
So finden Sie doppelte Daten in einer Linux-Textdatei Mit uniq
Sind Sie jemals auf Textdateien mit wiederholten Zeilen und doppelten Wörtern gestoßen? Vielleicht arbeiten Sie regelmäßig mit der Befehlsausgabe und möchten diese nach bestimmten Zeichenfolgen filtern. Wenn es um Textdateien und das Entfernen redundanter Daten unter Linux geht, ist der Befehl uniq die beste Wahl.
In diesem Artikel werden wir den Befehl uniq ausführlich erläutern und eine ausführliche Anleitung zur Verwendung des Befehls zum Entfernen doppelter Zeilen aus einer Textdatei verwenden.
Was ist der Uniq-Befehl?
Der Befehl uniq unter Linux wird verwendet, um identische Zeilen in einer Textdatei anzuzeigen. Dieser Befehl kann hilfreich sein, wenn Sie doppelte Wörter oder Zeichenfolgen aus einer Textdatei entfernen möchten. Da der Befehl uniq mit benachbarten Zeilen übereinstimmt, um redundante Kopien zu finden, funktioniert er nur mit sortierten Textdateien.
Glücklicherweise können Sie den Befehl sort mit uniq weiterleiten, um die Textdatei so zu organisieren, dass sie mit dem Befehl kompatibel ist. Neben der Anzeige wiederholter Zeilen kann der Befehl uniq auch das Auftreten doppelter Zeilen in einer Textdatei zählen.
Verwendung des uniq-Befehls
Es gibt verschiedene Optionen und Flags, die Sie mit uniq verwenden können. Einige von ihnen sind einfach und führen einfache Vorgänge aus, z. B. das Drucken wiederholter Zeilen, während andere für fortgeschrittene Benutzer gedacht sind, die häufig mit Textdateien unter Linux arbeiten.
Grundlegende Syntax
Die grundlegende Syntax des Befehls uniq lautet:
uniq option input output… wobei Option das Flag ist, das zum Aufrufen bestimmter Methoden des Befehls verwendet wird, Eingabe die Textdatei für die Verarbeitung ist und Ausgabe der Pfad der Datei ist, in der die Ausgabe gespeichert wird.
Das Ausgabeargument ist optional und kann übersprungen werden. Wenn ein Benutzer die Eingabedatei nicht angibt, verwendet uniq Daten aus der Standardausgabe als Eingabe. Dies ermöglicht es einem Benutzer, Uniq mit anderen Linux-Befehlen zu verbinden .
Beispieltextdatei
Wir werden die Textdatei duplicate.txt als Eingabe für den Befehl verwenden.
127.0.0.1 TCP
127.0.0.1 UDP
Do catch this
DO CATCH THIS
Don't match this
Don't catch this
This is a text file.
This is a text file.
THIS IS A TEXT FILE.
Unique lines are really rare.
Beachten Sie, dass wir diese Textdatei bereits mit dem Befehl sort sortiert haben. Wenn Sie mit einer anderen Textdatei arbeiten, können Sie diese mit dem folgenden Befehl sortieren:
sort filename.txt > sorted.txtDoppelte Linien entfernen
Die grundlegendste Verwendung von uniq besteht darin, wiederholte Zeichenfolgen aus der Eingabe zu entfernen und eine eindeutige Ausgabe zu drucken.
uniq duplicate.txtAusgabe:
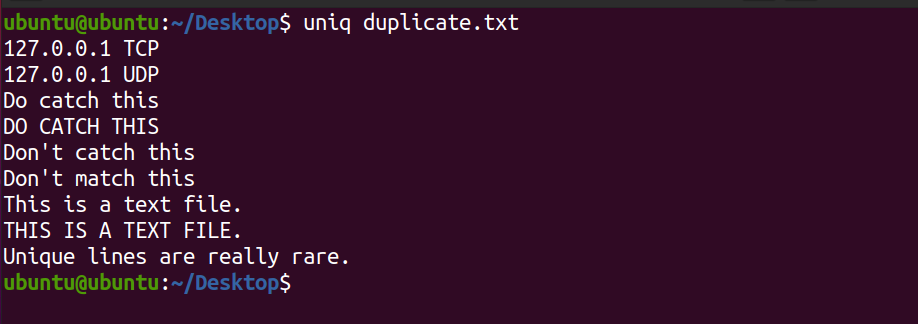
Beachten Sie, dass das System das zweite Vorkommen der Zeile nicht anzeigt. Dies ist eine Textdatei . Außerdem druckt der oben genannte Befehl nur die eindeutigen Zeilen in der Datei und hat keinen Einfluss auf den Inhalt der ursprünglichen Textdatei.
Wiederholte Zeilen zählen
Verwenden Sie das Flag -c mit dem Standardbefehl, um die Anzahl der wiederholten Zeilen in einer Textdatei auszugeben.
uniq -c duplicate.txtAusgabe:
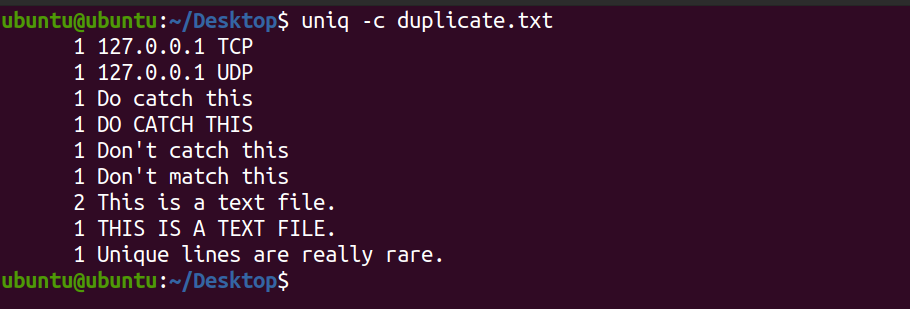
Das System zeigt die Anzahl jeder Zeile an, die in der Textdatei vorhanden ist. Sie können sehen, dass die Zeile Dies ist eine Textdatei zweimal in der Datei vorkommt. Standardmäßig unterscheidet der Befehl uniq zwischen Groß- und Kleinschreibung.
Nur wiederholte Zeilen drucken
Verwenden Sie das Flag -D , um nur doppelte Zeilen aus der Textdatei zu drucken. Das -D steht für Duplizieren .
uniq -D duplicate.txtDas System zeigt die Ausgabe wie folgt an.
This is a text file.
This is a text file.Felder überspringen, während nach Duplikaten gesucht wird
Wenn Sie eine bestimmte Anzahl von Feldern überspringen möchten, während Sie mit den Zeichenfolgen übereinstimmen, können Sie das Flag -f mit dem Befehl verwenden. Das -f steht für Field .
Betrachten Sie die folgende Textdatei fields.txt .
192.168.0.1 TCP
127.0.0.1 TCP
354.231.1.1 TCP
Linux FS
Windows FS
macOS FSSo überspringen Sie das erste Feld:
uniq -f 1 fields.txtAusgabe:
192.168.0.1 TCP
Linux FSDer oben genannte Befehl übersprang das erste Feld (die IP-Adressen und Betriebssystemnamen) und stimmte mit dem zweiten Wort (TCP und FS) überein. Anschließend wurde das erste Auftreten jeder Übereinstimmung als Ausgabe angezeigt.
Zeichen beim Vergleich ignorieren
Wie beim Überspringen von Feldern können Sie auch Zeichen überspringen. Mit dem Flag -s können Sie die Anzahl der zu überspringenden Zeichen angeben, während doppelte Zeilen abgeglichen werden. Diese Funktion hilft, wenn die Daten, mit denen Sie arbeiten, in Form einer Liste wie folgt vorliegen:
1. First
2. Second
3. Second
4. Second
5. Third
6. Third
7. Fourth
8. FifthSo ignorieren Sie die ersten beiden Zeichen (die Listennummern ) in der Datei list.txt :
uniq -s 2 list.txtAusgabe:
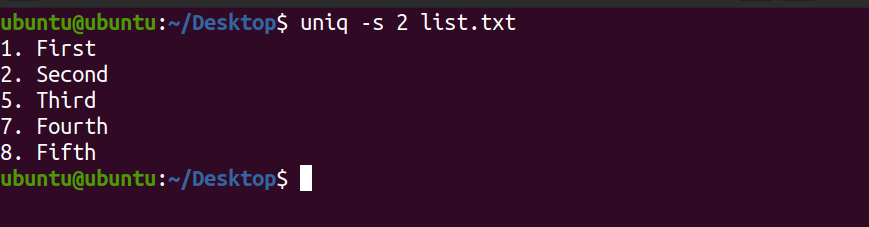
In der obigen Ausgabe wurden die ersten beiden Zeichen ignoriert und der Rest wurde auf eindeutige Zeilen abgeglichen.
Überprüfen Sie die erste N Anzahl der Zeichen auf Duplikate
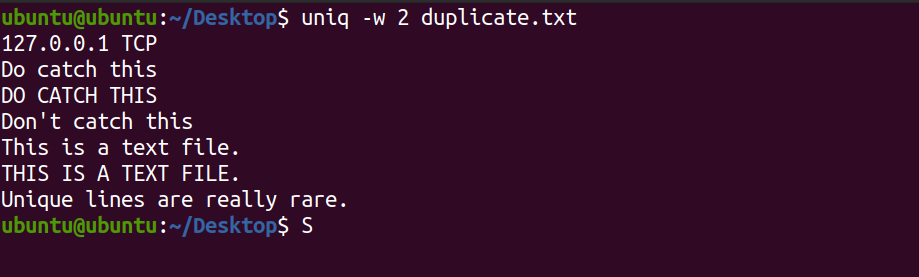
Mit dem Flag -w können Sie nur eine feste Anzahl von Zeichen auf Duplikate überprüfen. Beispielsweise:
uniq -w 2 duplicate.txtDer oben genannte Befehl stimmt nur mit den ersten beiden Zeichen überein und gibt gegebenenfalls eindeutige Zeilen aus.
Ausgabe:
Entfernen Sie die Groß- / Kleinschreibung
Wie oben erwähnt, unterscheidet Uniq beim Abgleichen von Zeilen in einer Datei zwischen Groß- und Kleinschreibung. Verwenden Sie die Option -i mit dem Befehl, um die Groß- und Kleinschreibung zu ignorieren.
uniq -i duplicate.txtSie sehen die folgende Ausgabe.
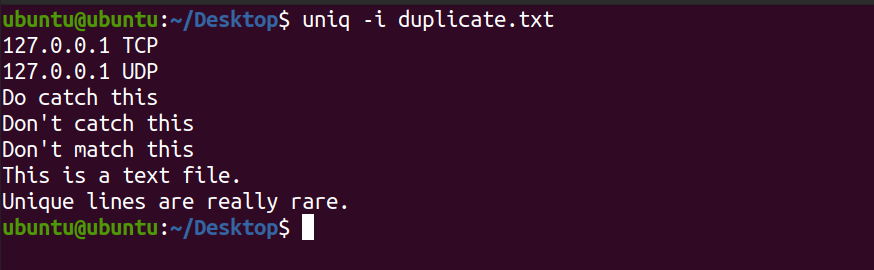
Beachten Sie, dass in der obigen Ausgabe uniq die Zeilen DO CATCH THIS und THIS IS A TEXT FILE nicht angezeigt hat.
Ausgabe an eine Datei senden
Um die Ausgabe des Befehls uniq an eine Datei zu senden, können Sie das Zeichen Output Redirection ( > ) wie folgt verwenden:
uniq -i duplicate.txt > otherfile.txtBeim Senden einer Ausgabe an eine Textdatei zeigt das System die Ausgabe des Befehls nicht an. Sie können den Inhalt der neuen Datei mit dem Befehl cat überprüfen.
cat otherfile.txtSie können auch andere Möglichkeiten verwenden, um eine Befehlszeilenausgabe an eine Datei unter Linux zu senden .
Doppelte Daten analysieren Mit uniq
Während der Verwaltung von Linux-Servern arbeiten Sie meistens entweder am Terminal oder bearbeiten Textdateien. Daher kann das Wissen, wie redundante Kopien von Zeilen in einer Textdatei entfernt werden, ein großer Vorteil für Ihre Linux-Kenntnisse sein.
Das Arbeiten mit Textdateien kann frustrierend sein, wenn Sie nicht wissen, wie Sie Text in einer Datei filtern und sortieren können. Um Ihnen die Arbeit zu erleichtern, verfügt Linux über mehrere Textbearbeitungsbefehle wie sed und awk , mit denen Sie effizient mit Textdateien und Befehlszeilenausgaben arbeiten können.