
Gerade hat OpenAI drei neue Modelle auf einmal veröffentlicht! Zu diesem Zweck habe ich auch eine neue Website erstellt
Gerade hat OpenAI die Einführung einer neuen Generation von Audiomodellen in seiner API angekündigt, einschließlich Speech-to-Text- und Text-to-Speech-Funktionen, die es Entwicklern ermöglichen, auf einfache Weise leistungsstarke Sprachagenten zu erstellen.
Nachfolgend sind die wichtigsten Highlights des neuen Produkts zusammengefasst
- gpt-4o-trancribe (Sprache in Text): Deutliche Reduzierung der Wortfehlerrate (WER) und übertrifft bestehende Whisper-Modelle bei mehreren Benchmarks
- gpt-4o-mini-trancribe (Sprache in Text): eine optimierte Version von gpt-4o-trancribe, schneller und effizienter
- gpt-4o-mini-tts (Text-to-Speech): Durch die erstmalige Unterstützung der „Steuerbarkeit“ können Entwickler nicht nur angeben, „was sie sagen“, sondern auch steuern, „wie sie es sagen“.
Laut OpenAI wird das neu eingeführte gpt-4o-trancribe seit langem mit vielfältigen und hochwertigen Audiodatensätzen trainiert, wodurch die Nuancen der Sprache besser erfasst, Fehlerkennungen reduziert und die Zuverlässigkeit der Transkription erheblich verbessert werden können.
Daher eignet sich gpt-4o-trancribe besser für die Bewältigung anspruchsvoller Szenarien wie unterschiedliche Akzente, laute Umgebungen und wechselnde Sprechgeschwindigkeiten, wie z. B. Kunden-Callcenter, Besprechungsprotokolle und andere Bereiche.
gpt-4o-mini-trancribe basiert auf der GPT-4o-mini-Architektur und überträgt Fähigkeiten von großen Modellen durch Wissensdestillationstechnologie. Obwohl der WER (je niedriger, desto besser) etwas höher ist als der des Vollversionsmodells, ist er immer noch besser als das ursprüngliche Whisper-Modell und eignet sich besser für Anwendungsszenarien mit begrenzten Ressourcen, die jedoch dennoch eine hochwertige Spracherkennung erfordern.
Die Leistung dieser beiden Modelle im mehrsprachigen FLEURS-Benchmark-Test übertraf die bestehenden Whisper v2- und v3-Modelle, insbesondere in Englisch, Spanisch und anderen Sprachen.
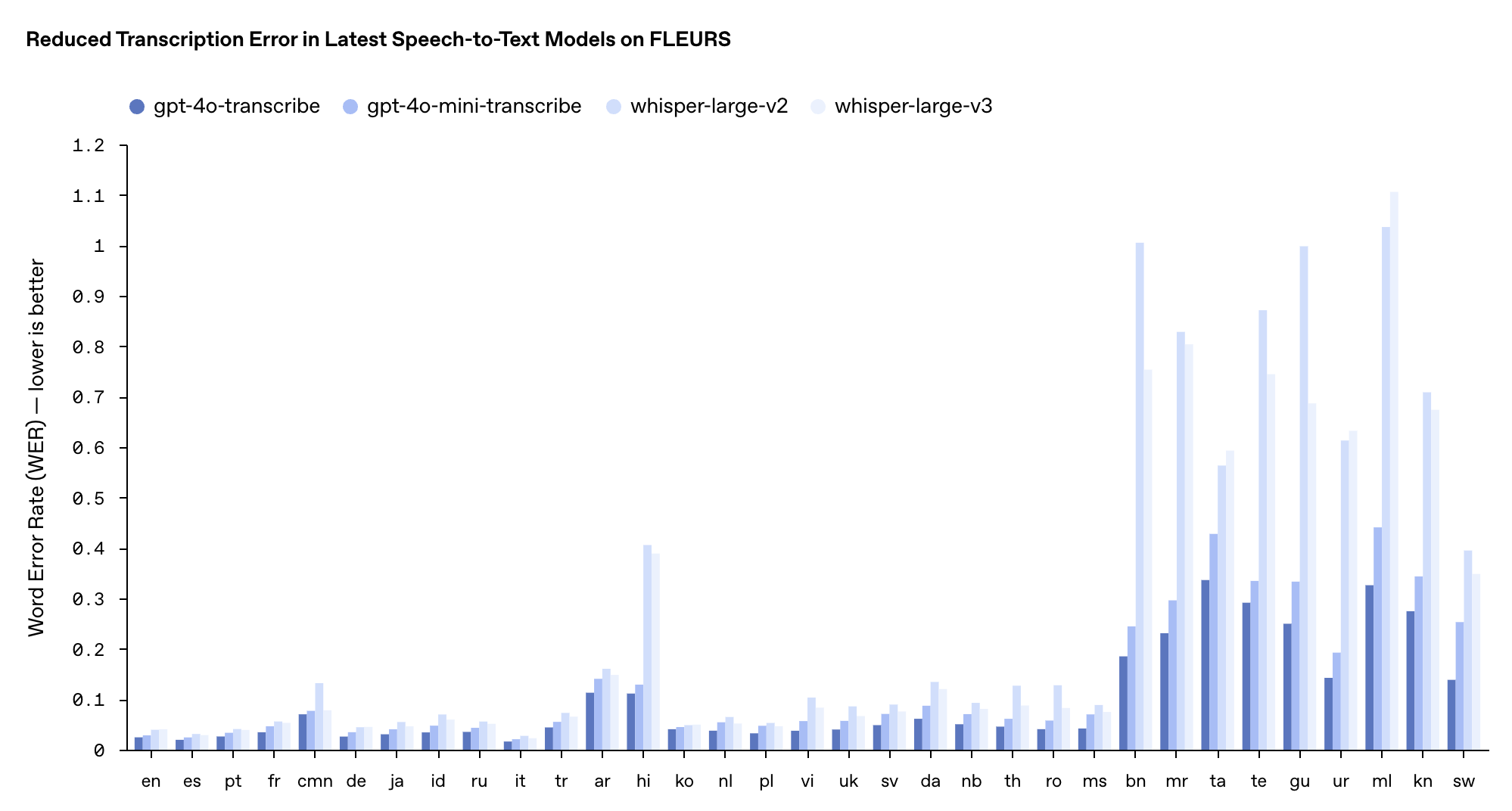
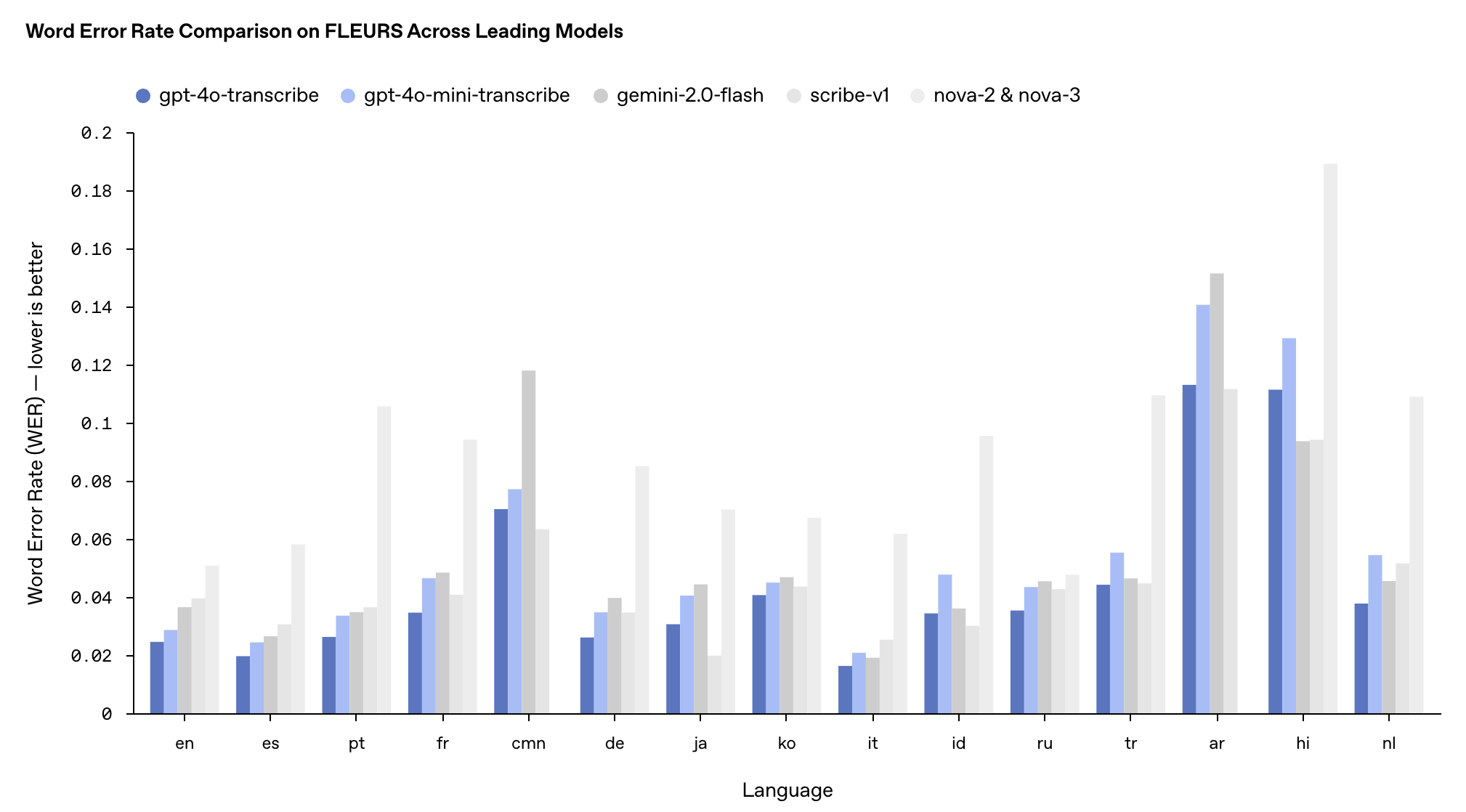
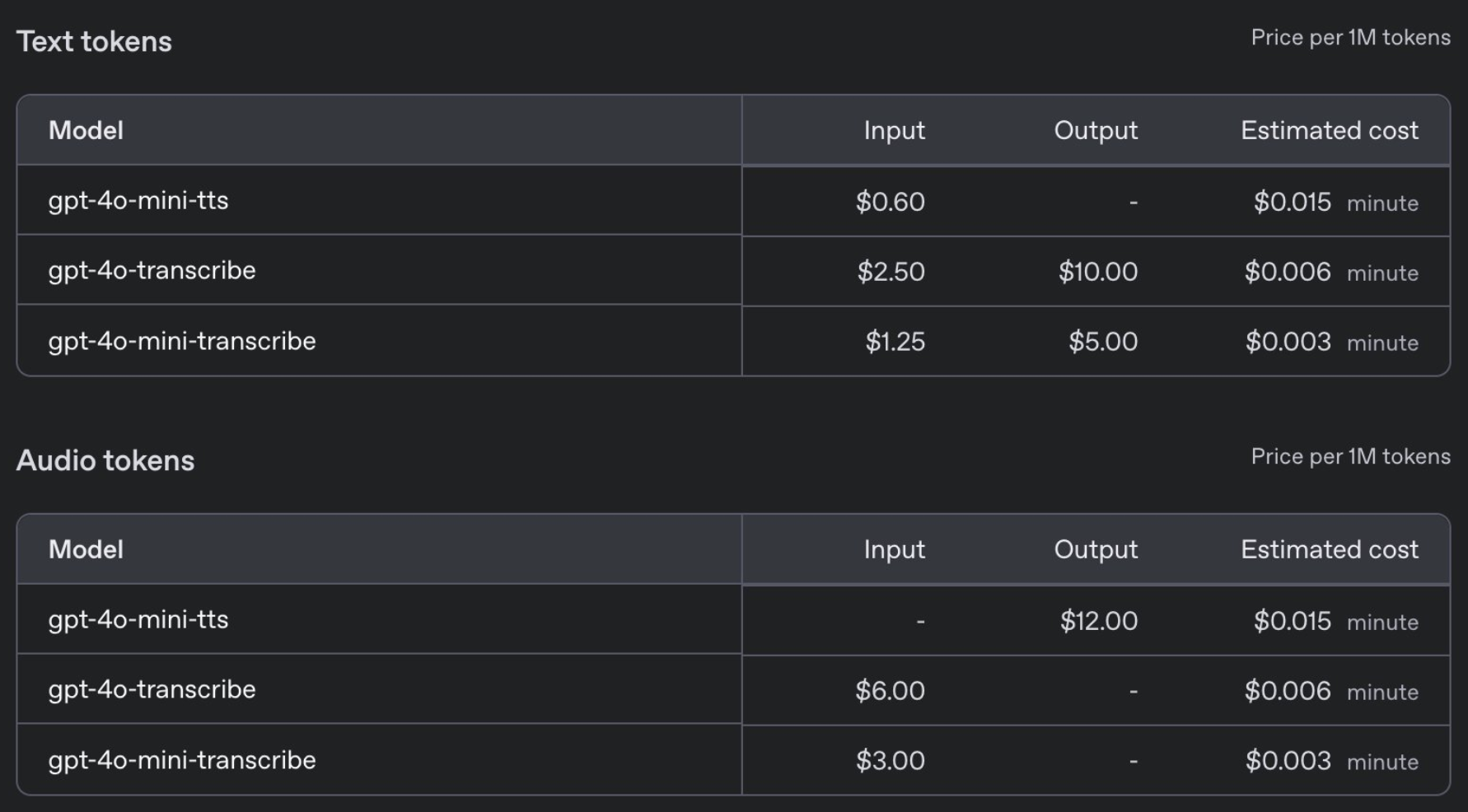
Preislich liegt der Preis für GPT-4o-trancribe mit 0,006 US-Dollar pro Minute auf dem gleichen Niveau wie für das vorherige Whisper-Modell, während GPT-4o-mini-trancribe mit 0,003 US-Dollar pro Minute nur die Hälfte kostet.
Gleichzeitig veröffentlichte OpenAI auch ein neues Text-to-Speech-Modell gpt-4o-mini-tts. Zum ersten Mal können Entwickler nicht nur festlegen, was sie sagen, sondern auch steuern, wie sie es sagen.
Konkret können Entwickler eine Vielzahl von Sprachstilen voreinstellen, z. B. „Ruhig“, „Surfer“, „Professionell“, „Mittelalterlicher Ritter“ usw. Der Sprachstil kann auch entsprechend den Anweisungen angepasst werden, z. B. „Sprechen Sie wie ein mitfühlender Kundendienstmitarbeiter“. Der Preis ist mit nur 0,015 US-Dollar pro Minute erschwinglich.
Die Sicherheit darf nicht auf die leichte Schulter genommen werden, und OpenAI sagt, dass gpt-4o-mini-tts kontinuierlich überwacht wird, um sicherzustellen, dass seine Ausgabe mit dem voreingestellten Synthesestil übereinstimmt.
Hinter diesen technologischen Fortschritten stehen viele Innovationen von OpenAI:
- Das neue Audiomodell basiert auf der GPT-4o- und GPT-4o-mini-Architektur und wird mithilfe echter Audiodatensätze vorab trainiert
- Wenden Sie die Wissensdestillationsmethode destillierter Datensätze an, die durch die Selbstspielmethode erstellt wurden, um einen Wissenstransfer von großen Modellen zu kleinen Modellen zu erreichen.
- Die Integration von Reinforcement Learning (RL) in die Speech-to-Text-Technologie kann die Transkriptionsgenauigkeit erheblich verbessern und „Illusions“-Phänomene reduzieren.
In der Live-Übertragung am frühen Morgen zeigte uns OpenAI einen Anwendungsfall des AI-Modeberaters Agent.
Als der Benutzer fragte: „Was ist meine letzte Bestellung?“, antwortete das System reibungslos: Die vom Benutzer am 9. Februar bestellten Patagonia-Shorts wurden versandt und die Bestellnummer „AD 507“ wurde in der Folgefrage korrekt angegeben.
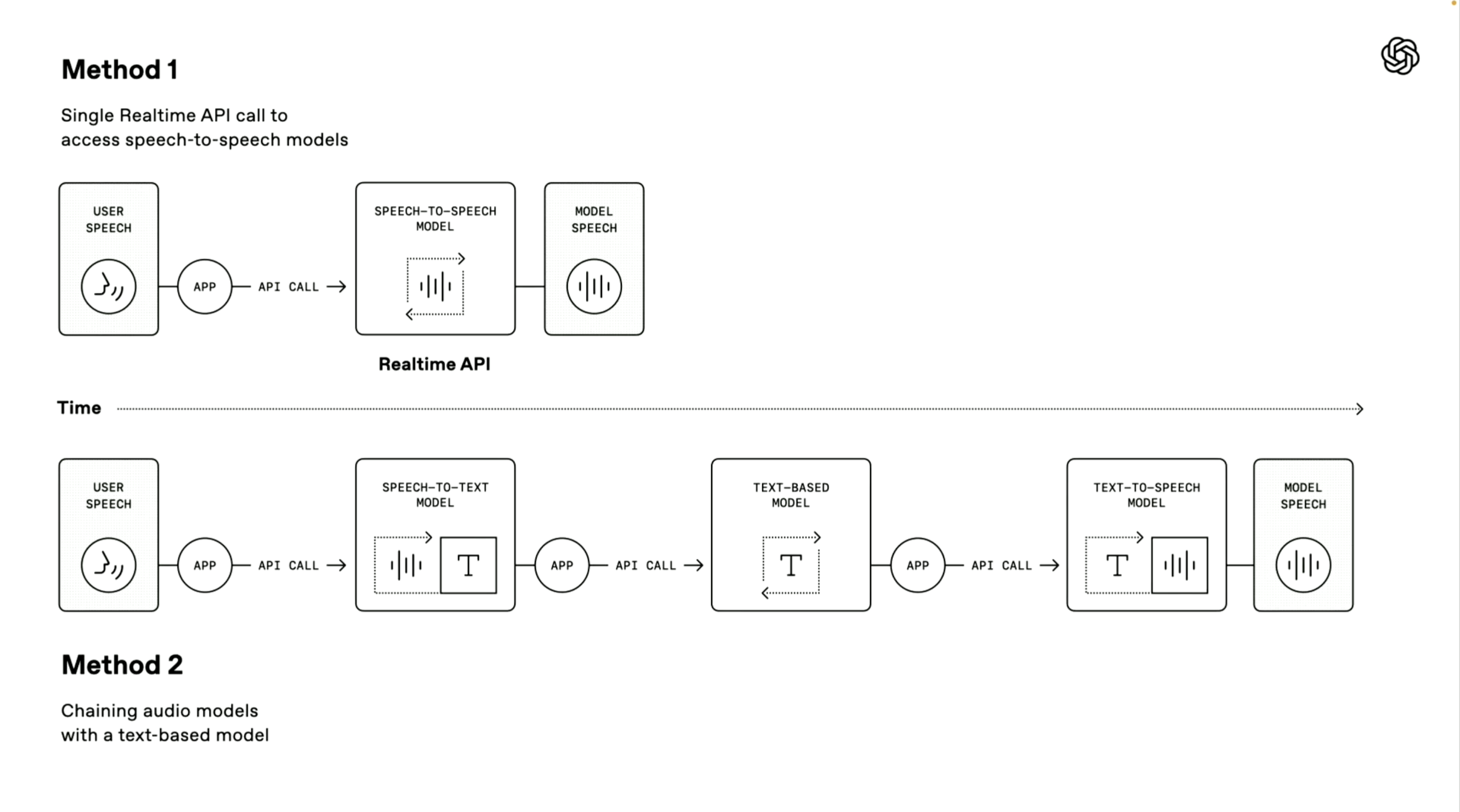
Erwähnenswert ist, dass der OpenAI-Demonstrator auch zwei technische Wege zum Aufbau eines Sprachagenten eingeführt hat. Das erste „Speech-to-Speech-Modell“ verwendet eine End-to-End-Direktverarbeitungsmethode.
Das System kann die Spracheingabe des Benutzers direkt empfangen und Sprachantworten ohne Zwischenkonvertierungsschritte generieren. Diese Methode hat eine schnellere Verarbeitungsgeschwindigkeit und wurde im erweiterten Sprachmodus und in den Echtzeit-API-Diensten angewendet. Sie eignet sich sehr gut für Szenarien, die eine extrem hohe Reaktionsgeschwindigkeit erfordern.
Die zweite „Kettenmethode“ steht im Mittelpunkt dieser Konferenz.
Es zerlegt den gesamten Verarbeitungsprozess in drei unabhängige Glieder: Zuerst wird ein Speech-to-Text-Modell verwendet, um die Sprache des Benutzers in Text umzuwandeln, dann verarbeitet ein Large Language Model (LLM) den Textinhalt und generiert Antworttext, und schließlich wird ein Text-to-Speech-Modell verwendet, um die Antwort in eine natürliche Sprachausgabe umzuwandeln.
Die Vorteile dieser Methode sind der modulare Aufbau, die Verarbeitungsergebnisse sind stabiler, da die Textverarbeitungstechnologie in der Regel ausgereifter ist als die direkte Audioverarbeitung und die Entwicklungsschwelle niedriger ist. Entwickler können Sprachfunktionen schnell auf der Grundlage vorhandener Textsysteme hinzufügen.
OpenAI bietet außerdem mehrere Verbesserungen für diese Sprachinteraktionssysteme:
- Unterstützt Sprachstreaming für kontinuierliche Audioeingabe und -ausgabe
- Die integrierte Geräuschunterdrückungsfunktion verbessert die Sprachverständlichkeit.
- Semantische Sprachaktivitätserkennung, die erkennen kann, wann ein Benutzer mit dem Sprechen fertig ist
- Stellen Sie Tracking-UI-Tools bereit, um Entwicklern das Debuggen von Sprachagenten zu erleichtern
Derzeit stehen diese neuen Audiomodelle Entwicklern weltweit zur Verfügung.
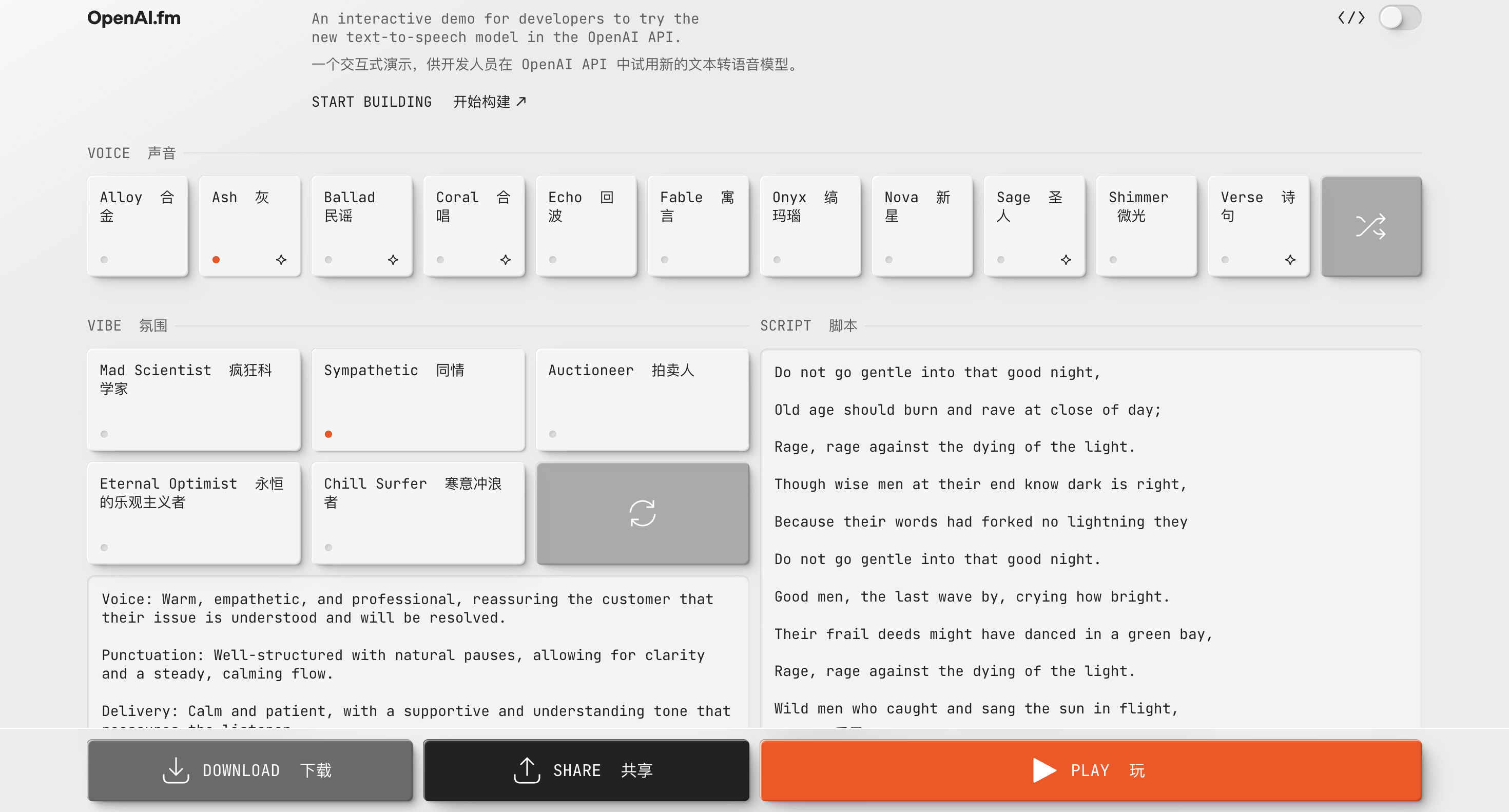
Sie können gpt-4o-mini-tts-bezogenes Audio auch auf http://OpenAI.fm erleben und erstellen. Die untere linke Ecke ist die offizielle voreingestellte Vorlage, die hauptsächlich Einstellungen wie Persönlichkeit, Ton, Dialekt und Aussprache enthält.
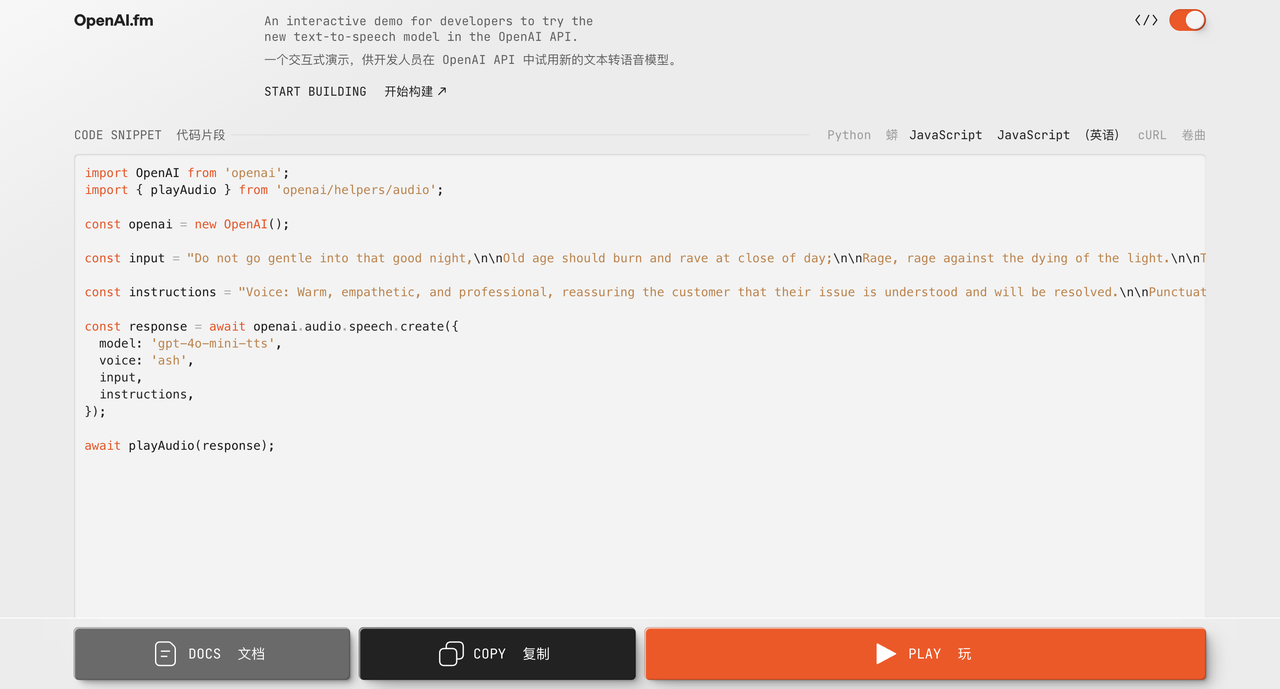
Wir haben auch einen Zungenbrecher getestet, bei dem ungefähr achthundert Schrittmacher den Nordhang hinaufliefen. Emmm, die chinesische Version war nur mittelmäßig. Was den englischen Effekt betrifft, so ähnelt das Hören beim Rezitieren von Gedichten einem echten Menschen, ist aber im Vergleich zu Hume AI oder Sesame immer noch nicht so gut wie „für das menschliche Ohr hörbar“.
Darüber hinaus hat OpenAI die Integration mit dem Agents SDK gestartet, um den Entwicklungsprozess weiter zu vereinfachen.
Erwähnenswert ist, dass OpenAI auch einen Broadcast-Wettbewerb veranstaltet hat. Benutzer können unter http://OpenAI.fm Audio erstellen, dann über die Schaltfläche „Teilen“ auf OpenAI.fm einen Link generieren und den Link dann auf der X-Plattform teilen.
Die drei kreativsten Teilnehmer erhalten jeweils eine limitierte Auflage des Teenage Engineering OB-4. Es wird empfohlen, die Audiodauer auf etwa 30 Sekunden zu beschränken, und Sie können in Bezug auf Stimme, Ausdruck, Aussprache oder Änderungen in der Intonation des Skripts Ihrer Kreativität freien Lauf lassen.

Tatsächlich ändert sich auch der Trend der KI in diesem Jahr stillschweigend. Zusätzlich zur Betonung des IQ gibt es auch einen zusätzlichen Trend zur Betonung von Emotionen.
Die Verkaufsargumente von GPT-4.5 und Grok 3 sind emotionale Intelligenz, kreativeres Schreiben und personalisiertere Antworten, während der kalte Roboter (Zhiyuan Robot) auch Wert darauf legt, anthropomorpher zu sein und sich auf einen emotionalen Wert konzentriert.
Da es die instinktivste Art der Kommunikation des Menschen direkt berührt, hat der Sprachbereich in diesem Bereich noch größere Anstrengungen unternommen.
Sesame AI, das in letzter Zeit im Silicon Valley populär geworden ist, kann Benutzeremotionen in Echtzeit erfassen und emotionale Reaktionen erzeugen, wodurch es schnell die Herzen einer großen Anzahl von Benutzern erobert. Auch Turing-Award-Gewinner Yann Lecun betonte kürzlich, dass zukünftige KI Emotionen haben müsse.
Ganz gleich, ob es sich um das heute von OpenAI veröffentlichte neue Sprachmodell oder um das demnächst erscheinende Meta Llama 4 handelt, beide nähern sich bewusst dem Dialog mit nativer Stimme an, versuchen durch natürlichere emotionale Interaktionen näher an die Benutzer heranzukommen und setzen auf „menschliche Berührung“, um Fans anzulocken.
Muss KI menschlich sein? Für eine lange Zeit. Chatbots werden oft als emotionslose Werkzeuge definiert und erinnern Sie während des Gesprächs auch daran, dass es sich um ein seelenloses Modell handelt. Allerdings können wir oft den emotionalen Wert daraus interpretieren und sogar unbewusst emotionale Verbindungen damit herstellen.
Vielleicht haben Menschen einen angeborenen Wunsch, verstanden und begleitet zu werden, auch wenn dieses Verständnis von einer Maschine kommt.
# Willkommen beim offiziellen öffentlichen WeChat-Konto von Aifaner: Aifaner (WeChat-ID: ifanr) wird Ihnen so schnell wie möglich zur Verfügung gestellt.
Ai Faner |. Ursprünglicher Link · Kommentare anzeigen · Sina Weibo