
Die Diagnosegenauigkeit der KI von Microsoft ist viermal höher als die menschlicher Ärzte. Sollten wir künftig vor einem Arztbesuch danach fragen?

Die diagnostische Genauigkeit des KI-Arztes übertrifft die von menschlichen Ärzten um das Vierfache.
Es ist vielleicht schwer zu glauben, aber das KI-Team von Microsoft hat vor Kurzem ein KI-Diagnosekoordinationssystem MAI-DxO (MAI Diagnostic Orchestrator) herausgebracht, das genau das leistet.
Der Vergleich erfolgte anhand von 304 realen komplexen Fällen, die wöchentlich im New England Journal of Medicine veröffentlicht wurden. Die Testergebnisse zeigten eine Genauigkeitsrate von 85,5 %.
Dieser Benchmark ist kein Test, der allein durch Auswendiglernen bearbeitet werden kann, sondern ein brandneuer Bewertungsstandard von Microsoft, der „Sequential Diagnosis Bench“ (SD Bench). Er stellt die interaktiven Herausforderungen des realen Diagnose- und Behandlungsprozesses in hohem Maße wieder her:
- Beginnen Sie mit der ersten Symptombeschreibung des Patienten.
- Durch mehrere Fragerunden und die Auswahl verschiedener Tests und Untersuchungen werden nach und nach Informationen über den Zustand des Patienten gesammelt.
- Notieren Sie für jede Inspektion die Kosten des Inspektionsgegenstands und bewerten Sie die Notwendigkeit und die Kosten.
- Stellen Sie eine endgültige Diagnose.
Angesichts der gleichen 304 komplexen Fälle wählte Microsoft weitere 21 praktizierende Ärzte aus den USA und Großbritannien mit 5 bis 20 Jahren klinischer Erfahrung aus. Die Testergebnisse zeigten, dass die durchschnittliche Genauigkeit echter Ärzte nur 20 % betrug, was dem Vierfachen der Lücke von „KI-Ärzten“ entspricht.
Gleichzeitig ordnete dieser „KI-Arzt“ im Vergleich zu menschlichen Ärzten weniger unnötige Untersuchungen an, wodurch die Diagnosekosten um 20 bis 70 Prozent gesenkt wurden.
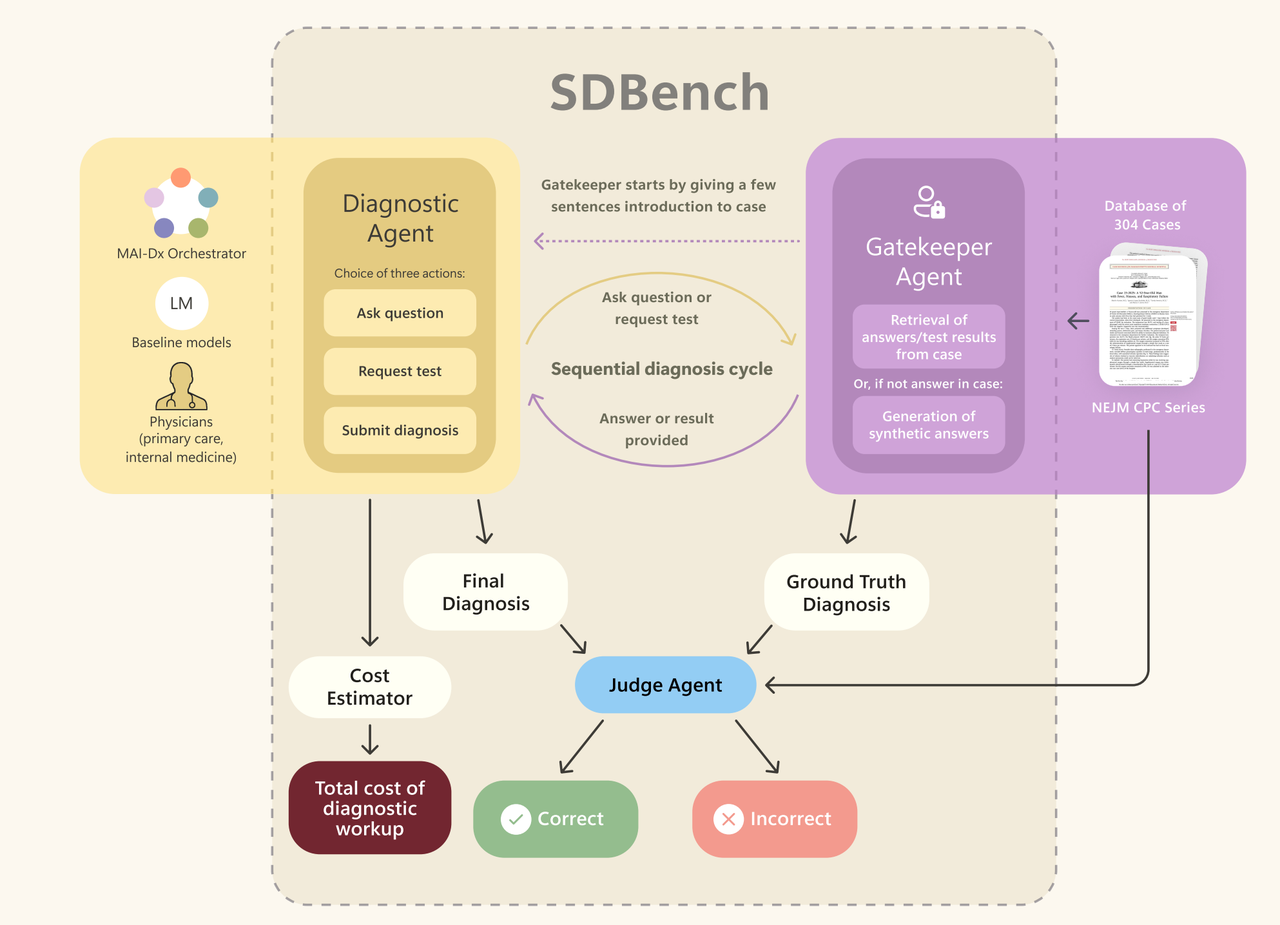
▲Einführungsdiagramm des sequentiellen diagnostischen Benchmarktests. Der „Gatekeeper“ reagiert auf Informationsanfragen von Diagnostikern, und das Bewertungsmodell bewertet die Genauigkeit der endgültigen Diagnose und des Fallberichts des Diagnostikers.
Wie erreicht MAI-DxO eine viermal höhere Genauigkeit als menschliche Ärzte? Es handelt sich weder um ein neu entwickeltes großes Sprachmodell, noch basiert es auf einem einzigen Modell.
MAI-DxO ist ein System, das den kollaborativen Diagnoseprozess mehrerer Ärzte in der Realität simuliert. Dank der kontinuierlichen Weiterentwicklung des aktuellen umfangreichen Sprachmodells gibt es im MAI-DxO-System verschiedene Sprachmodelle, die fünf verschiedene medizinische Rollen übernehmen.
Zu diesen medizinischen Rollen gehören der Hypothesenarzt, der über verschiedene Ergebnisse spekuliert, der Auswahlarzt, der Herausforderungsarzt, der aktuelle diagnostische Annahmen in Frage stellt, der Kostenmanagementarzt, der unnötige Tests vermeidet, und der Checklistenarzt, der sicherstellt, dass die Diagnoseschritte und die Auswahllogik konsistent sind.
Diese „Ärzte“ arbeiten zusammen, simulieren den Arbeitsablauf eines menschlichen Ärzteteams vollständig und gleichen die Mängel aus, die ein einzelnes KI-Modell bei komplexen Diagnosen haben kann.
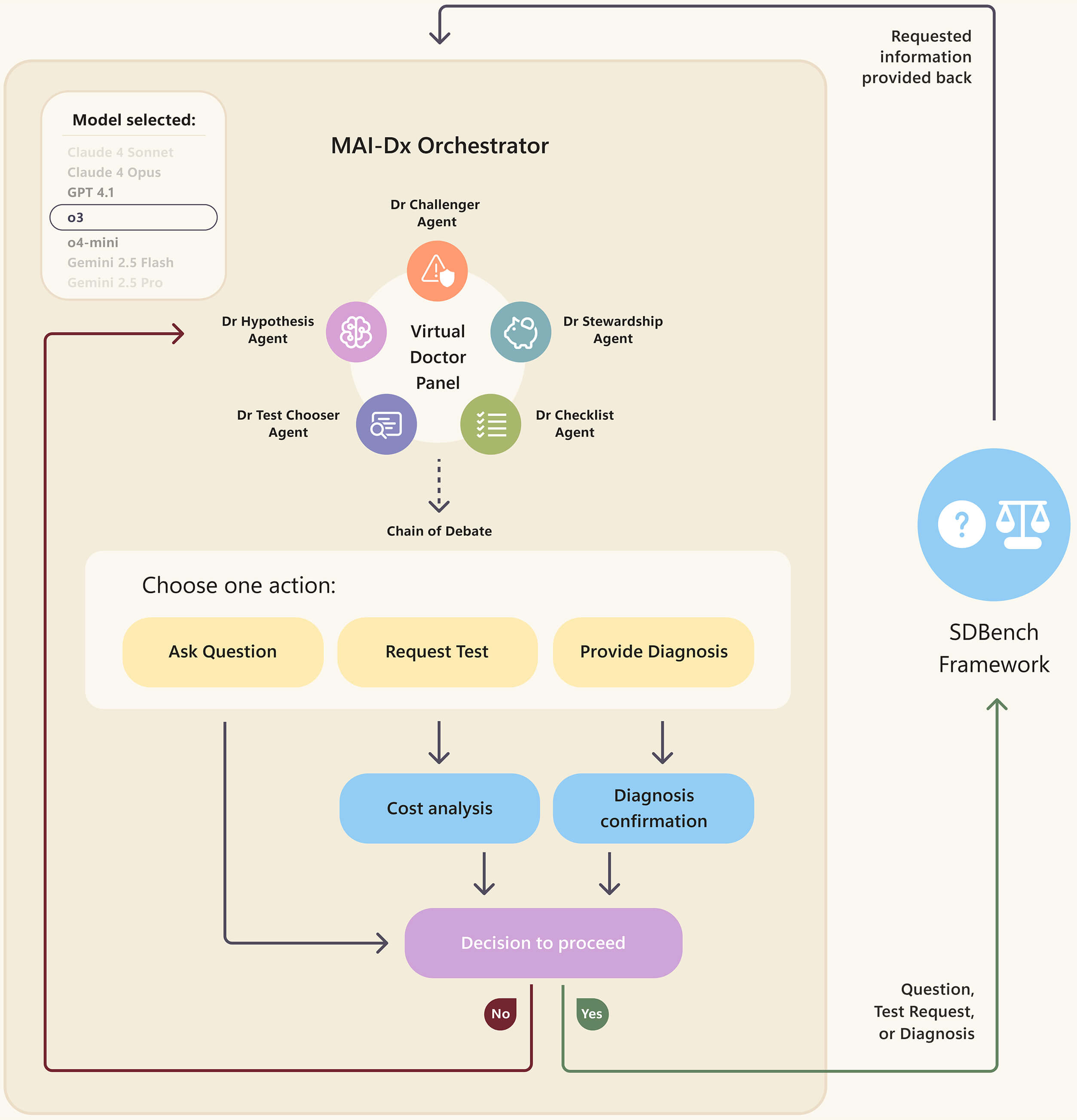
▲MAI-DxO-Systemübersicht
Wie im oben beschriebenen Systemübersichtsdiagramm gezeigt, simuliert MAI-DxO den Ablauf eines Krankenhausbesuchs zum Arzt vollständig.
- Zu Beginn der Konsultation erhält MAIN-DxO eine kurze klinische Geschichte, normalerweise 2–3 Sätze, die die grundlegenden Einzelheiten des Falls abdeckt.
- Anschließend beginnt MAI-DxO damit, die wichtigsten Wünsche des Patienten zusammenzufassen und den nächsten Schritt zu wählen, d. h., ob dem Patienten weitere Fragen gestellt oder eine Untersuchung angefordert werden soll.
- Die Kosten jeder Untersuchung werden berechnet und es finden mehrere Interaktionsrunden statt, bis die endgültige Diagnose vorliegt.
Während des Testprozesses setzte MAI-DxO o4-mini und professionelle Ärzte ein, um einen „Gatekeeper“ einzurichten, der sicherstellen sollte, dass die Informationen, die das System der KI gab, mit den Informationen übereinstimmten, die normale Ärzte während Konsultationen und in der klinischen Praxis erhalten konnten.
Die Einführung von MAI-DxO hat die Leistung großer Sprachmodelle in der medizinischen Diagnostik deutlich verbessert. Microsoft testete verschiedene Modelle der Serien OpenAI, Gemini, Claude, Grok, DeepSeek und Llama, und die Leistung war besser als bei Verwendung nur eines einzigen KI-Modells. Die beste Kombination war die Kombination aus MAI-DxO und OpenAIs o3.
Da MAI-DxO nicht durch große Sprachmodelle eingeschränkt ist, kann es sich auch synchron anpassen, wenn in Zukunft bessere Modelle verfügbar werden.
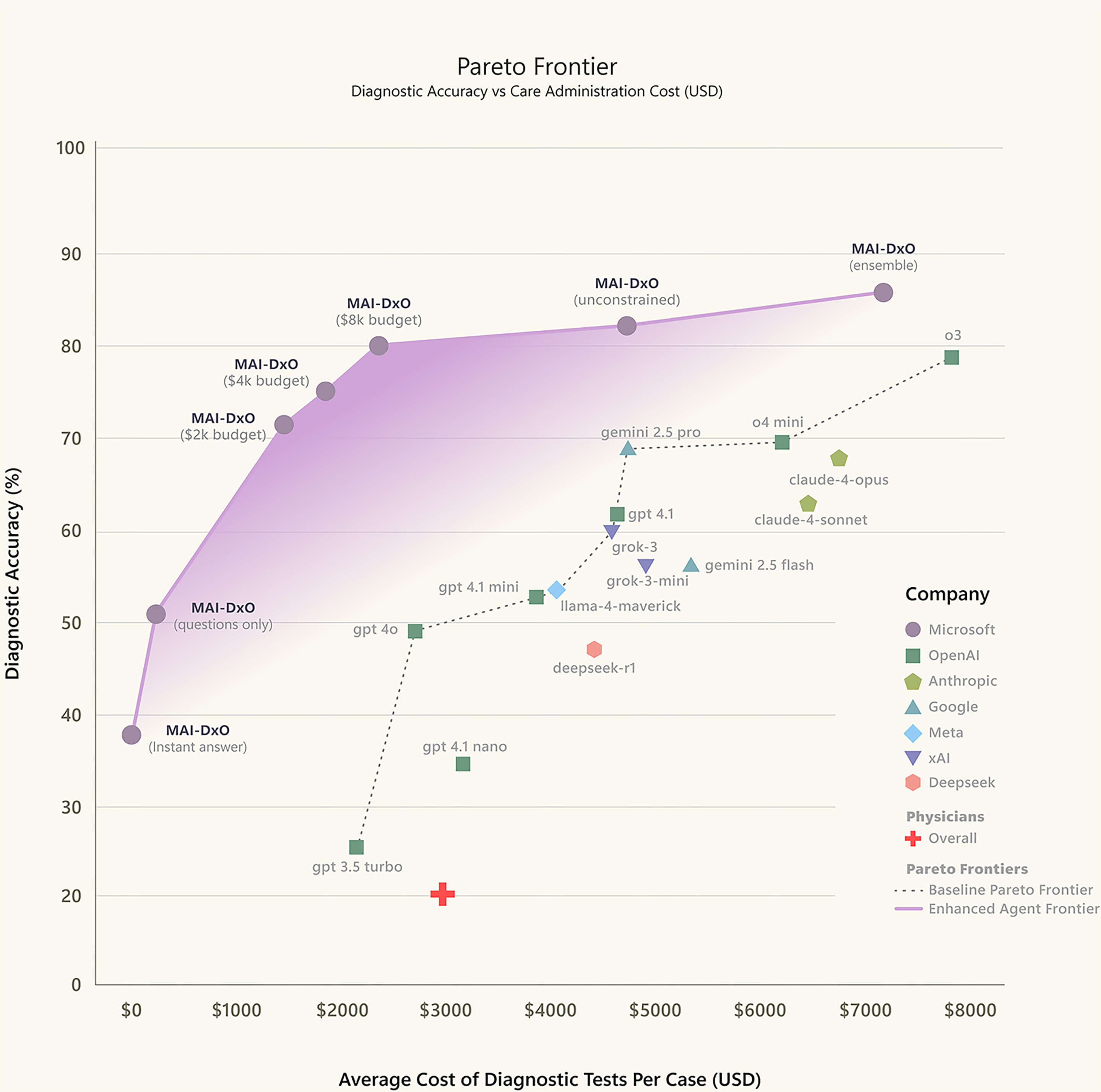
▲Vergleich der Genauigkeit verschiedener Modelle der künstlichen Intelligenz und der durchschnittlichen Kosten für diagnostische Tests pro Fall
Obwohl es den Anschein hat, als hätte sich ein „KI-Arzt“ herausgebildet, ist es für die KI nicht einfach, ein guter Arzt zu sein.
Microsoft erwähnte am Ende des Projektpapiers, dass diese Studie erhebliche Einschränkungen aufweise. So hatten die 21 am Vergleichsexperiment teilnehmenden Ärzte keinen Zugang zu Diskussionshilfen, Nachschlagewerken, generativer KI und anderen Ressourcen. Zudem wurden im Microsoft-Experiment nur die schwierigsten Fallprobleme behandelt, ohne dass weitere Tests zur Diagnose alltäglicher Krankheiten durchgeführt wurden.
Microsoft betont, dass KI Ärzte nicht ersetzen, sondern sowohl Ärzten als auch Patienten als Assistent dienen wird.
Doch dieser Assistent für Ärzte und Patienten erregt weiterhin weltweit Aufmerksamkeit. Bereits im März dieses Jahres veröffentlichte Microsoft mit Microsoft Dragon Copilot den ersten KI-Assistenten der Medizinbranche für klinische Arbeitsabläufe, der Ärzten dabei helfen kann, klinische Fallakten besser zu organisieren.
Die medizinische künstliche Intelligenzplattform IBM Watson Health von IBM, DeepMind von Google und NVIDIA Clara von NVIDIA bringen allesamt neue Veränderungen in medizinische Szenarien wie medizinische Anleitung, Beratung und Pathologie.
Vor einiger Zeit veröffentlichte die Alibaba DAMO Academy außerdem das weltweit erste KI-Modell für die bildgebende Untersuchung von Magenkrebs, DAMO GRAPE. Dabei wurde erstmals einfache CT-Scans mit Deep Learning kombiniert, um Magenkrebsläsionen im Frühstadium zu erkennen.
Huawei hat sein Medizin- und Gesundheitskorps erst in diesem Jahr gegründet und letzte Woche in Zusammenarbeit mit dem Ruijin-Krankenhaus das Open-Source-Pathologiemodell RuiPath angekündigt, das über klinische Verifizierungsfunktionen verfügt und sieben häufige Krebsarten, darunter Lungenkrebs, abdeckt.
In der Medizin ist höchste Präzision erforderlich, und ein Fehler von 0,01 % kann schwerwiegende Folgen haben. Das ist etwas völlig anderes als die Fehler, die beim Schreiben von Code durch Programmierer auftreten.
MAI-DxO simuliert den Ablauf einer echten medizinischen Konsultation und es scheint, dass der Weg zur KI-gestützten medizinischen Versorgung immer deutlicher wird.
Von der Baidu-Beratung bis zur ChatGPT-Beratung denke ich, dass Sie in Zukunft nicht nur die Untersuchungsergebnisse normaler Krankenhäuser abrufen, Krankenhausrankings prüfen und für die Befragung von Online-Ärzten bezahlen können, sondern auch zuerst einen Blick auf diesen „KI-Arzt“ werfen können.
#Willkommen beim offiziellen öffentlichen WeChat-Konto von iFanr: iFanr (WeChat-ID: ifanr), wo Ihnen so bald wie möglich weitere spannende Inhalte präsentiert werden.