
Wie wäre es, vier Mac Studios der Spitzenklasse zu verbinden und zwei DeepSeek-Maschinen gleichzeitig für nur 400.000 Yuan laufen zu lassen?

Vor einigen Monaten hat iFanr erfolgreich ein 671B DeepSeek Local Large Model (4-Bit-quantisierte Version) auf einem Mac Studio mit M3 Ultra-Prozessor implementiert . Könnte man vier Mac Studios der Spitzenklasse mit M3 Ultra-Prozessoren mithilfe von Open-Source-Tools zu einem „Desktop-KI-Cluster“ verbinden, könnte die Obergrenze der lokalen Inferenz noch weiter angehoben werden?
Dies ist auch das Problem, das Exo Labs, ein britisches Startup, zu lösen versucht.
Gehen Sie nicht davon aus, dass die Universität Oxford über einen unbegrenzten Vorrat an GPUs verfügt
Man könnte meinen, dass eine Spitzenuniversität wie Oxford mehr GPUs hätte, als sie nutzen kann, aber das ist überhaupt nicht der Fall.
Die Gründer von Exo Labs, Alex und Seth, haben an der Universität Oxford studiert. Selbst an einer so renommierten Institution muss man monatelang in der Schlange stehen, um auf GPU-Cluster zugreifen zu können. Außerdem können Anträge immer nur für eine Karte gleichzeitig gestellt werden, was den Prozess langwierig und ineffizient macht.
Sie sind sich bewusst, dass die derzeitige stark zentralisierte KI-Infrastruktur einzelne Forscher und kleine Teams marginalisiert.
Im vergangenen Juli starteten sie ihr erstes Experiment und führten das LLaMA-Modell erfolgreich mit zwei MacBook Pros im Tandembetrieb aus. Obwohl die Leistung begrenzt war und nur drei Token pro Sekunde ausgegeben wurden, reichte dies aus, um die Machbarkeit der Apple Silicon-Architektur für verteiltes KI-Denken zu demonstrieren.

Der Wendepunkt kam mit der Veröffentlichung des M3 Ultra Mac Studio. Sein 512 GB gemeinsamer Speicher, 819 GB/s Speicherbandbreite, eine 80-Kern-GPU und die bidirektionale Übertragungskapazität von 80 Gbit/s von Thunderbolt 5 machten lokale KI-Cluster zur Realität.
Wie ist es, zwei Modelle mit 67 Milliarden Parametern gleichzeitig auszuführen?
Nach dem Anschluss von vier Mac Studios der Spitzenklasse mit M3 Ultra-Prozessoren über Thunderbolt 5 sind die Leistungsdaten ziemlich beeindruckend:
- 128-Kern-CPU (32×4)
- 240 GPU-Kerne (80×4)
- 2 TB gemeinsamer Speicher (512 GB x 4)
- Die gesamte Speicherbandbreite übersteigt 3 TB/s
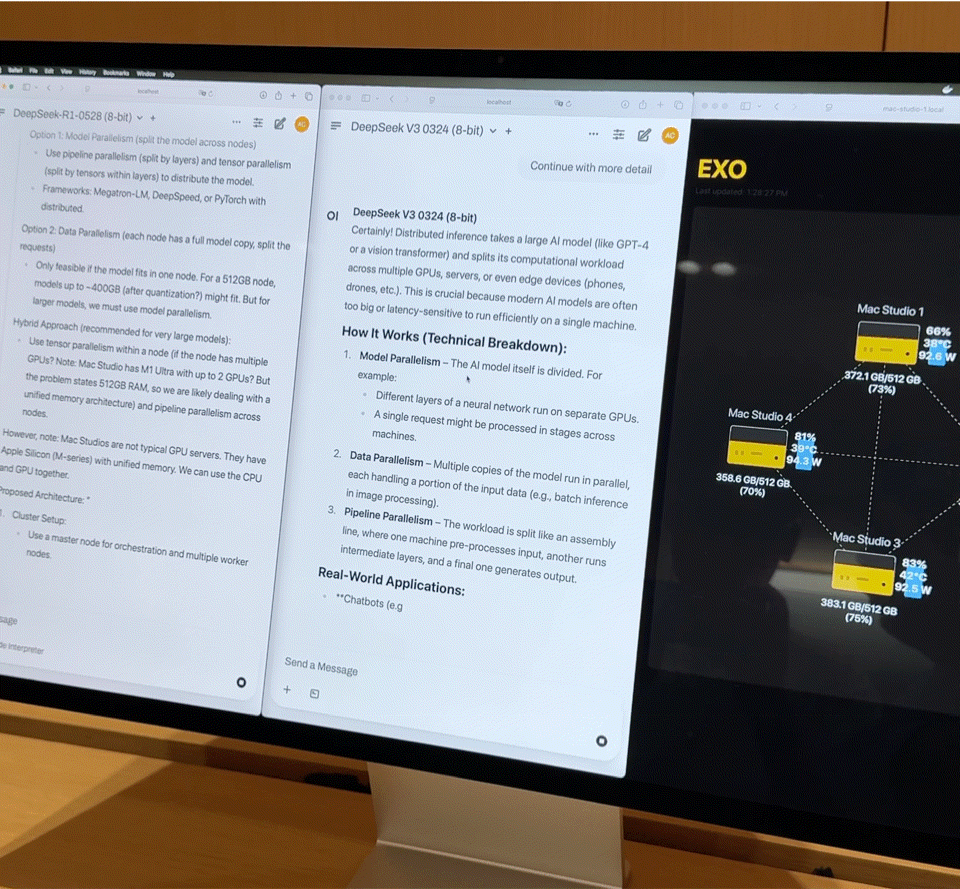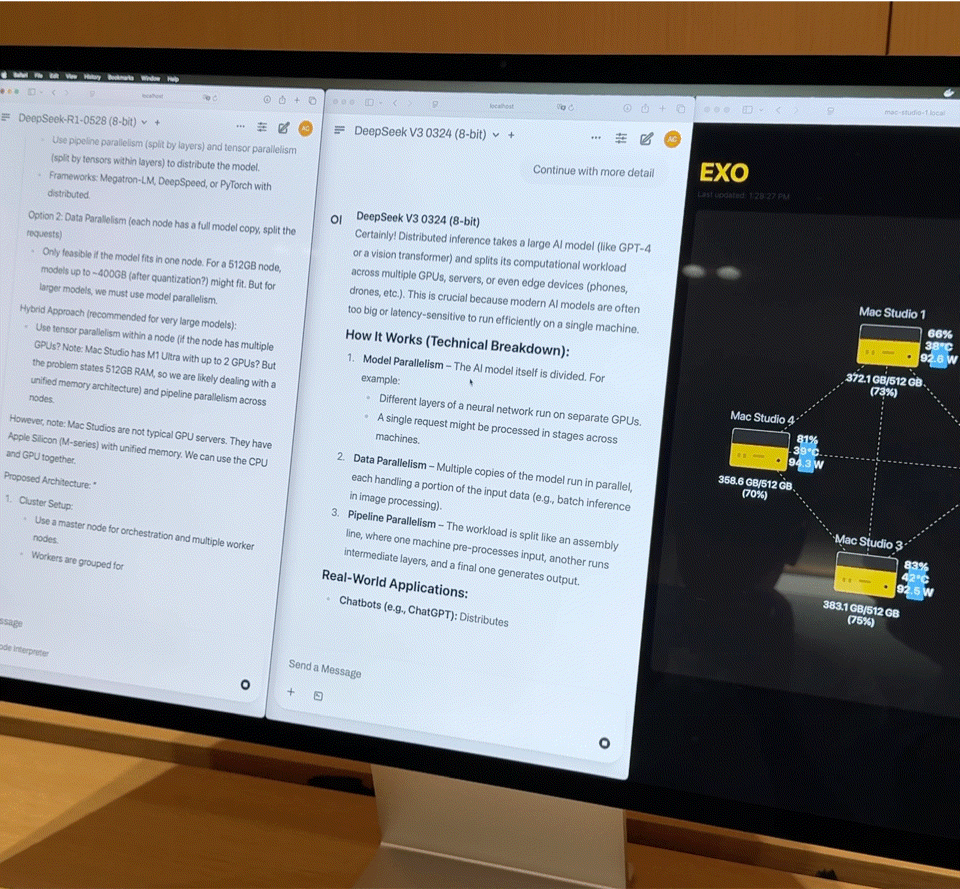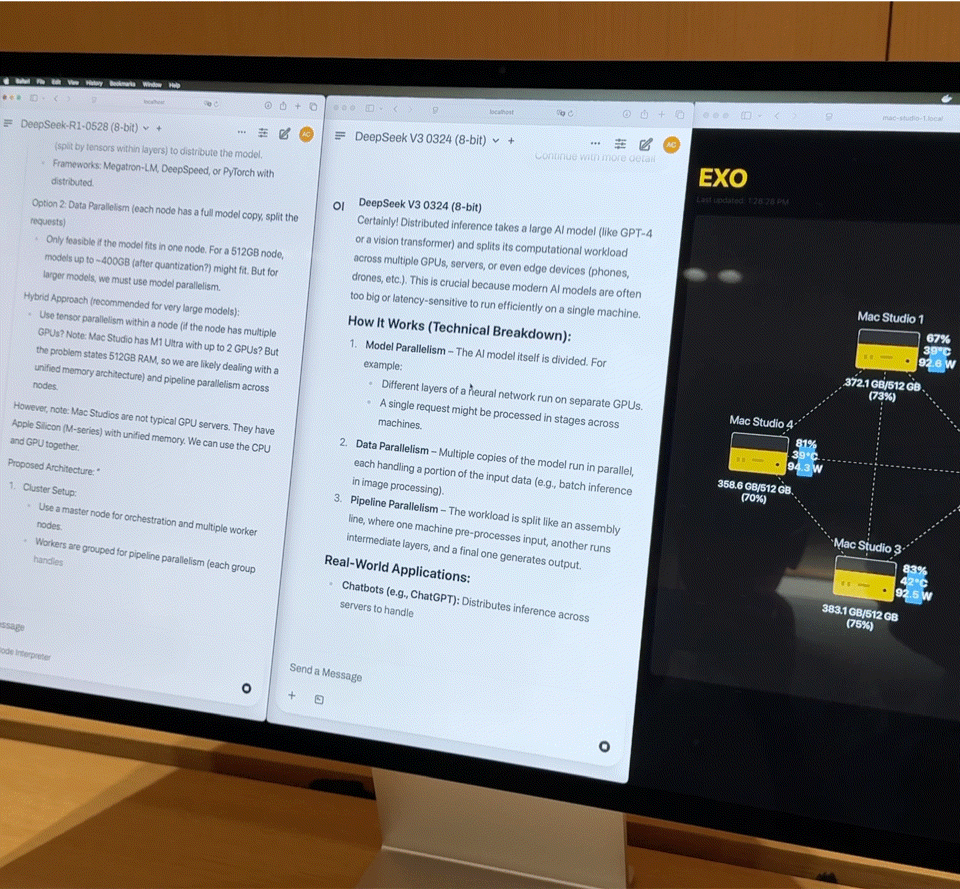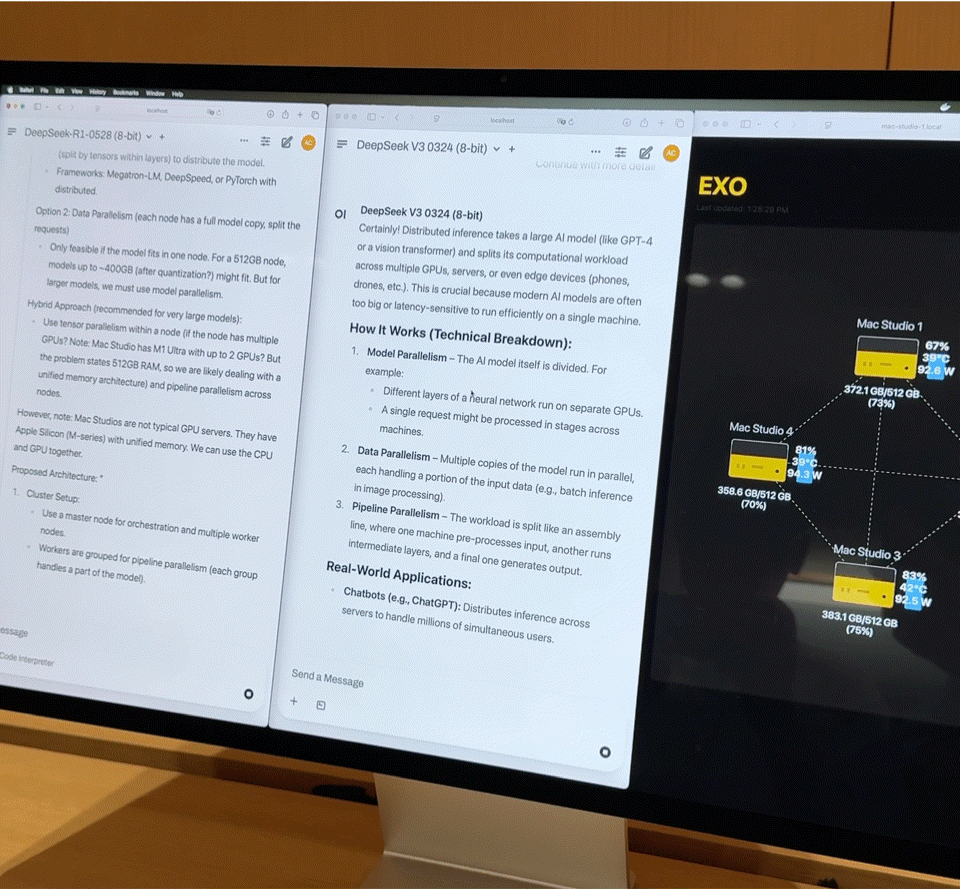
Diese Kombination entspricht fast einem kleinen Supercomputer für den Heimgebrauch. Die Hardware bildet jedoch nur die Grundlage; der Schlüssel zur vollen Entfaltung ihrer Leistungsfähigkeit liegt in Exo V2, der von Exo Labs entwickelten Plattform für verteilte Modellplanung. Exo V2 teilt das Modell automatisch basierend auf Speicher- und Bandbreitenverfügbarkeit auf und stellt es auf dem am besten geeigneten Knoten bereit.
Vor Ort demonstrierte Exo V2 die folgenden Kernfunktionen:
- Laden großer Modelle: Ein vollständiges DeepSeek-Modell mit 8-Bit-Quantisierung benötigt über 700 GB Speicher, weit mehr als die Kapazität eines einzelnen Mac Studios. Exo verteilt das Modell auf zwei Mac Studios, um den Ladevorgang abzuschließen. Nach der Aktivierung übertrifft seine „Tippgeschwindigkeit“ die menschliche Lesegeschwindigkeit.
- Parallele Inferenz: DeepSeek R1, ebenfalls mit 67 Milliarden Parametern, wurde auf DeepSeek V3 geladen. Das System verteilte R1 sofort auf die verbleibenden beiden Geräte, wodurch die parallele Inferenz zweier großer Modelle und die gleichzeitige Abfrage durch mehrere Benutzer ermöglicht wurden.
- Fragen und Antworten zu privaten Dokumenten : Ziehen Sie einen PDF-Finanzbericht des Unternehmens hinein, und das Modell führt die Wissenseinbettung und die Fragen und Antworten lokal durch. Es ist nicht auf Cloud-Ressourcen angewiesen und die Daten sind vollständig privat und kontrollierbar.
- Leichtgewichtige Feinabstimmung: Unternehmen mit Tausenden von internen Dokumenten können mithilfe der QLoRA + LoRA-Technologie eine lokale Feinabstimmung durchführen. Die Feinabstimmung einer einzelnen Maschine kann Tage dauern, aber mit den Cluster-Scheduling-Funktionen von Exo können Trainingsaufgaben linear beschleunigt werden, was den Zeitaufwand erheblich reduziert.
Riesiger Kostenunterschied
iFanr beobachtete das Topologiediagramm hinter der Bühne und stellte fest, dass selbst wenn die vier Maschinen gleichzeitig stark ausgelastet waren, der Stromverbrauch des gesamten Systems immer innerhalb von 400 W gehalten wurde und während des Betriebs fast keine Lüftergeräusche auftraten.
Um die gleiche Leistung wie bei herkömmlichen Serverlösungen zu erreichen, müssen mindestens 20 A100-Grafikkarten eingesetzt werden. Die Kosten für Server und Netzwerkausrüstung übersteigen 2 Millionen RMB, der Stromverbrauch erreicht mehrere Kilowatt und es sind ein unabhängiger Computerraum und ein Kühlsystem erforderlich.
Apple-Chips fanden unerwartet eine neue Position in der KI-Welle

Der M3 Ultra Mac Studio ist ab 32.999 Yuan erhältlich und verfügt über 96 GB gemeinsamen Speicher. Die Top-Version mit 512 GB ist zwar recht teuer, bietet aber aus technischer Sicht revolutionäre Vorteile.
Als Apple den M-Chip entwickelte, war er in erster Linie für energieeffiziente und effiziente persönliche Kreationen gedacht. Doch Funktionen wie der einheitliche Speicher, eine GPU mit hoher Bandbreite und Thunderbolt-Multipath-Aggregation haben im KI-Zeitalter unerwartet eine neue Nische gefunden.
Herkömmliche GPUs, selbst die hochwertigsten Workstation-Karten, verfügen typischerweise nur über 96 GB Videospeicher. Dank des einheitlichen Speichers von Apple können CPU und GPU denselben Speicher mit hoher Bandbreite gemeinsam nutzen, wodurch häufige Datenübertragungen zwischen verschiedenen Speicherebenen entfallen. Dies ist entscheidend für die Inferenz von Modellen im großen Maßstab.
Natürlich hat die EXO-Lösung auch eine klare Positionierung. Sie ist weder als direkte Konkurrenz zum H100 konzipiert, noch ist sie für das Training der nächsten GPT-Generation konzipiert. Stattdessen ist sie darauf ausgelegt, praktische Anwendungsprobleme zu lösen: die Ausführung eigener Modelle, den Schutz eigener Daten und die Durchführung notwendiger Feinabstimmungen und Optimierungen.
Wenn H100 der König an der Spitze der Pyramide ist, dann wird Mac Studio zum Schweizer Taschenmesser in den Händen kleiner und mittelgroßer Teams.
#Willkommen beim offiziellen öffentlichen WeChat-Konto von iFaner: iFaner (WeChat-ID: ifanr), wo Ihnen so bald wie möglich weitere spannende Inhalte präsentiert werden.