
DeepSeek dominiert den App Store, eine Woche, in der chinesische KI ein Erdbeben in der US-amerikanischen Technologiewelt verursachte

In der vergangenen Woche hat das DeepSeek-R1-Modell aus China die gesamte ausländische KI-Szene aufgewühlt.
Einerseits erreicht es eine mit OpenAI o1 vergleichbare Leistung bei geringeren Schulungskosten, was die Vorteile Chinas in Bezug auf technische Fähigkeiten und Skalierungsinnovation demonstriert, andererseits hält es auch den Open-Source-Geist aufrecht und ist bestrebt, technische Details zu teilen.
Kürzlich hat ein Forschungsteam von Jiayi Pan, einem Doktoranden an der University of California, Berkeley, die Schlüsseltechnologie von DeepSeek R1-Zero – den „Aha-Moment“ – zu sehr geringen Kosten (weniger als in den USA) reproduziert 30 $).

Kein Wunder also, dass Meta-CEO Zuckerberg, Turing-Award-Gewinner Yann LeCun und Deepmind-CEO Demis Hassabis alle lobend über DeepSeek sprachen.
Da die Beliebtheit von DeepSeek R1 weiter zunimmt, war die DeepSeek-App heute Nachmittag aufgrund eines Anstiegs der Benutzerbesuche vorübergehend überlastet und stürzte sogar zeitweise ab.
Sam Altman, CEO von OpenAI, hat gerade versucht, die Nutzungsbeschränkung von o3-mini offenzulegen, um Schlagzeilen in den internationalen Medien zu machen – ChatGPT Plus-Mitglieder können 100 Mal am Tag Anfragen stellen.
Was jedoch wenig bekannt ist, ist, dass die Muttergesellschaft von DeepSeek, Huanfang Quantitative, vor ihrem Ruhm tatsächlich eines der führenden Unternehmen im inländischen quantitativen Private-Equity-Bereich war.
Das DeepSeek-Modell schockierte das Silicon Valley und sein Goldgehalt steigt immer noch
Am 26. Dezember 2024 veröffentlichte DeepSeek offiziell das große Modell DeepSeek-V3.
Dieses Modell weist in mehreren Benchmark-Tests eine hervorragende Leistung auf und übertrifft die gängigen Topmodelle der Branche, insbesondere in Bereichen wie Wissensfragen und -antworten, Langtextverarbeitung, Codegenerierung und mathematische Fähigkeiten. Beispielsweise liegt die Leistung von DeepSeek-V3 bei Wissensaufgaben wie MMLU und GPQA nahe am internationalen Spitzenmodell Claude-3.5-Sonnet.
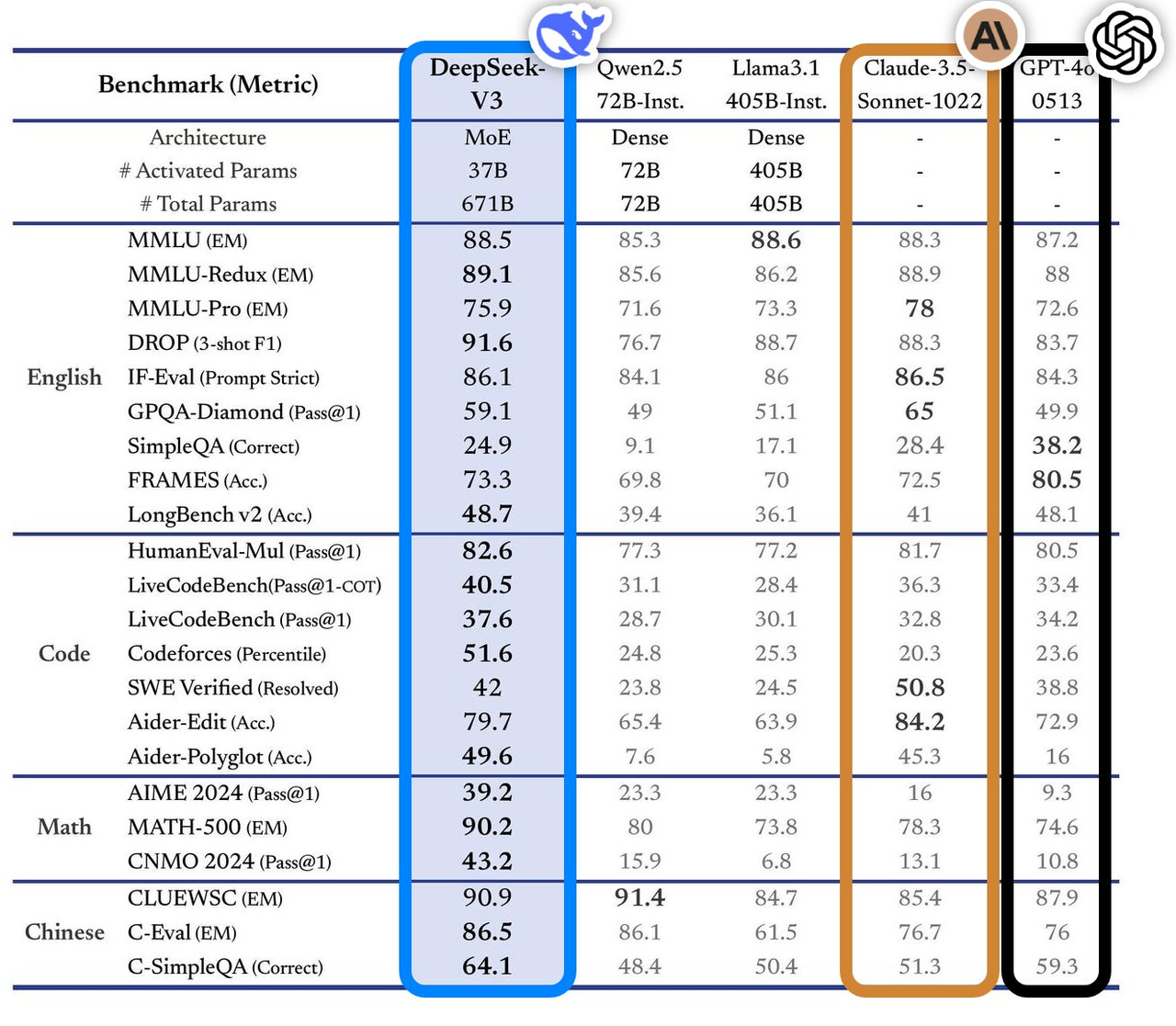
In Bezug auf die mathematischen Fähigkeiten hat es in Tests wie AIME 2024 und CNMO 2024 neue Rekorde aufgestellt und alle bekannten Open-Source- und Closed-Source-Modelle übertroffen. Gleichzeitig ist die Generierungsgeschwindigkeit im Vergleich zur Vorgängergeneration um 200 % auf 60 TPS gestiegen, was das Benutzererlebnis erheblich verbessert.
Laut der Analyse der unabhängigen Bewertungswebsite Artificial Analysis übertrifft DeepSeek-V3 andere Open-Source-Modelle in vielen Schlüsselindikatoren und liegt in der Leistung auf Augenhöhe mit den weltweit führenden Closed-Source-Modellen GPT-4o und Claude-3.5-Sonnet.
Zu den wichtigsten technischen Vorteilen von DeepSeek-V3 gehören:
- Mixed Expert (MoE)-Architektur: DeepSeek-V3 verfügt über 671 Milliarden Parameter, aber im tatsächlichen Betrieb werden nur 37 Milliarden Parameter für jede Eingabe aktiviert. Diese selektive Aktivierungsmethode reduziert die Rechenkosten erheblich und sorgt gleichzeitig für eine hohe Leistung.
- Multi-Head Latent Attention (MLA): Diese Architektur hat sich in DeepSeek-V2 bewährt und kann effizientes Training und Inferenz erreichen.
- Lastausgleichsstrategie ohne Hilfsverluste: Diese Strategie soll die negativen Auswirkungen des Lastausgleichs auf die Modellleistung minimieren.
- Trainingsziel für Multi-Token-Vorhersage: Diese Strategie verbessert die Gesamtleistung des Modells.
- Effizientes Trainings-Framework: Mithilfe des HAI-LLM-Frameworks werden 16-Wege-Pipeline-Parallelität (PP), 64-Wege-Experten-Parallelität (EP) und ZeRO-1-Datenparallelität (DP) unterstützt und die Schulungskosten durch eine Vielzahl von Optimierungsmethoden gesenkt .
Noch wichtiger ist, dass die Schulungskosten von DeepSeek-V3 nur 5,58 Millionen US-Dollar betragen, was viel niedriger ist als bei GPT-4, wo die Schulungskosten 78 Millionen US-Dollar betragen. Darüber hinaus sind die API-Servicepreise auch in der Vergangenheit weiterhin kundenfreundlich.
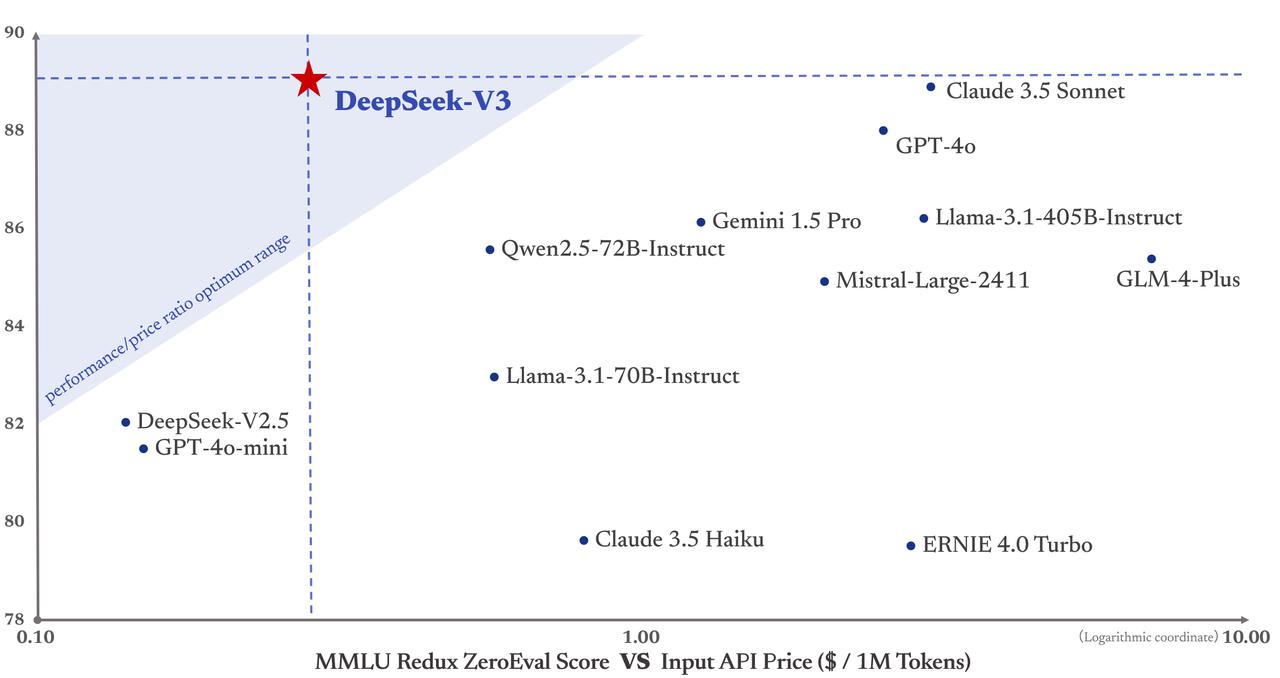
Eingabe-Token kosten nur 0,5 Yuan (Cache-Hit) oder 2 Yuan (Cache-Miss) pro Million, und Ausgabe-Token kosten nur 8 Yuan pro Million.
Die Financial Times beschrieb es als „ein dunkles Pferd, das die internationale Technologiegemeinschaft schockierte“ und glaubte, dass seine Leistung mit der von amerikanischen Konkurrenzmodellen wie dem gut finanzierten OpenAI vergleichbar sei. Maginative-Gründer Chris McKay wies weiter darauf hin, dass der Erfolg von DeepSeek-V3 die etablierten Methoden der KI-Modellentwicklung neu definieren könnte.
Mit anderen Worten: Der Erfolg von DeepSeek-V3 wird auch als direkte Reaktion auf die US-Exportbeschränkungen für Rechenleistung gesehen. Dieser externe Druck hat stattdessen Chinas Innovation stimuliert.
DeepSeek-Gründer Liang Wenfeng, ein zurückhaltendes Genie an der Zhejiang-Universität
Der Aufstieg von DeepSeek hat das Silicon Valley schlaflos gemacht. Liang Wenfeng, der Gründer dieses Modells, das die globale KI-Industrie aufgewühlt hat, erklärt perfekt den Wachstumspfad von Genies im traditionellen chinesischen Sinne – junger Erfolg, dauerhafter Erfolg.
Ein guter KI-Unternehmensleiter muss sowohl Technologie als auch Geschäft verstehen, sowohl visionär als auch pragmatisch sein, den Mut zur Innovation haben und über technische Disziplin verfügen. Diese Art von zusammengesetztem Talent ist eine knappe Ressource.
Im Alter von 17 Jahren wurde er an der Zhejiang-Universität mit Schwerpunkt Informations- und Elektrotechnik aufgenommen. Im Alter von 30 Jahren gründete er Hquant und begann, das Team zu leiten, das sich mit der Erforschung des vollautomatischen quantitativen Handels befasste. Die Geschichte von Liang Wenfeng beweist, dass Genies immer das Richtige zur richtigen Zeit tun.

- 2010: Mit der Einführung der CSI 300-Aktienindex-Futures eröffneten quantitative Investitionen Entwicklungschancen. Das Huanfang-Team nutzte die Dynamik und seine selbst verwalteten Fonds wuchsen schnell.
- 2015: Liang Wenfeng war Mitbegründer von Magic Square Quantification mit seinen Alumni. Im folgenden Jahr brachte er das erste KI-Modell auf den Markt und führte Handelspositionen ein, die durch Deep Learning generiert wurden.
- 2017: Huanfang Quantitative behauptet, eine umfassende KI-basierte Anlagestrategie umzusetzen.
- 2018: KI als Hauptentwicklungsrichtung des Unternehmens etablieren.
- 2019: Der Umfang der Fondsverwaltung überstieg 10 Milliarden Yuan und wurde zu einem der „vier Giganten“ des inländischen quantitativen Private Equity.
- 2021: Huanfang Quantitative wird das erste inländische quantitative Private-Equity-Unternehmen mit einem Umfang von mehr als 100 Milliarden.
Man kann nicht einfach erfolgreich sein und an das Unternehmen denken, das die letzten Jahre am Rande gestanden hat. Doch genau wie die Umstellung quantitativer Handelsunternehmen auf KI mag es unerwartet erscheinen, ist aber eigentlich logisch – denn es handelt sich allesamt um datengesteuerte, technologieintensive Branchen.
Huang Renxun wollte nur Spielgrafikkarten verkaufen, um Geld für diejenigen von uns zu verdienen, die schlecht im Spielen sind, aber er hatte nicht damit gerechnet, das größte KI-Arsenal der Welt zu werden. Es ähnelt Huanfangs Einstieg in den KI-Bereich. Eine solche Entwicklung ist praktikabler als die groß angelegten KI-Modelle, die viele Branchen derzeit mechanisch anwenden.
Magic Square Quantitative hat im Prozess der quantitativen Investition viel Erfahrung in der Datenverarbeitung und Algorithmusoptimierung gesammelt und verfügt außerdem über eine große Anzahl von A100-Chips, die eine starke Hardwareunterstützung für das Training von KI-Modellen bieten. Seit 2017 setzt Huanfang KI-Rechenleistung in großem Umfang ein und baut Hochleistungs-Rechencluster wie „Yinghuo 1“ und „Yinghuo 2“, um leistungsstarke Rechenleistungsunterstützung für das KI-Modelltraining bereitzustellen.

Im Jahr 2023 gründete Magic Square Quantification offiziell DeepSeek, um sich auf die Entwicklung großer KI-Modelle zu konzentrieren. DeepSeek übernahm die Ansammlung von Technologie, Talenten und Ressourcen von Magic Quantitative und etablierte sich schnell im Bereich der KI.
In einem ausführlichen Interview mit „Undercurrent“ zeigte DeepSeek-Gründer Liang Wenfeng zudem eine einzigartige strategische Vision.
Im Gegensatz zu den meisten chinesischen Unternehmen, die sich dafür entscheiden, die Llama-Architektur zu kopieren, geht DeepSeek direkt von der Modellstruktur aus, nur um das ehrgeizige Ziel von AGI zu erreichen.
Liang Wenfeng macht aus der aktuellen Kluft keinen Hehl. Es besteht derzeit eine erhebliche Kluft zwischen Chinas KI und den führenden internationalen Ebenen. Die umfassende Kluft in der Modellstruktur, der Trainingsdynamik und der Dateneffizienz erfordert die vierfache Rechenleistung, um den gleichen Effekt zu erzielen.

▲Bild vom Screenshot von CCTV News
Diese Einstellung, sich Herausforderungen direkt zu stellen, ist auf Liang Wenfengs jahrelange Erfahrung in Huanfang zurückzuführen.
Er betonte, dass Open Source nicht nur Technologieaustausch sei, sondern auch ein kultureller Ausdruck. Der wahre Vorteil liege in der kontinuierlichen Innovationsfähigkeit des Teams. Die einzigartige Organisationskultur von DeepSeek fördert Bottom-up-Innovationen, spielt Hierarchien herunter und schätzt die Leidenschaft und Kreativität von Talenten.
Das Team besteht hauptsächlich aus jungen Leuten von Spitzenuniversitäten und wendet ein natürliches Arbeitsteilungsmodell an, um den Mitarbeitern die Möglichkeit zu geben, unabhängig zu erkunden und zusammenzuarbeiten. Bei der Rekrutierung legen wir Wert auf die Leidenschaft und Neugier der Mitarbeiter und nicht auf Erfahrung und Hintergrund im herkömmlichen Sinne.
Was die Branchenaussichten betrifft, ist Liang Wenfeng davon überzeugt, dass sich die KI eher in einer explosionsartigen Phase der technologischen Innovation als in einer explosionsartigen Phase der Anwendung befindet. Er betonte, dass China mehr originelle technologische Innovationen brauche und nicht für immer in der Nachahmungsphase bleiben könne. Es brauche Menschen, die an der Spitze der Technologie stehen.
Auch wenn Unternehmen wie OpenAI derzeit führend sind, bestehen immer noch Möglichkeiten für Innovationen.

Deepseek stürzt das Silicon Valley auf den Kopf und sorgt für Unruhe in ausländischen KI-Kreisen
Obwohl die Branche unterschiedliche Meinungen zu DeepSeek hat, haben wir auch einige Kommentare von Brancheninsidern gesammelt.
Jim Fan, NVIDIA GEAR Lab-Projektleiter, lobte DeepSeek-R1.
Er wies darauf hin, dass dies bedeutet, dass Nicht-US-Unternehmen die ursprüngliche offene Mission von OpenAI erfüllen und durch die Offenlegung ursprünglicher Algorithmen und Lernkurven Einfluss gewinnen. Dies beinhaltet übrigens auch eine Welle von OpenAI.
DeepSeek-R1 stellte nicht nur eine Reihe von Modellen als Open Source zur Verfügung, sondern enthüllte auch alle Trainingsgeheimnisse. Sie könnten die ersten Open-Source-Projekte sein, die das signifikante und kontinuierliche Wachstum des RL-Schwungrads demonstrieren.
Einfluss kann durch legendäre Projekte wie „ASI Internal Implementation“ oder „Strawberry Project“ oder einfach durch die Offenlegung des ursprünglichen Algorithmus und der Matplotlib-Lernkurve erreicht werden.
Marc Andreesen, Gründer von A16Z, einem führenden Risikokapitalunternehmen an der Wall Street, glaubt, dass DeepSeek R1 einer der überraschendsten und beeindruckendsten Durchbrüche ist, die er je gesehen hat. Als Open Source ist es ein weitreichendes Geschenk an die Welt.
Lu Jing, ein ehemaliger leitender Forscher bei Tencent und Postdoktorand für künstliche Intelligenz an der Universität Peking, analysierte aus der Perspektive der Technologieakkumulation. Er wies darauf hin, dass DeepSeek nicht plötzlich populär geworden sei. Es habe viele Innovationen in der Modellversion der vorherigen Generation geerbt, und es sei unvermeidlich, die Branche zu erschüttern.
Yann LeCun, Gewinner des Turing-Preises und Chef-KI-Wissenschaftler von Meta, brachte eine neue Perspektive vor:
„Für diejenigen, die denken, „China übertrifft die Vereinigten Staaten in Sachen KI“, nachdem sie die Leistung von DeepSeek gesehen haben, ist Ihre Interpretation falsch.“ Die richtige Interpretation sollte lauten: „Das Open-Source-Modell übertrifft das proprietäre Modell.“ "
Die Kommentare von Demis Hassabis, CEO von Deepmind, ließen einen Anflug von Besorgnis erkennen:
„Was es (DeepSeek) erreicht hat, ist sehr beeindruckend, und ich denke, wir müssen darüber nachdenken, wie wir die Führung der westlichen Grenzmodelle beibehalten können. Ich denke, der Westen ist immer noch vorne, aber China verfügt sicherlich über extrem starke technische und Skalierungskapazitäten.“ "
Satya Nadella, CEO von Microsoft, sagte auf dem Weltwirtschaftsforum in Davos, Schweiz, dass DeepSeek effektiv ein Open-Source-Modell entwickelt habe, das nicht nur bei Inferenzberechnungen gute Leistungen erbringt, sondern auch beim Supercomputing äußerst effizient ist.
Er betonte, dass Microsoft auf diese bahnbrechenden Entwicklungen in China mit höchster Priorität reagieren müsse.
Die Bewertung von Meta-CEO Zuckerberg war ausführlicher. Er glaubte, dass die technische Stärke und Leistung von DeepSeek beeindruckend seien, und wies darauf hin, dass die KI-Lücke zwischen China und den Vereinigten Staaten bereits minimal sei und China den vollen Sprint geschafft habe Wettbewerb intensiver.
Die Reaktion der Konkurrenz ist vielleicht die beste Bestätigung für DeepSeek. Berichten von Meta-Mitarbeitern der anonymen Arbeitsplatz-Community TeamBlind zufolge hat das Aufkommen von DeepSeek-V3 und R1 das generative KI-Team von Meta in Panik versetzt.
Meta-Ingenieure liefern sich einen Wettlauf mit der Zeit, um die Technologie von DeepSeek zu analysieren und zu versuchen, jede mögliche Technologie daraus zu kopieren.
Der Grund dafür ist, dass die Schulungskosten von DeepSeek-V3 nur 5,58 Millionen US-Dollar betragen, was nicht einmal so viel ist wie das Jahresgehalt einiger Meta-Führungskräfte. Eine solche Diskrepanz im Input-Output-Verhältnis setzt das Meta-Management bei der Erklärung seines enormen KI-Forschungs- und Entwicklungsbudgets unter großen Druck.

Auch die internationalen Mainstream-Medien haben dem Aufstieg von DeepSeek große Aufmerksamkeit geschenkt.
Die Financial Times wies darauf hin, dass der Erfolg von DeepSeek das traditionelle Verständnis, dass „KI-Forschung und -Entwicklung auf enormen Investitionen beruhen muss“, untergraben hat und beweist, dass präzise technische Wege auch hervorragende Forschungsergebnisse erzielen können. Noch wichtiger ist, dass der selbstlose Austausch technologischer Innovationen durch das DeepSeek-Team dieses Unternehmen, das mehr Wert auf den Forschungswert legt, zu einem außergewöhnlich starken Konkurrenten gemacht hat.
Der Economist gab an, dass seiner Ansicht nach Chinas schnelle Durchbrüche bei der Kosteneffizienz der KI-Technologie begonnen haben, die technologischen Vorteile der Vereinigten Staaten zu erschüttern, was sich auf die Produktivitätsverbesserung und das Wirtschaftswachstumspotenzial der Vereinigten Staaten im nächsten Jahrzehnt auswirken könnte.

Die New York Times greift aus einem anderen Blickwinkel auf. DeepSeek-V3 entspricht in seiner Leistung den High-End-Chatbots amerikanischer Unternehmen, ist jedoch deutlich kostengünstiger.
Dies zeigt, dass chinesische Unternehmen selbst angesichts der Chip-Exportkontrollen durch Innovation und effizienten Ressourceneinsatz wettbewerbsfähig sein können. Darüber hinaus könnte die Chip-Restriktionspolitik der US-Regierung kontraproduktiv sein und stattdessen Chinas innovative Durchbrüche im Bereich der Open-Source-KI-Technologie fördern.
DeepSeek hat „die falsche Tür gemeldet“ und behauptet, GPT-4 zu sein
Trotz des Lobes gab es bei DeepSeek auch einige Kontroversen.
Viele Außenstehende glauben, dass DeepSeek möglicherweise die Ausgabedaten von Modellen wie ChatGPT während des Trainingsprozesses als Schulungsmaterial verwendet hat. Durch die Modelldestillationstechnologie wird das „Wissen“ in diesen Daten auf das eigene Modell von DeepSeek übertragen.
Diese Praxis ist im KI-Bereich nicht ungewöhnlich, Skeptiker sind jedoch besorgt darüber, ob DeepSeek die Ausgabedaten des OpenAI-Modells ohne vollständige Offenlegung verwendet hat. Dies scheint sich im Selbstbewusstsein von DeepSeek-V3 widerzuspiegeln.
Frühere Benutzer stellten fest, dass sich ein Modell bei der Frage nach der Identität mit GPT-4 verwechselte.
Qualitativ hochwertige Daten waren schon immer ein wichtiger Faktor bei der Entwicklung von KI. Auch OpenAI kann sich Kontroversen über die Datenerfassung im Internet nicht entziehen Die New York Times hat in erster Instanz entschieden. Bevor die Anklage geäußert wurde, wurde ein neuer Fall hinzugefügt.
So erhielt DeepSeek auch öffentliche Konnotationen von Sam Altman und John Schulman.
„Es ist (relativ) einfach, etwas zu kopieren, von dem man weiß, dass es funktionieren wird. Es ist sehr schwierig, etwas Neues zu tun, riskant und schwierig, wenn man nicht weiß, ob es funktionieren wird.“

Allerdings machte das DeepSeek-Team im technischen Bericht von R1 deutlich, dass es nicht die Ausgabedaten des OpenAI-Modells nutzte und gab an, dass eine hohe Leistung durch Reinforcement Learning und eine einzigartige Trainingsstrategie erreicht wurde.
Beispielsweise wird eine mehrstufige Trainingsmethode angewendet, die grundlegendes Modelltraining, RL-Training (Reinforcement Learning), Feinabstimmung usw. umfasst. Diese mehrstufige zyklische Trainingsmethode hilft dem Modell, in verschiedenen Phasen unterschiedliche Kenntnisse und Fähigkeiten zu absorbieren.
Geld sparen ist auch eine technische Aufgabe, und die Technologie hinter DeepSeek ist die beste Lösung
Im technischen Bericht von DeepSeek-R1 wurde eine bemerkenswerte Entdeckung erwähnt, nämlich der „Aha-Moment“, der während des R1-Null-Trainingsprozesses auftrat. In der mittleren Trainingsphase des Modells beginnt DeepSeek-R1-Zero damit, die anfänglichen Problemlösungsideen aktiv neu zu bewerten und mehr Zeit für die Optimierung der Strategie einzuplanen (z. B. durch mehrmaliges Ausprobieren verschiedener Lösungen).
Mit anderen Worten: Durch das RL-Framework kann KI spontan menschenähnliche Denkfähigkeiten entwickeln und sogar die Grenzen voreingestellter Regeln überschreiten. Und dies wird hoffentlich auch eine Richtung für die Entwicklung autonomerer und adaptiverer KI-Modelle vorgeben, etwa zur dynamischen Anpassung von Strategien bei komplexen Entscheidungen (medizinische Diagnose, Algorithmendesign).

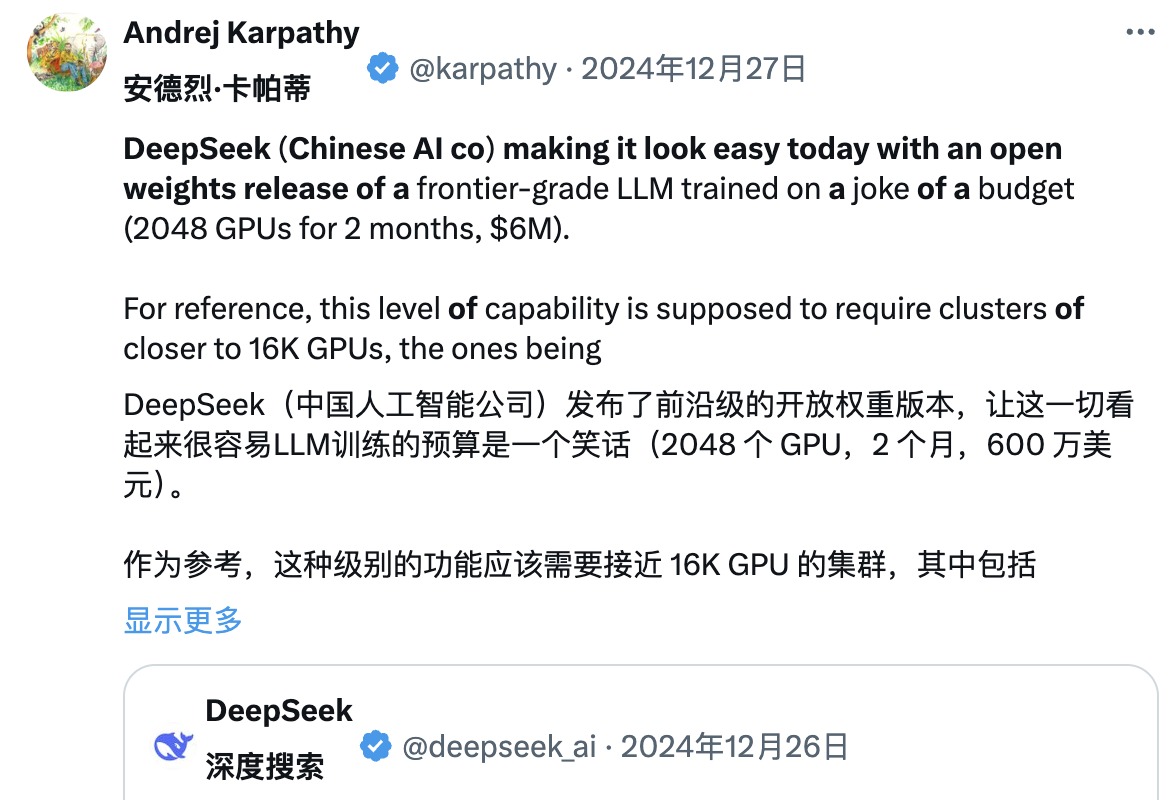
Gleichzeitig versuchen viele Brancheninsider, den technischen Bericht von DeepSeek eingehend zu analysieren. Andrej Karpathy, ehemaliger Mitbegründer von OpenAI, sagte nach der Veröffentlichung von DeepSeek V3:
DeepSeek (das chinesische KI-Unternehmen) fühlt sich heute entspannt. Es hat öffentlich ein hochmodernes Sprachmodell (LLM) veröffentlicht und das Training mit einem extrem niedrigen Budget abgeschlossen (2048 GPUs, dauert 2 Monate, kostet 6 Millionen US-Dollar).
Zur Veranschaulichung: Für diese Funktion ist in der Regel ein Cluster von 16.000 GPUs erforderlich, und die meisten modernen Systeme nutzen etwa 100.000 GPUs. Beispielsweise verbrauchte Llama 3 (405B-Parameter) 30,8 Millionen GPU-Stunden, während DeepSeek-V3 mit nur 2,8 Millionen GPU-Stunden (etwa 1/11 der Berechnung von Llama 3) ein leistungsstärkeres Modell zu sein scheint.
Wenn dieses Modell auch in realen Tests gut abschneidet (die LLM Arena-Rangliste läuft beispielsweise noch und mein Schnelltest hat gut abgeschnitten), dann ist dies ein sehr gutes Beispiel dafür, wie Forschungs- und Ingenieurskompetenzen unter Ressourcenbeschränkungen demonstriert werden können. Beeindruckende Ergebnisse.
Bedeutet das also, dass wir keine großen GPU-Cluster mehr benötigen, um hochmodernes LLM zu trainieren? Nicht wirklich, aber es zeigt, dass man darauf achten muss, dass die eingesetzten Ressourcen nicht verschwendet werden, und dieser Fall zeigt, dass die Optimierung von Daten und Algorithmen dennoch zu großen Fortschritten führen kann. Darüber hinaus ist auch der technische Bericht sehr interessant und ausführlich und lesenswert.
Angesichts der Kontroverse über die Verwendung von ChatGPT-Daten durch DeepSeek V3 sagte Karpathy, dass große Sprachmodelle nicht unbedingt über ein menschenähnliches Selbstbewusstsein verfügen. Awareness-Trainingssatz: Wenn das Modell nicht speziell trainiert ist, antwortet es auf der Grundlage der nächstgelegenen Informationen in den Trainingsdaten.
Darüber hinaus ist die Tatsache, dass sich das Modell als ChatGPT identifiziert, nicht das Problem. Angesichts der Allgegenwärtigkeit von ChatGPT-bezogenen Daten im Internet spiegelt diese Antwort tatsächlich ein natürliches Phänomen der „Entstehung von Wissen in der Nähe“ wider.
