von AGI sein werden“.
Bezüglich der Ankunft von Sora sagte der leitende NVIDIA-Wissenschaftler Jim Fan:
Wenn Sie der Meinung sind, dass Sora von OpenAI wie DALL·E ein Werkzeug für kreative Experimente ist, sollten Sie es sich vielleicht noch einmal überlegen.
Sora ist eigentlich eine datenbasierte Physiksimulations-Engine, die reale oder fiktive Welten simulieren kann. Dieser Simulator erlernt komplexe Bildwiedergabe, „intuitives“ physikalisches Verhalten, langfristige Planungsfähigkeiten und das Verständnis semantischer Ebenen durch Rauschunterdrückung und Gradientenberechnungen.
Die Grundlage dieser Modellfähigkeit ist das Weltuniversalmodell, ein künstliches Intelligenzsystem. Sein Ziel ist der Aufbau eines neuronalen Netzwerkmoduls, das den Zustand aktualisieren kann, um die Umgebung zu speichern und zu modellieren.
Dieses Modell ist in der Lage, basierend auf aktuellen Beobachtungen (z. B. Bildern, Zuständen usw.) und bevorstehenden Aktionen die nächste mögliche Beobachtung vorherzusagen. Es simuliert mögliche zukünftige Ereignisse in der Umwelt, indem es die Gesetze und den gesunden Menschenverstand der Welt lernt.

Tatsächlich ist das Weltmodell kein neues Konzept. Bereits im Dezember letzten Jahres kündigte Runway, der führende Anbieter von KI-Videogenerierung, offiziell an, ein universelles Weltmodell zu entwickeln, mit dem Ziel, eine Art LLM zu schaffen, das anders ist vom bestehenden LLM abweichen und realistischer sein können. Künstliche Intelligenzsysteme, die die reale Welt simulieren.
Konkret besteht die Kernidee des Weltmodells darin, durch das Auswendiglernen historischer Erfahrungen zu lernen, wie die Welt funktioniert, und dann Ereignisse vorherzusagen, die in der Zukunft eintreten könnten. Beispielsweise kann das Modell aus einem Video eines fallenden Objekts das nächste Bild basierend auf dem aktuellen Bild vorhersagen und so die physikalischen Gesetze der Objektbewegung lernen.
Turing-Preisträger Yann LeCun hat ebenfalls ein ähnliches Konzept vorgeschlagen und große Modelle, die auf probabilistischer generativer Autoregression basieren, wie etwa GPT, kritisiert, da er glaubt, dass solche Modelle das Halluzinationsproblem nicht lösen können. LeCun und sein Team sagen sogar voraus, dass Modelle wie GPT innerhalb der nächsten fünf Jahre veraltet sein könnten.
Weltmodelle können als eine Forschungsrichtung im Bereich der künstlichen Intelligenz angesehen werden, die versucht, KI näher an das Niveau der menschlichen Intelligenz heranzuführen. Durch die Simulation und das Lernen realer Umgebungen und Ereignisse haben Weltmodelle das Potenzial, die KI zu höheren Simulations- und Vorhersagefähigkeiten zu führen.
Im Februar führte Justine Moore, Partnerin der bekannten Risikokapitalgesellschaft a16z, eine eingehende Analyse der aktuellen Situation im Bereich der KI-Videogenerierung durch. In den zwei Jahren, seit die generative KI allmählich in den Fokus der Öffentlichkeit gerückt ist, hat der Bereich der KI-Videogenerierung eine blühende Szene eingeläutet, in der hundert Blumen blühen und hundert Denkrichtungen konkurrieren.
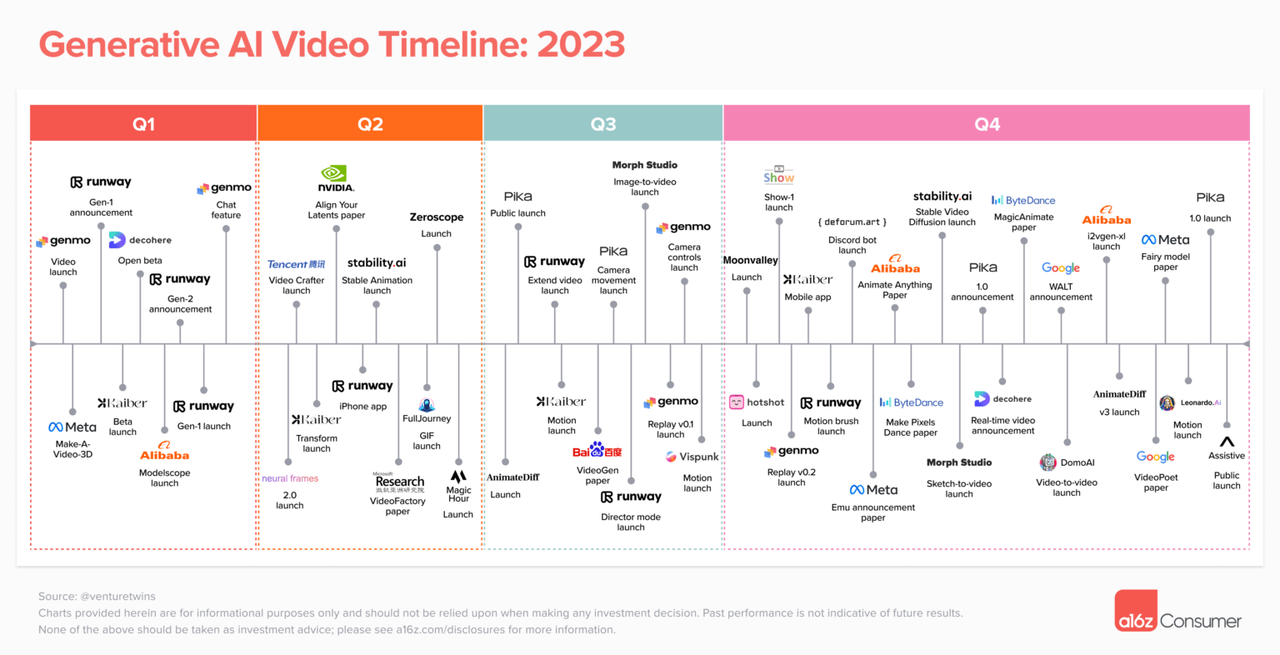
Mit der Hinzufügung von OpenAI Sora wird der Bereich der KI-Videogenerierung große Wellen schlagen und bestehende Mainstream-Plattformen wie Runway, Pika und Stable Video Diffusion könnten davon betroffen sein.
Gleichzeitig werden die Spielregeln für unabhängige Ersteller komplett geändert: Jeder mit Kreativität und Ideen kann Sora nutzen, um eigene Videoinhalte zu generieren. Die Senkung der Schwelle zur Schöpfung bedeutet auch, dass unabhängige Schöpfer ein goldenes Zeitalter einläuten werden.
Wie es in „Das Drei-Körper-Problem“ heißt: „Das spielt keine Rolle.“ Unabhängig von der aktuellen Wettbewerbssituation kann der Bereich der KI-Videogenerierung durch neue Technologien und Innovationen untergraben werden. Und Soras Auftritt ist erst der Anfang, noch lange nicht das Ende.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner: aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo