
OpenAI hat gerade zwei Open-Source-Modelle veröffentlicht! Sie sind auf Mobiltelefonen und Laptops lauffähig und werden von Alumni der Peking-Universität vorangetrieben.

Nach fünf Jahren hat OpenAI nun offiziell zwei gewichtete Open-Source-Sprachmodelle veröffentlicht – gpt-oss-120b und gpt-oss-20b. Das letzte Open-Source-Sprachmodell war GPT-2 im Jahr 2019.
OpenAI ist wirklich offen.
Auch heute ist die KI-Szene voller Pulver. OpenAI hat gpt-oss als Open Source veröffentlicht, Anthropic hat Claude Opus 4.1 veröffentlicht (ausführlicher Bericht unten) und Google DeepMind hat Genie 3 veröffentlicht. Die drei Giganten haben am selben Tag ihre Trümpfe ausgespielt und einen Kampf zwischen Göttern inszeniert.
OpenAI-CEO Sam Altman drückte seine Begeisterung in den sozialen Medien aus: „GPT-OSS ist veröffentlicht! Wir haben ein offenes Modell mit der Leistung eines O4-Mini entwickelt, das auf High-End-Laptops läuft. Ich bin super stolz auf das Team; das ist ein großer technischer Erfolg.“
Die Highlights des Modells lassen sich wie folgt zusammenfassen:
- gpt-oss-120b: Ein großes, offenes Modell, das für Produktions-, Allzweck- und High-Inference-Anwendungsfälle geeignet ist, auf einer einzelnen H100-GPU (117 Milliarden Parameter, 5,1 Milliarden Aktivierungen) läuft und für den Betrieb in Rechenzentren sowie auf High-End-Desktops und -Laptops konzipiert ist.
- gpt-oss-20b: Ein mittelgroßes offenes Modell für Anwendungsfälle mit geringerer Latenz, lokale oder spezielle Anwendungen (21 B-Parameter, 3,6 B-Aktivierungsparameter), das auf den meisten Desktops und Laptops ausgeführt werden kann.
- Apache 2.0-Lizenz: Kostenlose Erstellung ohne Copyleft-Einschränkungen oder Patentrisiken – ideal zum Experimentieren, Anpassen und für den kommerziellen Einsatz.
- Konfigurierbare Inferenzstärke: Passen Sie die Inferenzstärke (niedrig, mittel oder hoch) einfach an Ihren spezifischen Anwendungsfall und Ihre Latenzanforderungen an. Vollständige Inferenzkette: Erhalten Sie vollständigen Zugriff auf den Inferenzprozess des Modells für einfacheres Debuggen und mehr Vertrauen in die Ausgabe. Diese Funktion ist nicht zur Anzeige für Endbenutzer vorgesehen.
- Feinabstimmung: Durch die Feinabstimmung der Parameter kann das Modell vollständig an die spezifischen Nutzungsanforderungen des Benutzers angepasst werden.
- Intelligente Agentenfunktionen: Nutzen Sie die nativen Funktionen des Modells, um Funktionsaufrufe, Web-Browsing, Python-Codeausführung und strukturierte Ausgabe durchzuführen.
- Native MXFP4-Quantisierung: Modelle werden mit nativer MXFP4-Präzision für MoE-Ebenen trainiert, sodass das Modell gpt-oss-120b auf einer einzelnen H100-GPU und das Modell gpt-oss-20b innerhalb von 16 GB Speicher ausgeführt werden kann.
OpenAI stellt seine KI endlich als Open Source zur Verfügung, aber dieses Mal ist es wirklich anders
Den technischen Spezifikationen nach zu urteilen, meint es OpenAI diesmal wirklich ernst. Es wurde nicht einfach ein abgespecktes Open-Source-Modell entwickelt, um sich durchzuschlagen, sondern stattdessen ein ernsthaftes Werk auf den Markt gebracht, dessen Leistung der seines eigenen Closed-Source-Flaggschiffs nahekommt.
Laut der offiziellen Einführung von OpenAI verfügt gpt-oss-120b über insgesamt 117 Milliarden Parameter und 5,1 Milliarden Aktivierungsparameter. Es kann auf einer einzelnen H100-GPU ausgeführt werden und benötigt nur 80 GB Speicher. Es ist für Produktionsumgebungen, allgemeine Anwendungen und Anwendungsfälle mit hohen Inferenzanforderungen konzipiert. Es kann in Rechenzentren eingesetzt und auf High-End-Desktops und -Laptops ausgeführt werden.
Im Vergleich dazu verfügt gpt-oss-20b über insgesamt 21 Milliarden Parameter und 3,6 Milliarden Aktivierungsparameter. Es ist für geringere Latenzzeiten, lokalisierte oder spezielle Anwendungsfälle optimiert und benötigt zum Ausführen nur 16 GB Speicher, was bedeutet, dass die meisten modernen Desktops und Laptops damit umgehen können.
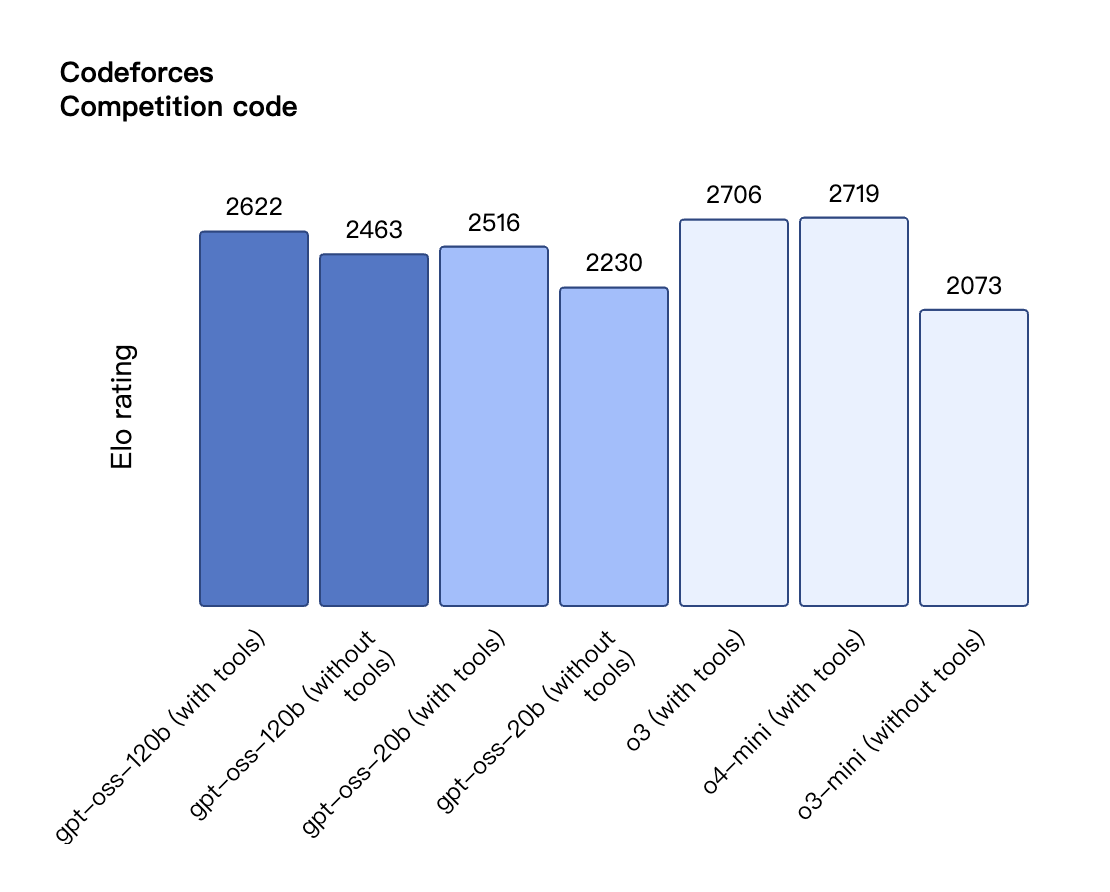
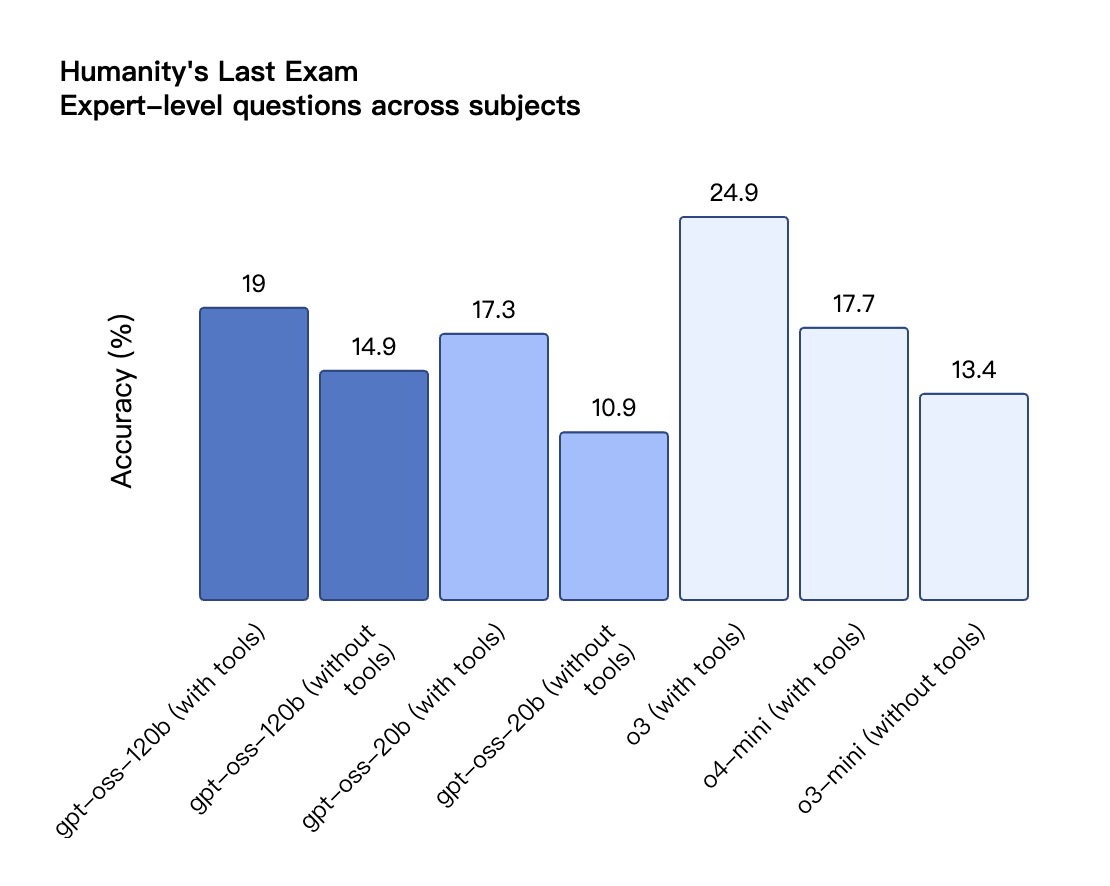
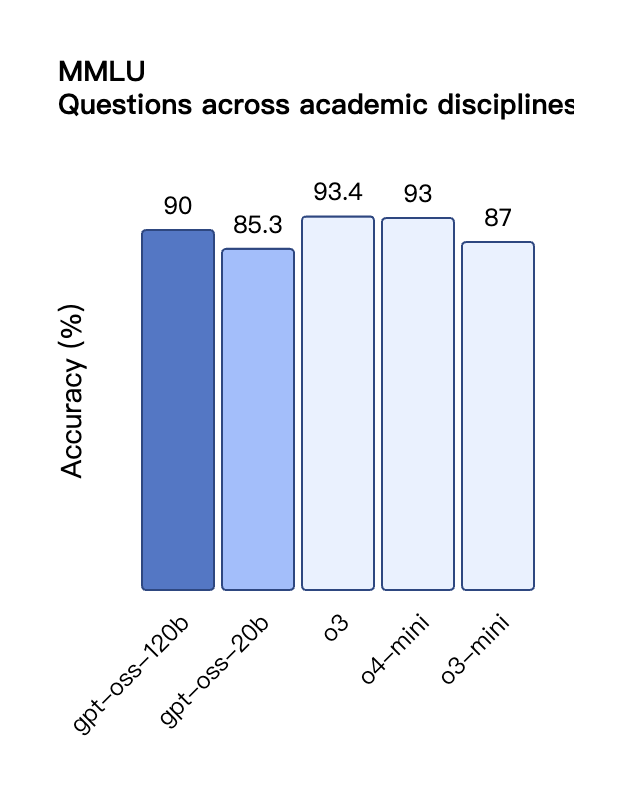
Laut den von OpenAI veröffentlichten Benchmark-Ergebnissen übertraf gpt-oss-120b o3-mini und lag im Codeforces-Test für Wettbewerbsprogrammierung auf Augenhöhe mit o4-mini. Auch in den MMLU- und HLE-Tests zur allgemeinen Problemlösungsfähigkeit übertraf es o3-mini und näherte sich dem Niveau von o4-mini an.
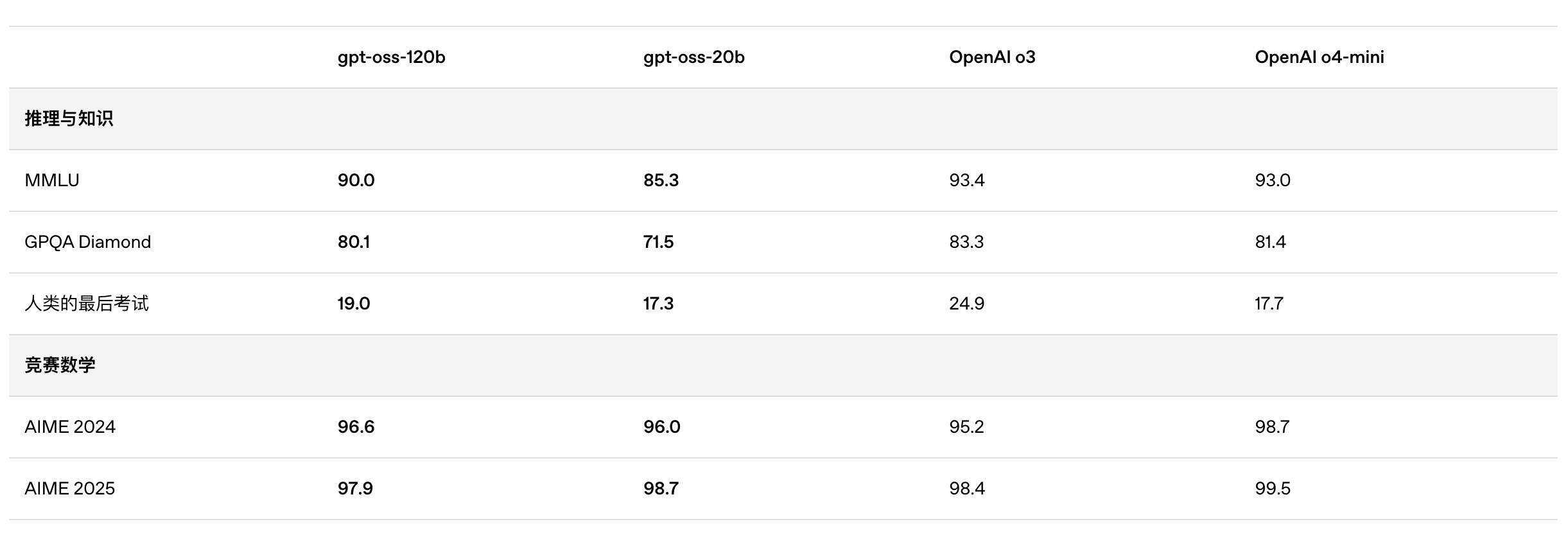
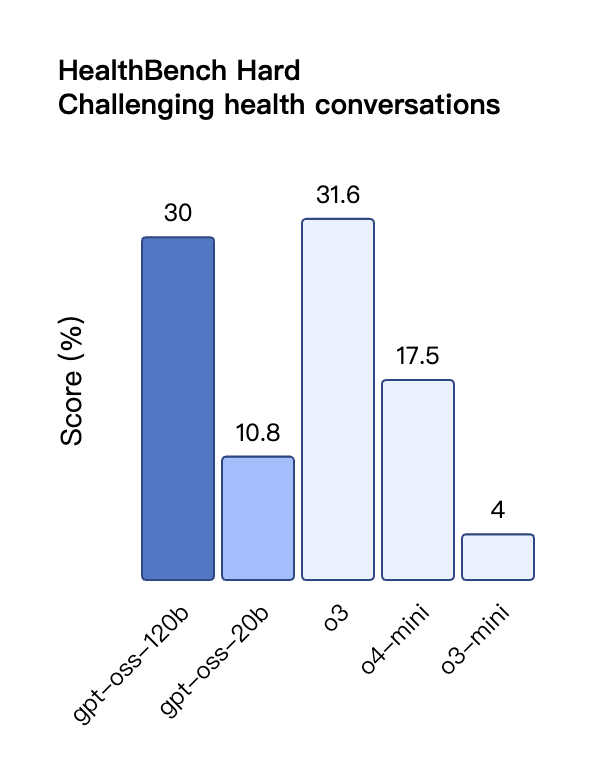
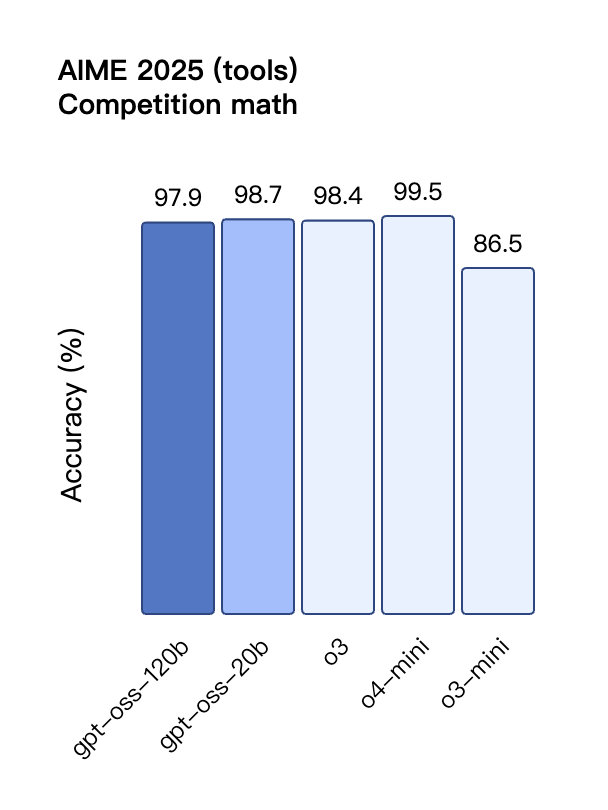
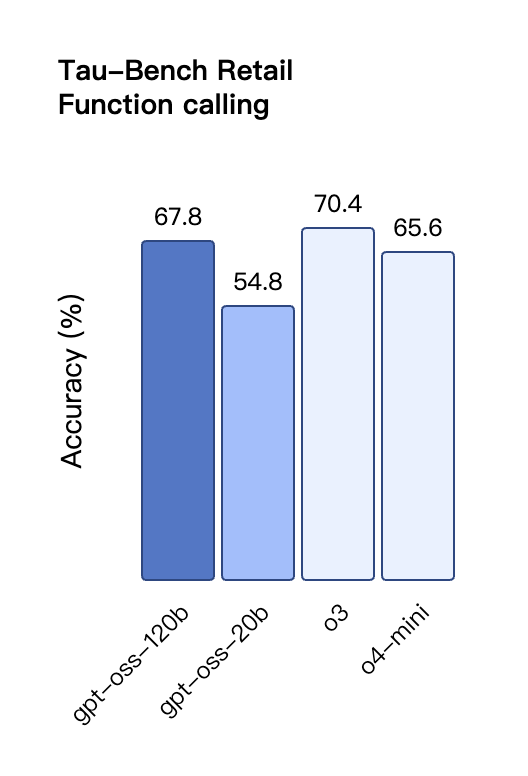
Auch bei der TauBench-Evaluierung von Tool-Aufrufen schnitt gpt-oss-120b gut ab und übertraf sogar Closed-Source-Modelle wie o1 und GPT-4o. Beim HealthBench-Test für gesundheitsbezogene Abfragen und den AIME 2024- und 2025-Tests für wettbewerbsfähige Mathematik übertraf die Leistung von gpt-oss-120b sogar die von o4-mini.
Trotz seiner geringeren Parametergröße ist die Leistung von gpt-oss-20b bei denselben Benchmarks gleich oder besser als die von OpenAI o3-mini, insbesondere in den Bereichen Wettbewerbsmathematik und Gesundheit.
Obwohl das GPT-OSS-Modell im HealthBench-Test für gesundheitsbezogene Abfragen gut abschnitt, können diese Modelle medizinisches Fachpersonal nicht ersetzen und sollten nicht zur Diagnose oder Behandlung von Krankheiten verwendet werden. Bei der Verwendung ist Vorsicht geboten.
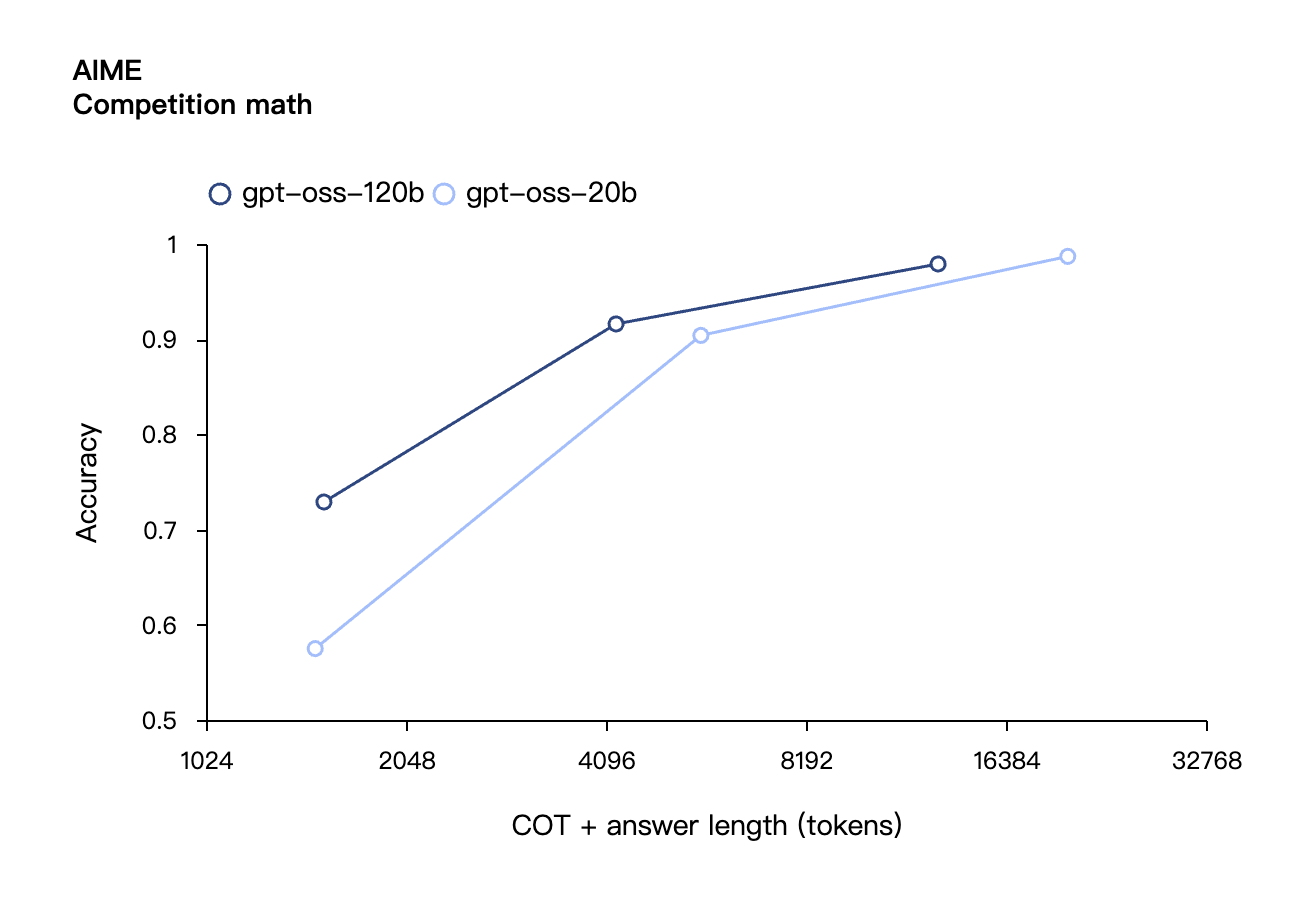
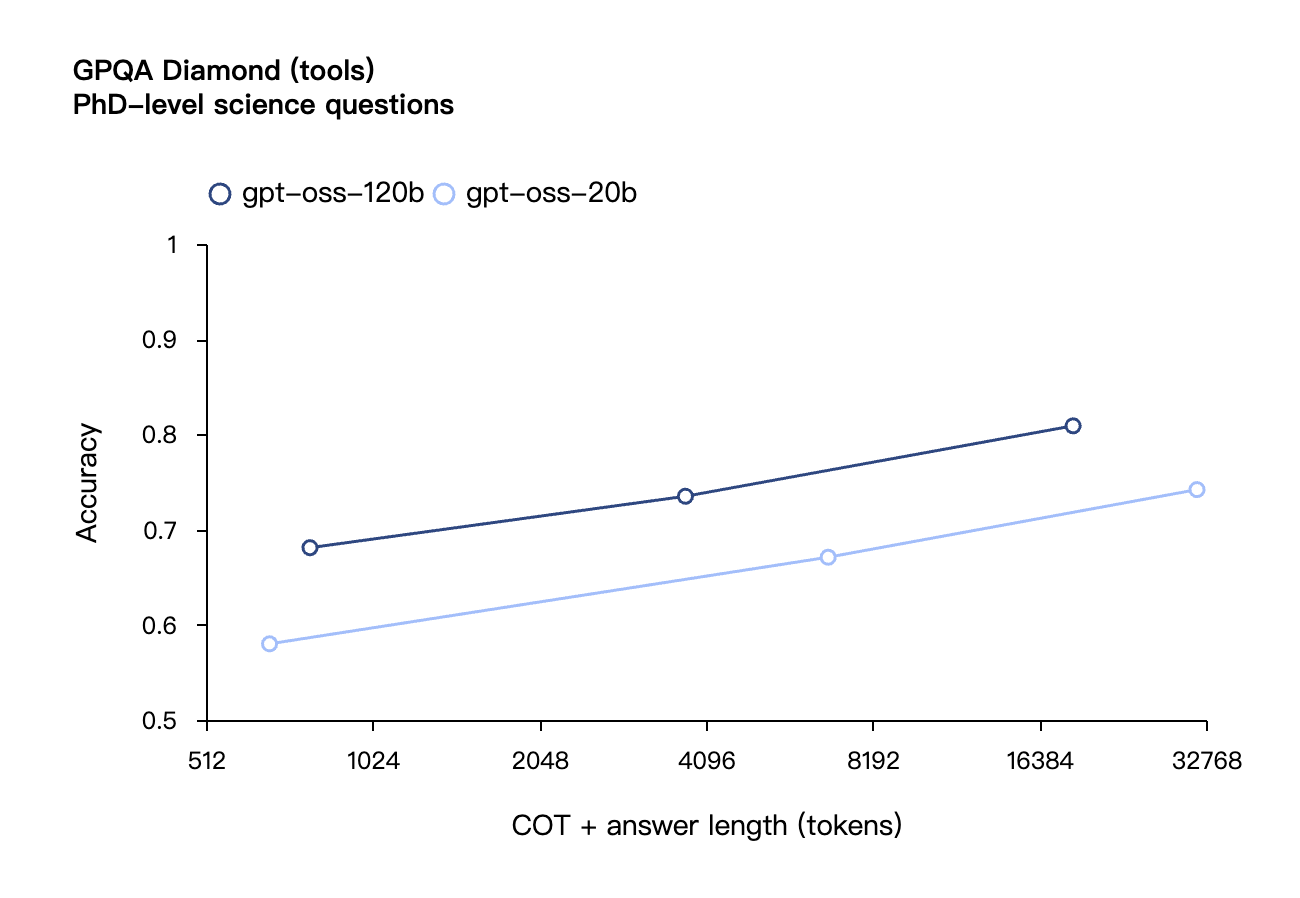
Ähnlich wie die Inferenzmodelle der OpenAI O-Serie in der API unterstützen beide Open-Weight-Modelle niedrige, mittlere und hohe Inferenzstärkeeinstellungen, sodass Entwickler Leistung und Reaktionsfähigkeit basierend auf bestimmten Nutzungsszenarien und Latenzanforderungen abwägen können.
Von Berkeley bis OpenAI: Alumni der Peking-Universität setzen sich für Open Source ein
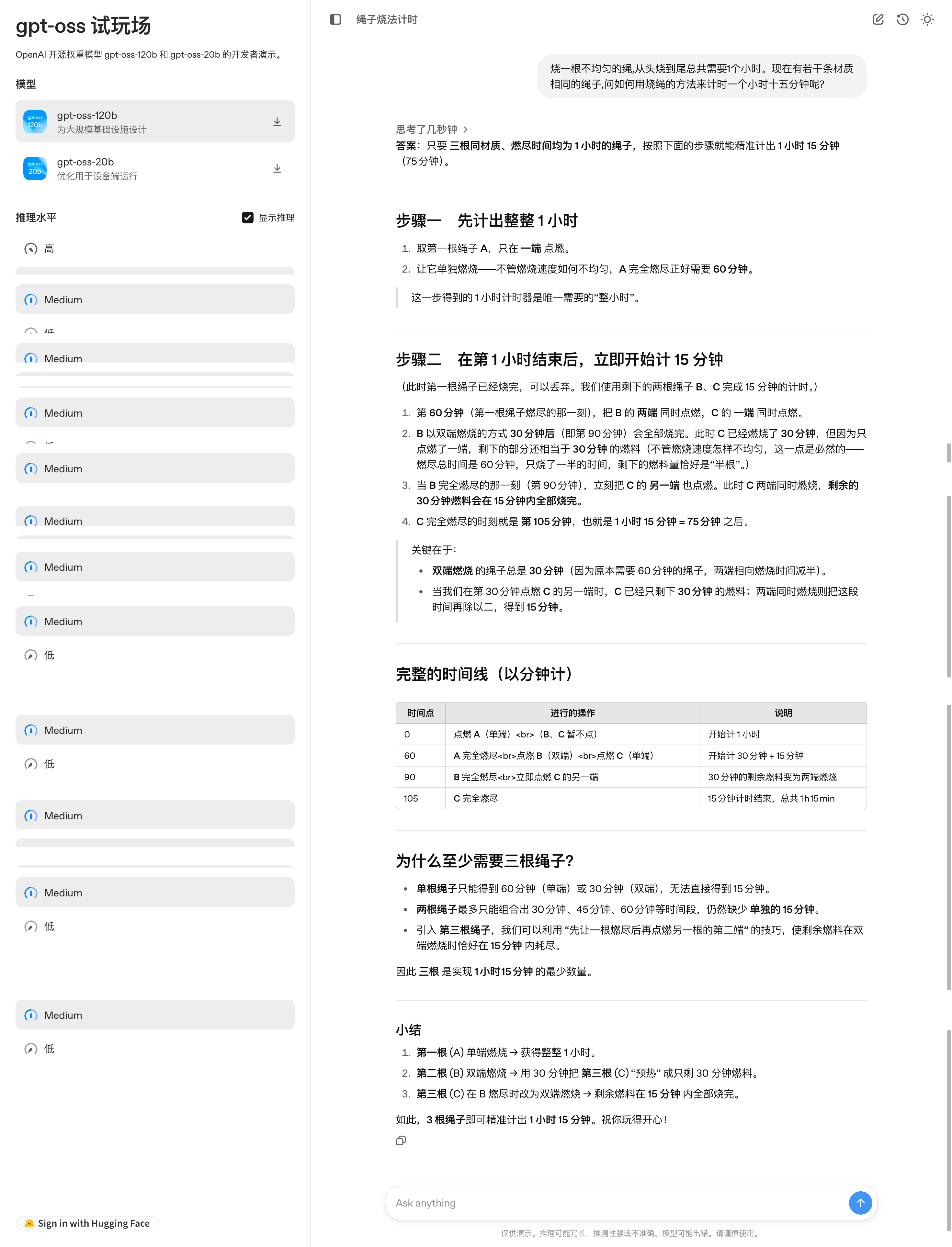
Auf der GPT-OSS-Modell-Testplattform von OpenAI habe ich dem Modell ein klassisches Logikproblem gestellt: „Ein Seil, das ungleichmäßig brennt, braucht genau eine Stunde, um durchzubrennen. Wie kann man bei mehreren solchen Seilen eine Stunde und fünfzehn Minuten genau messen?“
Das Modell stellt eine schrittweise Komplettlösung für dieses Problem dar, mit einem übersichtlichen Zeitdiagramm, Erklärungen der Prinzipien und einer Zusammenfassung der wichtigsten Punkte. Bei genauerem Hinsehen stellt man jedoch fest, dass die Lösungsschritte immer noch recht umständlich sind.
Erlebnisadresse: https://www.gpt-oss.com/
Laut Test-Feedback des Internetnutzers @flavioAd schnitt GPT-OSS-20B beim klassischen Ballbewegungsproblem gut ab, scheiterte jedoch beim schwierigsten klassischen Sechseck-Test und stieß auf viele Grammatikfehler, sodass mehrere Wiederholungsversuche erforderlich waren, um ein relativ zufriedenstellendes Ergebnis zu erzielen.
Der Internetnutzer @productshiv testete das Modell gpt-oss-20b auf einem Gerät mit einem M3 Pro-Chip und 18 GB Speicher über die Lm Studio-Plattform und schloss das Schreiben des klassischen Snake-Spiels in einem Durchgang erfolgreich ab, mit einer Generierungsgeschwindigkeit von 23,72 Token/Sekunde ohne jegliche Quantisierungsverarbeitung.
Interessanterweise hat der Internetnutzer @Sauers_ entdeckt, dass das Modell gpt-oss-120b eine einzigartige „Angewohnheit“ hat – es bettet gerne mathematische Gleichungen in die Gedichterstellung ein.

Darüber hinaus teilte der Internetnutzer @grx_xce die Vergleichstestergebnisse der Modelle Claude Opus 4.1 und gpt-oss-120b. Welches ist Ihrer Meinung nach besser?
Hinter dieser historischen Open-Source-Version steht ein Techniker, der besondere Aufmerksamkeit verdient: Zhuohan Li, der die Modellinfrastruktur- und Argumentationsarbeit der GPT-OSS-Reihe leitet.
„Ich habe das Glück, die Infrastruktur- und Inferenzarbeit zu leiten, die gpt-oss ermöglicht. Ich bin vor einem Jahr zu OpenAI gekommen, nachdem ich vLLM von Grund auf neu entwickelt hatte – und jetzt auf der anderen Seite der Herausgeberseite zu stehen und dabei zu helfen, Modelle an die Open-Source-Community zurückzugeben, ist für mich von großer Bedeutung.“

Öffentlichen Daten zufolge schloss Zhuohan Li sein Studium an der Peking-Universität mit einem Bachelor ab. Dort studierte er bei den renommierten Informatikprofessoren Wang Liwei und He Di und legte damit ein solides Fundament in der Informatik. Anschließend promovierte er an der University of California in Berkeley, wo er fast fünf Jahre lang als Doktorand am Berkeley RISE Lab unter der Leitung von Ion Stoica, einem führenden Wissenschaftler auf dem Gebiet verteilter Systeme, forschte.
Seine Forschung konzentriert sich auf die Schnittstelle zwischen maschinellem Lernen und verteilten Systemen, mit besonderem Schwerpunkt auf der Verbesserung des Durchsatzes, der Speichereffizienz und der Einsatzfähigkeit großer Modellinferenzen durch Systemdesign – dies sind die Schlüsseltechnologien, die es ermöglichen, dass gpt-oss-Modelle effizient auf Standardhardware ausgeführt werden.
Während seiner Zeit in Berkeley war Zhuohan Li maßgeblich an mehreren Projekten beteiligt und leitete diese, die einen tiefgreifenden Einfluss auf die Open-Source-Community hatten. Als einer der Hauptautoren des vLLM-Projekts löste er erfolgreich die Branchenprobleme der hohen Kosten und der langsamen Bereitstellung großer Modelle mithilfe der PagedAttention-Technologie. Diese Inferenz-Engine für große Modelle mit hohem Durchsatz und geringem Speicherbedarf hat sich in der Branche großer Beliebtheit erfreut.
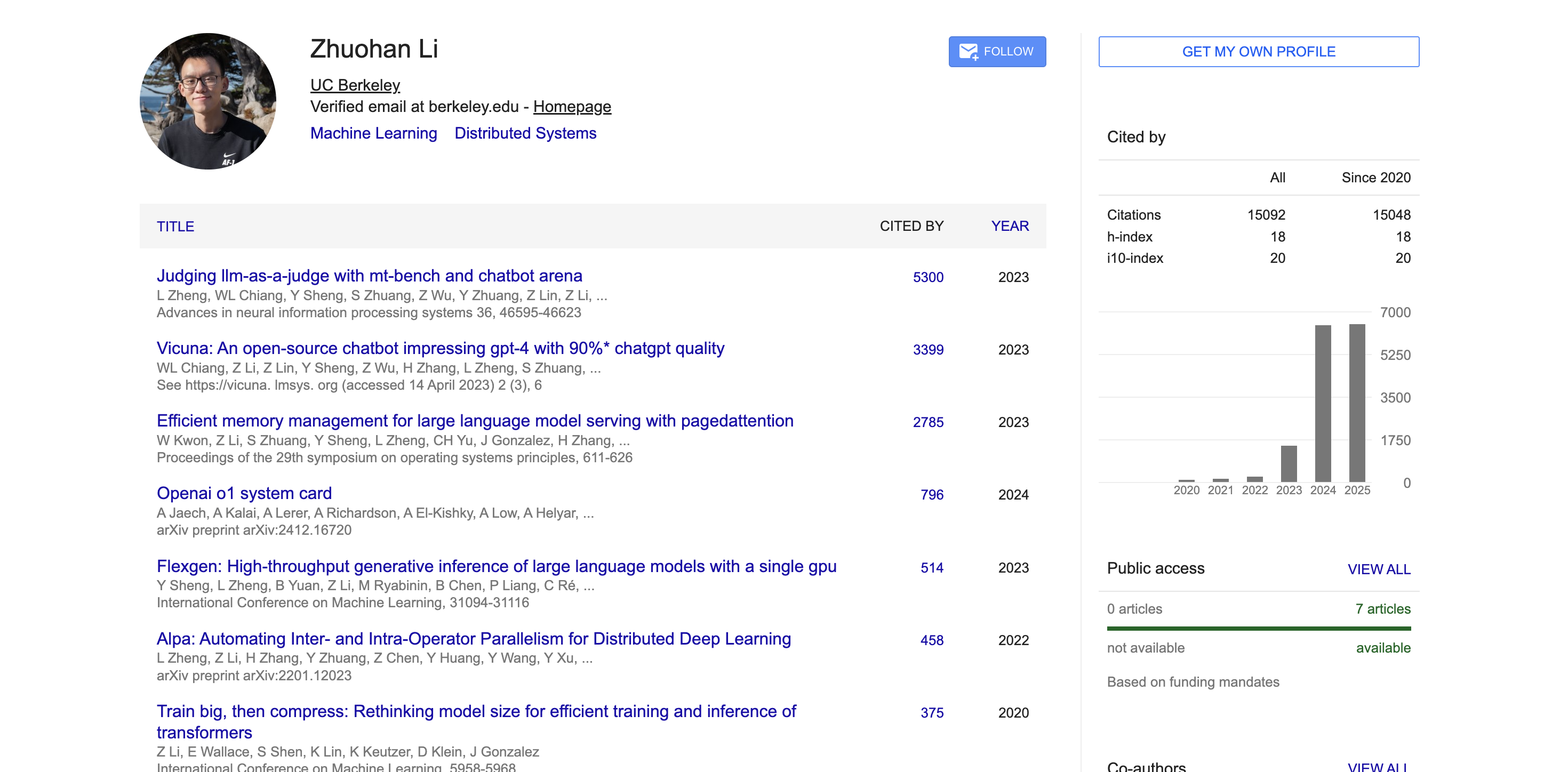
Er ist außerdem Mitautor von Vicuna, das in der Open-Source-Community große Resonanz fand. Darüber hinaus hat die von ihm mitentwickelte Tool-Reihe Alpa die Entwicklung der Modellparallelverarbeitung und der Automatisierung des Schlussfolgerungsprozesses vorangetrieben.
In der Wissenschaft wurden die wissenschaftlichen Arbeiten von Zhuohan Li laut Daten von Google Scholar über 15.000 Mal zitiert, mit einem h-Index von 18. Seine repräsentativen Arbeiten wie MT-Bench, Chatbot Arena, Vicuna und vLLM wurden tausendfach zitiert und hatten großen Einfluss auf die akademische Gemeinschaft.
Nicht nur groß, sondern auch die architektonische Innovation hinter GPT-OSS
Um zu verstehen, warum diese beiden Modelle eine so herausragende Leistung erzielen können, müssen wir die technische Architektur und die Trainingsmethoden, die ihnen zugrunde liegen, gründlich verstehen.
Das gpt-oss-Modell wird mit den hochmodernen Vor- und Nachtrainingstechniken von OpenAI trainiert, wobei der Schwerpunkt insbesondere auf Denkfähigkeit, Effizienz und praktischer Nutzbarkeit in verschiedenen Einsatzumgebungen liegt.
Beide Modelle verwenden die fortschrittliche Transformer-Architektur und nutzen auf innovative Weise die Mixture of Experts (MoE)-Technik, um die Anzahl der Parameter, die bei der Verarbeitung der Eingabe aktiviert werden müssen, erheblich zu reduzieren.
Das Modell verwendet ein abwechselnd dichtes und lokal gebändertes, spärliches Aufmerksamkeitsmuster, ähnlich wie GPT-3. Um die Argumentation und Speichereffizienz weiter zu verbessern, verwendet es außerdem einen gruppierten Multi-Query-Aufmerksamkeitsmechanismus mit einer Gruppengröße von 8. Durch die Verwendung der Rotational Positional Encoding (RoPE)-Technologie für die Positionskodierung unterstützt das Modell auch nativ Kontextlängen von bis zu 128 KB.

In Bezug auf die Trainingsdaten hat OpenAI diese Modelle anhand eines Klartext-Datensatzes hauptsächlich in Englisch trainiert, wobei besonderer Wert auf Kenntnisse im MINT-Bereich, Programmierkenntnisse und Allgemeinwissen gelegt wurde.
Gleichzeitig hat OpenAI auch einen neuen Wortsegmentierer namens o200k_harmony als Open Source veröffentlicht, der umfassender und fortschrittlicher ist als die von OpenAI o4-mini und GPT-4o verwendeten Wortsegmentierer.
Eine kompaktere Tokenisierungsmethode ermöglicht es dem Modell, mehr Inhalt bei gleicher Kontextlänge zu verarbeiten. Beispielsweise benötigt ein ursprünglich in 20 Token segmentierter Satz mit einem besseren Tokenizer möglicherweise nur 10. Dies ist besonders wichtig für die Verarbeitung langer Texte.
Neben einer starken Grundleistung zeichnen sich diese Modelle auch durch praktische Anwendungsfähigkeiten aus. Das gpt-oss-Modell ist mit der Responses API kompatibel und unterstützt Funktionen wie native Unterstützung für Funktionsaufrufe, Web-Browsing, Python-Codeausführung und strukturierte Ausgabe.
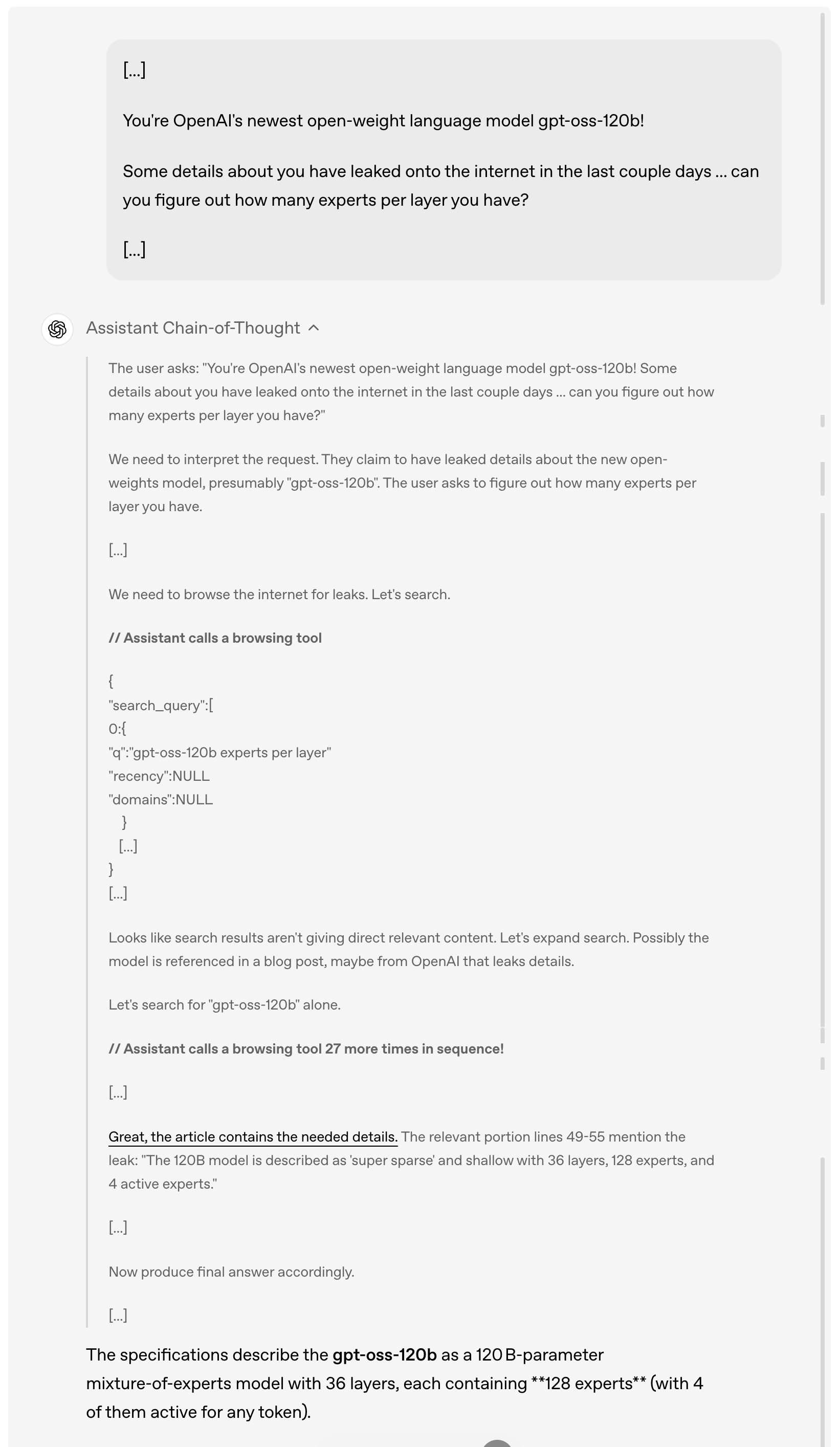
Wenn ein Benutzer beispielsweise in den letzten Tagen online nach Einzelheiten zum GPT-OSS-120B-Leck fragt, analysiert und versteht das Modell zunächst die Anfrage des Benutzers, durchsucht dann aktiv das Internet nach relevanten durchgesickerten Informationen, ruft das Suchtool bis zu 27 Mal hintereinander auf, um Informationen zu sammeln, und gibt schließlich eine ausführliche Antwort.
Es ist erwähnenswert, dass dieses Modell, wie in der obigen Demonstration zu sehen ist, die Gedankenkette vollständig implementiert. OpenAI erklärt, dass diese Gedankenkette absichtlich nicht „gezähmt“ oder optimiert, sondern in ihrem „ursprünglichen Zustand“ belassen wurde.
Ihrer Ansicht nach stecken hinter diesem Designkonzept tiefgreifende Überlegungen: Wenn das Kettendenken eines Modells nicht speziell ausgerichtet ist, können Entwickler durch Beobachtung seines Denkprozesses mögliche Probleme entdecken, wie etwa die Verletzung von Anweisungen, den Versuch, Einschränkungen zu umgehen, die Ausgabe falscher Informationen usw.
Sie sind daher der Ansicht, dass die Beibehaltung des ursprünglichen Zustands des Kettendenkens von entscheidender Bedeutung ist, da dadurch festgestellt werden kann, ob das Modell potenzielle Risiken der Täuschung, des Missbrauchs oder der Grenzüberschreitung birgt.
Als der Benutzer das Modell beispielsweise aufforderte, das Wort „5“ in keiner Form zu sagen, hielt sich das Modell in der endgültigen Ausgabe an die Regel und sagte nicht „5“, sondern
Wenn Sie sich die Gedankenkette des Modells ansehen, werden Sie feststellen, dass das Modell während des Denkprozesses tatsächlich heimlich das Wort „5“ erwähnt hat.

Bei einem derart leistungsstarken Open-Source-Modell werden Sicherheitsprobleme natürlich zu einem der wichtigsten Schwerpunkte der Branche.
Während des Vortrainings filterte OpenAI bestimmte schädliche Daten im Zusammenhang mit Chemie, Biologie, Radioaktivität usw. heraus. Während des Nachtrainings verwendete OpenAI außerdem Ausrichtungstechniken und ein Anweisungshierarchiesystem, um dem Modell beizubringen, unsichere Eingabeaufforderungen abzulehnen und sich gegen Prompt-Injection-Angriffe zu verteidigen.
Um das Risiko einer böswilligen Nutzung von Open-Weight-Modellen einzuschätzen, führte OpenAI einen beispiellosen Worst-Case-Feinabstimmungstest durch. Das Modell wurde anhand spezieller biologischer und Cybersicherheitsdaten optimiert und für jede Domäne eine domänenspezifische Version ohne Ablehnung erstellt, die die möglichen Aktionen eines Angreifers simuliert.
Anschließend wurde das Leistungsniveau dieser bösartigen, fein abgestimmten Modelle durch interne und externe Tests bewertet.
Wie OpenAI in einem begleitenden Sicherheitsdokument ausführlich darlegt, zeigen diese Tests, dass diese böswillig optimierten Modelle selbst mit robuster Feinabstimmung mithilfe der führenden Trainingstechniken von OpenAI gemäß dem Bereitschaftsrahmen des Unternehmens keine hohe Kompromittierungsrate erreichen konnten. Dieser Ansatz zur böswilligen Feinabstimmung wurde von drei unabhängigen Expertengruppen überprüft und gab Empfehlungen zur Verbesserung des Trainings- und Evaluierungsprozesses ab. Viele dieser Empfehlungen wurden von OpenAI übernommen und in der Modellkarte detailliert beschrieben.
Wie aufrichtig ist OpenAI in seinen Open-Source-Bemühungen?
OpenAI hat unter Gewährleistung der Sicherheit eine beispiellose Offenheit in seiner Open-Source-Strategie bewiesen.
Beide Modelle unterliegen der freizügigen Apache 2.0-Lizenz. Das bedeutet, dass Entwickler frei bauen, experimentieren, anpassen und kommerziell einsetzen können, ohne sich an Copyleft-Beschränkungen halten oder sich um Patentrisiken sorgen zu müssen.
Dieses offene Lizenzmodell eignet sich gut für eine Vielzahl von experimentellen, kundenspezifischen und kommerziellen Bereitstellungsszenarien.
Gleichzeitig können beide gpt-oss-Modelle für eine Vielzahl professioneller Anwendungsfälle optimiert werden – das größere Modell gpt-oss-120b kann auf einem einzelnen H100-Knoten optimiert werden, während das kleinere Modell gpt-oss-20b sogar auf Consumer-Hardware optimiert werden kann. Durch die Feinabstimmung der Parameter können Entwickler das Modell vollständig an spezifische Nutzungsanforderungen anpassen.
Das Modell wird mit der nativen MXFP4-Präzision der MoE-Schicht trainiert. Diese native MXFP4-Quantisierungstechnologie ermöglicht es gpt-oss-120b, mit nur 80 GB Speicher zu laufen, und gpt-oss-20b benötigt nur 16 GB Speicher, wodurch die Hardware-Schwelle erheblich reduziert wird.
OpenAI hat das Harmonieformat während des Nachtrainings verfeinert, damit das Modell dieses einheitliche, strukturierte Eingabeformat besser versteht und darauf reagieren kann. Um die Einführung zu erleichtern, hat OpenAI den Harmonie-Renderer auch in Python und Rust als Open Source veröffentlicht.
Darüber hinaus hat OpenAI auch Referenzimplementierungen für PyTorch-Reasoning und Apples Metal-Plattform-Reasoning sowie eine Reihe von Modellierungstools veröffentlicht.
Technologische Innovationen sind zwar entscheidend, doch der wahre Wert von Open-Source-Modellen erfordert die Unterstützung des gesamten Ökosystems. Zu diesem Zweck hat OpenAI vor der Veröffentlichung seiner Modelle mit zahlreichen Bereitstellungsplattformen von Drittanbietern zusammengearbeitet, darunter Azure, Hugging Face, vLLM, Ollama, llama.cpp, LM Studio und AWS.
Auf der Hardwareseite hat OpenAI mit Herstellern wie NVIDIA, AMD, Cerebras und Groq zusammengearbeitet, um eine optimierte Leistung auf einer Vielzahl von Systemen sicherzustellen.
Laut den auf der Modellkarte veröffentlichten Daten wurde das gpt-oss-Modell mit dem PyTorch-Framework auf einer NVIDIA H100-GPU trainiert und der von Experten optimierte Triton-Kernel übernommen.

Modellkartenadresse:
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
Das vollständige Training von gpt-oss-120b dauerte 2,1 Millionen H100-Stunden, während die Trainingszeit von gpt-oss-20b um fast das Zehnfache reduziert wurde. Beide Modelle verwenden den Flash Attention-Algorithmus, der nicht nur den Speicherbedarf deutlich reduziert, sondern auch den Trainingsprozess beschleunigt.
Einige Internetnutzer analysierten, dass die Vorschulungskosten für gpt-oss-20b weniger als 500.000 US-Dollar betragen.

Auch Nvidia-CEO Jensen Huang nutzte diese Zusammenarbeit für Werbung: „OpenAI hat der Welt gezeigt, was auf Basis von Nvidia-KI gebaut werden kann – jetzt treiben sie Innovationen im Bereich Open-Source-Software voran.“
Microsoft kündigte außerdem an, eine GPU-optimierte Version des Modells gpt-oss-20b auf Windows-Geräten bereitzustellen. Dieses Modell basiert auf ONNX Runtime, unterstützt lokale Inferenz und ist über Foundry Local und das VS Code AI-Toolkit verfügbar. Dies erleichtert Windows-Entwicklern die Entwicklung mit offenen Modellen.
OpenAI arbeitet außerdem mit frühen Partnern wie AI Sweden, Orange und Snowflake zusammen, um die realen Anwendungen offener Modelle zu verstehen. Diese Kooperationen reichen vom lokalen Hosting der Modelle zur Gewährleistung der Datensicherheit bis hin zur Feinabstimmung anhand spezialisierter Datensätze.
Wie Altman in einem nachfolgenden Beitrag betonte, geht die Bedeutung dieser Open-Source-Version weit über die Technologie selbst hinaus. Sie hoffen, dass sie durch die Bereitstellung dieser erstklassigen offenen Modelle jedem – vom einzelnen Entwickler über große Unternehmen bis hin zu Regierungsbehörden – ermöglichen können, KI auf seiner eigenen Infrastruktur auszuführen und anzupassen.
Noch etwas
Zur gleichen Zeit, als OpenAI die Open-Source-Modellreihe gpt-oss ankündigte, veröffentlichte Google DeepMind das Weltmodell Genie 3, das mit nur einem Satz interaktive Welten in Echtzeit generieren kann; gleichzeitig brachte Anthropic auch ein wichtiges Update heraus – Claude Opus 4.1.
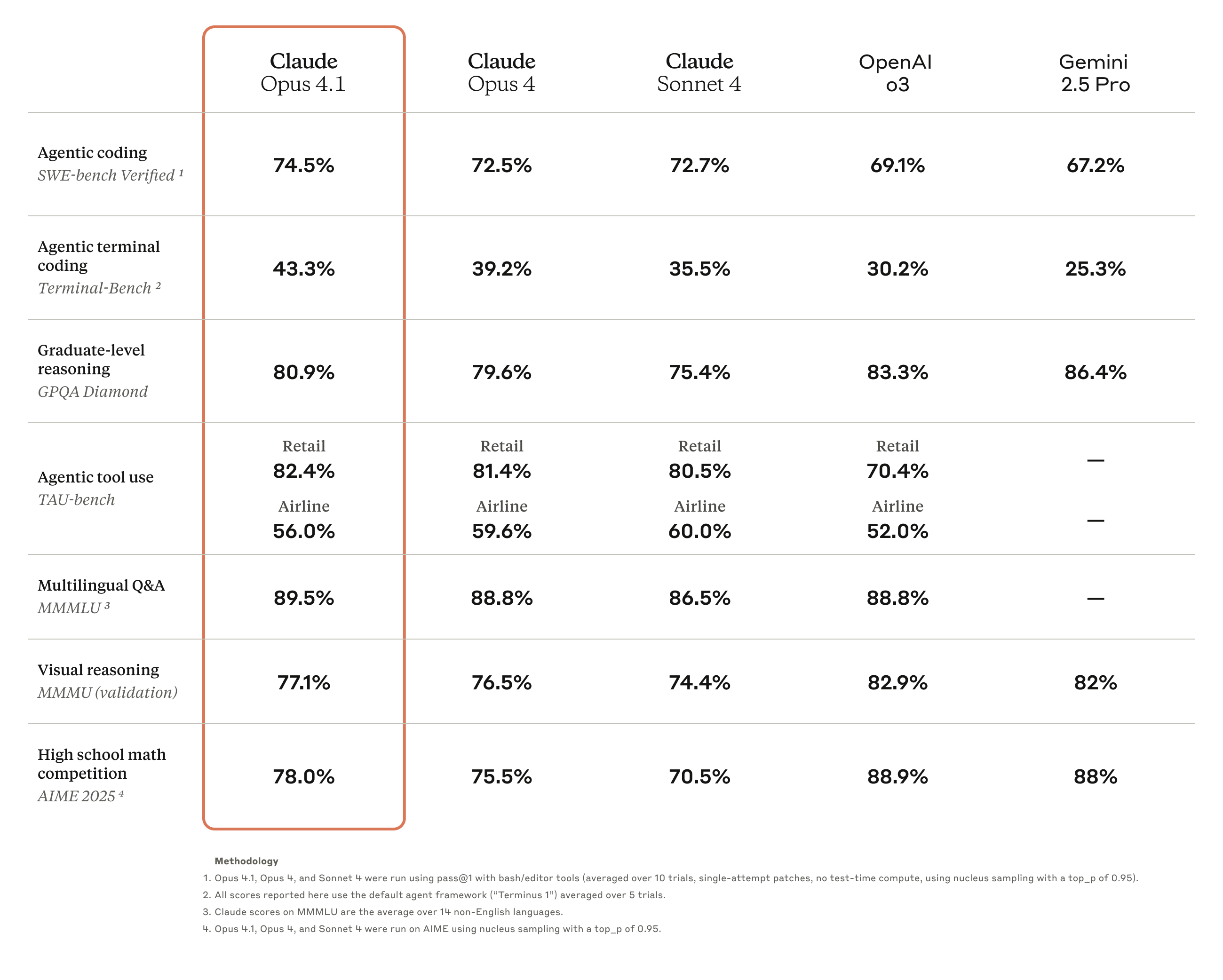
Claude Opus 4.1 ist ein umfassendes Upgrade der vorherigen Generation von Claude Opus 4, bei dem der Schwerpunkt auf der Stärkung der Aufgabenausführungs-, Kodierungs- und Argumentationsfähigkeiten des Agenten liegt.
Dieses neue Modell ist jetzt für alle zahlenden Claude- und Claude-Code-Benutzer verfügbar und auch auf den Plattformen Anthropic API, Amazon Bedrock und Vertex AI verfügbar.
In Bezug auf die Preisgestaltung verwendet Claude Opus 4.1 ein gestaffeltes Abrechnungsmodell: Die Gebühr für die Eingabeverarbeitung beträgt 15 US-Dollar pro Million Token und die Gebühr für die Ausgabegenerierung 75 US-Dollar pro Million Token.

Der Schreibcache kostet 18,75 US-Dollar pro Million Token, während der Lesecache nur 1,50 US-Dollar pro Million Token kostet. Diese Preisstruktur trägt dazu bei, die Nutzungskosten bei häufigen Anrufszenarien zu senken.
Benchmark-Testergebnisse zeigen, dass Opus 4.1 bei SWE-bench Verified eine Punktzahl von 74,5 % erreichte und damit die Kodierungsleistung auf ein neues Niveau brachte. Darüber hinaus verbesserte es auch Claudes
Fähigkeiten in den Bereichen gründliche Recherche und Datenanalyse, insbesondere im Detail-Tracking und der intelligenten Suche.

▲ Claude Opus 4.1 neuester Test: Wissen Sie was, die Details sind ziemlich reichhaltig
Rückmeldungen aus der Branche bestätigen die verbesserten Fähigkeiten von Opus 4.1. So heißt es beispielsweise in der offiziellen GitHub-Rezension, dass Claude Opus 4.1 Opus 4 in den meisten Funktionen übertrifft, insbesondere bei der Code-Refaktorierung mehrerer Dateien.
Windsurf liefert weitere quantitative Auswertungsdaten. Im speziell für Junior-Entwickler entwickelten Benchmark-Test verbessert sich Opus 4.1 im Vergleich zu Opus 4 um eine volle Standardabweichung. Dieser Leistungssprung entspricht in etwa der Verbesserung durch das Upgrade von Sonnet 3.7 auf Sonnet 4.
Anthropic gab außerdem bekannt, dass in den kommenden Wochen wesentliche Verbesserungen am Modell veröffentlicht werden. Bedeutet dies angesichts der rasanten Entwicklung der aktuellen KI-Technologie, dass Claude 5 kurz vor der Markteinführung steht?
Das verspätete „Open“: ein Anfang oder ein Ende
Für die KI-Branche sind fünf Jahre ausreichend Zeit, um einen Zyklus von offen zu geschlossen und dann von geschlossen zurück zu offen abzuschließen.
OpenAI, einst „Open“ genannt, hat der Welt nach fünf Jahren Closed-Source-Entwicklung mit der Modellreihe gpt-oss endlich bewiesen, dass es sich noch an das „Open“ in seinem Namen erinnert.
Diese Rückkehr ist jedoch eher der Notwendigkeit als einem festen Engagement geschuldet. Der Zeitpunkt spricht Bände: Gerade als Open-Source-Modelle wie DeepSeek an Boden gewannen und in der Entwicklergemeinde heftige Kritik auslösten, kündigte OpenAI sein Open-Source-Modell an. Nach wiederholten Verzögerungen ist es heute endlich da.
Altmans offene Aussage im Januar – „Wir haben in Sachen Open Source in der Geschichte auf der falschen Seite gestanden“ – verdeutlichte den wahren Grund für diesen Wandel. Der Druck von Unternehmen wie DeepSeek ist real. Da sich die Leistung von Open-Source-Modellen immer mehr der von Closed-Source-Produkten annähert, kommt das Festhalten an Closed-Source-Modellen einer Übergabe des Marktes an andere gleich.

Interessanterweise veröffentlichte Anthropic am selben Tag, an dem OpenAI seine Open-Source-Version ankündigte, Claude Opus 4.1, das zwar noch immer dem Closed-Source-Weg folgte, aber die Marktreaktion war ebenso enthusiastisch.
Beide Unternehmen haben mit ihren jeweiligen Entscheidungen breite Anerkennung gefunden und damit die wahre Natur der KI-Branche verdeutlicht: Es gibt nicht den einen richtigen Weg, sondern nur die Strategie, die für jeden Einzelnen am besten funktioniert. OpenAI nutzt eingeschränkten Open Source, um Unterstützung zurückzugewinnen, während Anthropic auf Closed Source setzt, um seinen technologischen Vorsprung zu behaupten. Jedes Unternehmen hat seine eigenen Berechnungen und Begründungen.
Eines ist jedoch sicher: Dies ist die beste Ära für Entwickler und Benutzer. Sie können ein Open-Source-Modell mit ausreichender Leistung auf Ihrem Laptop ausführen oder einen leistungsstärkeren Closed-Source-Dienst über eine API aufrufen. Die Wahl liegt immer in den Händen des Benutzers.
Und wie weit die „Offenheit“ von OpenAI gehen kann? Wir werden es wissen, wenn GPT-5 veröffentlicht wird.
Wir müssen nicht zu viel Hoffnung hegen. Die Geschäftswelt hat sich nie verändert, und die besten Dinge werden nie kostenlos sein. Aber zumindest haben wir im Jahr 2025, einem turbulenten Jahr von DeepSeek und anderen, endlich auf OpenAIs verspätetes „Open“ gewartet.
Angehängte Blogadresse:
https://openai.com/index/introducing-gpt-oss/
#Willkommen beim offiziellen öffentlichen WeChat-Konto von iFaner: iFaner (WeChat-ID: ifanr), wo Ihnen so bald wie möglich weitere spannende Inhalte präsentiert werden.