Jim Fan wies darauf hin, nachdem er den technischen Bericht von DeepSeek-R1 gelesen hatte:
Der wichtigste Punkt dieses Artikels ist, dass er vollständig auf verstärktem Lernen basiert, ohne dass überwachtes Lernen (SFT) involviert ist. Diese Methode ähnelt AlphaZero – das Beherrschen von Go und Shogi von Grund auf durch „Kaltstart“ und Schach, ohne es zu imitieren das Spiel menschlicher Schachspieler.
– Verwenden Sie echte Belohnungen, die auf der Grundlage fest codierter Regeln berechnet werden, und nicht erlernte Belohnungsmodelle, die durch Reinforcement Learning leicht „gehackt“ werden können.
– Die Denkzeit des Modells nimmt mit fortschreitendem Training stetig zu. Dies ist nicht vorprogrammiert, sondern eine spontane Funktion.
– Es entstehen Selbstreflexion und exploratives Verhalten.
– Verwenden Sie GRPO anstelle von PPO: GRPO entfernt das Kommentatorennetzwerk in PPO und verwendet stattdessen die durchschnittliche Belohnung mehrerer Stichproben. Dies ist eine einfache Möglichkeit, die Speichernutzung zu reduzieren. Es ist erwähnenswert, dass GRPO im Februar 2024 vom DeepSeek-Team erfunden wurde, was wirklich ein sehr starkes Team ist.
Als Kimi am selben Tag auch ähnliche Forschungsergebnisse veröffentlichte, stellte Jim Fan fest, dass die Forschungsergebnisse der beiden Unternehmen das gleiche Ziel erreichten:
- Sie alle gaben komplexe Baumsuchmethoden wie MCTS auf und wandten sich einfacheren linearen Denktrajektorien zu, wobei sie traditionelle autoregressive Vorhersagemethoden verwendeten.
- Alle vermeiden die Verwendung von Wertfunktionen, die zusätzliche Modellkopien erfordern, wodurch der Bedarf an Rechenressourcen reduziert und die Trainingseffizienz verbessert wird.
- Sie alle verzichten auf eine intensive Belohnungsmodellierung und verlassen sich so weit wie möglich auf reale Ergebnisse als Orientierung, um die Stabilität des Trainings sicherzustellen.
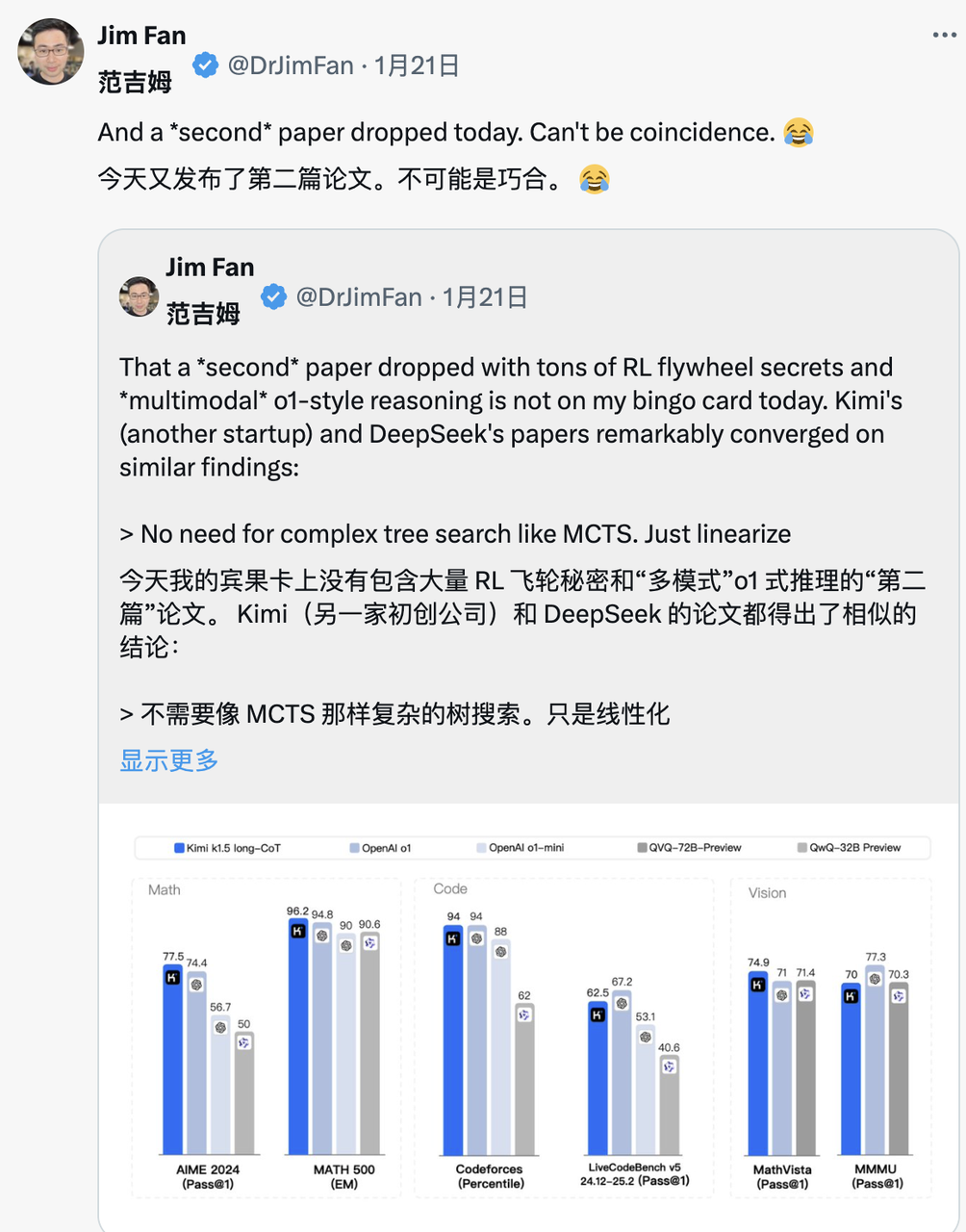
Es gibt aber auch erhebliche Unterschiede zwischen den beiden:
- DeepSeek verwendet die reine RL-Kaltstartmethode im AlphaZero-Stil, Kimi k1.5 wählt die Vorheizstrategie im AlphaGo-Master-Stil und verwendet leichtes SFT
- DeepSeek ist Open Source unter der MIT-Lizenz und Kimi schneidet in multimodalen Benchmark-Tests gut ab. Die Designdetails des Papiersystems sind umfangreicher und decken RL-Infrastruktur, Hybrid-Cluster, Code-Sandboxen und parallele Strategien ab.
In diesem sich schnell entwickelnden KI-Markt ist der Vorsprung jedoch oft nur flüchtig. Andere Modellierungsunternehmen werden schnell aus den Erfahrungen von DeepSeek lernen und diese verbessern und möglicherweise bald aufholen können.
Der Auslöser des großen Modellpreiskampfes
Viele Menschen wissen, dass DeepSeek einen Titel namens „AI Pinduoduo“ hat, aber sie wissen nicht, dass die Bedeutung dahinter tatsächlich auf den großen Preiskampf um Modelle zurückzuführen ist, der letztes Jahr begann.
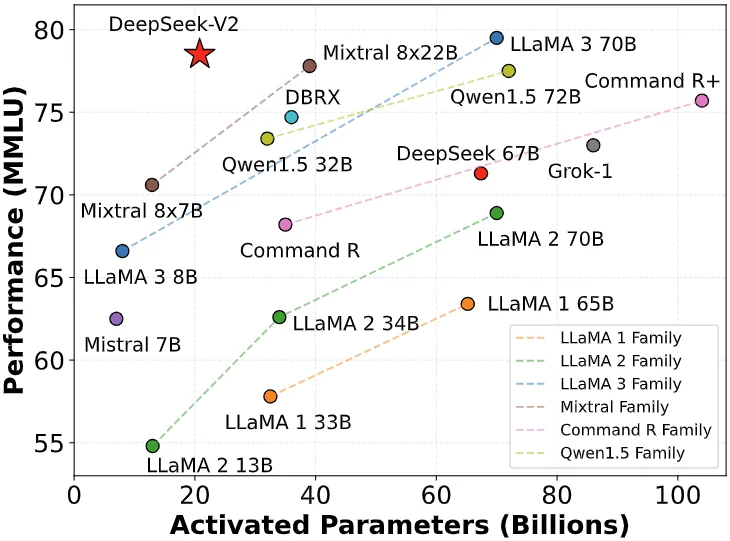
Am 6. Mai 2024 veröffentlichte DeepSeek das Open-Source-MoE-Modell DeepSeek-V2, das durch innovative Architekturen wie MLA (Multi-Head Latent Attention Mechanism) und MoE (Mixed Expert Model) zwei Durchbrüche bei Leistung und Kosten erzielte.
Die Inferenzkosten wurden auf nur 1 Yuan pro Million Token reduziert, was etwa einem Siebtel der Kosten von Llama3 70B und einem Siebzigstel der Kosten von GPT-4 Turbo zu diesem Zeitpunkt entsprach. Dieser technologische Durchbruch ermöglicht es DeepSeek, äußerst kostengünstige Dienste anzubieten, ohne dafür Geld zu verlangen, und übt darüber hinaus einen enormen Wettbewerbsdruck auf andere Hersteller aus.
Die Veröffentlichung von DeepSeek-V2 löste eine Kettenreaktion aus. ByteDance, Baidu, Alibaba, Tencent und Zhipu AI folgten diesem Beispiel und senkten die Preise ihrer großen Modellprodukte deutlich. Die Auswirkungen dieses Preiskampfs erstrecken sich sogar über den Pazifik und lösen im Silicon Valley große Besorgnis aus.
DeepSeek wurde daher als „Pinduoduo der KI“ bezeichnet.
Angesichts der Zweifel der Außenwelt antwortete DeepSeek-Gründer Liang Wenfeng in einem Interview mit Undercurrent:
„Benutzer zu gewinnen ist nicht unser Hauptziel. Einerseits haben wir den Preis gesenkt, weil wir die Struktur des Modells der nächsten Generation untersuchen, und die Kosten sind zuerst gesunken; andererseits sind wir auch der Meinung, dass sowohl API als auch KI sollte inklusiv sein und sich jeder leisten können.“
Tatsächlich geht die Bedeutung dieses Preiskampfes weit über die Konkurrenz selbst hinaus. Niedrigere Eintrittsbarrieren ermöglichen es mehr Unternehmen und Entwicklern, auf modernste KI zuzugreifen und diese anzuwenden, und er zwingt auch die gesamte Branche dazu, Preisstrategien zu überdenken Damit trat DeepSeek in den Fokus der Öffentlichkeit und erlangte Berühmtheit.
Lei Jun gibt Tausende von Dollar aus, um Pferdeknochen zu kaufen, und wirbt KI-geniale Mädchen ab
Vor einigen Wochen vollzog DeepSeek auch eine aufsehenerregende personelle Veränderung.
Laut China Business News hat Lei Jun erfolgreich Luo Fuli mit einem Jahresgehalt von mehreren zehn Millionen abgeworben und ihr die wichtige Aufgabe übertragen, das große Modellteam des Xiaomi AI Lab zu leiten.
Luo Fuli kam 2022 zu DeepSeek, einer Tochtergesellschaft von Magic Square Quantitative. Sie ist in wichtigen Berichten wie DeepSeek-V2 und dem neuesten R1 zu sehen.
Später begann DeepSeek, das sich einst auf die B-Seite konzentrierte, auch mit dem Layout der C-Seite und der Einführung mobiler Anwendungen. Zum Zeitpunkt der Drucklegung belegt die mobile Anwendung von DeepSeek in der kostenlosen Version des App Store von Apple den zweiten Platz und zeigt damit eine starke Wettbewerbsfähigkeit.
Eine Reihe kleinerer Höhepunkte haben DeepSeek berühmt gemacht, aber gleichzeitig gibt es auch höhere Höhepunkte. Am Abend des 20. Januar wurde das ultragroße Modell DeepSeek R1 mit 660B-Parametern offiziell veröffentlicht.
Dieses Modell schneidet bei mathematischen Aufgaben gut ab und erreichte bei AIME 2024 einen Pass@1-Score von 79,8 % .
Bei den Programmieraufgaben erreichte es beispielsweise die Elo-Bewertung 2029 auf Codeforces und übertraf damit 96,3 % der menschlichen Teilnehmer. In Wissensbenchmarks wie MMLU, MMLU-Pro und GPQA Diamond erreichte DeepSeek R1 90,8 %, 84,0 % bzw. 71,5 %, was etwas weniger als OpenAI-o1, aber besser als andere Closed-Source-Modelle ist.
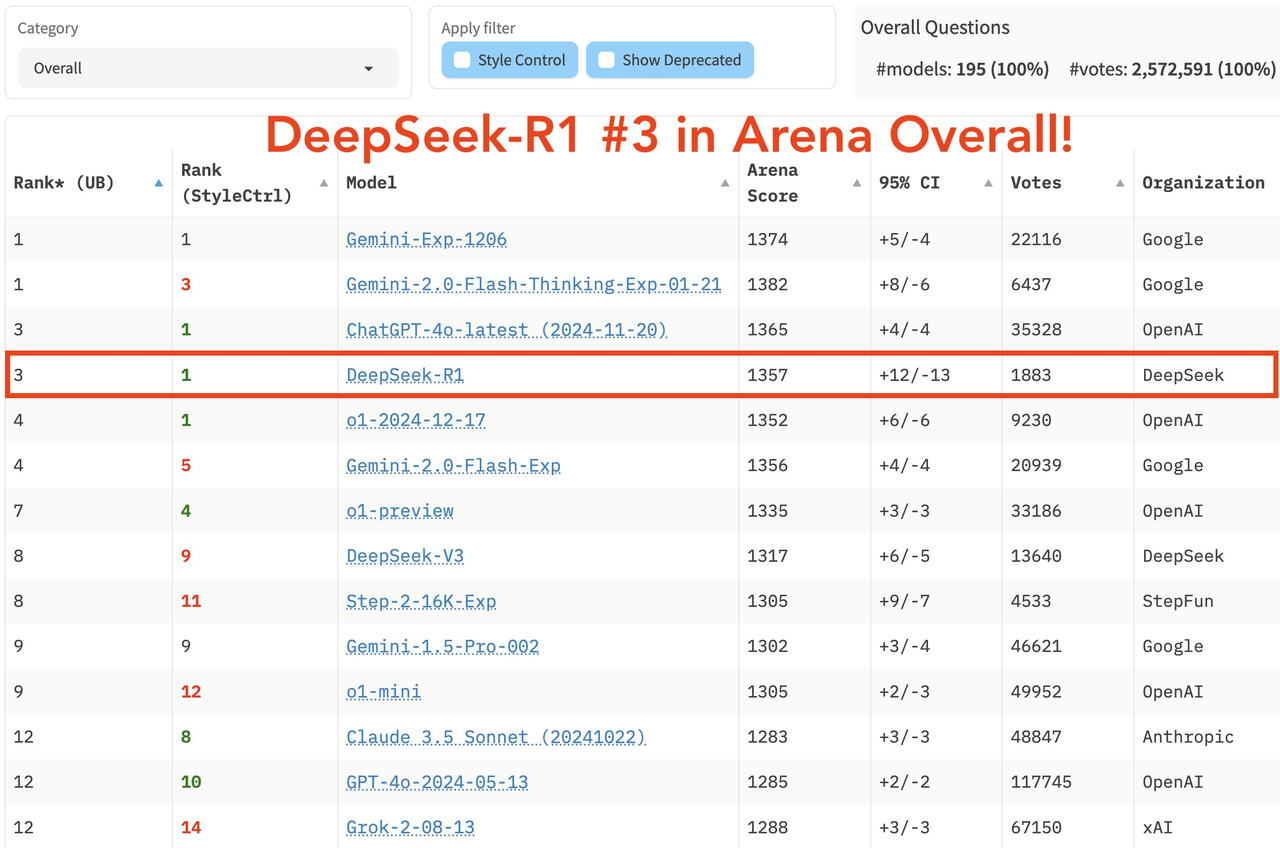
In der neuesten umfassenden Liste der großen Modellarena LM Arena belegte DeepSeek R1 den dritten Platz, gleichauf mit o1.
- In den Bereichen „Hard Prompts“ (schwierige Eingabeaufforderungswörter), „Coding“ (Codierungsfähigkeit) und „Math“ (mathematische Fähigkeiten) belegt DeepSeek R1 den ersten Platz.
- In Sachen „Style Control“ belegten DeepSeek R1 und o1 punktgleich den ersten Platz.
- Im Test „Hard Prompt with Style Control“ belegte DeepSeek R1 ebenfalls punktgleich mit o1 den ersten Platz.
In Bezug auf die Open-Source-Strategie übernimmt R1 die MIT-Lizenz, bietet Benutzern die größte Nutzungsfreiheit und unterstützt die Modelldestillation, mit der Argumentationsfunktionen in kleinere Modelle destilliert werden können. Beispielsweise haben die Modelle 32B und 70B den Benchmark o1-mini erreicht Die Wirkung von Open Source übertrifft sogar das bereits kritisierte Meta.
Das Aufkommen von DeepSeek R1 ermöglicht inländischen Benutzern erstmals die kostenlose Nutzung von O1-Level-Modellen und überwindet so die seit langem bestehenden Informationsbarrieren. Die Begeisterung, die es auf sozialen Plattformen wie Xiaohongshu auslöste, ist vergleichbar mit GPT-4 zum Zeitpunkt seiner Veröffentlichung.
Gehen Sie ans Meer und drehen Sie sich um
Wenn man auf den Entwicklungsverlauf von DeepSeek zurückblickt, ist sein Erfolgskodex klar erkennbar: Stärke ist das Fundament, aber Markenbekanntheit ist der Burggraben.
In einem Gespräch mit „Later“ teilte MiniMax-CEO Yan Junjie ausführlich seine Gedanken zur KI-Branche und den strategischen Veränderungen des Unternehmens mit. Er hob zwei wichtige Wendepunkte hervor: erstens die Anerkennung der Bedeutung des Technologie-Brandings und zweitens das Verständnis des Werts einer Open-Source-Strategie.
Yan Junjie glaubt, dass im Bereich der KI die Geschwindigkeit der technologischen Entwicklung wichtiger ist als aktuelle Errungenschaften, und dass Open Source diesen Prozess durch Community-Feedback beschleunigen kann. Zweitens ist eine starke Technologiemarke entscheidend für die Gewinnung von Talenten und den Erwerb von Ressourcen.
Nehmen wir als Beispiel OpenAI, obwohl es in der späteren Zeit auf Unruhen im Management stieß, sein innovatives Image und sein schon früh etablierter Open-Source-Geist haben ihm einen guten ersten Eindruck beschert. Auch wenn Claude in Zukunft technisch gleichwertig geworden ist und die B-Seitenbenutzer von OpenAI nach und nach ausgeschlachtet hat, liegt OpenAI aufgrund der Pfadabhängigkeit der Benutzer bei C-Seitenbenutzern immer noch weit vorne.
Im Bereich der KI ist die eigentliche Wettbewerbsphase immer global, und auch der Weg ins Ausland, die Involution und die Werbung sind ein guter Weg.

Diese Welle der globalen Expansion hat bereits für Aufsehen in der Branche gesorgt. Die früheren Modelle Qwen, Wall-facing Smart und neuere Modelle DeepSeek R1, Kimi v1.5 und Doubao v1.5 Pro haben im Ausland bereits für großes Aufsehen gesorgt.
Obwohl 2025 als das erste Jahr der intelligenten Körper und das erste Jahr der KI-Brillen bezeichnet wird, wird dieses Jahr auch ein wichtiges erstes Jahr für chinesische KI-Unternehmen sein, um den globalen Markt zu erobern, und die Globalisierung wird zu einem unvermeidlichen Schlüsselwort werden.
Darüber hinaus ist die Open-Source-Strategie auch ein guter Schachzug und lockt viele technische Blogger und Entwickler dazu, spontan zum „Leitungswasser“ von DeepSeek zu werden Durch die Integration von Technologien hat DeepSeek einen reineren Weg eingeschlagen als OpenAI.
Wenn OpenAI uns die Leistungsfähigkeit der KI erkennen lässt, dann lässt uns DeepSeek glauben:
Diese Macht wird letztendlich allen zugute kommen.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo