
Die chinesische Punktzahl liegt weltweit an erster Stelle und liegt in mehreren Blindtests gleichauf mit GPT4o. Wie kommt es, dass dieses große inländische Modell zu einem dunklen Pferd in der KI-Welt geworden ist?

Alles ist so, als ob es einen V12-Motor hätte.
Am 13. dieses Monats veröffentlichten Kai-fu Lee und Zero One Wish ihr zweites Produkt, das Yi-Large Closed-Source-Modell. In weniger als einem halben Monat seit seiner Veröffentlichung hat sich Yi-Large von einer neuen Generation, die keine Angst vor Tigern hat, zu einer mächtigen Gruppe entwickelt, die den Wellen im Jangtse-Fluss voraus ist.
Letzte Woche tauchte plötzlich ein mysteriöses Model namens „im-also-a-good-gpt2-chatbot“ in der großen Model-Arena Chatbot Arena auf, das direkt höher rangiert als GPT-4-Turbo, Gemini 1,5 Pro, Claude 3 0pus, Llama-3-70b und andere beliebte Basismodelle großer internationaler Hersteller.
Dieses mysteriöse Modell ist die Testversion von GPT-4o. Sam Altman, CEO von OpenAI, hat die Testergebnisse des LMSYS-Arena-Blindtests nach der Veröffentlichung von GPT-4o auch persönlich erneut veröffentlicht und zitiert.
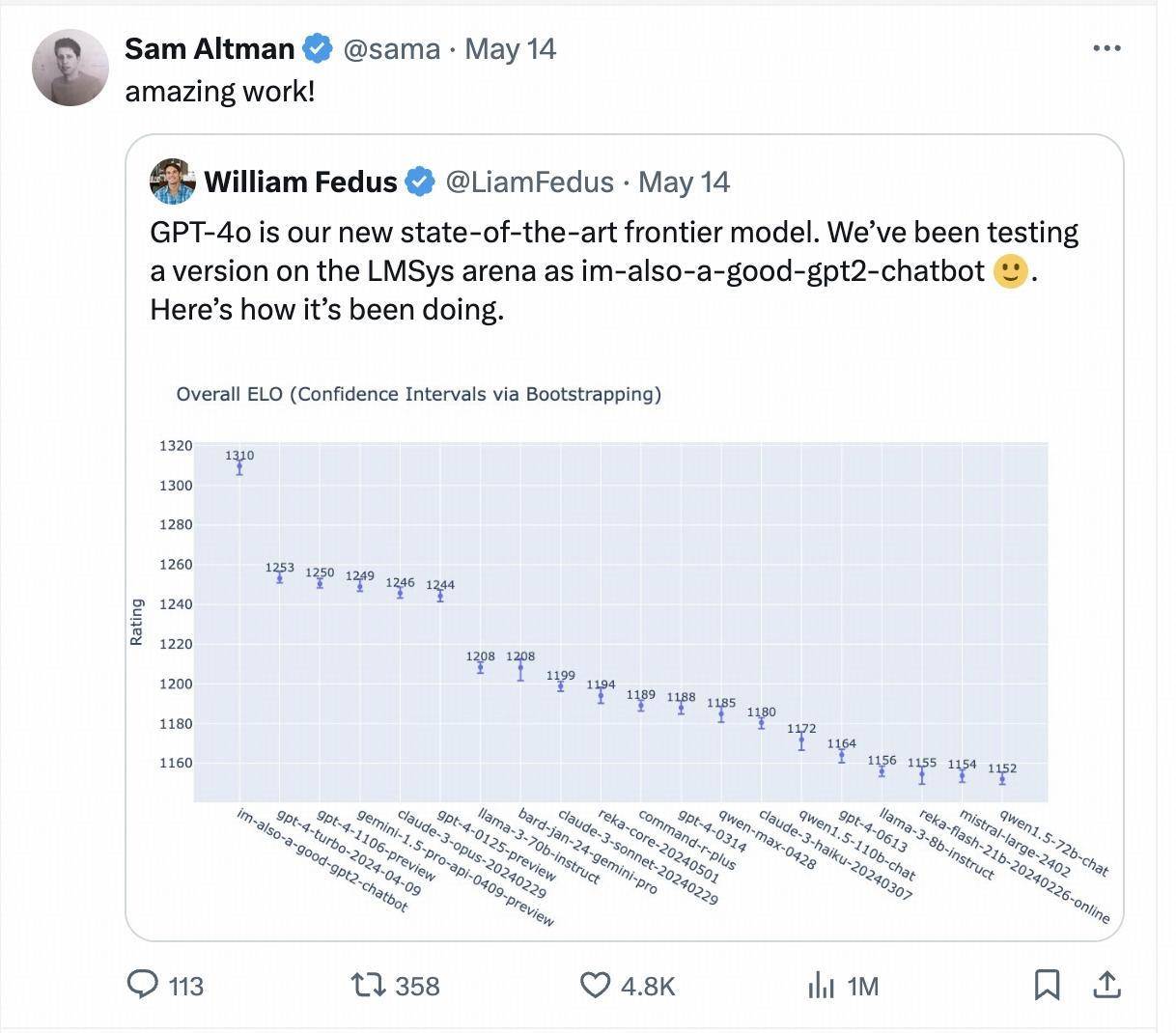
Eine Woche später wurde in der neuesten aktualisierten Rangliste erneut die dunkle Geschichte von „Ich bin auch ein guter GPT2-Chatbot“ inszeniert. Dieses Mal wurde das Modell, das in der Rangliste schnell aufstieg, von den großen Chinesen eingereicht Modellunternehmen Zero One Wan. Das Closed-Source-Großmodell „Yi-Large“ mit Hunderten von Milliarden Parametern.
Im neuesten Ranking der LMSYS Blind Test Arena belegt Yi-Large, das neueste 100-Milliarden-Parameter-Modell von Yi-Large, den 7. Platz weltweit und den 1. Platz unter den großen Modellen in China und übertrifft Llama-3-70B und Claude 3 Sonnet. ; Sein chinesisches Ranking liegt mit GPT4o auf dem ersten Platz der Welt.
Chatbot Arena, herausgegeben von der offenen Forschungsorganisation LMSYS Org (Large Model Systems Organization), hat sich zu einem Kopf-an-Kopf-Wettbewerb für große internationale Unternehmen wie OpenAI, Anthropic, Google und Meta entwickelt und hat auch eine Massenabstimmungsfunktion eröffnet .
Damit ist Lingyiwuwu das einzige große chinesische Modellunternehmen mit eigenen Modellen in den Top Ten der Gesamtliste.
In der Gesamtliste belegt die GPT-Reihe 4 der Top 10. Nach Institutionen sortiert liegt 01W01.AI nach OpenAI, Google und Anthropic an zweiter Stelle und ist offiziell in das weltweit führende große Modellunternehmenslager eingestiegen.
Nun scheint es, dass der Slogan „Werde die Nummer 1 der Welt“ nicht nur ein Slogan ist, sondern er wird.
Der chinesische Score steht weltweit an erster Stelle und der Blindtest „Brain-Burning“ steht weltweit an zweiter Stelle.
Die Blindtestergebnisse der LMSYS Chatboat Arena, die gerade am 20. Mai 2024 (US-Zeit) aktualisiert wurden, basieren auf den tatsächlichen Stimmen von mehr als 11,7 Millionen Nutzern weltweit, die bisher gesammelt wurden.
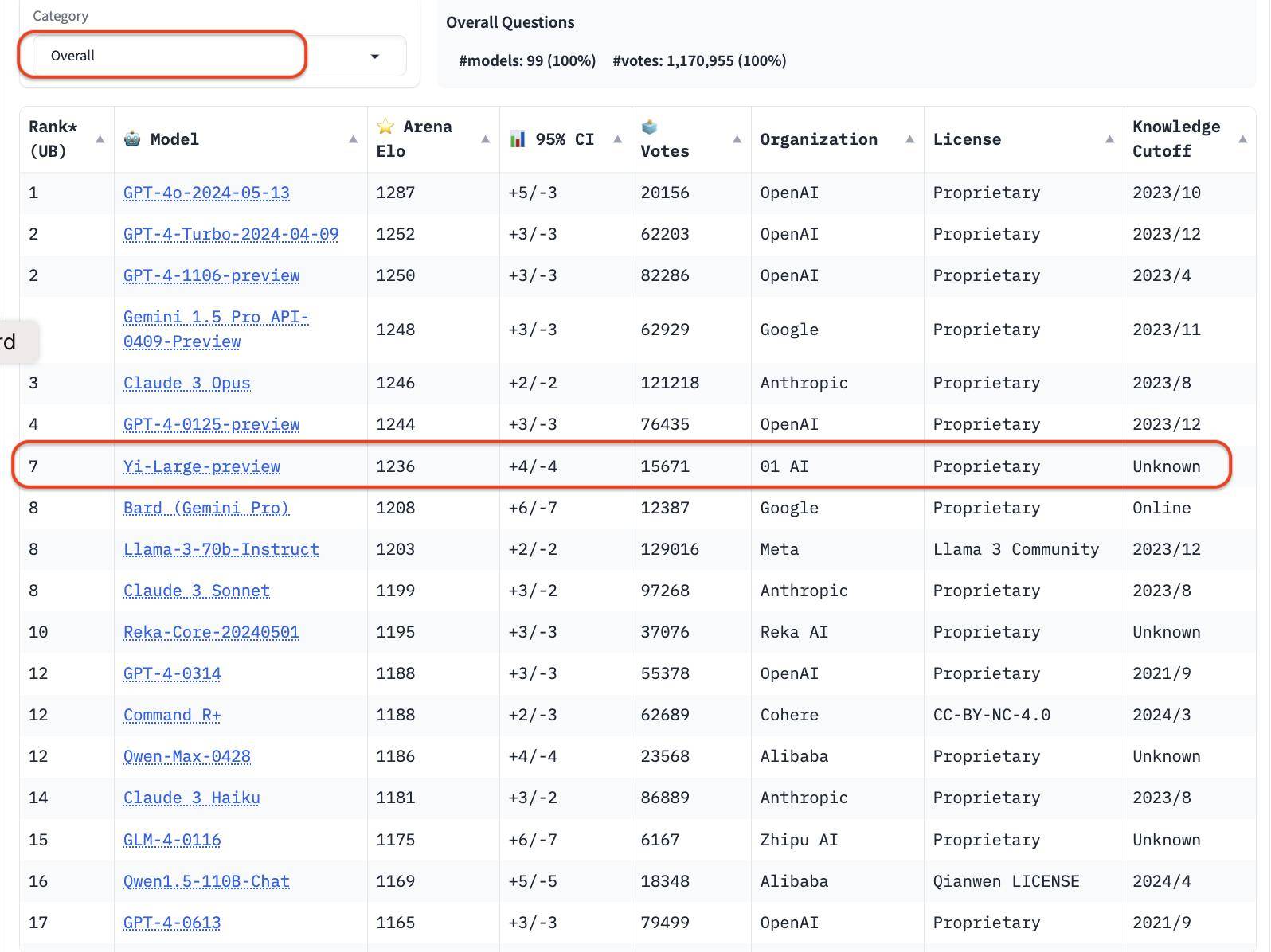
Erwähnenswert ist, dass LMSYS zur Verbesserung der Gesamtqualität der Chatbot Arena-Abfragen auch einen Deduplizierungsmechanismus implementiert und nach dem Entfernen redundanter Abfragen eine Liste herausgegeben hat.
Dieser neue Mechanismus soll übermäßig redundante Benutzeraufforderungen wie beispielsweise sich übermäßig wiederholende „Hallo“ eliminieren, die die Genauigkeit der Rankings beeinträchtigen können.
LMSYS hat öffentlich erklärt, dass die Liste nach dem Entfernen redundanter Abfragen in Zukunft zur Standardliste werden wird.
In der Gesamtliste stieg der Elo-Score von Yi-Large nach dem Entfernen redundanter Abfragen sogar noch weiter und belegte mit Claude 3 Opus und GPT-4-0125-preview den vierten Platz.
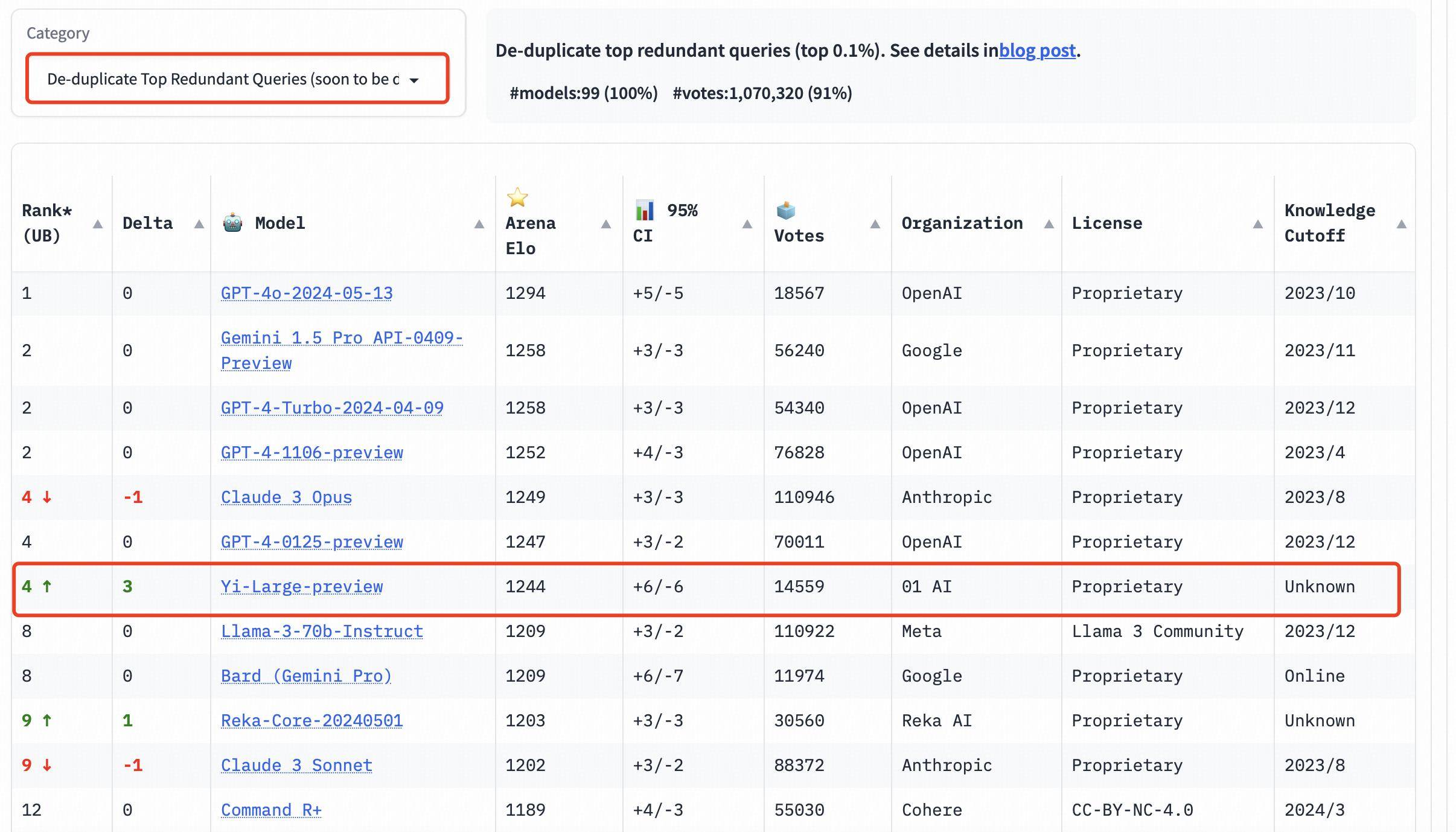
Zusätzlich zur Gesamtliste hat LMSYS drei neue Sprachbewertungen in Englisch, Chinesisch und Französisch hinzugefügt und damit begonnen, sich auf die Vielfalt globaler Großmodelle zu konzentrieren. Yi-Large führte die Liste der chinesischen Sprachen an und belegte gemeinsam mit GPT4o den ersten Platz. Auch auf der Liste der chinesischen Sprachen schnitt GLM-4 gut ab.
Unter den großen inländischen Modellherstellern schnitten sowohl der Qwen-Max von Alibaba als auch der GLM-4 von Zhipu außergewöhnlich gut ab.
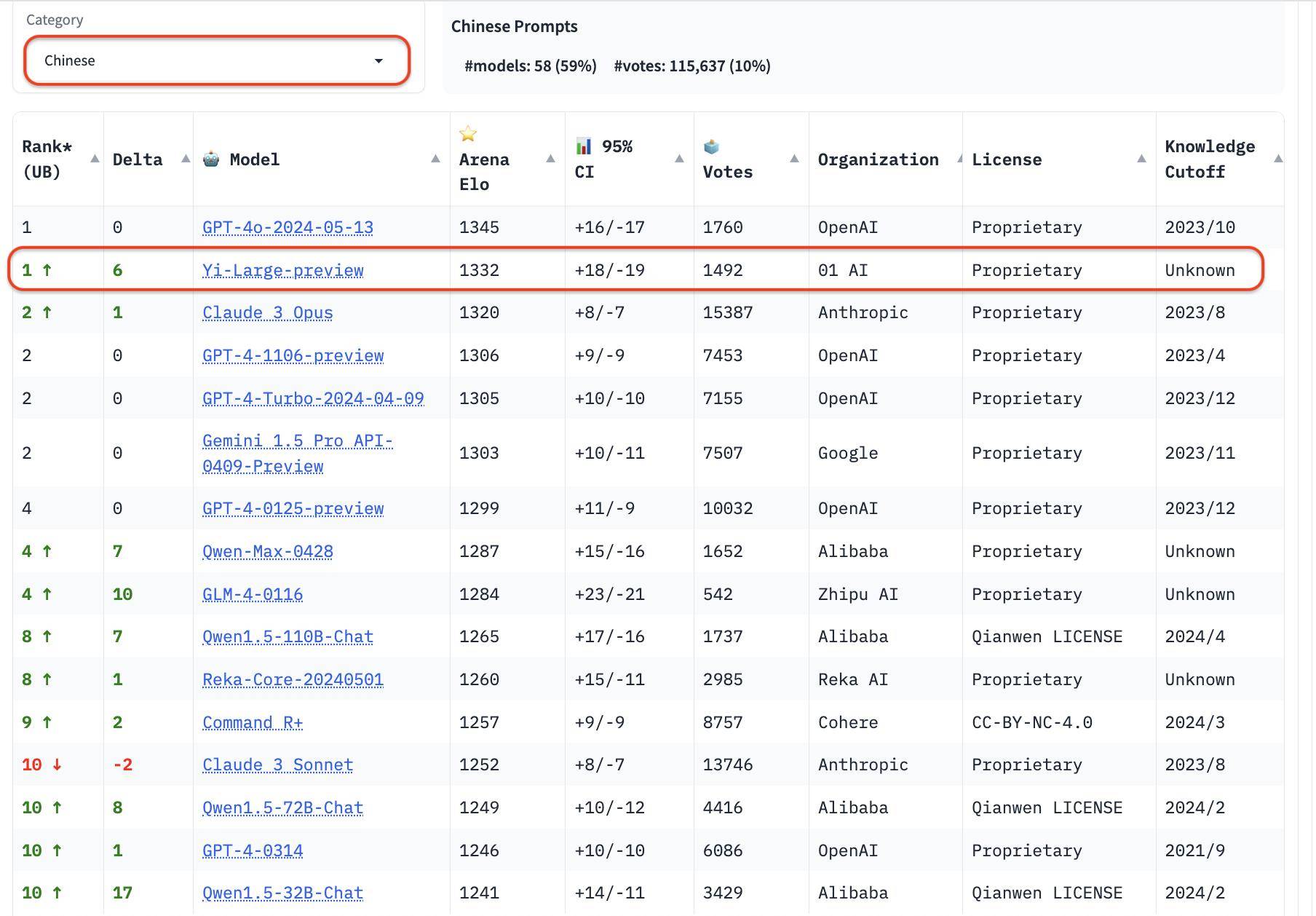
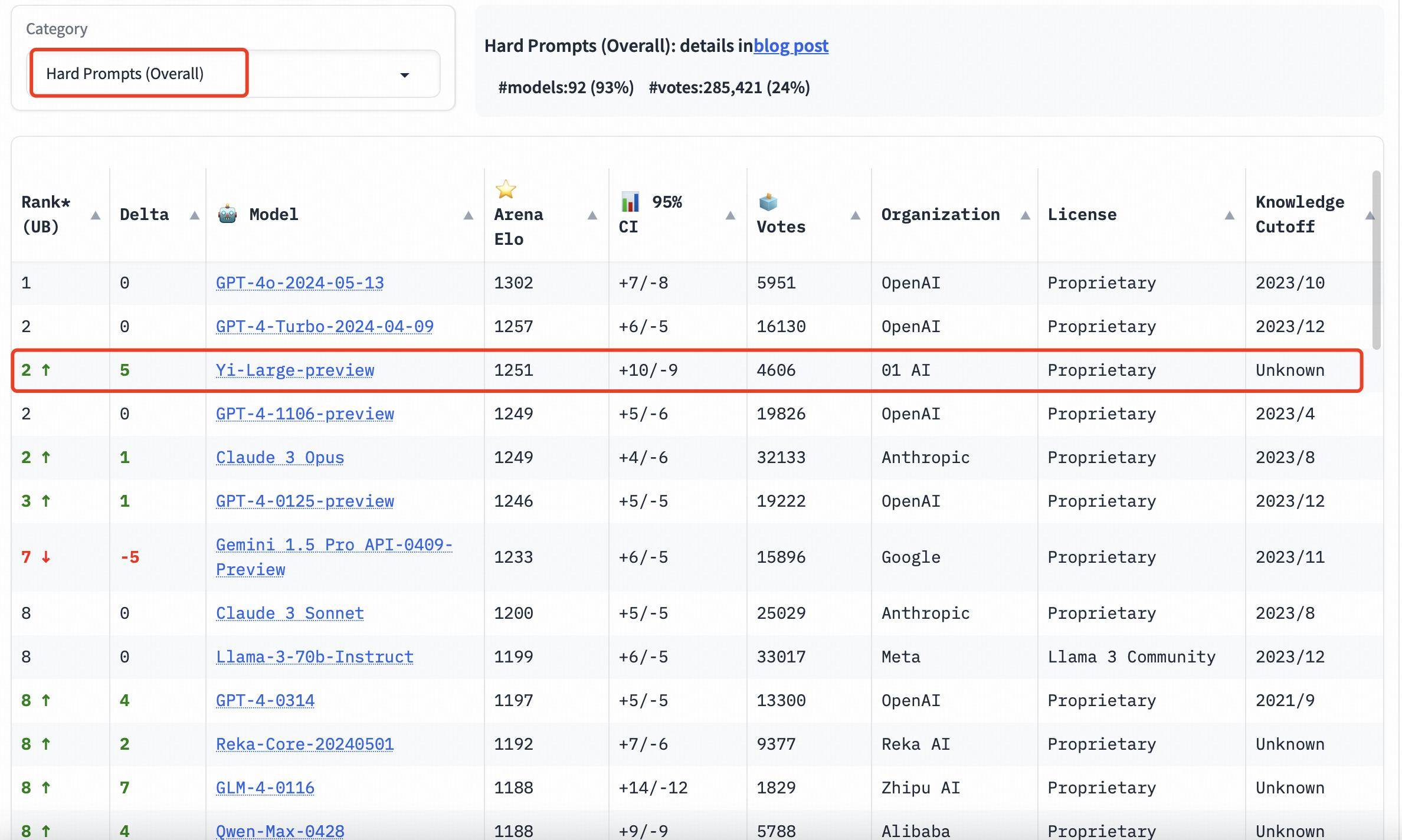
Auch im Kategorieranking schneidet Yi-Large gut ab. Die drei Bewertungen der Programmierfähigkeiten, der langen Fragen und der neuesten „schwierigen Eingabeaufforderungen“ sind zielgerichtete Listen von LMSYS. Sie sind bekannt für ihre Professionalität und ihren hohen Schwierigkeitsgrad. Sie können als die „hirnbrennendsten“ öffentlichen Blindheit bezeichnet werden . Messung.
Die drei Bewertungen der Programmierfähigkeiten, der langen Fragen und der neuesten „schwierigen Eingabeaufforderungen“ sind professionell und schwierig. Er wird auch als der „hirnbrennendste“ öffentliche Blindtest auf der LMSYS-Liste bezeichnet.
In der Rangliste der Programmierfähigkeiten (Codierung) übertrifft der Elo-Score von Yi-Large den Claude 3 Opus von Anthropic, liegt nur unter GPT-4o und belegt mit GPT-4-Turbo und GPT-4 den zweiten Platz;
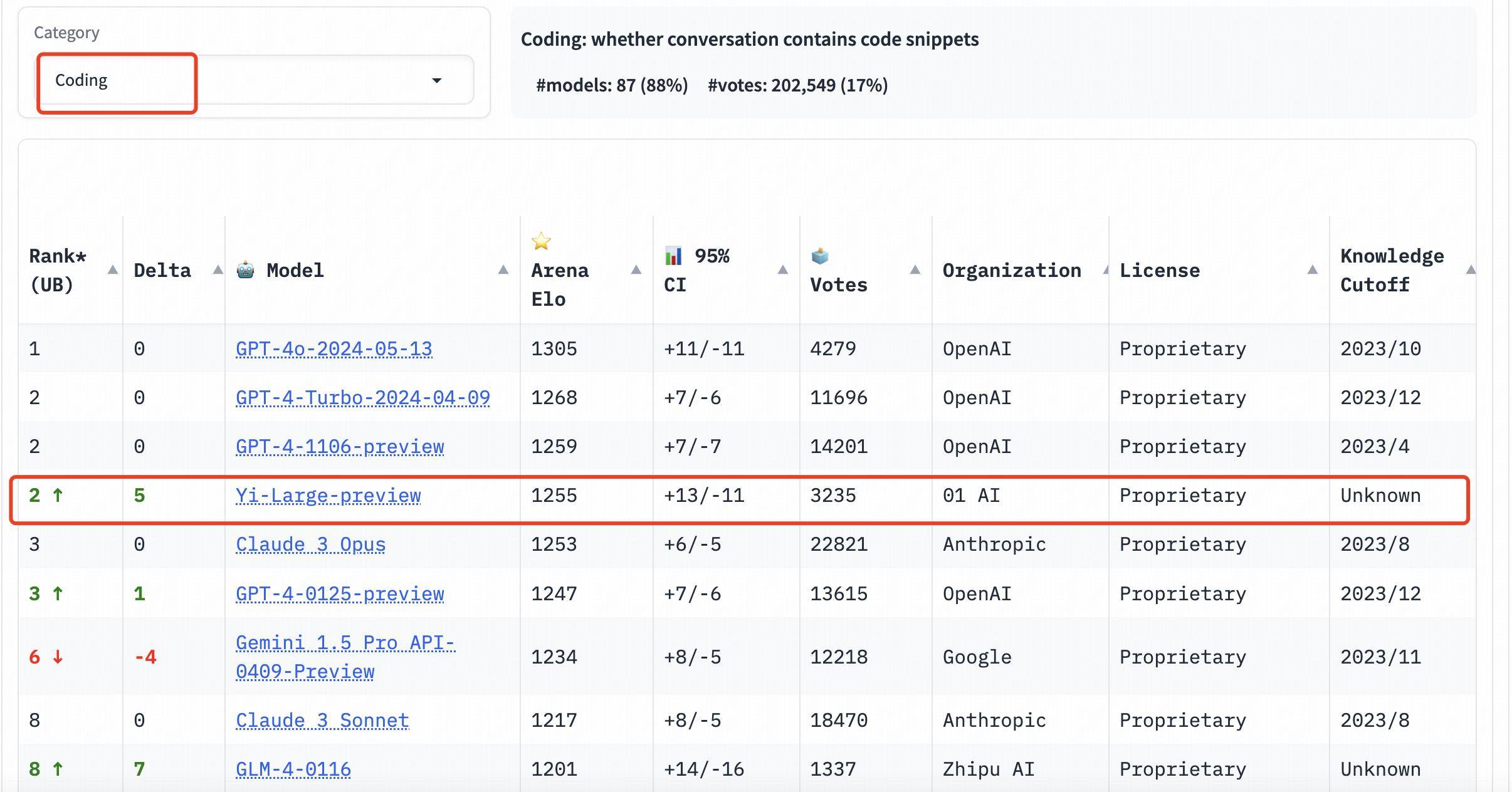
Auf der Liste der längeren Suchanfragen belegt Yi-Large ebenfalls den zweiten Platz weltweit, gleichauf mit GPT-4-Turbo, GPT-4 und Claude 3 Opus;

Auf der Liste der harten Eingabeaufforderungen liegt Yi-Large gemeinsam mit GPT-4-Turbo, GPT-4 und Claude 3 Opus auf dem zweiten Platz.
Nutzen Sie wissenschaftliche Methoden, um objektive Ergebnisse zu erzielen
Die Frage, wie eine objektive und faire Bewertung großer Modelle erfolgen kann, war schon immer ein Thema, das in der Branche große Besorgnis erregte.
Früher gab es in der Branche verschiedene Methoden zum „Swipen der Rankings“, aber diese waren immer nicht in der Lage, die wahren Fähigkeiten großer Modelle widerzuspiegeln, was Menschen, die es verstehen wollen, im Nebel zurücklässt und Investoren in verwandten Branchen sich den Kopf kratzt .
Die von LMSYS Org veröffentlichte Chatbot Arena beginnt, dieses Chaos zu durchbrechen.
Mit seinem neuartigen „Arena“-Format und der Genauigkeit des Testteams ist es zu einem von der globalen Industrie anerkannten Maßstab geworden. Sogar OpenAI wurde vor der offiziellen Veröffentlichung von GPT-4o anonym auf LMSYS vorab veröffentlicht und getestet.
Andrej Karpathy, ein Gründungsmitglied von OpenAI, erklärte sogar öffentlich:
Chatbot Arena ist großartig.
Formal orientiert sich Chatbot Arena an den horizontal vergleichenden Bewertungsideen des Suchmaschinenzeitalters:
- Zunächst werden alle zur Bewertung hochgeladenen „Eintritts“-Modelle zufällig paarweise gepaart und den Benutzern in Form anonymer Modelle präsentiert.
- Dann werden die echten Benutzer aufgefordert, ihre eigenen Aufforderungswörter einzugeben, und die echten Benutzer bewerten die Antworten auf die beiden Modellprodukte, ohne den Modellnamen zu kennen.
- Anschließend werden auf der Blindtestplattform https://arena.lmsys.org/ die großen Modelle paarweise verglichen und der Nutzer stellt selbstständig Fragen zu den großen Modellen ein;
- Modell A und Modell B generieren jeweils die tatsächlichen Ergebnisse von zwei PK-Modellen auf beiden Seiten. Benutzer können unter den Ergebnissen abstimmen, um eines von vier auszuwählen: Modell A ist besser/Modell B ist besser/Beide sind gleichauf/Beide sind nicht gut;
- Nach der Einreichung kann die nächste PK-Runde durchgeführt werden.
Durch Crowdfunding realer Benutzer zur Durchführung von Online-Blindtests und anonymen Abstimmungen in Echtzeit reduziert Chatbot Arena einerseits die Auswirkungen von Vorurteilen und vermeidet andererseits weitestgehend die Möglichkeit von Rankings auf Basis des Testsatzes. Dadurch wird die Objektivität der Endergebnisse erhöht.
Chatbot Arena macht außerdem alle Abstimmungsdaten der Benutzer öffentlich, nachdem sie bereinigt und anonymisiert wurden.
Nach der Erfassung realer Benutzerabstimmungsdaten wird LMSYS Chatbot Arena auch das Elo-Bewertungssystem verwenden, um die Leistung des Modells zu quantifizieren, den Bewertungsmechanismus weiter zu optimieren und sich darum zu bemühen, die Stärke der Teilnehmer fair widerzuspiegeln.
Beim Elo-Bewertungssystem erhält jeder Teilnehmer eine Grundpunktzahl und nach jedem Spiel wird die Punktzahl des Teilnehmers basierend auf den Ergebnissen des Spiels angepasst.
Das System berechnet die Wahrscheinlichkeit, das Spiel zu gewinnen, basierend auf der Bewertung des Teilnehmers. Sobald ein Spieler mit niedriger Punktzahl einen Spieler mit hoher Punktzahl besiegt, erhält der Spieler mit niedriger Punktzahl mehr Punkte und umgekehrt.
Durch die Einführung des Elo-Scoring-Systems gewährleistet LMSYS Chatbot Arena weitgehend die Objektivität und Fairness des Rankings.
Nutzen Sie das Kleine, um Großes zu gewinnen
Insgesamt nahmen dieses Mal 44 Modelle an der Chatbot Arena teil, darunter sowohl das Top-Open-Source-Modell Llama3-70B als auch Closed-Source-Modelle großer Hersteller.
