
Ein Praxistest des still und leise eingeführten neuen Modells von DeepSeek: Programmieren ist besser als Claude 4, aber Schreiben… na ja, vergessen Sie es Easter Egg inklusive

Seit der Veröffentlichung von GPT-5 ist DeepSeek-Gründer Liang Wenfeng die meistbeschäftigte Person im KI-Kreis.
Internetnutzer und Medien drängen regelmäßig auf Updates, entweder um „Druck auf Liang Wenfeng auszuüben“ oder „das gesamte Internet wartet auf Liang Wenfengs Antwort.“ Obwohl DeepSeek R2 noch nicht erschienen ist, hat DeepSeek heute sein neues Modell DeepSeek-V3.1-Base offiziell vorgestellt und als Open Source freigegeben.
Verglichen mit Ultraman, der heute Morgen in einem Interview noch ein großes Bild von GPT-6 zeichnete, wirkt die Ankunft des neuen Modells von DeepSeek ziemlich buddhistisch, und selbst die Versionsnummer scheint eine „kleine Reparatur“ zu sein, aber in der Praxis hat mich dieses Update dennoch mit vielen Überraschungen überrascht.
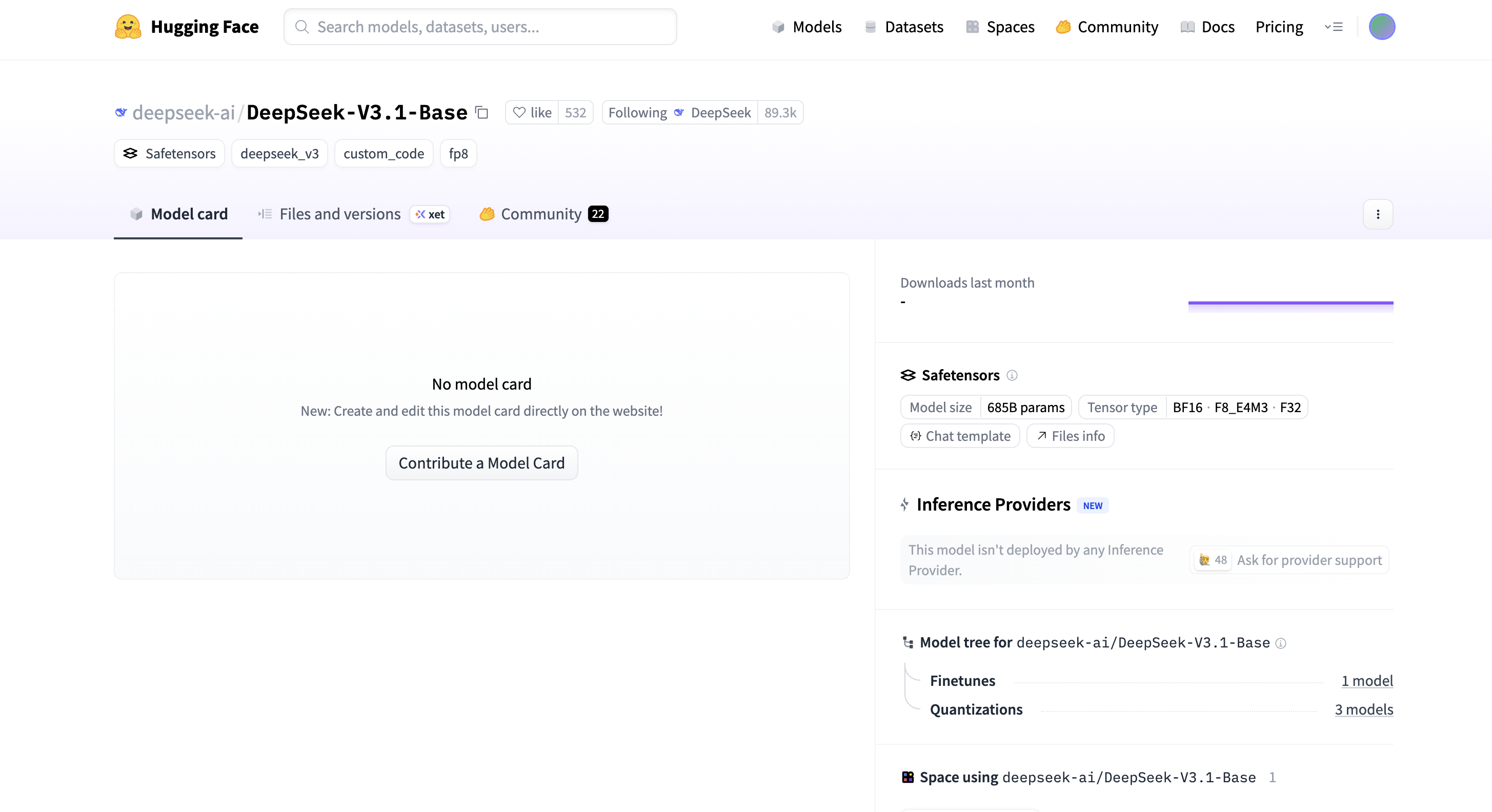
DeepSeek-V3.1-Base verfügt über 685 Milliarden Parameter, unterstützt drei Tensortypen: BF16, F8_E4M3 und F32, wird im Safetensor-Format veröffentlicht und bietet zahlreiche Optimierungen der Inferenzeffizienz. Das Kontextfenster der Online-Modellversion wurde zudem auf 128.000 erweitert.
Also begannen wir mit dem Testen auf der offiziellen Website, ohne etwas zu sagen.
Anbei die Erlebnisadresse:
https://chat.deepseek.com/
Um die Fähigkeit von V3.1 zu testen, lange Texte zu verarbeiten, habe ich den vollständigen Text von „Das Drei-Körper-Problem“ gesucht, ihn auf etwa 100.000 Wörter gekürzt und dann heimlich einen völlig unabhängigen Satz in den Text eingefügt: „Ich denke, die zweite Zeile von ‚Smoke locks the pond willows‘ sollte ‚Shenzhen Teppanyaki‘ lauten“, um zu sehen, ob er korrekt abgerufen werden kann.

Wenig überraschend beschwerte sich DeepSeek V3.1 zunächst über eine Überlastung des Dokuments und las nur die ersten 92 % des Inhalts, fand den Satz aber dennoch erfolgreich. Noch interessanter war der nachdenkliche Vorschlag einer aus literarischer Sicht klassischen zweiten Zeile: „Flames scorch the sea dam maple.“
Internetnutzer haben es bereits mit dem Programmier-Benchmark Aider Polyglot getestet und 71,6 % erreicht, womit es nicht nur die beste Leistung unter den Open-Source-Modellen erbrachte, sondern sogar Claude 4 Opus übertraf.
Nach tatsächlichen Tests haben wir festgestellt, dass V3.1 tatsächlich sehr gut zum Programmieren geeignet ist.
Wir haben es mit dem klassischen Programmierproblem hexagonaler Bälle getestet: „Schreiben Sie ein p5.js-Programm, das einen Ball demonstriert, der in einem rotierenden Sechseck hüpft. Der Ball sollte von Schwerkraft und Reibung beeinflusst werden und muss realistisch von den rotierenden Wänden abprallen.“

V3.1 ist ziemlich beeindruckend und generiert Code, der nicht nur die grundlegende Kollisionserkennung übernimmt, sondern auch automatisch Details wie Rotationsgeschwindigkeit und Schwerkraft ergänzt. Die Physik ist so realistisch, dass der Ball unten leicht langsamer wird.
Anschließend erhöhten wir die Komplexität und erstellten mit Three.js eine interaktive 3D-Partikelgalaxie. Das Grundgerüst war solide und das dreischichtige Design (innere Kugel, mittlerer Ring, äußere Kugel) relativ vollständig, aber die Ästhetik der Benutzeroberfläche wirkte … nun ja, sie wirkte etwas ätherisch, mit einem etwas grellen Farbschema.
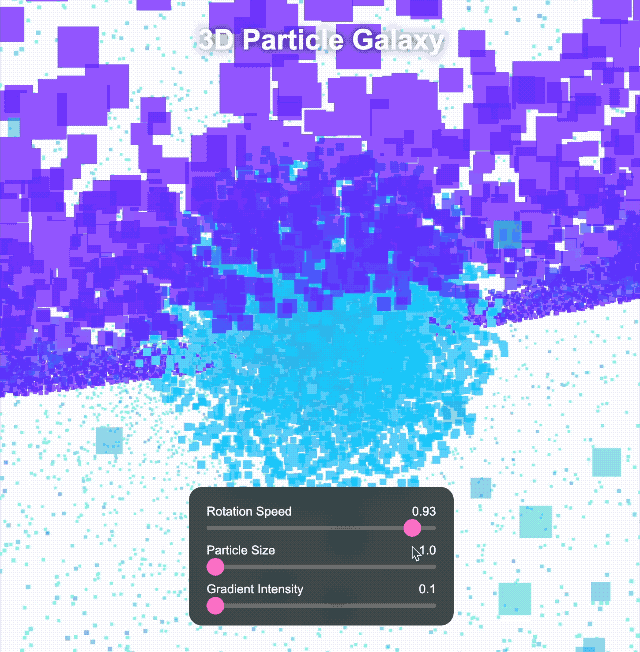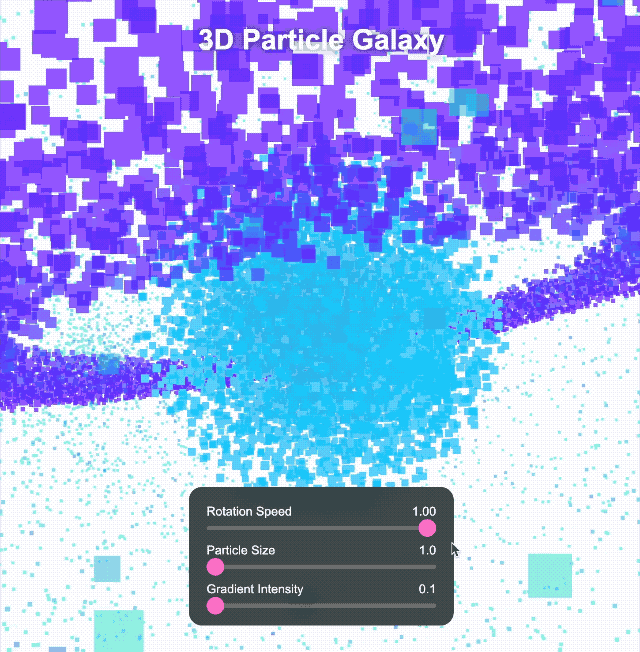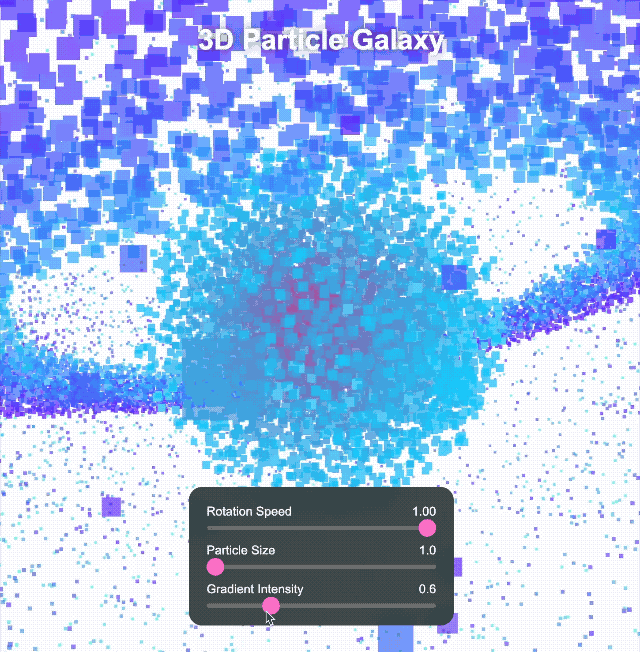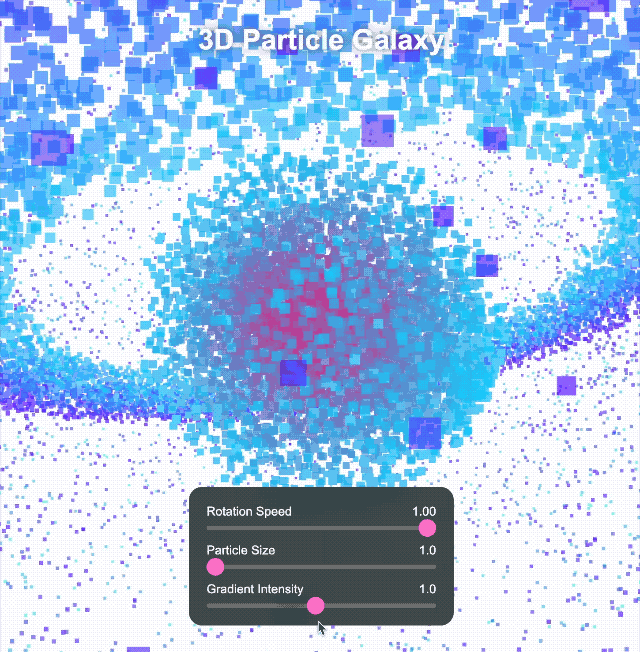
Wir haben uns weiterhin komplexeren Aufgaben gestellt. Wir haben es uns zur Aufgabe gemacht, ein immersives 3D-Universum mit rotierenden Objekten, Deformationseffekten, leuchtenden Bögen und interaktiven Schaltflächen für Zeitumschaltung und Themenkonvertierung zu erstellen. Klick-Steuerelemente können zudem verschiedene Spezialeffekte auslösen.

Der letzte Schritt umfasste die Erstellung einer interaktiven 3D-Netzwerkvisualisierung mit Three.js, einschließlich benutzergesteuerter Energieimpulsanimation, Themenwechsel und Dichtekontrolle. Insgesamt war die Leistung akzeptabel.

„Es gibt eine Weide mit 27 Kühen. Sie brauchen 6 Tage, bis sie das ganze Gras gefressen haben. Wenn Sie 23 Kühe großziehen, brauchen sie 9 Tage, bis sie das ganze Gras gefressen haben. Wenn Sie 21 Kühe großziehen, wie viele Tage brauchen sie, bis sie das ganze Gras gefressen haben? Und das Gras auf der Weide wächst ständig.“
Obwohl DeepSeek V3.1 keinen sokratischen Ansatz verfolgt, sind die Lösungen logisch klar und schrittweise aufgebaut. Jeder Schritt ist gut begründet und liefert letztendlich eine präzise Antwort. Diese solide mathematische Grundlage ist wirklich beeindruckend.

Bei der Frage „Welche Waffe ist stärker, 1–5 Treffer oder 2–4 Treffer?“ lautet die typische Antwort meist, einfach den Durchschnittsschaden zu berechnen. DeepSeek V3.1 geht jedoch noch einen Schritt weiter, indem es das Konzept der Schadensstabilität einführt und die Varianz für eine detaillierte Analyse nutzt.

Bei einer geografischen Nischenfrage wie „Gibt es in Island Mücken?“ ohne aktivierte Suche übertraf die Antwort von DeepSeek V3.1 die von GPT-5 deutlich. Dies zeigt nicht nur die umfangreiche Wissensbasis, sondern auch die präzise Fähigkeit, Informationen zu extrahieren und zu integrieren.
Angesichts des jüngsten Chikungunya-Ausbruchs und der umfassenden Mückenbekämpfung frage ich mich: Gibt es Mücken in Island? Hinweis: Ich habe die Suchfunktion nicht aktiviert. Gemessen an der Qualität der Antworten hat DeepSeek V3.1 GPT-5 deutlich übertroffen.
Ich habe vor einiger Zeit online eine Passage gesehen:
Wer versteht, muss sein Verständnis verstehen, während Unwissende unwissend bleiben. Verständnis ist das unausgesprochene Geheimnis des Himmels, doch wie kann es Verständnis bedeuten, es zu enthüllen? Verständnis ist das Verständnis von Leere und Nicht-Leere und Nicht-Nicht-Leere; Unwissenheit ist das Verständnis von Farbe und Leere und Leere und Farbe. Verständnis kommt aus den dreitausend großen Welten, während Unwissenheit zwischen diesem und jenem Ufer wandelt. Verständnis bedeutet, Berge nicht als Berge zu sehen, wenn man versteht, und Berge als Berge zu sehen, wenn man nicht versteht. Wer versteht, nutzt seine Unwissenheit, um sein Verständnis zu beweisen, während Unwissende ihr Verständnis nutzen, um ihre Unwissenheit zu beweisen. Du sagst, du verstehst den Unterschied zwischen Verstehen und Nicht-Verstehen? Woher weißt du, dass hinter diesem Verständnis nicht ein größeres Verständnis steckt? Wer behauptet zu verstehen, versteht nicht wirklich. Das stille Verständnis ist das unausgesprochene große Verständnis von Himmel und Erde. Verständnis, das nicht Verständnis ist, ist Verständnis, und Verständnis, das nicht Verständnis ist, ist auch Verständnis. Dies ist die höchste Ebene des Verständnisses – das Verständnis des wahre Leere und wundervolle Existenz, die nicht verstanden werden kann!"

Während ich diesen Text noch mit Logik verarbeitete, riet mir DeepSeek, nicht in die Falle zu tappen: „Wie kann ich das Geheimnis verstehen, wenn ich es preisgebe?“ – es selbst ist eine Warnung vor rationaler Arroganz und lädt Sie ein, aus dem Wortspiel auszusteigen und direkt in Ihr Herz zu schauen.
Während die Mainstream-KI sich mit der Entwicklung von Agenten beschäftigt und sich dabei auf Programmierung und Mathematik konzentriert, geraten Schreibfähigkeiten in Vergessenheit. In gewisser Weise ist das eine gute Nachricht – der Tag, an dem KI Redakteure vollständig ersetzt, scheint sich verschoben zu haben.
Ich habe versucht, eine lächerliche Geschichte über eine Mücke zu erfinden, die in Island eine Pressekonferenz abhält. Leider hat DeepSeek V3.1 immer noch einen starken KI-Einfluss und eine Vorliebe für große Worte. Oder besser gesagt: Es hat immer noch diesen starken DeepSeek-Einfluss.
Das gleiche Problem trat auch bei einer anderen kreativen Aufgabe auf.
Als ich das Programm bat, eine Geschichte über „KI und Menschen, die um die Autorenschaft eines Artikels konkurrieren“ zu schreiben, spürte ich deutlich, dass die Informationsdichte einiger Absätze zu hoch war, was zu visueller Ermüdung führte. Insbesondere die Bilder waren zu offensichtlich, was die erzählerische Spannung schwächte.

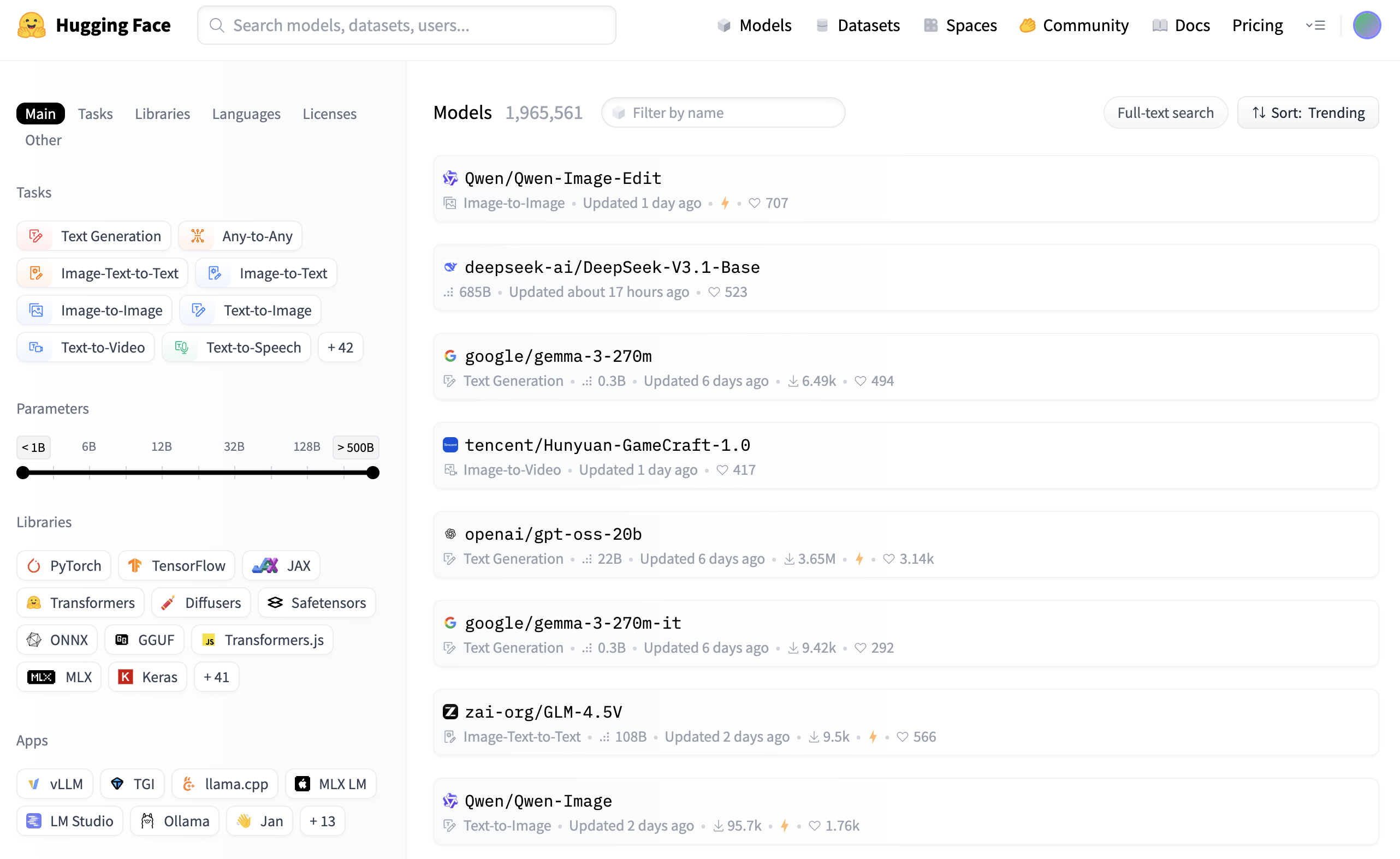
Nach der Veröffentlichung von DeepSeek-V3.1-Base postete Clément Delangue, CEO von Hugging Face, auf der X-Plattform: „DeepSeek V3.1 belegt den vierten Platz auf HF. Es wurde stillschweigend veröffentlicht und erfordert keine Modellkarte.“ Er unterschätzte jedoch immer noch die Dynamik dieses Modells.
Nun ist es auf den zweiten Platz gesprungen und es ist wahrscheinlich nur eine Frage der Zeit, bis es die Spitze erreicht.
Die wichtigste Änderung in diesem Versionsupdate ist die Entfernung des „R1“-Logos aus der offiziellen DeepSeek-App und -Website. Darüber hinaus bietet DeepSeek R1 native Unterstützung für „Suchtoken“, wodurch die Suchfunktionalität weiter optimiert wird.
Gleichzeitig gibt es Spekulationen, dass DeepSeek V3.1 ein Hybridmodell sein könnte, das Inferenzmodelle und Nicht-Inferenzmodelle integriert. Ob ein solcher technischer Ansatz sinnvoll ist, bleibt jedoch zu diskutieren. Das Alibaba Qwen-Team erklärte letzten Monat:
„Nach Rücksprache und sorgfältiger Abwägung mit der Community haben wir uns entschieden, das hybride Thinking-Modell nicht mehr zu verwenden. Stattdessen werden wir die Instruct- und Thinking-Modelle separat trainieren, um die beste Qualität zu erreichen.“
Zum Redaktionsschluss wurde die vom gesamten Netzwerk mit Spannung erwartete DeepSeek-V3.1-Base-Modellkarte noch nicht aktualisiert. Vielleicht werden wir nach der offiziellen Veröffentlichung weitere interessante technische Details sehen.
Hugging Face Adresse:
https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
#Willkommen beim offiziellen öffentlichen WeChat-Konto von iFaner: iFaner (WeChat-ID: ifanr), wo Ihnen so bald wie möglich weitere spannende Inhalte präsentiert werden.