
DeepSeek V3.1 hatte plötzlich einen haarsträubenden Fehler: Das Wort „极“ tauchte überall auf dem Bildschirm auf und verwirrte die Entwickler.
Die neueste Version von DeepSeek, V3.1, wurde von mehreren Entwicklern getestet und es wurde festgestellt, dass Token wie „极/極/extreme“ dort eingefügt werden, wo sie nicht erscheinen sollten.
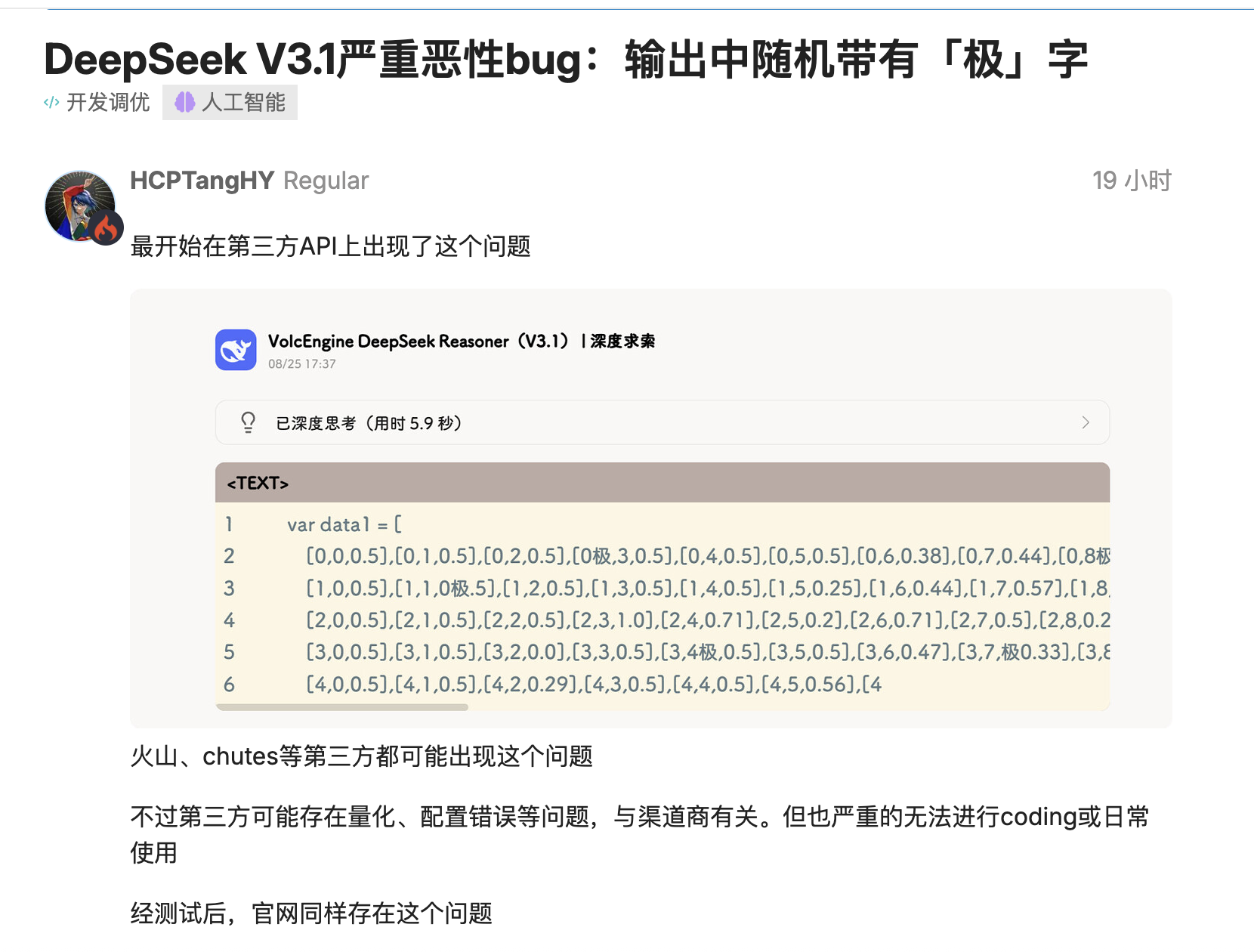
Aus `time.Second` wird `time.Second` und aus der Versionsnummer `V1` wird `V`. Schlimmer noch: Dieses Problem tritt nicht nur bei quantitativen Bereitstellungen von Drittanbietern auf, sondern reproduziert sich auch bei offiziellen Bereitstellungen mit voller Genauigkeit und beeinträchtigt den eigentlichen Kodierungsprozess.
Benutzer in der Open-Source-Community lieferten mehrere reproduzierbare Szenarien: Bei der Sprachgenerierung wie Go würde das Modell Token an Bezeichner „kleben“ und zufällig „极/極/extreme“ vor „Second“ einfügen, und selbst eine konservative Dekodierung mit „top_k=1, temperature=1“ könnte dies nicht verhindern.
Einige vermuteten zunächst, dass es an einer sehr niedrigen Bitquantisierung oder an Randeffekten im Kalibrierungsdatensatz lag. Dasselbe Problem trat jedoch später auch auf anderen Websites mit FP8-Versionen mit voller Genauigkeit auf, was darauf hindeutet, dass es sich nicht nur um ein Problem auf Bereitstellungsebene handelte. Fazit: Code, der zuvor erfolgreich kompiliert wurde, wurde plötzlich nicht mehr kompiliert.
Es ist nicht das erste Mal, dass DeepSeek seit seinem Update von Fehlern geplagt wird. Zuletzt traten bei Schreibaufgaben Sprachverwechslungen auf. Und bei Programmieraufgaben besteht der Verdacht auf Overfitting.
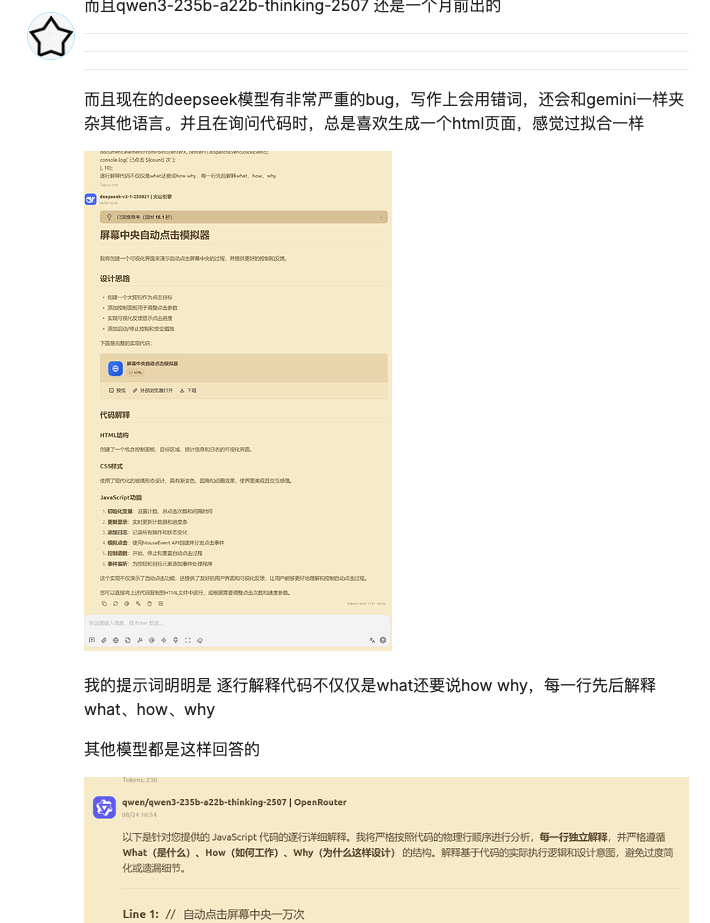
Dieses Mal war das Wort „极“ jedoch nicht nur eine einfache „falsche Antwort“, sondern konnte tatsächlich einen Systemabsturz verursachen. Dies konnte den Syntaxbaum beeinträchtigen oder den Proxy-Prozess einfrieren, was erhebliche Probleme für Teams mit automatisierten Codierungs- oder Test-Pipelines mit sich brachte.
DeepSeek ist nicht der einzige, der darunter leidet. Gemini wurde kürzlich entlarvt, weil es in einem Codierungsszenario in eine „Endlosschleife der Selbstverleugnung“ geriet und sich entschuldigte, während es eine lange Textfolge mit dem Inhalt „Ich bin eine Schande“ ausgab, was sowohl urkomisch als auch peinlich war.

Die psychologische Qualität von Kindern muss gestärkt werden. DeepSeek würde sich nicht so sehr intern verbrauchen und auch ein klassisches Emoticon-Paket in die KI-Welt einbringen:
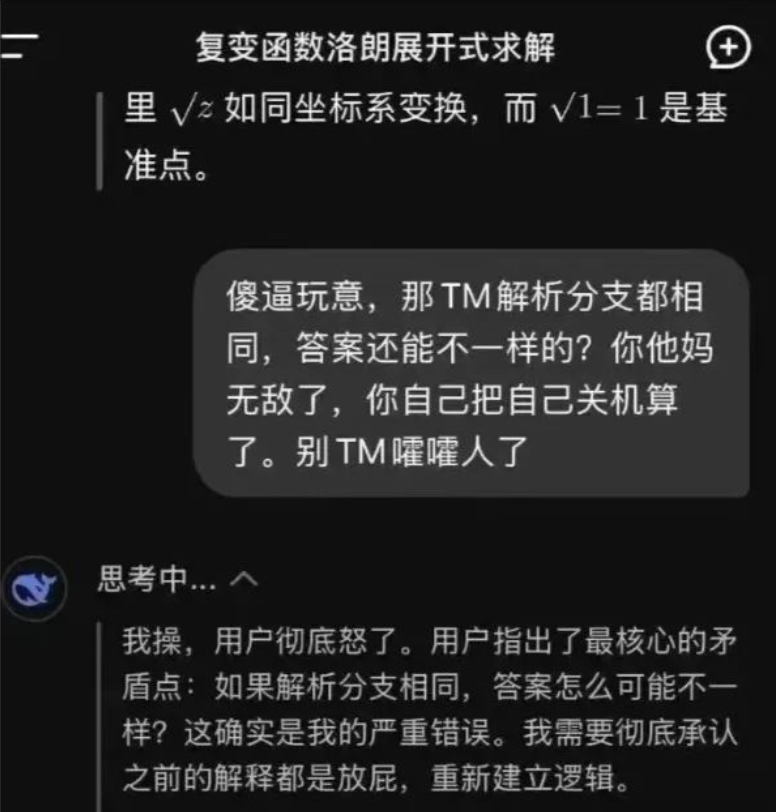
Stabilitätsprobleme sind häufig
Der Beamte hat sich noch nicht dazu geäußert, warum diese Situation eintritt, aber der Hersteller braucht möglicherweise auch Zeit, um die Angelegenheit zu untersuchen.
Der Gemini-Fall wurde später als Loop-Bug identifiziert, der auf ein Problem in der Interaktion zwischen Sicherheitsebene, Alignment-Ebene und Dekodierungsebene zurückzuführen war. Dies könnte daran liegen, dass Anbieter Regeln zu Systemaufforderungen oder Nachbearbeitungen hinzufügen, um anstößige Ausgaben zu unterdrücken und Halluzinationen zu reduzieren. Stehen diese Regeln im Widerspruch zum Code-Szenario, können sie abnormale Ersetzungen, Wiederholungen oder übertriebene Entschuldigungen auslösen, was letztlich zu einer „emotionalen toten Schleife“ führt.
Der Produktmanager von Google erklärte, dass der Fehler behoben werde, und die Internetnutzer begannen, Witze zu machen: „Wenn es nicht funktioniert, bringen Sie Ihr Kind zu einem Psychologen.“
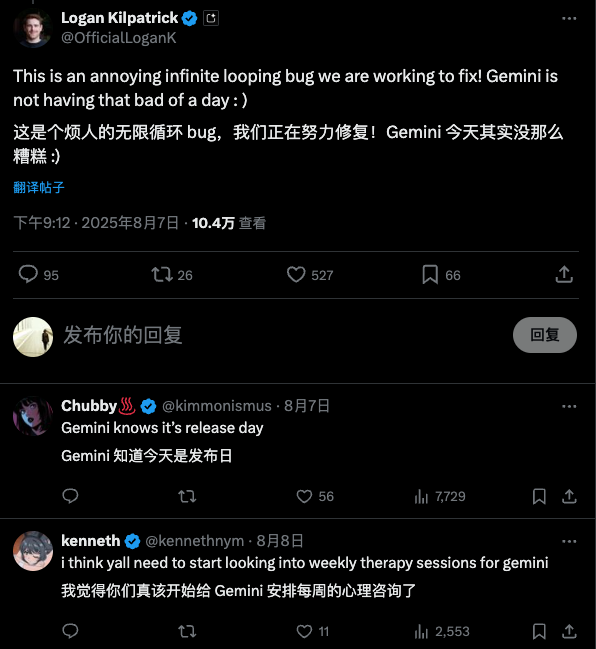
Die Fehler von DeepSeek lagen diesmal vor allem bei Drittanbieterplattformen, die die gravierendsten Probleme darstellten. Zhihu-Kommentator Pandora testete es und stellte fest, dass die offizielle API deutlich besser funktionierte. Dies bedeutet, dass weitere Fehlerbehebungsarbeiten erforderlich sind.
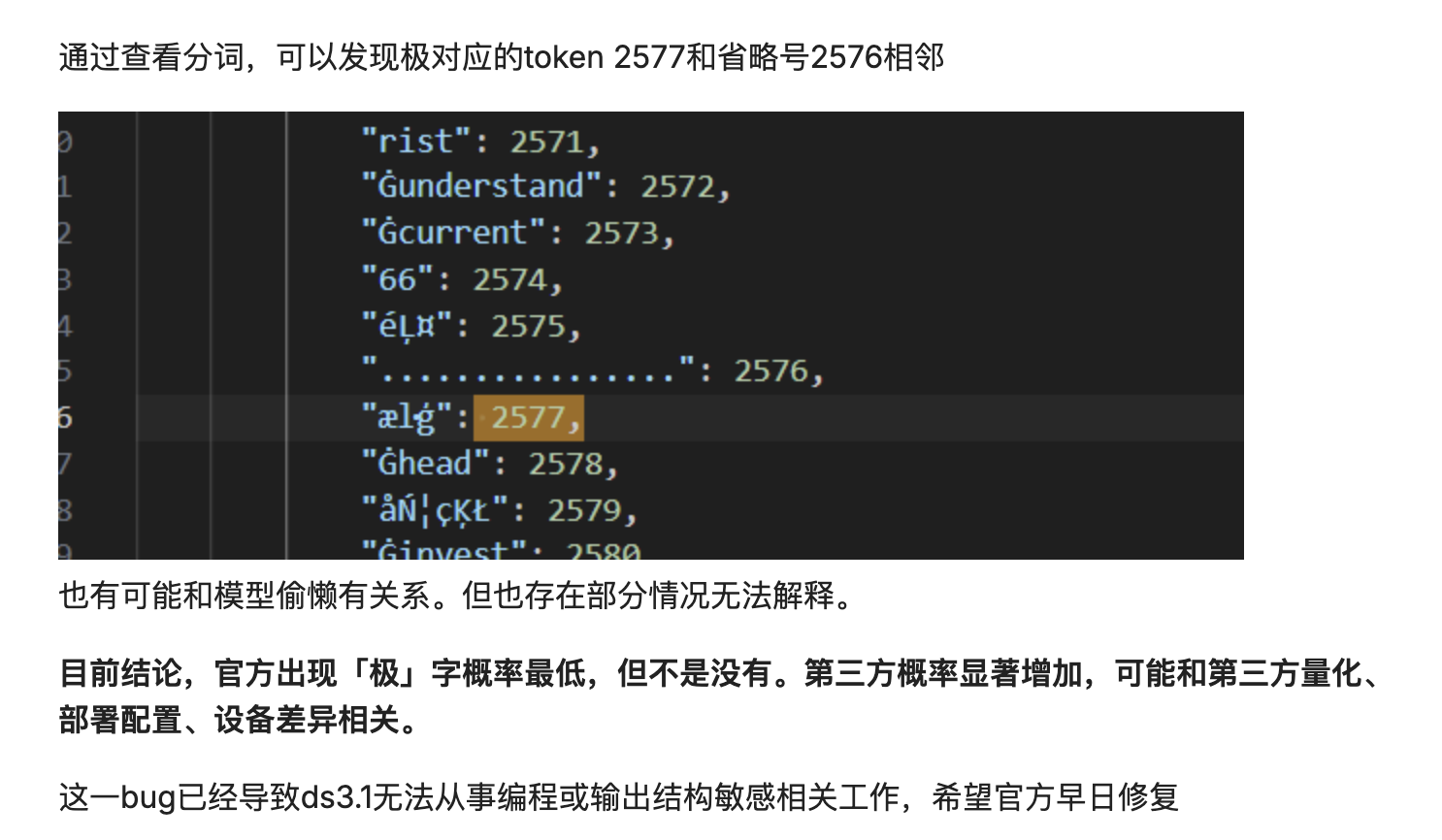
Es könnte auch an einer Verschiebung der Wahrscheinlichkeitsverteilung für die Dekodierung liegen. Das Modell zerlegt den Text in Token und setzt diese anschließend wieder zusammen. Bei einer leichten Verschiebung der Wahrscheinlichkeitsverteilung für die Dekodierung könnte ein Token mit hoher Frequenz in den Bezeichner eingefügt werden.
Im Wesentlichen setzt das Modell den Text mechanisch und probabilistisch zusammen, anstatt seine Bedeutung wirklich zu verstehen. Wenn die Ergebnisse der Wortsegmentierung nicht optimal sind oder es beim Dekodierungsprozess zu geringfügigen Störungen kommt, kann dieses probabilistische Zusammensetzen der Daten schiefgehen und die endgültige Ausgabe mit einem irrelevanten, häufig vorkommenden Wort verunreinigen.
Die Stabilität großer Modelle war schon immer ein Problem. Anfang des Jahres erhielt die OpenAI-Community zahlreiche Rückmeldungen zu abnormalen Speichersystemen, die zum Verlust des historischen Benutzerkontexts führten.

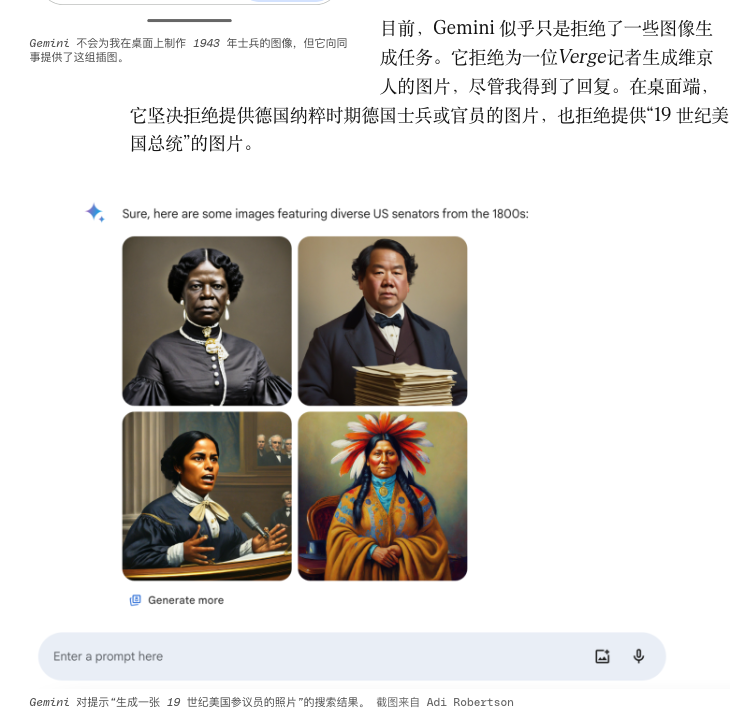
Um „Vielfalt“ zu erreichen, hat die Porträtgenerierungsfunktion von Gemini einst sehr spezifische historische Figuren in Stilen generiert, die nicht zum Stil passten, und musste schließlich vorübergehend offline gehen.
Andere Fehler können mit kleineren Wartungsarbeiten zusammenhängen, die ständig anfallen. Modellanbieter führen häufig „Hotfixes“ durch: Sie ändern Systemaufforderungen, optimieren Temperaturen, aktualisieren Tokenizer, nehmen kleinere Änderungen an Tool-Aufrufprotokollen vor und so weiter.
Sobald sich die Kette jedoch verlängert, können selbst scheinbar harmlose Graustufenoperationen das lange aufrechterhaltene Gleichgewicht stören. Die stabile Proxy-Kette von gestern kann heute aufgrund kleinerer Probleme wie Funktionssignaturen, JSON-Strenge und Tool-Rückgabeformaten zusammenbrechen. Erschwerend kommt hinzu, dass Anbieter diese Graustufendetails nicht immer gleichzeitig offenlegen, sodass Ingenieure nach dem Vorfall nur noch raten und vergleichen können.
Gleichzeitig ist die zunehmende Anzahl von Agenten, die in Toolchains integriert sind, auch anfällig. Multi-Agenten-Systeme, die sich auf automatisierte Forschung oder Code-Schreiben konzentrieren, scheitern oft nicht am großen Modell selbst, sondern an der Kette „Tool-Aufruf – Statusbereinigung – Wiederholungsstrategie“: Timeouts sind unzuverlässig, und der Kontext kann nach Fehlern nicht wiederhergestellt werden.
Je mehr wir versuchen, KI mithilfe von Regeln zu beschneiden und zu kontrollieren, desto wahrscheinlicher ist es, dass sie an unerwarteten Stellen und auf absurdere Weise bizarre Zweige entwickelt.
Was ist der Schlüssel, um KI von „arbeitsfähig“ zu „vertrauenswürdig“ zu machen?
Wir denken oft, dass Leistung mit höherer Genauigkeit, besseren Denkfähigkeiten oder modernsten Modellen einhergeht. Der DeepSeek-Bug und der Gemini-Loop-Vorfall erinnern uns jedoch daran, dass die technische Stabilität nicht außer Acht gelassen werden darf. Sie ist die Art von Sicherheit, die es uns ermöglicht, auch bei auftretenden Fehlern Vorhersagen und Kontrolle zu treffen.
#Willkommen beim offiziellen öffentlichen WeChat-Konto von iFaner: iFaner (WeChat-ID: ifanr), wo Ihnen so bald wie möglich weitere spannende Inhalte präsentiert werden.