
Machen Sie ein Video mit Ihrem Mund, das kommt wirklich! Diese neue App, Meta, ist erschreckend
Dieses Jahr ist ein Jahr großer Fortschritte für KI im Bereich der Bild- und Videoproduktion.
Jemand hat den Digital Art Award mit einem von KI generierten Bild gewonnen und eine Gruppe menschlicher Künstler besiegt; es gibt Anwendungen wie Tiktok, die Bilder durch Texteingabe generieren und sie in den Greenscreen-Hintergrund von kurzen Videos verwandeln; es gibt neue Produkte, die das können Text erstellen Video direkt erstellen und direkt den Effekt von "Video mit dem Mund erstellen" realisieren.
Das Produkt stammt diesmal von Meta, das seit vielen Jahren künstliche Intelligenz intensiv kultiviert und vor einiger Zeit wegen des Metaversums wahnsinnig belächelt wurde.

▲ Die Meta Metaverse wurde wild verspottet
Nur dieses Mal kann man es nicht verspotten, denn es hat wirklich einen kleinen Durchbruch.
Text zu Video, was getan werden kann
Jetzt können Sie Ihren Mund bewegen, um ein Video zu machen.
Obwohl dies etwas übertrieben ist, bewegt sich Metas Make-A-Video dieses Mal wahrscheinlich wirklich in Richtung dieses Ziels.

Was Make-A-Video derzeit kann, ist:
- Text-zu-Video – Verwandeln Sie Ihre Vorstellungskraft in echte, einzigartige Videos
- Konvertieren Sie Bilder direkt in Video – lassen Sie ein einzelnes Bild oder zwei Bilder sich natürlich bewegen
- Video Generieren eines erweiterten Videos – Geben Sie ein Video ein, um eine Videovariante zu erstellen
In Bezug auf die direkte Generierung von Videos aus Text hat Make-A-Video viele professionelle Animationsdesign-Studenten besiegt. Zumindest kann es jeden Stil machen, und die Produktionskosten sind sehr niedrig.
Obwohl die offizielle Website es Ihnen nicht erlaubt, direkt ein Videoerlebnis zu generieren, können Sie zuerst Ihre persönlichen Daten übermitteln, und Make-A-Video teilt Ihnen dann zuerst alle Entwicklungen mit.

Es gibt nicht viele Fälle, die bisher zu sehen sind, und die auf der offiziellen Website angezeigten Fälle haben immer noch einige seltsame Stellen im Detail. Aber trotzdem ist die Tatsache, dass Text direkt in Video umgewandelt werden kann, eine Verbesserung für sich.
Ein Teddybär zeichnet ein Selbstporträt, und Sie können die unnatürliche Projektion der Bärenhand auf dem schattierten Teil des Papiers sehen.

Roboter tanzen auf dem Times Square.

Die Katze hält die TV-Fernbedienung, um den Kanal zu wechseln. Die Krallen der Katze sind den menschlichen Händen sehr ähnlich, und manchmal fühlt es sich ein wenig beängstigend an, sie zu beobachten.

Und ein pelziges Faultier mit orangefarbener Strickmütze hantiert mit einem Laptop, das Licht des Computerbildschirms in den Augen.

Die oben genannten sind surreale Stile, und Hüllen, die der Realität ähnlicher sind, sind einfacher zu tragen.
Die von Make-A-Video gezeigten Fälle sind gut, wenn sie sich nur auf lokale Bereiche konzentrieren, wie die Nahaufnahme des Künstlers, der auf die Leinwand malt, das Pferd, das Wasser trinkt, und die kleinen Fische, die im Korallenriff schwimmen.



Aber ein etwas realistischeres junges Paar, das im starken Regen spazieren geht, ist sehr seltsam: Der Oberkörper ist in Ordnung, aber die Füße des Unterkörpers flackern, manchmal gedehnt, wie in einem Geisterfilm.

Es gibt auch Videos im Malstil von Raumschiffen, die auf dem Mars landen, Paare im Smoking, die in Regengüssen gefangen sind, Sonnenlicht auf Tischen und sich bewegende Pandapuppen. Im Detail sind diese Videos nicht perfekt, aber allein schon durch die innovative Wirkung von AI Text-to-Video sind sie immer noch verblüffend.




Auch statische Gemälde können mit Hilfe von Make-A-Video animiert werden – das Boot bewegt sich in den großen Wellen.

Die Schildkröten schwimmen im Meer.Das anfängliche Bild ist sehr natürlich, aber später wird es eher wie ein grüner Bildschirmausschnitt, was unnatürlich ist.
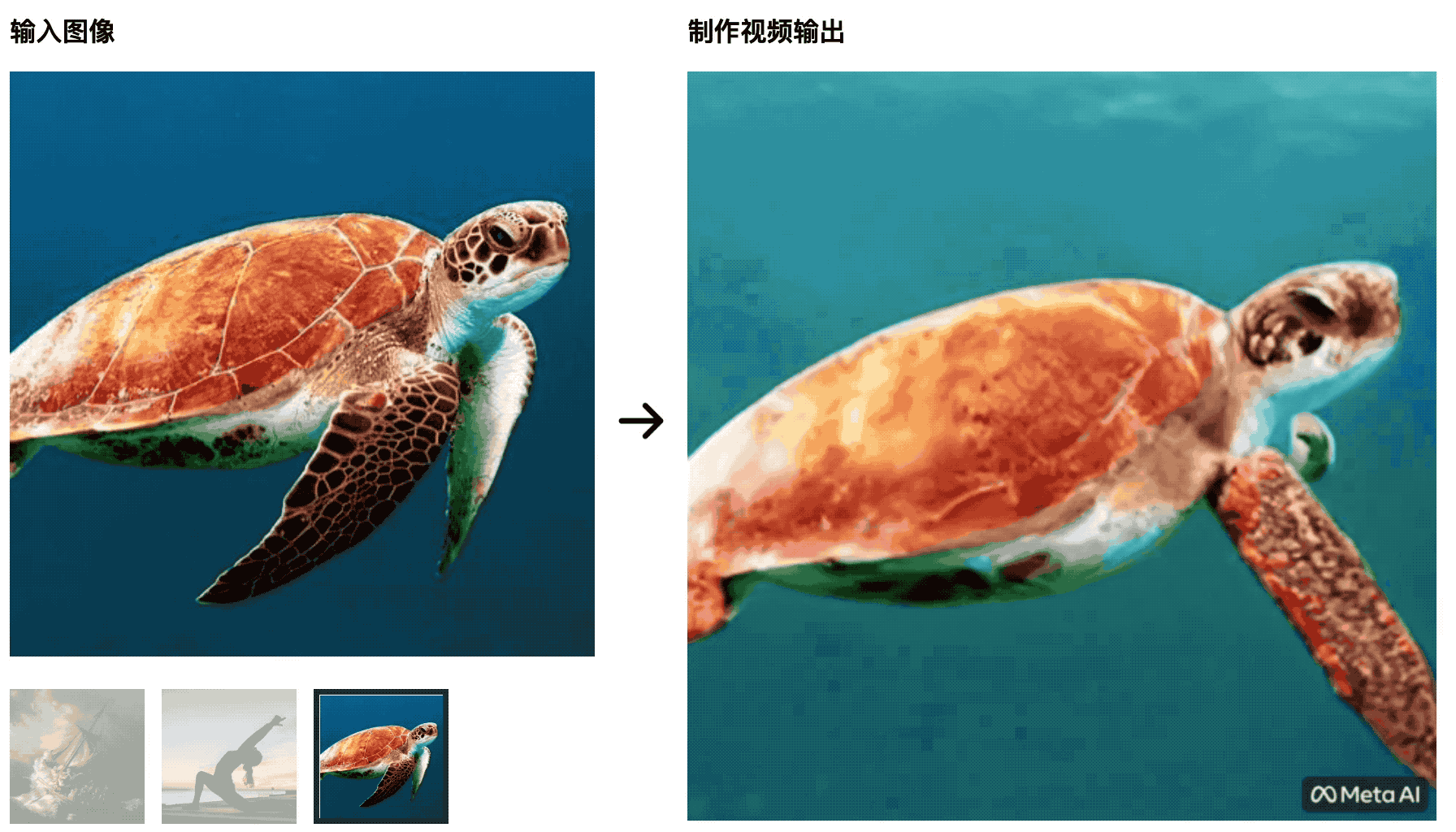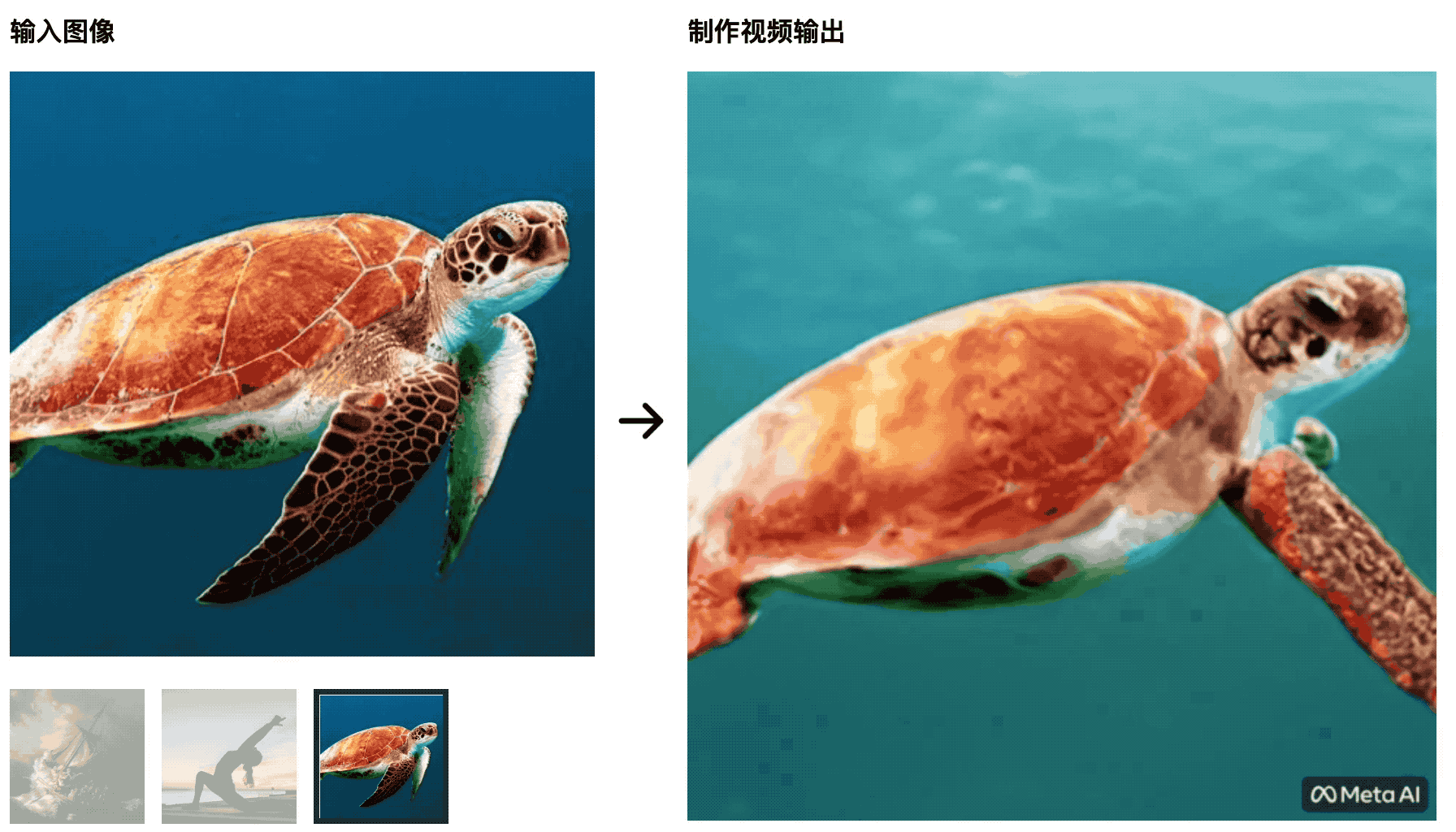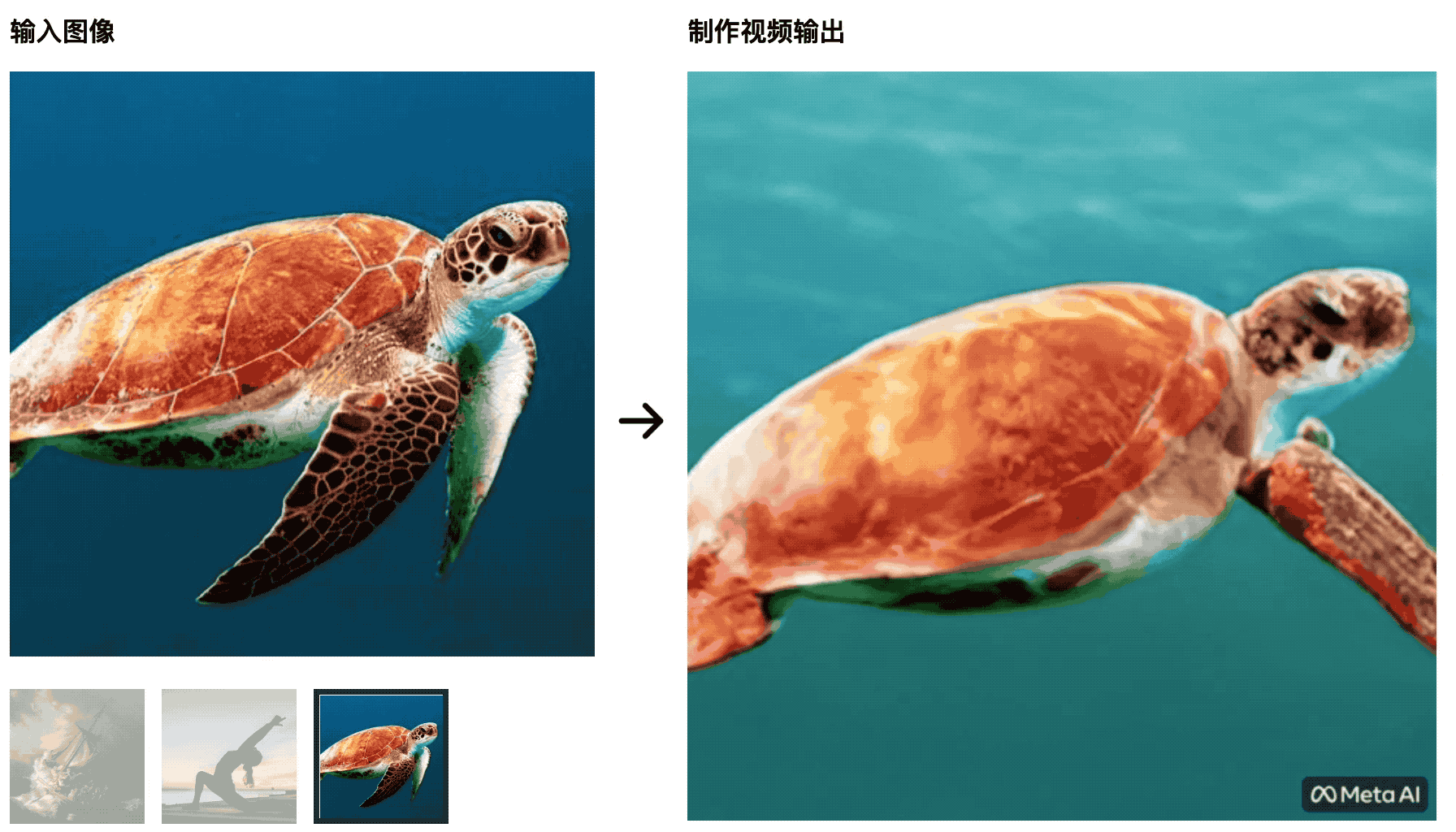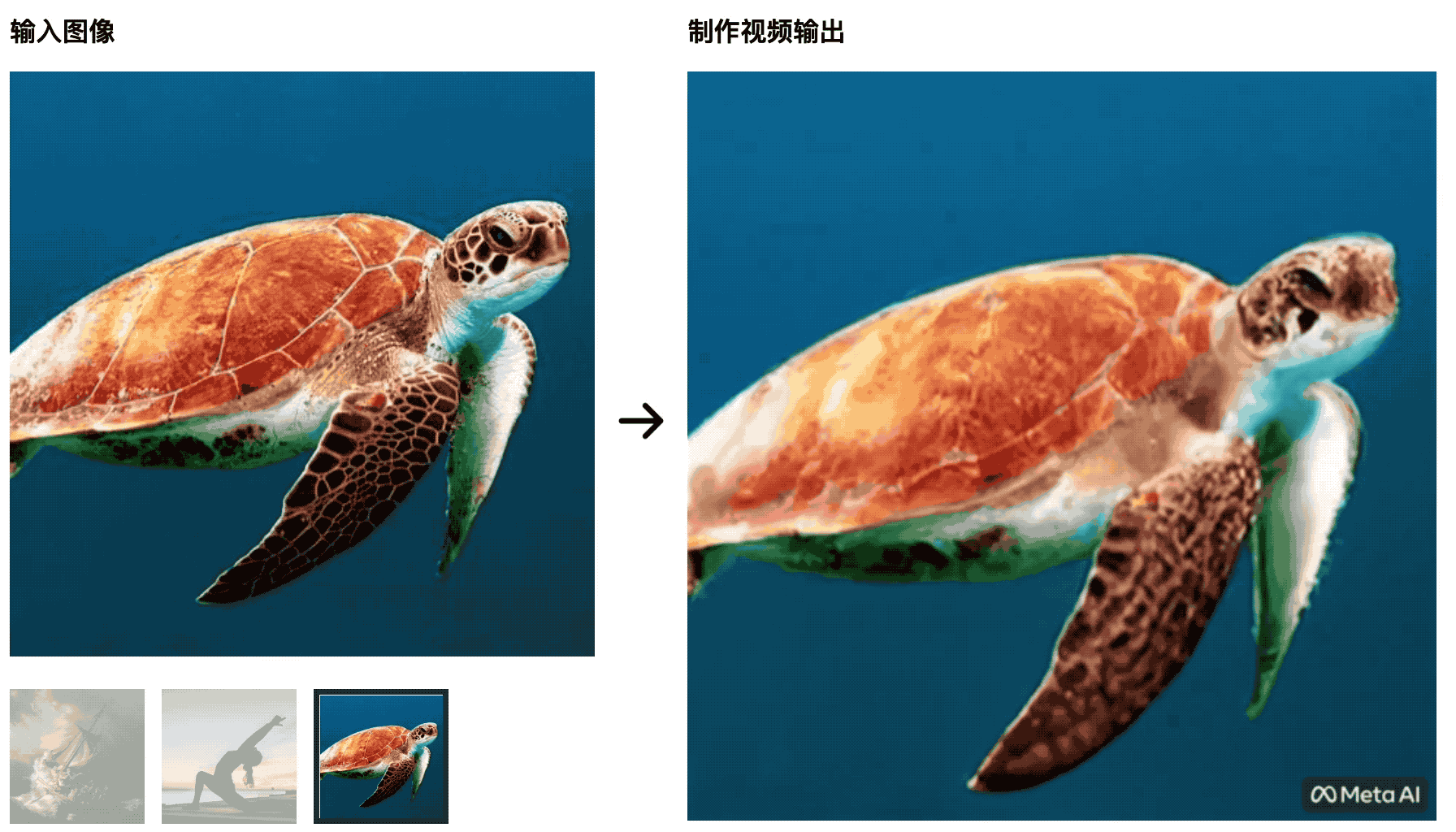
Yoga-Trainer strecken ihre Körper in die aufgehende Sonne, und die Yogamatte ändert sich mit den Änderungen des Videos – diese KI wird die Studenten, die Film- und Fernsehproduktion studieren, nicht besiegen können, und die Kontrollvariablen sind nicht gut gemacht.

Geben Sie schließlich ein Video ein, um seinen Stil zu imitieren, um Videovarianten zu erstellen. Es gibt auch 3 Fälle.
Eine der Änderungen ist relativ weniger raffiniert. Das Video von Astronauten, die im Weltraum flattern, wurde in eine etwas weniger ästhetische Version von 4 groben Versionen des Videos umgewandelt.

Im Video des kleinen tanzenden Bären gibt es einige überraschende Änderungen, zumindest die Tanzhaltung hat sich geändert.

Was das letzte Video mit dem Gras fressenden Hasen betrifft, so ist es das „anneng unterscheidet mich als Mann und Frau.“ Es ist schwer zu erkennen, wer das erste Video in den letzten 5 Videos ist, und es sieht sehr harmonisch aus.

Sobald der Text zu Bildern fortgeschritten ist, gibt es das Video hier
In " Nach AlphaGo untergräbt es die menschliche Wahrnehmung wieder komplett " haben wir einmal die Bilderzeugungsanwendung DALL·E vorgestellt. Jemand hat es verwendet, um Bilder zu erstellen, um mit menschlichen Künstlern zu konkurrieren und schließlich zu gewinnen.
Das Make-A-Video, das wir jetzt sehen, kann als Videoversion von DALL·E (primäre Version) bezeichnet werden – es ist wie das DALL·E vor 18 Monaten, mit einem großen Durchbruch, aber der aktuelle Effekt kann das nicht schaffen die Leute sind zufrieden.

▲ Erweiterte Malerei erstellt von DALL·E
Man kann sogar sagen, dass es sich um ein Produkt handelt, das auf den Schultern des Giganten DALL·E steht und Erfolge erzielt. Im Vergleich zu textgenerierten Bildern hat Make-A-Video nicht allzu viele neue Änderungen im Backend vorgenommen.
„Wir haben gesehen, dass Modelle, die textgenerierte Bilder beschreiben, auch überraschend effektiv bei der Erstellung kurzer Videos waren“, sagten die Forscher in ihrer Arbeit.

▲Preisgekrönte Arbeiten, die textgenerierte Bilder beschreiben
Derzeit haben die von Make-A-Video produzierten Videos 3 Vorteile:
- Beschleunigtes Training von T2V-Modellen (Text zu Video)
- Keine Notwendigkeit für gepaarte Text-zu-Video-Daten
- Das konvertierte Video erbt den Stil des ursprünglichen Bildes/Videos
Diese Bilder haben sicherlich Nachteile, und die oben erwähnte Unnatürlichkeit ist alles real. Und sie sind nicht wie die Videos, die in dieser Zeit geboren wurden, die Bildqualität ist verschwommen, die Bewegung ist steif, die Tonanpassung wird nicht unterstützt, die Länge eines Videos beträgt nicht mehr als 5 Sekunden und die Auflösung beträgt 64 x 64 Pixel.

▲ Dieses Video zeigt ein paar Frames von der Zunge und den Händen des Hundes, die sehr seltsam sind
Das erste CogVideo-Modell, das Video direkt aus Text synthetisieren kann, das vor einigen Monaten von einem Forschungsteam der Tsinghua-Universität und des Zhiyuan Research Institute (BAAI) veröffentlicht wurde, hat ebenfalls ein solches Problem. Basierend auf der groß angelegten vortrainierten Transformer-Architektur schlägt es eine hierarchische Trainingsstrategie mit mehreren Bildraten vor, die Text und Videoclips effizient ausrichten kann, aber einer genauen Prüfung nicht standhält.
Aber wer sagt 18 Monate später, dass Make-A-Video und CogVideo nicht bessere Videos machen werden als die meisten anderen?

▲ Von CogVideo generiertes Video – dies unterstützt derzeit nur die chinesische Generation
Obwohl nicht viele Text-zu-Video-Tools veröffentlicht wurden, sind viele auf dem Markt. Nach der Veröffentlichung von Make-A-Video erklärten die Entwickler des Start-ups StabilityAI öffentlich: „Unsere (Text-zu-Video-Anwendung) wird schneller und besser und für mehr Menschen anwendbar.“
Der Wettbewerb ist besser, und die immer realistischer werdende Text-to-Image-Funktion ist der beste Beweis.
#Willkommen beim offiziellen WeChat-Konto von Aifaner: Aifaner (WeChat: ifanr), weitere aufregende Inhalte werden Ihnen so bald wie möglich zur Verfügung gestellt.
Liebe Faner | Ursprünglicher Link · Kommentare anzeigen · Sina Weibo