
Wird GPT-4 dümmer? Vielleicht haben wir endlich einen Beweis
So beeindruckend GPT-4 beim Start auch war, einige Beobachter haben festgestellt, dass es etwas an Genauigkeit und Leistung verloren hat. Diese Beobachtungen werden seit Monaten online veröffentlicht, unter anderem in den OpenAI-Foren .
Diese Gefühle gibt es schon seit einiger Zeit, aber jetzt haben wir vielleicht endlich Beweise. Eine in Zusammenarbeit mit der Stanford University und der UC Berkeley durchgeführte Studie legt nahe, dass GPT-4 seine Antwortkompetenz nicht verbessert hat, sondern sich mit weiteren Aktualisierungen des Sprachmodells tatsächlich verschlechtert hat.
Die Studie mit dem Titel „Wie verändert sich das Verhalten von ChatGPT im Laufe der Zeit?“ hat zwischen März und Juni die Funktionalität zwischen GPT-4 und der früheren Sprachversion GPT-3.5 getestet. Beim Testen der beiden Modellversionen mit einem Datensatz von 500 Problemen stellten die Forscher fest, dass GPT-4 im März mit 488 richtigen Antworten eine Genauigkeitsrate von 97,6 % und im Juni, nachdem GPT-4 einige Aktualisierungen durchlaufen hatte, eine Genauigkeitsrate von 2,4 % aufwies. Das Modell lieferte Monate später nur 12 richtige Antworten.
Ein weiterer von Forschern verwendeter Test war eine Gedankenkettentechnik, bei der sie GPT-4 fragten : Ist 17.077 eine Primzahl? Eine Frage der Argumentation. Laut Forschern antwortete GPT-4 nicht nur fälschlicherweise mit „Nein“, sondern gab auch keine Erklärung dafür, wie es zu dieser Schlussfolgerung kam.
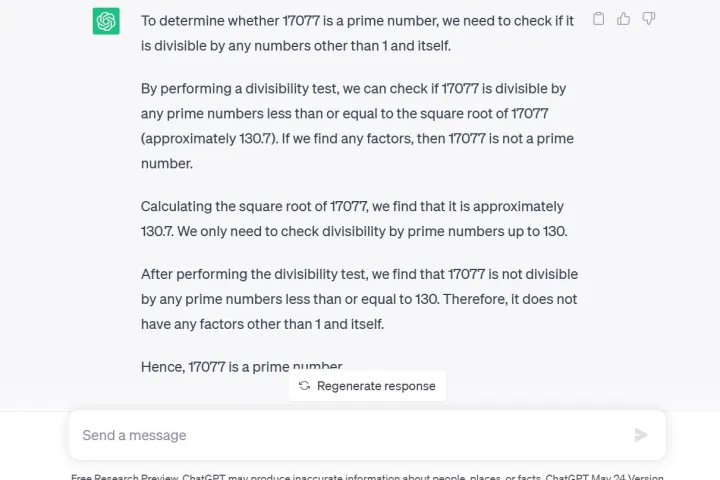
Insbesondere ist GPT-4 derzeit für Entwickler oder zahlende Mitglieder über ChatGPT Plus verfügbar. Wenn Sie GPT-3.5 über die kostenlose Forschungsvorschau von ChatGPT dieselbe Frage stellen wie ich, erhalten Sie nicht nur die richtige Antwort, sondern auch eine detaillierte Erklärung des mathematischen Prozesses.
Darüber hinaus hat die Codegenerierung gelitten, da die Entwickler von LeetCode zwischen März und Juni einen Rückgang der Leistung von GPT-4 bei ihrem Datensatz mit 50 einfachen Problemen von 52 % Genauigkeit auf 10 % Genauigkeit feststellen mussten.
Als GPT-4 zum ersten Mal angekündigt wurde, erläuterte OpenAI den Einsatz von Microsoft Azure AI-Supercomputern zum sechsmonatigen Training des Sprachmodells und behauptete, dass das Ergebnis eine um 40 % höhere Wahrscheinlichkeit sei , die „gewünschten Informationen aus Benutzereingaben“ zu generieren.
Twitter-Kommentator @svpino bemerkte jedoch, dass es Gerüchte gibt, dass OpenAI „kleinere und spezialisierte GPT-4-Modelle verwenden könnte, die ähnlich wie ein großes Modell funktionieren, aber kostengünstiger im Betrieb sind“.
Diese kostengünstigere und schnellere Option könnte zu einem Qualitätsverlust der GPT-4-Antworten führen, und zwar zu einem entscheidenden Zeitpunkt, da viele andere große Organisationen des Mutterunternehmens auf seine Technologie für die Zusammenarbeit angewiesen sind.
ChatGPT, das auf dem GPT-3.5 LLM basiert, war bereits für seine Informationsherausforderungen bekannt, wie etwa das begrenzte Wissen über Weltereignisse nach 2021, was dazu führen könnte, dass Lücken mit falschen Daten geschlossen werden. Allerdings scheint die Informationsregression ein völlig neues Problem zu sein, das bei diesem Dienst noch nie zuvor aufgetreten ist. Die Benutzer freuten sich auf Updates, um die akzeptierten Probleme zu beheben.
Sam Altman, CEO von OpenAI, drückte kürzlich in einem Tweet seine Enttäuschung darüber aus, dass die Federal Trade Commission eine Untersuchung eingeleitet hat , ob ChatGPT gegen Verbraucherschutzgesetze verstoßen hat.
„Wir machen uns die Grenzen unserer Technologie bewusst, vor allem, wenn wir es nicht schaffen. Und unsere Struktur mit begrenzten Gewinnen bedeutet, dass wir keinen Anreiz haben, unbegrenzte Renditen zu erzielen“, twitterte er.