
Im tatsächlichen Test des Wenxin 4.5T/X1 Dual-Turbo-Modells hat Baidus „Schnitt mit einem Messer“ auch DeepSeek überwältigt

Die von DeepSeek vertretene Open-Source-Strategie hatte nicht nur große Auswirkungen auf die „Six Little Dragons of AI“, sondern übte auch echten Druck auf etablierte Giganten wie Baidu aus.
Doch Baidu, das die Kehrtwende gemacht hat, zeigt nach und nach einen starken Gegenangriff.
Nach der Ankündigung, dass die „Wenxin Large Model 4.5 Series“ am 30. Juni offiziell als Open Source verfügbar sein wird, stellte Baidu, das eine Reihe neuer Produkte herausgebracht hat, heute auf der Create-Konferenz für Entwickler zwei neue Modelle vor: Wenxin 4.5 Turbo und Deep Thinking Model X1 Turbo.
Da sie den Namen Turbo tragen, wurden die Fähigkeiten dieser beiden Modelle in puncto Leistung natürlich vollständig verbessert, wobei der Schwerpunkt auf Multimodalität, überzeugender Argumentation und niedrigen Kosten liegt. Baidus neuer intelligenter Suchassistent Wen Xiaoyan kündigte ebenfalls vollen Zugriff an und steht Benutzern kostenlos zur Verfügung. Ab sofort können Benutzer die Wen Xiaoyan APP verwenden.
Bei dem Treffen machte Baidu-Gründer Robin Li deutlich: „Multimodalität wird in Zukunft zum Standard für Basismodelle werden. Der Markt für reine Textmodelle wird immer kleiner, während der Markt für multimodale Modelle immer größer wird.“
„Natürlich ist DeepSeek nicht allmächtig. Es kann beispielsweise nur Text verarbeiten, Multimedia-Inhalte wie Bilder, Audios und Videos jedoch nicht verstehen und generieren“, glaubt Robin Li. „Das größere Problem besteht darin, dass es langsam und teuer ist. Die meisten API-Aufrufe großer Modelle auf dem chinesischen Markt sind billiger und schneller als die Vollversion von DeepSeek.“
Seiner Meinung nach lösen die heute vorgestellten Großmodelle 4.5 Turbo und X1 Turbo von Wenxin genau diese Probleme.
Basierend auf diesem Urteil stärkt das Wenxin-Großmodell 4.5 Turbo seine multimodalen Fähigkeiten weiter. In mehreren Benchmark-Testsätzen liegen die multimodalen Fähigkeiten von Wenxin 4.5 Turbo auf Augenhöhe mit GPT-4.1 und sind in einigen Dimensionen sogar besser als GPT-4o.
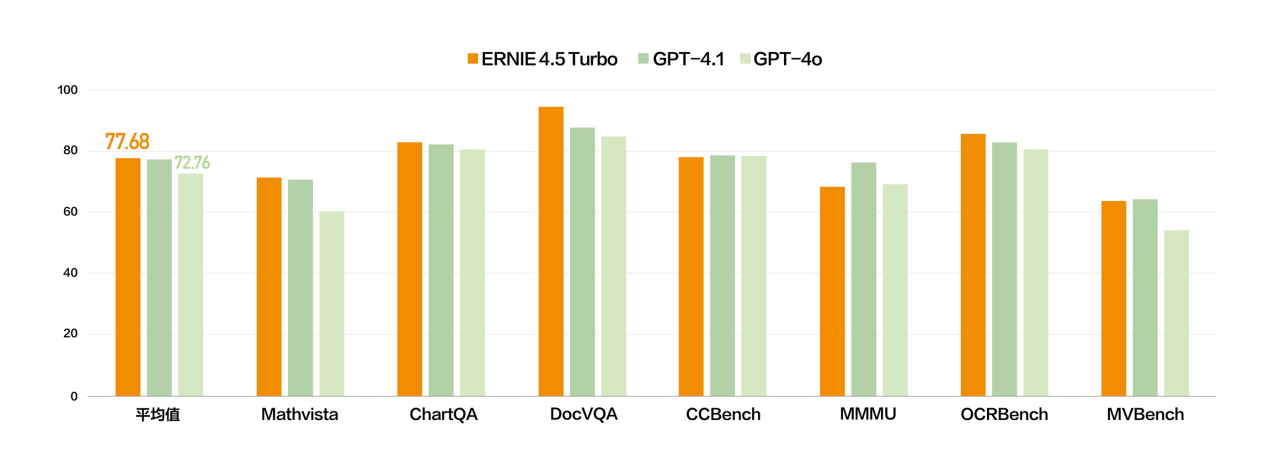
▲Wenxin 4.5 Turbo-Multimodus
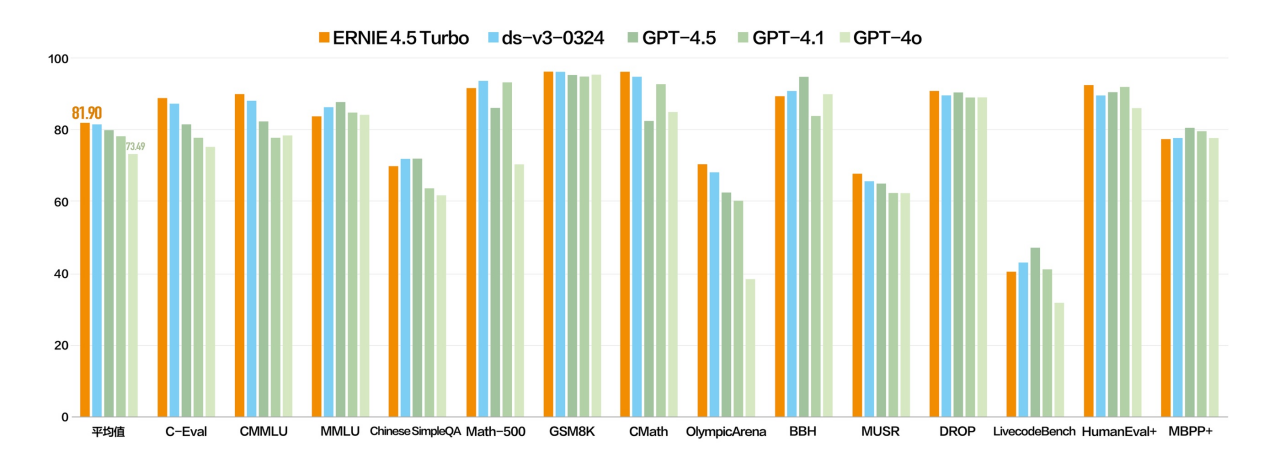
▲Wenxin 4.5 Turbo-Text
Wir könnten genauso gut die logische Denkfähigkeit von Wenxin 4.5 Turbo testen und sehen, wie es eine so klassische Frage beantworten kann:
„Es dauert eine Stunde, ein unebenes Seil zu verbrennen. Wie kann man damit eine halbe Stunde beurteilen? Es dauert insgesamt eine Stunde, um ein unebenes Seil vom Anfang bis zum Ende zu verbrennen. Jetzt gibt es mehrere Seile aus dem gleichen Material. Wie kann ich die Methode des Verbrennens eines Seils anwenden, um eine Stunde und fünfzehn Minuten zu messen?“

Ist Wenxin 4.5 Turbo in Bezug auf die Erstellung zuverlässig? Wir haben ihn auch gebeten, ein kurzes Drehbuch über die Verschwörung von Sun Wukong und dem Drachenkönig des Ostchinesischen Meeres zu schreiben.
Dadurch respektierte das übergebene Drehbuch nicht nur den Kern des Originalwerks, sondern brachte auch neue Interpretationen mit sich. Unter ihnen ist die Personifizierung der Meeresfixierungsnadel der Höhepunkt, und auch die Gestaltung der Blutsbündniszeremonie fügt eine neue Dimension hinzu.

Das große Wenxin-Modell X1 Turbo wurde auf Basis des 4.5 Turbo mit „Deep Thinking“ aufgerüstet, mit deutlich verbesserter Leistung und einem vollständigeren integrierten Denkkettensystem.
Ob es um Frage- und Antwortfunktionen, Inhaltserstellung, logisches Denken, Toolaufruf oder multimodale Verarbeitung geht, X1 Turbo hat umfassende Verbesserungen erzielt und ist in seiner Gesamtleistung besser als DeepSeek R1 und die neueste Version V3.
Letzten Monat haben wir die Fähigkeit des Wenxin Large Model 4.5 und des Deep Thinking Model X1 getestet, Memes zu verstehen. Wie ist die Leistung des neuen Modells? Die Antwort ist, dass das multimodale Verständnis tatsächlich stärker ist.
Nehmen Sie dieses Meme als Beispiel. Im Vergleich zum letzten Mal verfügt X1 Turbo über ein besseres Verständnis und eine besser organisierte Antwort und erkennt die „freundliche Freundlichkeit“ hinter diesem universellen Emoticon voll und ganz an.

Laden Sie beispielsweise ein Foto eines Kulturdenkmals hoch und lassen Sie es von X1 Turbo erklären und analysieren. Es kann nicht nur die Identität kultureller Relikte genau identifizieren, sondern auch deren handwerkliche Merkmale im Detail analysieren und den Inhalt so detailliert erklären wie ein professioneller Museumsdolmetscher.

Oder versuchen Sie, ein Bild aus der Perspektive eines Flugzeugs in der Luft zu erstellen, und das Bild wird sofort erzeugt, fast real.

▲Eingabeaufforderung: Die Hand einer Person zeigt aus dem Flugzeugfenster. Von der Seite sind die Flugzeugflügel außerhalb des Fensters sichtbar. Der Himmel draußen ist klar und die Skyline zeigt eine Morgen- oder Abenddämmerungsszene. Vor Ihnen liegt der weite Ozean
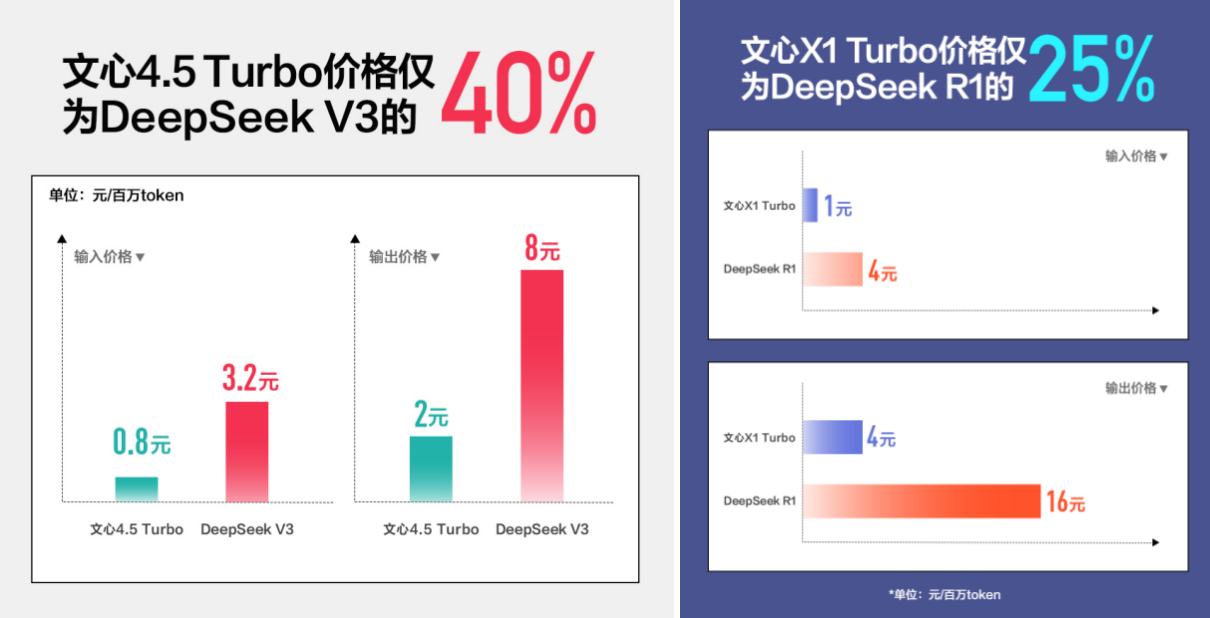
In Bezug auf die Kosten, die allen am meisten am Herzen liegen, hat Baidu dieses Mal auch eine Preiskombination auf den Markt gebracht.
Der Eingabepreis des Wenxin Large Model 4.5 Turbo beträgt nur 0,8 Yuan pro Million Token, und der Ausgabepreis beträgt 3,2 Yuan, was einem Rückgang von 80 % im Vergleich zur Vorgängergeneration 4.5 entspricht und nur 40 % von DeepSeek V3 entspricht.
Der Eingabepreis des Wenxin-Großmodells X1 Turbo beträgt 1 Yuan pro Million Token und der Ausgabepreis 4 Yuan. Auch der Preis halbiert sich, während die Leistung verbessert wird, nur 25 % des DeepSeek R1.
In der One More Thing-Sitzung des Tages stellte Baidu offiziell Chinas ersten vollständig selbst entwickelten 30.000-Karten-Cluster vor, der gleichzeitig das vollständige Training mehrerer großer Modelle mit Dutzenden Milliarden Parametern hosten und 1.000 Kunden bei der gleichzeitigen Feinabstimmung großer Modelle mit Dutzenden Milliarden Parametern unterstützen kann. Hinter der harten Kraft einer starken technischen Basis bedeutet dies auch, dass Baidu erneut das deutlichste Signal an die Branche gesendet hat.
Darüber hinaus sagte Robin Li bei dem Treffen, dass eines der aktuellen Hindernisse für Entwickler bei der Implementierung von KI-Anwendungen darin bestehe, dass große Modelle teuer und unbezahlbar seien. Nachdem die Kosten gesenkt wurden, können Entwickler und Unternehmer mit Zuversicht und Mut entwickeln, und Unternehmen können große Modelle zu geringen Kosten bereitstellen, was letztendlich die Explosion von Anwendungen in allen Lebensbereichen fördert.
Wir betrachten Modellfähigkeiten nicht mehr als Hindernis, sondern kehren zur „Kosteneffizienz“-Logik zurück, die ein Produkt und eine Plattform haben sollten. Anstatt über den rollierenden Preis zu sprechen, ist es besser, Effizienz zu nutzen, um die Schwelle zu senken und durch Offenheit ein Ökosystem aufzubauen.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von aifaner: aifaner (WeChat-ID: ifanr). Weitere spannende Inhalte werden Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo