
Ein Gespräch mit dem Team von Ideal Assisted Driving: Wie sich das assistierte Fahren vom „Affen“ zum „Menschen“ entwickelte

Etwa um diese Zeit im letzten Jahr diskutierten iFanr und Dongchehui mit dem Team von Ideal Assisted Driving im Ideal Beijing R&D Center. Damals stand die neue Technologiearchitektur von Ideal Assisted Driving, „End-to-End + VLM Visual Language Model“, kurz vor der Implementierung in Fahrzeugen. Die damalige Stellungnahme des Teams von Ideal Assisted Driving lautete:
Der theoretische Rahmen hinter dem „End-to-End + VLM Visual Language Model“ ist die „ultimative Antwort“ auf autonomes Fahren.
Mit der Umstellung der technischen Architektur „End-to-End + VLM Visual Language Model“ auf VLA (Vision-Language-Action, Visual Language Action Model) sind wir der „ultimativen Antwort“ einen Schritt näher gekommen.
Laut Li Xiang und dem Ideal-Fahrassistenzteam ist dies ein wichtiger Schritt in der Weiterentwicklung der Fahrassistenzfunktionen von Ideal vom „Affen“-Stadium zum „Menschen“-Stadium. Gleichzeitig besuchten wir heute das Forschungs- und Entwicklungszentrum von Ideal in Peking, um mit dem Ideal-Fahrassistenzteam weiterhin über neue Trends in diesem Bereich zu diskutieren.

▲ Lang Xianpeng, Senior Vice President für Forschung und Entwicklung im Bereich autonomes Fahren bei Ideal Auto
Was ist beim assistierten Fahren der Unterschied zwischen Affen und Menschen?
Bevor Ideals Fahrassistenzlösung im vergangenen Jahr auf das „End-to-End + VLM Visual Language Model“ umgestellt wurde, wurde die branchenübliche technische Architektur „Wahrnehmung – Planung – Steuerung“ übernommen. Bei dieser Architektur schreiben Ingenieure entsprechende Regeln, um die Fahrzeugsteuerung auf der Grundlage verschiedener realer Verkehrsbedingungen zu steuern. Es ist jedoch schwierig, alle realen Verkehrsbedingungen abzudecken.

Dies ist das „mechanische Zeitalter“ des assistierten Fahrens. Das assistierte Fahren kann nur mit Situationen mit entsprechenden Regeln umgehen und verfügt nicht über die Fähigkeit zu denken und zu lernen.
Das „End-to-End + VLM-Visual-Language-Modell“ ist die „Affen-Ära“ des assistierten Fahrens. Im Vergleich zu Maschinen sind Affen intelligenter und verfügen über eine gewisse Fähigkeit zur Nachahmung und zum Lernen. Natürlich sind Affen auch aktiver und ungehorsamer.
Das Wesentliche des visuellen Sprachmodells „End-to-End + VLM“ ist „Imitationslernen“, das für das Training auf umfangreichen Daten menschlicher Fahrerfahrungen basiert. Quantität und Qualität dieser Daten bestimmen die Leistung. Aus Sicherheitsgründen ist das visuelle Sprachmodell VLM, das für komplexe Szenarien zuständig ist, in dieser Architektur nicht an der Fahrzeugsteuerung beteiligt; es übernimmt lediglich die Entscheidungsfindung und die Trajektorienführung.

VLA (Vision-Language-Action) ist das „menschliche Zeitalter“ des assistierten Fahrens, das die Fähigkeit besitzt, „zu denken, zu kommunizieren, sich zu erinnern und sich selbst zu verbessern“.
Affen haben eine lange Transformation durchlaufen, um Menschen zu werden. Theoretisch kann das „Imitationslernen“ des „End-to-End + VLM-Visual-Language-Modells“ auch über einen langen Zeitraum fast alle menschlichen Fahrdaten lernen und sich fast wie ein Mensch verhalten.
Der Preis ist jedoch „Zeit“.
Lang Xianpeng, Senior Vice President für Forschung und Entwicklung im autonomen Fahren bei Ideal Auto, sagte:
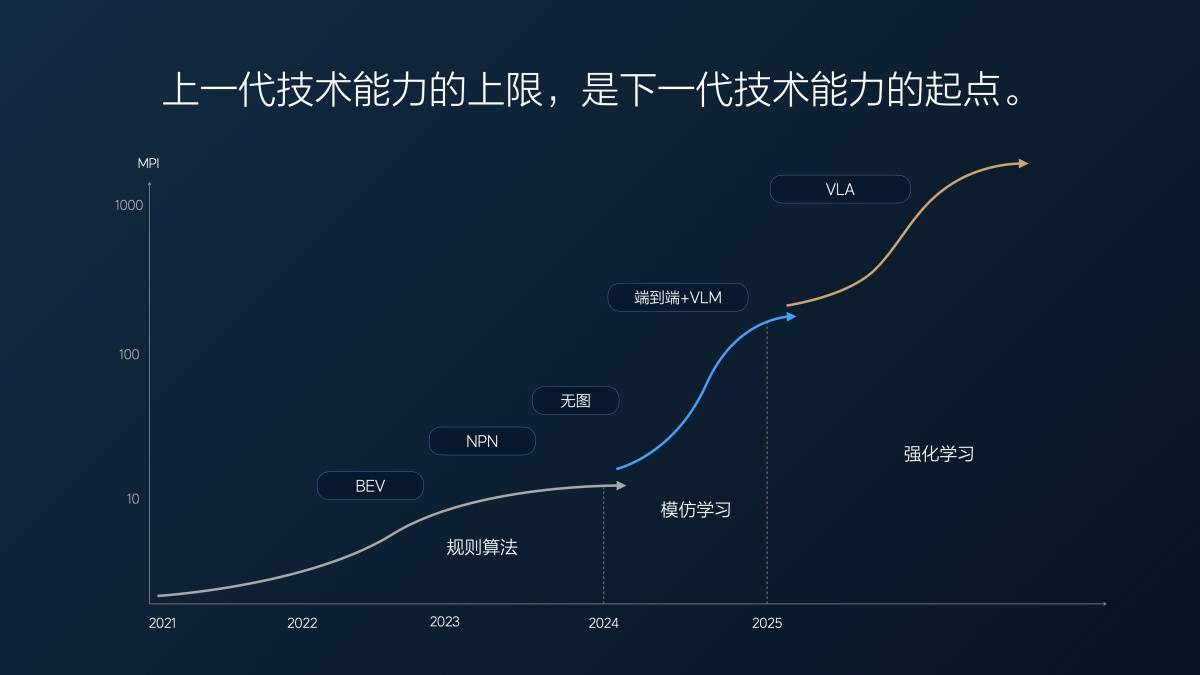
Unser tatsächlicher End-to-End-MPI (durchschnittliche Übernahmekilometerzahl) betrug letztes Jahr in der ersten Version im Juli letzten Jahres etwa zehn Kilometer. Wir dachten damals, das sei ziemlich gut, weil unsere kartenfreie Version schon lange iteriert wurde und der umfassende MPI (Autobahn + Stadt) nur etwa 10 Kilometer betrug.
Von 1 Million auf 2 Millionen Clips (Videoclips zum Trainieren des durchgängig assistierten Fahrens) und dann mit zunehmender Datenmenge auf 10 Millionen Clips, erreichte der MPI Anfang dieses Jahres 100 Kilometer. In 7 Monaten hat sich der MPI verzehnfacht, durchschnittlich mehrmals im Monat.
Doch nachdem wir 10 Millionen Clips erreicht hatten, stellten wir ein Problem fest: Die Datenmenge einfach zu erhöhen, war nutzlos; die Menge an wertvollen Daten schwand. Es ist wie bei einer Prüfung: Wenn man durchfällt, kann man seine Punktzahl durch einen zufälligen Credit schnell verbessern. Aber wenn man nur noch 80 oder 90 Punkte hat, ist es sehr schwierig, sich auch nur um 5 oder 10 Punkte zu verbessern.
An diesem Punkt nutzten wir die Super-Alignment-Methode, um das Modell zu zwingen, Ergebnisse zu produzieren, die den menschlichen Erwartungen entsprachen. Wir wählten außerdem einige Daten aus und ergänzten sie mit der Super-Alignment-Methode, um die Fähigkeiten des Modells weiter zu verbessern. Dieser Ansatz zeigte eine gewisse Wirkung, doch es dauerte etwa fünf Monate, von März bis Ende Juli dieses Jahres, bis wir eine etwa zweifache Verbesserung der Modellleistung erreichten.
Dies ist das erste Problem, auf das die technische Architektur „End-to-End + VLM-Visual-Language-Model“ nach ihrer rasanten Weiterentwicklung stößt: Je mehr Zeit vergeht, desto knapper werden die nützlichen Daten und desto langsamer verbessert sich die Modellleistung.

Auch das grundlegende Problem wurde offengelegt. Lang Xianpeng sagte:
Im Wesentlichen fehlt es dem aktuellen End-to-End-Imitationslernen an tiefgreifenden logischen Denkfähigkeiten. Es ist wie ein Affe, der Auto fährt. Füttere ihn mit Bananen, und er verhält sich vielleicht wie beabsichtigt, weiß aber nicht warum. Er kommt vielleicht zu dir, wenn ein Gong geschlagen wird, oder tanzt, wenn eine Trommel gespielt wird, aber er weiß nicht warum.
Daher ist die End-to-End-Architektur nicht in der Lage, tiefgreifend zu denken. Sie ist höchstens eine Stressreaktion. Das heißt, bei einer Eingabe gibt das Modell eine Ausgabe aus. Es steckt keine tiefe Logik dahinter.
Aus diesem Grund ergänzen wir das umfassende Modell um ein Visual Language Model (VLM). Das VLM verfügt über bessere Verständnis- und Denkfähigkeiten und ermöglicht so eine bessere Entscheidungsfindung. Allerdings ist dieses Modell langsam im Denken und nicht eng mit dem umfassenden Modell verknüpft. Folglich kann das umfassende Modell die Entscheidungen des VLM oft nicht verstehen oder akzeptieren.
Letztes Jahr um diese Zeit sagte das Ideal Assisted Driving Team:
Es gibt zwei zukünftige Trends. Erstens wird der Maßstab der Modelle zunehmen. System 1 und System 2 sind derzeit zwei End-to-End-Modelle mit einem VLM. Diese beiden Modelle könnten zusammengeführt werden. Derzeit sind sie lose gekoppelt, könnten aber in Zukunft enger miteinander verbunden werden. Zweitens können wir auch vom aktuellen Trend zu großen multimodalen Modellen lernen. Diese Modelle entwickeln sich in Richtung nativer Multimodalität und können Sprache, Sprechen, Sehen und Lidar verarbeiten. Dies ist ein Aspekt, den wir in Zukunft berücksichtigen werden.
Der Trend wurde schnell Realität.
Lang Xianpeng erläuterte auch die Gründe für den Wechsel von End-to-End + VLM zu VLA:
Als wir letztes Jahr an End-to-End arbeiteten, dachten wir ständig darüber nach, ob End-to-End ausreichte und wenn nicht, was wir sonst noch tun mussten.
Wir haben einige Vorstudien zu VLA durchgeführt. Diese Vorstudien spiegeln unser Verständnis wider, dass künstliche Intelligenz kein Imitationslernen ist. Sie muss über die gleichen Denk- und Argumentationsfähigkeiten wie der Mensch verfügen. Mit anderen Worten: Sie muss in der Lage sein, Dinge oder unbekannte Szenarien zu lösen, die sie noch nie zuvor gesehen hat. Dies mag zwar eine gewisse Generalisierungsfähigkeit im End-to-End-Bereich besitzen, reicht aber nicht aus, um von Denkvermögen zu sprechen.
Wie ein Affe kann es Dinge tun, die jenseits Ihrer Vorstellungskraft liegen, aber es wird nicht immer so sein. Menschen sind jedoch anders. Menschen können wachsen und iterieren, daher müssen wir unsere künstliche Intelligenz im Einklang mit der Entwicklung der menschlichen Intelligenz entwickeln. Wir sind schnell von der End-to-End-Lösung zur VLA-Lösung gewechselt.
VLA (Vision-Language-Action) ist der Denktrend des letzten Jahres und die technische Architektur, die heute Realität geworden ist.
Obwohl sich VLA und VLM nur durch einen Buchstaben unterscheiden, sind ihre Konnotationen sehr unterschiedlich.
Unter Vision versteht man bei VLA die Eingabe verschiedener Sensorinformationen, darunter Navigationsinformationen, die es dem Modell ermöglichen, den Raum zu verstehen und wahrzunehmen.
Die Sprache von VLA bezieht sich auf die Fähigkeit des Modells, das wahrgenommene räumliche Verständnis zusammenzufassen, zu übersetzen, zu komprimieren und in einen Sprachausdruck zu kodieren, genau wie ein Mensch.
Die Aktion von VLA besteht darin, dass das Modell basierend auf der Codierungssprache der Szene eine Verhaltensstrategie zum Fahren des Autos generiert.
Der intuitivste Unterschied besteht darin, dass Menschen das Auto mit Sprache steuern können. Sie können das Auto durch Sprechen verlangsamen oder beschleunigen, nach links oder rechts abbiegen lassen. Dies ist hauptsächlich auf den Sprachanteil zurückzuführen. Die vom großen Modell menschlicher Befehle empfangenen Eingabeaufforderungen sind auch Eingabeaufforderungen innerhalb des VLA-Modells, was der Verbindung von Mensch und Auto entspricht.
Darüber hinaus gibt es keine Barriere zwischen Sehen und Verhalten. Die Geschwindigkeit und Effizienz von der visuellen Informationseingabe bis zur Ausgabe des Fahrzeugsteuerungsverhaltens werden erheblich beschleunigt und die Probleme des langsamen VLM und des durchgängigen Mangels an VLM-Verständnis werden gelöst.
Ein wesentlicherer Unterschied ist die Chain of Thought (CoT)-Fähigkeit. Das VLA-Modell hat eine Inferenzfrequenz von 10 Hz und ist damit mehr als dreimal schneller als das VLM-Modell. Es verfügt außerdem über eine umfassendere Wahrnehmung und ein besseres Verständnis der Umgebung, was schnelleres und rationaleres Denken und die Generierung von Fahrentscheidungen ermöglicht.
Neben Denk- und Kommunikationsfähigkeiten verfügt VLA auch über ein gewisses Gedächtnis, das sich an die Vorlieben und Gewohnheiten des Besitzers erinnern kann, sowie über eine ziemlich starke autonome Lernfähigkeit.

▲ Ideal i8 ist das erste Modell, das die Ideal VLA-Technologie nutzt
Ideales assistiertes Fahren „Flying Life“
Wenn Menschen in der realen Welt erfahrene Fahrer werden wollen, müssen sie sich zunächst bei einer Fahrschule anmelden und einen Führerschein machen, dann einen „Praktikumsaufkleber“ anbringen und losfahren und ein paar Jahre lang auf echten Straßen fahren.
Gleiches gilt für die bisherige Ausbildung zum assistierten Fahren, die nicht nur reale Fahrdaten zur Ausbildung benötigt, sondern auch eine große Anzahl von Fahrversuchen in der realen Welt erfordert.
In einigen Romanen können talentierte Kandidaten durch Lesen zu Meistern der Kampfkunst mit extrem hohem Können werden, wie etwa der „konfuzianische Schwert-Unsterbliche“ Xie Xuan in „Das Lied der Jugend“ und Xuanyuan Jingcheng in „Der Schwertkämpfer im Schnee“.
In traditionellen Kampfkunstromanen gibt es jedoch nur Charaktere wie Wang Yuyan in „Die Halbgötter und Halbteufel“, die zwar die klassischen Kampfkünste beherrschen, aber keine wirklichen Kampffähigkeiten besitzen.

▲ Standbilder aus „Speeding Life“
Natürlich gibt es auch Zwischensituationen: Im Rennfilm „Speeding Life“ reproduzierte der heruntergekommene Rennfahrer Zhang Chi ständig die komplexen Streckenbedingungen im Gebiet Bayinbuluke in Gedanken, fuhr in Gedanken 20 Mal am Tag, simulierte das Fahren in 5 Jahren mehr als 36.000 Mal und wurde dann, als er auf die echte Strecke zurückkehrte, der Champion.
Virtuell fahren, sich ständig verbessern und die besten Ergebnisse der Vergangenheit übertreffen, das ist der „Algorithmus“.
Bevor Zhang Chi jedoch auf die Strecke zurückkehrte und erneut Champion wurde, hatte er sich auf dieser Strecke bereits viele Male bewiesen und viel praktische Fahrerfahrung gesammelt.
Echtes Auto und echte Straße, das Sammeln von Erfahrung, bis Sie alle Straßenbedingungen dieser Strecke verstehen, das sind „Daten“.

Lang Xianpeng sagte, dass zur Entwicklung eines guten VLA-Modells Fähigkeiten auf vier Ebenen erforderlich seien: Daten, Algorithmen, Rechenleistung und technische Fähigkeiten.
Ideal legt seit langem Wert auf seine Datenfülle, seine exzellenten Daten, seine gute Datenbank sowie seine präzise Datenkennzeichnung und sein Data Mining. Im Bereich Daten verfügt Ideal zudem über eine neue Kompetenz: die Generierung von Datentraining.

Das Weltmodell wird zur Rekonstruktion der Szene verwendet. Anschließend werden ähnliche Szenen basierend auf den rekonstruierten realen Daten generiert. Beispielsweise ist es ideal, eine Hochgeschwindigkeits-ETC-Szene im Weltmodell zu rekonstruieren. In diesem Szenario können nicht nur die ursprünglichen realen Datenbedingungen verwendet werden, wie z. B. sonniger und trockener Boden tagsüber, sondern auch Szenen wie starker Schneefall tagsüber mit rutschigem Boden und leichter Regen nachts mit schlechter Sicht generiert werden.
Der ideale Trainingsalgorithmus für VLA-Modelle hängt auch eng mit den generierten Daten zusammen. Lang Xianpeng erklärte:
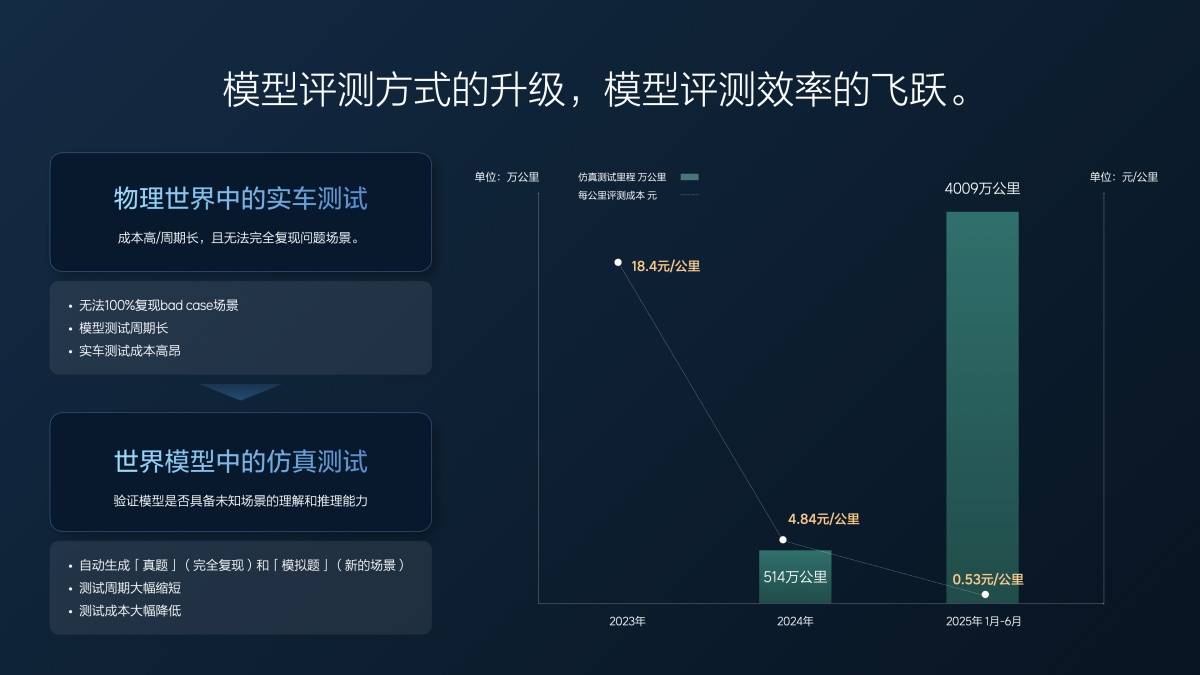
Wir haben im Jahr 2023 noch keine End-to-End-Entwicklung erreicht. Die effektive Testkilometerleistung realer Fahrzeuge pro Jahr beträgt ungefähr 1,57 Millionen Kilometer und die Kosten pro Kilometer betragen 18 Yuan.
Als wir mit der Arbeit an End-to-End-Systemen begannen, hatten wir einen Teil unserer Arbeit bereits in Simulationstests erledigt. Im Jahr 2024 legten wir in Simulationstests rund fünf Millionen Kilometer und in Tests mit realen Fahrzeugen über eine Million Kilometer zurück. Die durchschnittlichen Kosten sanken auf weniger als fünf Yuan pro Kilometer, der immer noch rund 30 Millionen Yuan kostete. Mit denselben 30 Millionen Yuan konnten wir jedoch sechs Millionen Kilometer testen.
In den ersten sechs Monaten dieses Jahres (1. Januar bis 30. Juni) haben wir 40 Millionen Testkilometer absolviert, davon nur 20.000 Kilometer mit realen Fahrzeugen, die grundlegende Szenarien abdecken. Alle unsere Tests, einschließlich der Super Alignment- und aktuellen VLA-Funktionen, die Sie bereits gesehen haben, werden mithilfe von Simulationen durchgeführt. Die Kosten betragen 0,5 Cent pro Kilometer und decken damit kaum die Strom- und Serverkosten. Darüber hinaus ist die Testqualität hoch, da alle Fälle und Szenarien vollständig und präzise repliziert werden, was präzise Ergebnisse gewährleistet. Unsere erhöhte Testkilometerzahl und die verbesserte Testqualität haben die Effizienz in Forschung und Entwicklung gesteigert.
Viele Leute haben bezweifelt, dass wir in einem halben Jahr ein VLA bauen könnten und dass wir es nicht einmal vollständig testen könnten. Tatsächlich haben wir eine Menge Tests durchgeführt.
Neben den geringen Kosten liegt der Vorteil von Simulationstests in der perfekten Reproduktion der Szene. Bei realen Tests ist es schwierig, eine Szene hundertprozentig wiederherzustellen. Beim VLA-Modell kann selbst der kleinste Unterschied in der Szenenwiedergabe zu einem enormen Unterschied in der Fahrleistung führen.

In diesem Sinne ähnelt die ideale Trainingsform des VLA-Modells in gewisser Weise dem Modell im Film „Speeding Life“, in dem der Protagonist kontinuierlich ein virtuelles Training auf der Grundlage realer Fahrerfahrungen durchführt.
Natürlich erfordert auch das Training des VLA-Modells enorme Rechenleistung. Die aktuelle Gesamtrechenleistung von Ideal beträgt 13 EFLOPS, davon 3 EFLOPS für die Inferenz und 10 EFLOPS für das Training. Umgerechnet auf Grafikkarten entspricht dies 20.000 NVIDIA H20 GPUs für das Training und 30.000 NVIDIA L20 GPUs für die Inferenz.

Wichtige Fragen und Antworten
F: Intelligentes, assistiertes Fahren stellt ein „unlösbares Dreieck“ dar – Effizienz, Komfort und Sicherheit –, die sich gegenseitig bedingen und derzeit möglicherweise nur schwer gleichzeitig erreicht werden können. Welche Kennzahl priorisiert Ideal Auto derzeit für VLA? Sie haben gerade den MPI erwähnt. Können wir davon ausgehen, dass Ideal Auto letztendlich die Verbesserung der Sicherheit anstrebt, um Übernahmen effektiv zu reduzieren?
Lang Xianpeng: MPI ist eine unserer Messgrößen. Eine andere ist MPA, die die Kilometerleistung vor einem Unfall angibt. Ideale Autobesitzer erleiden etwa alle 600.000 Kilometer einen Unfall, wenn sie selbst fahren, während Fahrer mit Fahrassistenzsystemen alle 3,5 bis 4 Millionen Kilometer einen Unfall erleiden. Wir werden diese Kilometerleistungsdaten weiter verbessern. Unser Ziel ist es, MPA auf das Zehnfache des menschlichen Fahrens zu erhöhen, d. h. zehnmal sicherer zu sein als selbstfahrende Autos, und eine Unfallrate von 6 Millionen Kilometern zu erreichen. Dies kann jedoch erst nach einer Verbesserung des VLA-Modells erreicht werden.
Wir haben auch den MPI analysiert. Während einige Sicherheitsrisiken zur Übernahme durch den Fahrer führen können, können auch andere Faktoren, wie z. B. mangelnder Komfort bei plötzlichem oder starkem Bremsen, zur Übernahme durch den Fahrer führen. Obwohl Sicherheitsrisiken nicht immer auftreten, zögern Nutzer möglicherweise dennoch, assistiertes Fahren zu nutzen, wenn der Fahrkomfort nicht optimal ist. Da MPA neben der Sicherheit auch die Sicherheit misst, haben wir uns beim MPI auf die Verbesserung des Fahrkomforts konzentriert. Erleben Sie die assistierten Fahrfunktionen des Ideal i8 und Sie werden eine deutliche Verbesserung des Komforts im Vergleich zu früheren Versionen feststellen.
Effizienz kommt erst nach Sicherheit und Komfort. Wenn wir beispielsweise die falsche Straße nehmen, kommt es zwar zu einem Effizienzverlust, wir können dies aber nicht sofort durch gefährliche Maßnahmen korrigieren. Wir müssen Effizienz auf der Grundlage von Sicherheit und Komfort anstreben.

F: Welche Schwierigkeiten bringt das VLA-Modell mit sich? Welche Anforderungen werden an Unternehmen gestellt? Welchen Herausforderungen muss ein Unternehmen bei der Implementierung des VLA-Modells begegnen?
Lang Xianpeng: Viele Leute haben gefragt, ob Automobilhersteller den vorherigen Regelalgorithmus und die End-to-End-Phase überspringen können, wenn sie ein VLA-Modell entwickeln wollen. Ich denke, das ist nicht möglich.
Obwohl sich die Daten, Algorithmen und andere Aspekte von VLA von früheren Modellen unterscheiden können, basieren sie dennoch auf bestehenden Grundlagen. Ohne einen vollständigen Kreislauf von Daten, die von realen Fahrzeugen erfasst werden, fehlen Daten zum Trainieren des Weltmodells. Ideal Auto konnte das VLA-Modell implementieren, da wir über 1,2 Milliarden Datenpunkte verfügen. Nur mit einem gründlichen Verständnis dieser Daten können wir bessere Daten generieren. Ohne diese Datengrundlage ist es erstens unmöglich, das Weltmodell zu trainieren, und zweitens ist unklar, welche Art von Daten generiert werden sollen.
Gleichzeitig erfordert die Unterstützung der Rechenleistung für die Grundausbildung und die Inferenzrechenleistung einen hohen finanziellen und technischen Aufwand, der ohne vorherige Ansammlung nicht erreicht werden kann.
F: Die tatsächliche Fahrzeugprüfung von Ideal beträgt in diesem Jahr 20.000 Kilometer. Was ist die Grundlage für eine deutliche Reduzierung der tatsächlichen Fahrzeugprüfung?
Lang Xianpeng: Wir sind davon überzeugt, dass Tests mit realen Fahrzeugen zahlreiche Herausforderungen mit sich bringen. Die Kosten sind ein Problem, aber das größte ist, dass es unmöglich ist, das genaue Szenario, in dem das Problem beim Testen bestimmter Szenarien aufgetreten ist, vollständig zu reproduzieren. Darüber hinaus sind Tests mit realen Fahrzeugen ineffizient, da die Fahrer das Fahrzeug fahren und es dann erneut testen müssen. Unsere aktuellen Simulationen können es mit Tests mit realen Fahrzeugen aufnehmen. Über 90 % der Tests der aktuellen Super Edition und der VLA-Version des Ideal i8 werden simuliert.
Wir nutzen Simulationstests seit letztem Jahr, um unsere End-to-End-Version zu verifizieren. Wir sind überzeugt, dass diese Tests äußerst zuverlässig und effektiv sind und haben daher die Tests an realen Fahrzeugen durch Simulationstests ersetzt. Während einige Tests, wie z. B. Hardware-Haltbarkeitstests, unersetzlich sind, verwenden wir Simulationstests im Allgemeinen für leistungsbezogene Tests und erzielen hervorragende Ergebnisse.
Mit dem Beginn des Industriezeitalters wurden Kahlschlagprozesse durch Mechanisierung ersetzt; mit dem Aufkommen des Informationszeitalters hat das Internet einen erheblichen Teil der Arbeit übernommen. Dasselbe gilt im Zeitalter des autonomen Fahrens. Mit dem Beginn des End-to-End-Zeitalters sind wir dazu übergegangen, KI für das autonome Fahren zu nutzen. Vom Einsatz einer großen Anzahl von Ingenieuren und Algorithmentestern bis hin zu einem datengesteuerten Ansatz verbessern wir die Fähigkeiten des autonomen Fahrens durch Datenprozesse, Datenplattformen und Algorithmus-Iteration. Im Zeitalter groß angelegter virtualisierter automatisierter Modelle (VLAs) ist die Testeffizienz der zentrale Faktor zur Verbesserung der Fähigkeiten. Um eine schnelle Iteration zu erreichen, müssen Faktoren, die eine schnelle Iteration behindern, eliminiert werden. Wenn weiterhin erhebliche Eingriffe an realen Fahrzeugen und manuelle Eingriffe erforderlich sind, verringert sich die Geschwindigkeit. Dabei geht es nicht unbedingt darum, Tests an realen Fahrzeugen zu ersetzen; vielmehr erfordern Technologie und Ansatz von Natur aus den Einsatz von Simulationstests. Ohne diese können wir kein bestärkendes Lernen praktizieren oder VLA-Modelle entwickeln.
F: VLA untergräbt nicht wirklich End-to-End + VLM. Kann man also davon ausgehen, dass VLA eine Innovation ist, die sich eher auf technische Fähigkeiten konzentriert?
Zhan Kun (Senior Algorithm Expert, Autonomes Fahren, Ideal Auto): VLA ist mehr als nur eine technische Innovation. Wenn Sie sich für verkörperte Intelligenz interessieren, werden Sie feststellen, dass dieser Trend durch die Anwendung großer Modelle auf die physische Welt vorangetrieben wird. Dies beinhaltet im Wesentlichen die Entwicklung eines VLA-Algorithmus. Unser VLA-Modell zielt darauf ab, die Ideen und Ansätze der verkörperten Intelligenz auf das Feld des autonomen Fahrens anzuwenden. Wir waren die Ersten, die es vorgeschlagen und in die Praxis umgesetzt haben. VLA ist auch End-to-End, da es im Wesentlichen auf Szeneneingabe und Trajektorienausgabe basiert, ein VLA-ähnliches Konzept. Die algorithmische Innovation erfordert jedoch zusätzliches Denken. End-to-End kann als VA ohne Sprache verstanden werden. Sprache entspricht Denken und Verstehen. Wir haben diese Komponente in VLA integriert, das Robotik-Paradigma vereinheitlicht und autonomes Fahren zu einer Kategorie der Robotik gemacht. Dies stellt algorithmische Innovation dar, nicht nur technische Innovation.
Eine große Herausforderung für autonomes Fahren sind technische Innovationen. VLA ist ein umfangreiches Modell, und seine Bereitstellung auf Edge-Rechenleistung ist äußerst anspruchsvoll. Viele Teams halten VLA nicht unbedingt für eine schlechte Idee, sondern halten die VLA-Bereitstellung für schwierig. Die praktische Umsetzung ist unglaublich anspruchsvoll, insbesondere wenn Edge-Chips nicht über die nötige Rechenleistung verfügen. Daher müssen wir es auf Hochleistungschips einsetzen. Dabei geht es nicht nur um technische Innovationen, sondern um eine umfassende Optimierung der technischen Bereitstellung, um erfolgreich zu sein.
F: Wird es bei der Bereitstellung großer VLA-Modelle im Fahrzeug zu einer Modellbeschneidung oder -destillation kommen? Wie können wir ein Gleichgewicht zwischen Inferenzeffizienz und Modellleistung erreichen?
Zhan Kun: Wir haben bei der Implementierung sorgfältig zwischen Effizienz und Destillation geachtet. Unser Basismodell ist ein proprietäres 8×0,4B MoE-Modell (Mixture of Experts), das in der Branche einzigartig ist. Nach eingehender Analyse der NVIDIA-Chips stellten wir fest, dass diese Architektur perfekt passt. Sie bietet schnelle Inferenzgeschwindigkeiten und große Modellkapazitäten und ermöglicht so die Aufnahme großer Modelle mit unterschiedlichen Szenarien und Fähigkeiten. Dies war unsere Architekturentscheidung.
Darüber hinaus haben wir ein großes Modell destilliert. Zunächst trainierten wir ein 32-Milliarden-Cloud-basiertes Modell, das über umfangreiches Wissen und Fahrfähigkeiten verfügt. Wir destillierten dessen Denk- und Argumentationsprozesse in ein 3,2-Milliarden-MoE-Modell und nutzten die Diffusionstechnologie in Verbindung mit Vision and Action (ein Diffusionsmodell, das Bilder, Videos, Audio, Bewegungstrajektorien und andere Daten generieren kann. Im idealen VLA-Szenario wird Diffusion insbesondere zur Generierung von Fahrtrajektorien verwendet).
Mit diesem Ansatz haben wir zahlreiche Optimierungen vorgenommen. Insbesondere haben wir auch technische Optimierungen für Diffusion implementiert. Anstatt einfach die Standarddiffusion zu verwenden, haben wir eine Inferenzkompression implementiert, die als eine Art Destillation betrachtet werden kann. Früher hätte Diffusion möglicherweise zehn Inferenzschritte benötigt, mit Flow Matching sind es nur noch zwei. Diese Kompression ist der Hauptgrund, warum wir VLA einsetzen konnten.

F: Ist VLA eine ausreichend gute Lösung? Wie lange wird es dauern, bis der sogenannte „GPT-Moment“ erreicht ist?
Zhan Kun: Die frühere Aussage, das multimodale Modell habe den GPT-Moment noch nicht erreicht, bezog sich möglicherweise eher auf physische KI wie VLA als auf VLM. Tatsächlich erfüllt VLM nun vollständig einen sehr innovativen „GPT-Moment“-Standard. Betrachtet man physische KI, hat die aktuelle VLA, insbesondere in den Bereichen Robotik und verkörperte Intelligenz, den „GPT-Moment“-Standard möglicherweise noch nicht erreicht, da sie nicht über so gute Generalisierungsfähigkeiten verfügt.
Im Bereich des autonomen Fahrens löst VLA jedoch tatsächlich ein relativ einheitliches Fahrparadigma, und auf diese Weise besteht die Chance, einen „GPT-Moment“ zu erreichen. Wir sind uns auch sehr bewusst, dass das aktuelle VLA die erste Version und die erste VLA-Version ist, die in der Branche in die Massenproduktion gebracht wird, sodass es definitiv einige Mängel geben wird.
Dieser große Versuch zielt darauf ab, mithilfe von VLA neue Wege zu beschreiten. Er beinhaltet viele Bereiche, die ausprobiert werden müssen, und viele Erkundungspunkte, die umgesetzt werden müssen. Das bedeutet nicht, dass wir nicht in die Massenproduktion gehen dürfen, wenn wir den „GPT-Moment“ nicht erreichen. Es gibt viele Details, einschließlich unserer Evaluierung und Simulation, um zu überprüfen, ob es in die Massenproduktion gehen kann und ob es den Benutzern ein „besseres, komfortableres und sichereres“ Erlebnis bietet. Wenn die oben genannten drei Punkte erreicht werden, können wir den Benutzern eine bessere Leistung bieten.
„GPT-Momente“ beziehen sich eher auf starke Vielseitigkeit und Generalisierung. In diesem Prozess, wenn wir autonomes Fahren auf Weltraumroboter oder andere verkörperte Felder ausweiten, können wir stärkere Generalisierungsfähigkeiten oder umfassendere Koordinationsfähigkeiten entwickeln. Nach der Implementierung werden wir schrittweise zu ChatGPT-Momenten migrieren, da „Benutzerdaten iterieren, Szenarien umfangreicher werden, das Denken logischer wird und Sprachinteraktionen häufiger werden“.
Wie Dr. Lang Bo (Dr. Lang Xianpeng) sagte: Wenn wir bis zum nächsten Jahr 1000 MPI erreichen, könnte dies den Benutzern das Gefühl geben, dass wir für VLA wirklich einen „GPT-Moment“ erreicht haben.
#Willkommen beim offiziellen öffentlichen WeChat-Konto von iFaner: iFaner (WeChat-ID: ifanr), wo Ihnen so bald wie möglich weitere spannende Inhalte präsentiert werden.