
Datenbankindex: Eine Einführung für Anfänger
"Datenbankindex" bezieht sich auf eine spezielle Art von Datenstruktur, die das Abrufen von Datensätzen aus einer Datenbanktabelle beschleunigt. Datenbankindizes stellen sicher, dass Sie die Daten in einer Datenbanktabelle effizient finden und darauf zugreifen können, ohne bei jeder Verarbeitung einer Datenbankabfrage jede Zeile durchsuchen zu müssen.
Ein Datenbankindex kann mit dem Index eines Buches verglichen werden. Indizes in Datenbanken verweisen Sie auf den gesuchten Datensatz in der Datenbank, genau wie die Indexseite eines Buches Sie auf Ihr gewünschtes Thema oder Kapitel verweist.
Obwohl Datenbankindizes für die schnelle und effiziente Datensuche und den Zugriff unerlässlich sind, belegen sie jedoch zusätzliche Schreibvorgänge und Speicherplatz.
Was ist ein Index?
Datenbankindizes sind spezielle Nachschlagetabellen, die aus zwei Spalten bestehen. Die erste Spalte ist der Suchschlüssel und die zweite der Datenzeiger. Die Schlüssel sind die Werte, die Sie suchen und aus Ihrer Datenbanktabelle abrufen möchten, und der Zeiger oder die Referenz speichert die Plattenblockadresse in der Datenbank für diesen bestimmten Suchschlüssel. Die Schlüsselfelder sind so sortiert, dass der Datenabrufvorgang für alle Ihre Abfragen beschleunigt wird.
Warum Datenbankindizierung verwenden?
Ich zeige Ihnen hier vereinfacht Datenbankindizes. Nehmen wir an, Sie haben eine Datenbanktabelle der acht Mitarbeiter eines Unternehmens und möchten die Informationen nach dem letzten Eintrag der Tabelle durchsuchen. Um den vorherigen Eintrag zu finden, müssen Sie nun jede Zeile der Datenbank durchsuchen.
Angenommen, Sie haben die Tabelle alphabetisch nach dem Vornamen der Mitarbeiter sortiert. Hier basieren also Indizierungsschlüssel auf der „Namensspalte“. Wenn Sie in diesem Fall den letzten Eintrag „ Zack “ suchen, können Sie in die Mitte der Tabelle springen und entscheiden, ob unser Eintrag vor oder nach der Spalte steht.
Wie Sie wissen, kommt es nach der mittleren Reihe, und Sie können die Reihen nach der mittleren Reihe wieder in zwei Hälften teilen und einen ähnlichen Vergleich anstellen. Auf diese Weise müssen Sie nicht jede Zeile durchlaufen, um den letzten Eintrag zu finden.
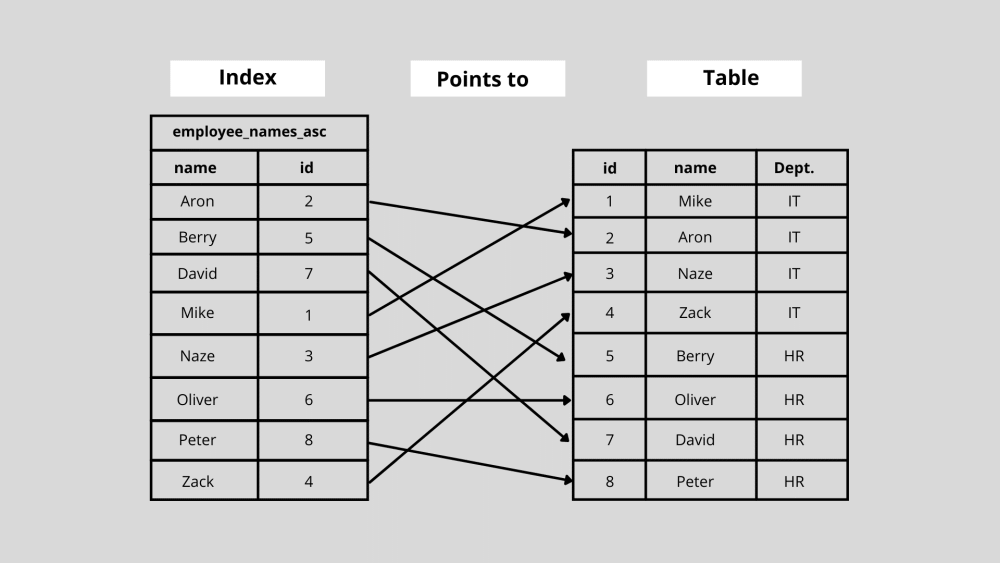
Wenn das Unternehmen 1.000.000 Mitarbeiter hatte und der letzte Eintrag „Zack“ war, müssten Sie 50.000 Zeilen durchsuchen, um seinen Namen zu finden. Bei der alphabetischen Indexierung hingegen können Sie dies in wenigen Schritten tun. Sie können sich jetzt vorstellen, wie viel schneller die Suche und der Zugriff auf Daten mit der Datenbankindexierung werden können.
Unterschiedliche Dateiorganisationsmethoden für Datenbankindizes
Die Indizierung hängt stark vom verwendeten Dateiorganisationsmechanismus ab. Normalerweise gibt es zwei Arten von Dateiorganisationsmethoden, die bei der Datenbankindizierung zum Speichern von Daten verwendet werden. Sie werden im Folgenden diskutiert:
1. Geordnete Indexdatei : Dies ist die traditionelle Methode zum Speichern von Indexdaten. Bei dieser Methode werden die Schlüsselwerte in einer bestimmten Reihenfolge sortiert. Daten in einer geordneten Indexdatei können auf zwei Arten gespeichert werden.
- Sparse Index: Bei dieser Art der Indexierung wird für jeden Datensatz ein Indexeintrag erstellt.
- Dense Index: Bei der Dense Indexing wird für einige Datensätze ein Indexeintrag erstellt. Um bei dieser Methode einen Datensatz zu finden, müssen Sie zunächst den wichtigsten Suchschlüsselwert aus Indexeinträgen ermitteln, die kleiner oder gleich dem gesuchten Suchschlüsselwert sind.
2. Hash-Dateiorganisation: Bei dieser Dateiorganisationsmethode bestimmt eine Hash-Funktion den Ort oder den Plattenblock, an dem ein Datensatz gespeichert wird.
Arten der Datenbankindizierung
Es gibt im Allgemeinen drei Methoden der Datenbankindizierung. Sie sind:
- Clustered-Indizierung
- Nicht gruppierte Indizierung
- Mehrstufige Indizierung
1. Clustered-Indizierung
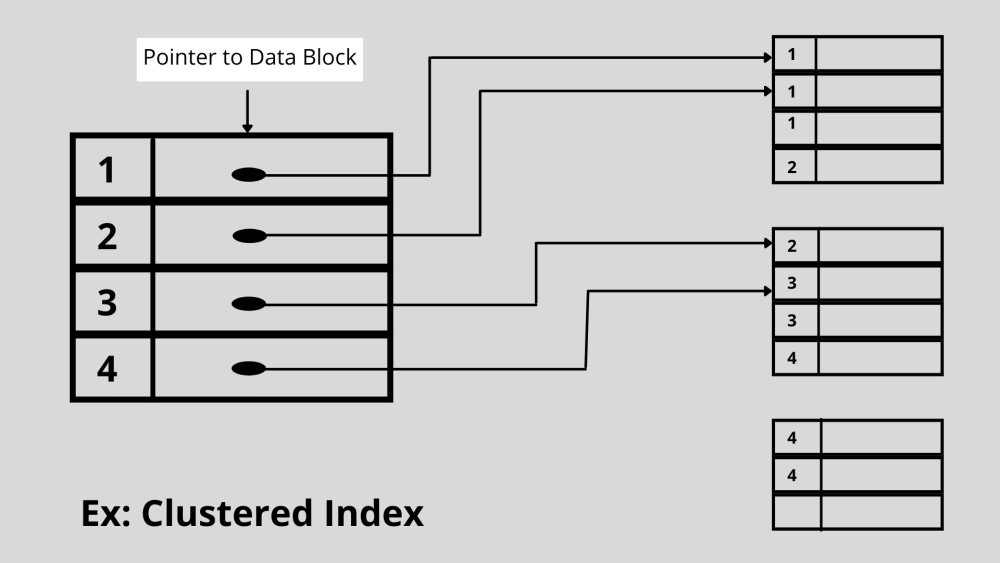
Bei der Clustered-Indizierung kann eine einzelne Datei mehr als zwei Datensätze speichern. Das System behält die tatsächlichen Daten in der Clustered-Indizierung statt der Zeiger. Die Suche mit Clustered Indexing ist kosteneffizient, da alle zugehörigen Daten am selben Ort gespeichert werden.
Ein Clustering-Index verwendet geordnete Datendateien, um sich selbst zu definieren. Auch das Zusammenführen mehrerer Datenbanktabellen ist bei dieser Art der Indizierung sehr üblich.
Es ist auch möglich, einen Index basierend auf nicht primären Spalten zu erstellen, die nicht für jeden Schlüssel eindeutig sind. In solchen Fällen werden mehrere Spalten kombiniert, um die eindeutigen Schlüsselwerte für Clustered-Indizes zu bilden.
Kurz gesagt, Clustering-Indizes sind der Ort, an dem ähnliche Datentypen gruppiert und Indizes für sie erstellt werden.
Beispiel: Angenommen, es gibt ein Unternehmen mit über 1.000 Mitarbeitern in 10 verschiedenen Abteilungen. In diesem Fall sollte das Unternehmen in seinem DBMS eine Clustering-Indizierung erstellen, um die Mitarbeiter zu indizieren, die in derselben Abteilung arbeiten.
Jeder Cluster mit Mitarbeitern, die in derselben Abteilung arbeiten, wird als einzelner Cluster definiert, und Datenzeiger in Indizes beziehen sich auf den Cluster als ganze Einheit.
2. Nicht gruppierte Indizierung
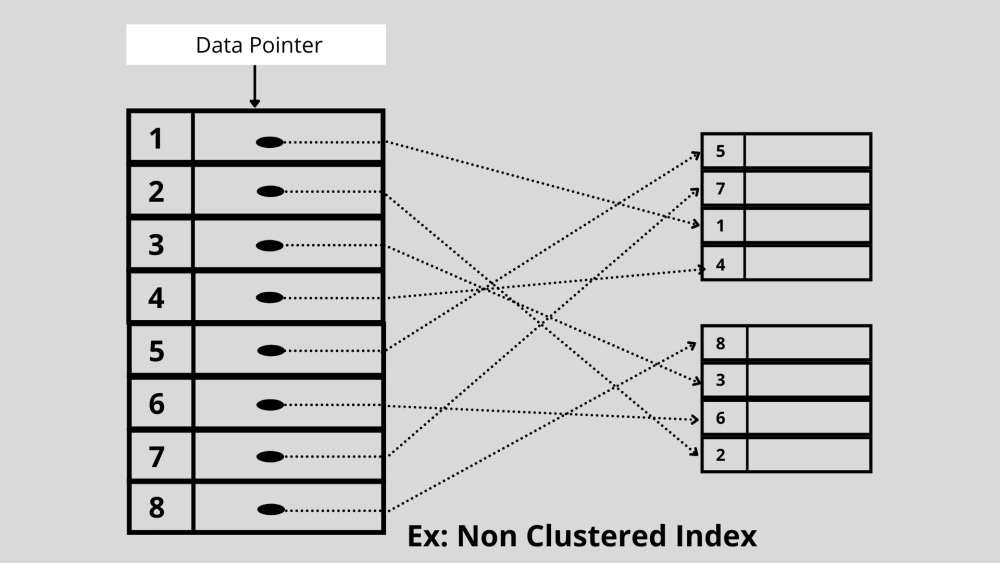
Nicht gruppierte Indizierung bezieht sich auf eine Art der Indizierung, bei der die Reihenfolge der Indexzeilen nicht mit der physischen Speicherung der Originaldaten übereinstimmt. Stattdessen verweist ein nicht gruppierter Index auf den Datenspeicher in der Datenbank.
Beispiel: Die Indexierung ohne Cluster ähnelt einem Buch mit einer geordneten Inhaltsseite. Hier ist der Datenzeiger oder die Referenz die geordnete Inhaltsseite, die alphabetisch sortiert ist, und die eigentlichen Daten sind die Informationen auf den Buchseiten. Die Inhaltsseite speichert die Informationen auf den Buchseiten nicht in ihrer Reihenfolge.
3. Mehrstufige Indizierung
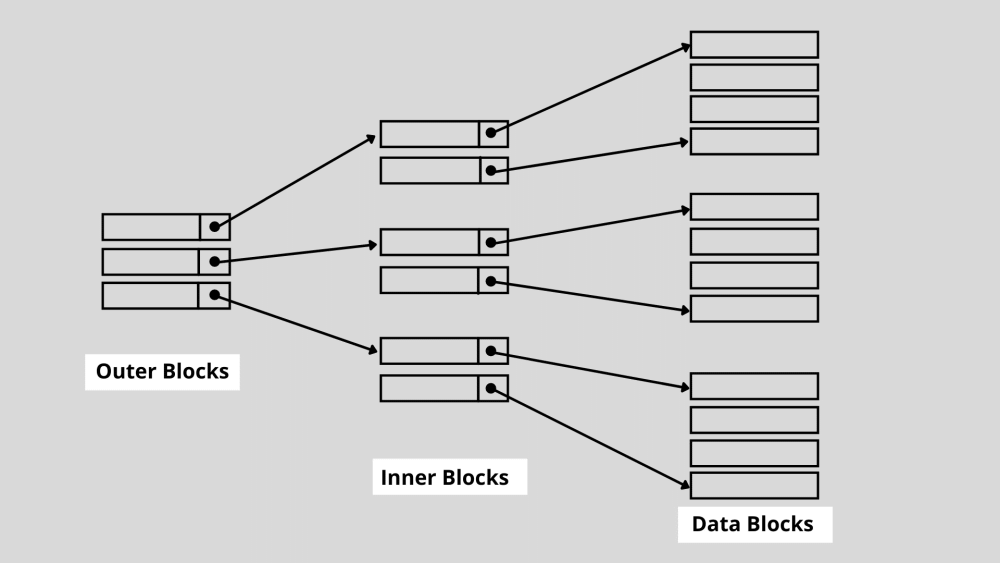
Die mehrstufige Indizierung wird verwendet, wenn die Anzahl der Indizes sehr hoch ist und der Primärindex nicht im Hauptspeicher gespeichert werden kann. Wie Sie vielleicht wissen, bestehen Datenbankindizes aus Suchschlüsseln und Datenzeigern. Mit zunehmender Datenbankgröße wächst auch die Anzahl der Indizes.
Um jedoch einen schnellen Suchvorgang zu gewährleisten, müssen Indexdatensätze im Speicher gehalten werden. Wenn ein einstufiger Index verwendet wird, wenn die Indexnummer hoch ist, ist es aufgrund seiner Größe und der Mehrfachzugriffe unwahrscheinlich, dass dieser Index im Arbeitsspeicher gespeichert wird.
Hier kommt die mehrstufige Indizierung ins Spiel. Diese Technik teilt den einstufigen Index in mehrere kleinere Blöcke auf. Nach dem Aufbrechen wird der Block der äußeren Ebene so winzig, dass er leicht im Hauptspeicher abgelegt werden kann.
Was ist SQL-Indexfragmentierung?
Wenn eine Reihenfolge der Indexseiten nicht mit der physischen Reihenfolge in der Datendatei übereinstimmt, führt dies zu einer SQL-Indexfragmentierung. Anfänglich befinden sich alle SQL-Indizes ohne Fragmentierung, aber wenn Sie die Datenbank wiederholt verwenden (Daten einfügen/löschen/ändern), kann dies zu Fragmentierungen führen.
Abgesehen von der Datenbankfragmentierung kann Ihre Datenbank auch mit anderen wichtigen Problemen wie Datenbankbeschädigung konfrontiert sein. Dies kann zu Datenverlust und einer beschädigten Website führen. Wenn Sie mit Ihrer Website Geschäfte machen, kann dies ein fataler Schlag für Sie sein.