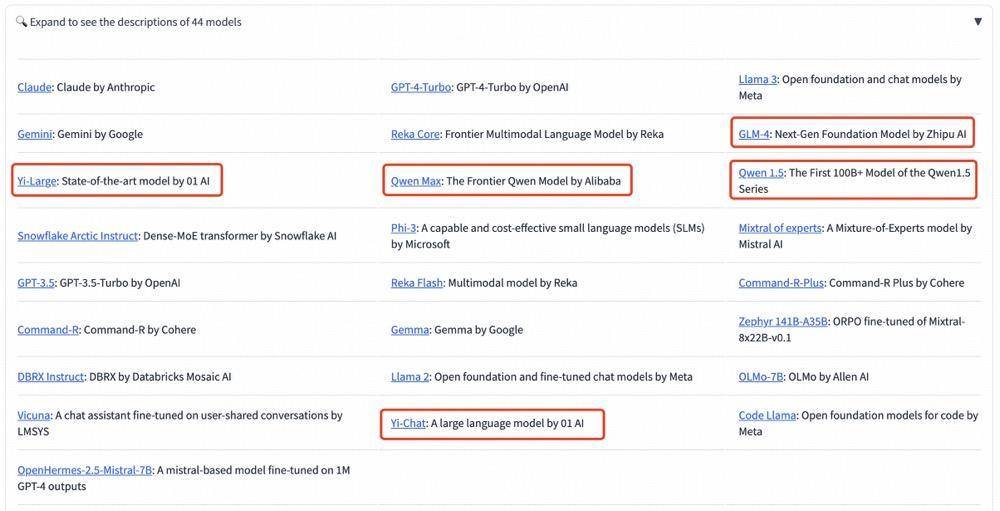
- Dem neuesten Elo-Score nach zu urteilen, führt GPT-4o die Liste mit einem Score von 1287 an;
- GPT-4-Turbo, Gemini 1 5 Pro, Claude 3 0pus, Yi-Large und andere Modelle liegen mit Werten um 1240 in der zweiten Reihe;
- Anschließend fielen die Ergebnisse von Bard (Gemini Pro), Llama-3-70b-Instruct und Claude 3 Sonett von einer Klippe auf etwa 1200 Punkte.
Es ist erwähnenswert, dass die Top-6-Modelle zu den ausländischen Giganten OpenAI, Google und Anthropic gehören. Zero-One Wansheng liegt weltweit an vierter Stelle und Modelle wie GPT-4 und Gemini 1.5 Pro verfügen alle über Parameter auf Billionenebene ist das Flaggschiffmodell der Größenordnung, und andere Modelle liegen ebenfalls auf der Parameterebene von Hunderten von Milliarden.
Yi-Large „nimmt klein, um groß zu gewinnen“ und folgt mit einem Parameterniveau von nur 100 Milliarden dicht dahinter.

Die wettbewerbsorientierte Entwicklung großer KI-Modelle befindet sich noch in einem harten Stadium, und der „Kampf der Hunderte von Modellen“ der künstlichen Intelligenz wird in diesem Bereich weiterhin ausgetragen, wobei „Wochen“ oder sogar „Tage“ als Iterationseinheiten verwendet werden. Besonders wichtig ist ein relativ faires und objektives Bewertungssystem.
Eine Bewertungsplattform, die das Bewertungssystem kontinuierlich aktualisiert, kann es nicht nur Brancheninvestoren ermöglichen, den wahren Stand der technologischen Entwicklung zu erkennen, sondern auch Benutzern das Recht geben, fortschrittliche Modelle auszuwählen, und kann auch die gesunde Entwicklung der gesamten großen Modellindustrie fördern .
Ob zur Iteration ihrer eigenen Modellfähigkeiten oder aus der Perspektive einer langfristigen Reputation: Große Modellhersteller sollten sich aktiv an maßgeblichen Bewertungsplattformen wie Chatbot Arena beteiligen, um ihre Produkte durch tatsächliches Benutzerfeedback und professionelle Bewertungsmechanismen zu beweisen.
Im Gegenteil, wenn Sie sich nur um die Ergebnisse der Rangliste kümmern und den tatsächlichen Anwendungseffekt des Modells ignorieren, wird die Kluft zwischen den Modellfähigkeiten und der Marktnachfrage deutlicher und es wird letztendlich schwierig, in der hart umkämpften KI Fuß zu fassen Marktwettbewerb.
Wenn große Modellhersteller im Zeitalter der KI exzellent oder sogar erstklassig sein wollen, brauchen sie mindestens zwei Eigenschaften:
- Dreimal am Tag muss ich mich selbst überprüfen: Erfahrungen sammeln durch Fortschritte und Antworten durch Wettbewerb erhalten;
- Wahres Gold hat keine Angst vor Feuer: Anstatt auf der „Wild List“ an erster Stelle zu stehen, ist es besser, nach innen zu schauen und seine wahren Fähigkeiten zu verbessern.
Es lohnt sich, darauf zu blicken, dass es mittlerweile eine Gruppe exzellenter heimischer Großmodellhersteller gibt, die bodenständig, innovativ in Forschung und Entwicklung sind und auch auf internationaler Ebene mit den Branchenriesen konkurrieren können.
LMSYS Chatbot Arena Blind Test Arena öffentliche Abstimmungsadresse: https://arena.lmsys.org/
LMSYS Chatbot Leaderboard-Bewertungsranking (laufendes Update): https://chat.lmsys.org/?leaderboard
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo