
Das Modell der nächsten Generation von OpenAI stößt auf große Engpässe, ehemaliger Chefwissenschaftler enthüllt neue Technologieroute

Das große Sprachmodell der nächsten Generation „Orion“ von OpenAI ist möglicherweise auf einen beispiellosen Engpass gestoßen.
Laut The Information sagten interne OpenAI-Mitarbeiter, dass die Leistungsverbesserung des Orion-Modells nicht den Erwartungen entsprach und dass die Qualitätsverbesserung „viel geringer“ ausfiel als beim Upgrade von GPT-3 auf GPT-4.
Darüber hinaus sagten sie, Orion sei bei bestimmten Aufgaben nicht zuverlässiger als sein Vorgänger GPT-4. Obwohl Orion über bessere Sprachkenntnisse verfügt, kann es GPT-4 in Bezug auf die Programmierung möglicherweise nicht übertreffen.

▲Bildquelle: WeeTech
Der Bericht wies darauf hin, dass das Angebot an qualitativ hochwertigen Texten und anderen Daten für das Training abnimmt, was es schwieriger macht, gute Trainingsdaten zu finden und dadurch die Entwicklung großer Sprachmodelle (LLMs) in mancher Hinsicht verlangsamt.
Darüber hinaus werden künftige Schulungen mehr Rechenressourcen, finanzielle Ressourcen und sogar Strom verbrauchen. Dies bedeutet, dass die Kosten und Kosten für die Entwicklung und den Betrieb von Orion und nachfolgenden großen Sprachmodellen teurer werden.
Noam Brown, ein Forscher bei OpenAI, erklärte kürzlich auf der TED AI-Konferenz, dass fortschrittlichere Modelle möglicherweise nicht „ wirtschaftlich machbar “ seien:
Müssen wir wirklich Hunderte Milliarden oder Billionen Dollar für die Ausbildung von Modellen ausgeben? Irgendwann bricht das Expansionsgesetz zusammen.
In diesem Zusammenhang hat OpenAI ein Basisteam unter der Leitung von Nick Ryder gegründet, der für das Vortraining verantwortlich ist, um zu untersuchen, wie mit dem Mangel an Trainingsdaten umgegangen werden kann und wie lange die Skalierungsgesetze großer Modelle Bestand haben.

▲Noam Brown
Skalierungsgesetze sind eine Kernannahme im Bereich der künstlichen Intelligenz: Solange es mehr Daten zum Lernen und mehr Rechenleistung gibt, um den Trainingsprozess zu erleichtern, können große Sprachmodelle die Leistung im gleichen Tempo weiter verbessern.
Vereinfacht ausgedrückt beschreiben Skalierungsgesetze die Beziehung zwischen Input (Datenvolumen, Rechenleistung, Modellgröße) und Output, also das Ausmaß, in dem sich die Leistung verbessert, wenn wir mehr Ressourcen in ein großes Sprachmodell investieren.
Das Trainieren eines großen Sprachmodells ist beispielsweise so, als würde man in einer Werkstatt ein Auto bauen . Anfangs war die Werkstatt klein, mit nur wenigen Maschinen und wenigen Arbeitern. Zu diesem Zeitpunkt kann jede zusätzliche Maschine oder jeder zusätzliche Arbeiter die Leistung erheblich steigern, da diese neuen Ressourcen direkt in eine Erhöhung der Produktionskapazität umgewandelt werden.
Wenn eine Fabrik größer wird, nimmt die Produktionssteigerung durch jede zusätzliche Maschine oder jeden zusätzlichen Arbeiter ab. Es könnte sein, dass das Management komplexer geworden ist oder dass die Koordination zwischen den Arbeitnehmern schwieriger geworden ist.
Wenn eine Fabrik eine bestimmte Größe erreicht, kann die Hinzufügung weiterer Maschinen und Arbeitskräfte die Produktion nur noch in sehr begrenztem Maße steigern. An diesem Punkt stößt die Fabrik möglicherweise an die Grenzen von Land, Stromversorgung, Logistik usw. und erhöhte Inputs können nicht mehr zu einer proportionalen Steigerung der Produktion führen .

Und darin liegt Orions Dilemma. Wenn die Größe des Modells zunimmt (ähnlich wie beim Hinzufügen von Maschinen und Arbeitern), kann die Leistungsverbesserung des Modells früh und mittelfristig sehr offensichtlich sein. Aber selbst wenn die Modellgröße oder die Menge der Trainingsdaten in der späteren Phase weiter zunimmt, kann die Leistungsverbesserung immer geringer werden. Dies ist das sogenannte „ Anstoßen an die Wand “.
In einem kürzlich auf arXiv veröffentlichten Artikel heißt es außerdem, dass angesichts der wachsenden Nachfrage nach öffentlichen menschlichen Textdaten und der begrenzten Menge vorhandener Daten zu erwarten ist, dass die Entwicklung großer Sprachmodelle zwischen 2026 und 2032 die aktuellen Ressourcen erschöpfen wird. Es gibt öffentliche menschliche Textdatenressourcen.
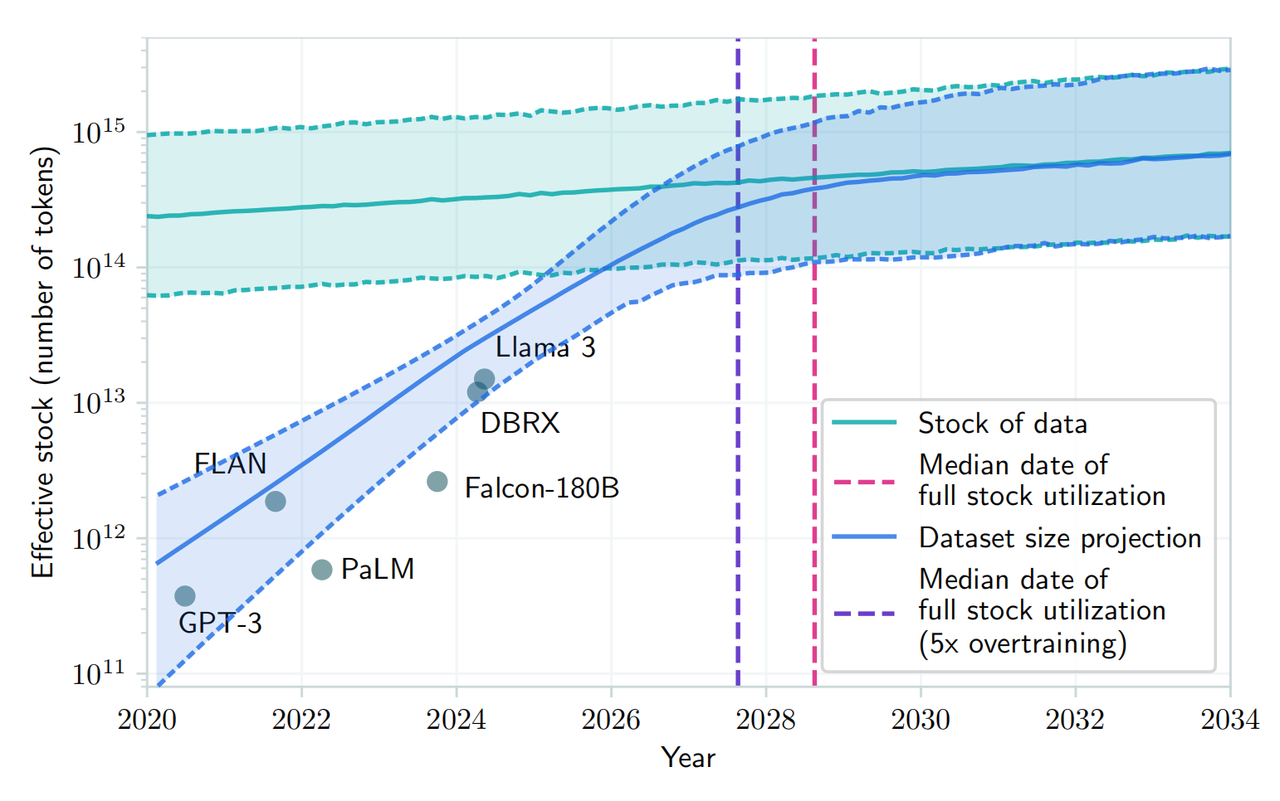
▲Bildquelle: arXiv
Auch als Norm Brown auf die „wirtschaftlichen Probleme“ der künftigen Modellausbildung hinwies, lehnte er den oben genannten Standpunkt dennoch ab. Er glaubt, dass „ die Entwicklung der künstlichen Intelligenz so schnell nicht nachlassen wird “.
Forscher von OpenAI sind sich weitgehend einig. Sie glauben, dass sich das Expansionsgesetz des Modells zwar verlangsamen könnte, die Gesamtentwicklung der KI jedoch nicht durch die Optimierung der Inferenzzeit und Verbesserungen nach dem Training beeinträchtigt wird.
Darüber hinaus haben die CEOs von Metas Mark Zuckerberg, OpenAIs Sam Altman und anderen KI-Entwicklern öffentlich erklärt, dass sie die Grenzen der traditionellen Skalierungsgesetze noch nicht erreicht haben und immer noch teure Rechenzentren entwickeln, um die Leistung vorab trainierter Modelle zu steigern.

▲Sam Altman (Quelle: Vanity Fair)
Peter Welinder, Produkt-Vizepräsident von OpenAI, sagte in den sozialen Medien auch, dass „die Leute die Leistungsfähigkeit der Datenverarbeitung während des Testens unterschätzen.“
Testzeitberechnung (TTC) ist ein Konzept des maschinellen Lernens, das sich auf die Berechnungen bezieht, die beim Ableiten oder Vorhersagen neuer Eingabedaten nach der Bereitstellung des Modells durchgeführt werden. Dies ist unabhängig von den Berechnungen in der Modelltrainingsphase, in der das Modell Muster in den Daten lernt und Vorhersagen trifft.
Bei herkömmlichen Modellen für maschinelles Lernen sind nach dem Training und Einsatz des Modells in der Regel keine zusätzlichen Berechnungen mehr erforderlich, um Vorhersagen für neue Dateninstanzen zu treffen. Bei einigen komplexeren Modellen, wie z. B. bestimmten Arten von Deep-Learning-Modellen, können jedoch zur Testzeit (d. h. zur Inferenzzeit) zusätzliche Berechnungen erforderlich sein.
Beispielsweise verwendet das von OpenAI entwickelte „o1“-Modell dieses Argumentationsmodell. Tatsächlich verlagert die gesamte KI-Branche ihren Fokus auf ein Modell, das Modelle nach dem ersten Training verbessert .

▲Peter Welinder (Quelle: Dagens industri)
In diesem Zusammenhang gab Ilya Sutskever, einer der Mitbegründer von OpenAI, kürzlich in einem Interview mit Reuters zu, dass durch die Verwendung großer Mengen unbeschrifteter Daten Modelle künstlicher Intelligenz trainiert werden, um Sprachmuster und -strukturen in der Vortrainingsphase zu verstehen Die Wirkungsverbesserung hat sich stabilisiert .
„Die 2010er Jahre waren eine Ära der Expansion, und jetzt sind wir zurück in einer Ära der Erkundung und Entdeckung“, sagte Ilya und merkte an, dass „ die Skalierung im richtigen Maßstab wichtiger denn je ist.“
Der Start von Orion wird für 2025 erwartet. OpenAI nannte es „Orion“ statt „GPT-5“, was auf eine neue Revolution hinweisen könnte. Obwohl es aufgrund theoretischer Einschränkungen vorübergehend „schwierig zu gebären“ ist, freuen wir uns dennoch auf dieses „Neugeborene“ mit einem neuen Namen, das dem großen KI-Modell neue Möglichkeiten eröffnen kann.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo